« 2005年12月 | メイン | 2006年02月 »
2006年01月31日
サーバベース・コンバータ V1.2をリリース
アンテナハウスは、1月30日からサーバベース・コンバータ (SBC) V1.2を出荷開始しました。
SBCは、インターネットやイントラネットに接続されたサーバ上でドキュメントや画像変換を行う変換コンポーネント(モジュール)です。
V1.2では、新しく製品のラインアップにPro版を追加しました。Pro版ではSVGおよび各種の画像形式をPDFに変換したり、JPEG/PNG(Windows版のみ)に変換することができます。それ以外の機能は変わりませんが、変換の精度を少しずつ上げています。
SBCの変換機能の概要、及びPro版と従来のStandard版の変換機能については次の図をご覧ください。
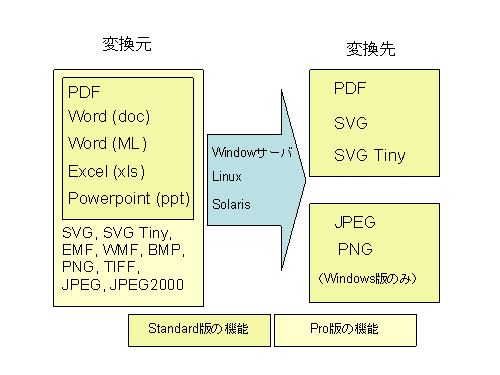
※この図はPowerpointで作成し、SBC V1.2でPNGに変換した画像です。50DPIの設定で画像化しました。
サーバベース・コンバータについては、2005年11月02日サーバでOfficeからPDF、PDFからSVGとイメージで、一度、紹介しました。昨年11月2日の時点では、V1.1はWindows版のみでしたが、その後、1月12日にSolaris/Linux版もV1.1を出荷し、今回はV1.2となっています。
今回は2回目ですので、簡単な変換例を紹介してみます。
上のPowerpointの絵をサンプルにして変換例を作ってみました。まず、SBCでサムネイルを作成します。サムネイルは、Powerpointファイルを、50DPI、サイズ30%で画像化して作成しました。そのサムネイルにオリジナルのファイル、PDFファイル、SVGファイルをリンクしました。
(1)オリジナルのPowerpointファイル
(2)SBCでPDF化したもの
(3)SBCでSVG化したもの

SVGのサポートはブラウザによって異なります。
・インターネット・エクスプローラでSVGを表示するには、通常、AdobeのSVGビューアなどのプラグインを使います。
・FireFoxでは、プラグインを使わなくても、この例のような簡単なSVGは自力で表示できます。
ライセンス価格は次の通りです。今回よりソフトウェア開発ライセンスを用意しました。
(1) SBC Pro版 35万円(消費税別)
(2) SBC Standard版 25万円(消費税別)
(3) ソフトウェア開発ライセンス 20万円(消費税別)
※ソフトウエア開発ライセンスは、SBCを企業内システムやアプリケーションに組み込んだり、システムの検証、保守をするシステム開発向けの割安なライセンスです。ソフトウェア開発ライセンスを実運用するシステムに適用することはできません。実運用システムには、通常のサーバライセンスを別途お求めください。

投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月30日
PDFと文字 (37) – 結合文字列の正規合成
昨日は、任意の新しい文字を、結合文字を使って合成して表示したり印刷したりするというのは、どうやらまだ夢の中のことらしい、ということをお話しました。
では、Unicodeでは結合文字列を合成して表示することはできないのでしょうか?
調べてみましたところ、正規合成(canonical composition)という方法があり、これを使えば、Unicodeでコードポイントをもつ合成済み文字の範囲ならば、殆どの文字を、結合文字列から合成できるように思います。
但し、Microsoft Word2003、OpenOffice.org2.0で試したところ、どうも両方とも正規合成をサポートしていないようです。
では、実際に、正規合成を使って結合文字列から合成済みの文字を合成して、表示・印刷・PDFにすることができるのでしょうか?このあたりをもう少し検討してみたいと思います。検討にあたり、最初に用語を明確にしておきましょう。
結合文字列 (Combining character sequence) p.70 D17
基底文字とそれに続く一つ以上の結合文字の並び、または、一つ以上の結合文字の並び。合成文字列 (Composit character sequence)とも言います。
分解可能な文字 (Decomposable character) p.71 D18
Unicodeの仕様書で文字の名前を指定している箇所で、名前の後に文字の分解マップが指定されている文字を言います。なお、分解マップには正規分解マップ(≡で示される)と互換分解マップ(≈で示される)があります。次の図はU+1E99の正規分解マップが<U+0079, U+030A>、U+1E9Aの互換分解マップが<U+0061, U+02BE>として与えられていることを示します。

合成済みの文字 (precomposed character)、合成文字(Composit character)とも言います。
分解 (Decomposable character) p.71 D19
分解可能な文字と等価な一つ以上の文字の並び。分解が1文字の場合もあることに注意しましょう。
※なお、以下では互換分解については説明しません。
正規分解 (Canonical decomposition) p.72 D23
分解可能な文字を正規分解マップを使って分解します。分解の中に分解可能な文字が入っているときは分解を繰り返し、完全に分解します。次に、分解の中の幅を持たない文字に対して正規並び変え(Canonical ordering)を適用します。この結果が正規分解です。
正規分解が一文字になることもあります。
正規分解可能な文字 (Canonical decomposable character) p.72 D23a
正規分解が自分自身と異なる文字のこと。
正規合成済みの文字 (Canonical precomposed character)、正規合成文字 (Canonical composit character) とも言います。
正規等価 (Canonical equivalent) p.72 D24
二つの文字列は、その二つの文字列の完全な正規分解が同じになる時に正規等価と言います。
正規並び替え(Canonical ordering) pp. 84-85
結合文字は基底文字または先行する結合文字列に対して特定の結合の仕方をします。結合文字に与えられる結合クラスが、この結合の仕方を決めていることは既に説明しました(2006年01月28日 PDFと文字 (35) – 文字の合成方法)。特に結合クラスが同じ値の場合は、結合文字はインサイドアウトルールで配置されます。このように結合文字の順序には意味があります。
従って、正規並び替えでは、二つの結合文字列が同じかどうかを比較するために、結合文字列を結合文字の順序の意味を変えない範囲で(すなわち、結合クラスが同じ値の結合文字の順番は入れ替えないで)、小さいほうから順に並び替えます。
正規合成 (Canonical composition)
分解の中の二つの文字のペアを、そのペアと正規等価なUnicodeの合成済の文字に置き換えていく処理。但し、合成除外文字(Composition Exclusion Tableの文字)は置き換えしません。
※UAX#15 Unicode Normalization Forms を参照。
UAX#15では、Unicode文字の4つの標準形を規定しています。その中で正規分解、正規合成に関係するのは次の二つです。
(1) 標準形式D(NFD):これは上に説明しました正規分解の形式です。
(2) 標準形式C(NFC):文字を正規分解にした後、正規合成した形式です。
次に簡単な絵で説明します。
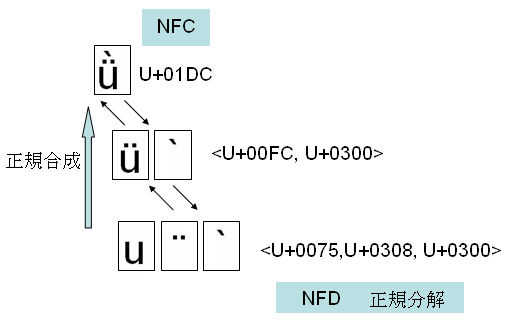
Latin small letter u with diaeresis and grave (U+01DC)は Latin small letter u with diaeresis (U+00FC) と Grave (U+0300)への正規分解マップをもちます。さらに、Latin small letter u with diaeresis は、Latin small letter u (U+0075) と Diaeresis (U+0300)への正規分解マップをもちます。NFDは一番下の形です。NFCは一番上の形です。
Latin small letter u with diaeresis and grave は、NFD形式では、uとGraveとDiaeresisの並びになります。NFD形式を正規合成するとNFCになります。
これを応用すれば、複雑な合成済み文字ラテン文字を基底文字と結合文字でバラバラに記述しておき、表示・印刷・PDF化するときに合成文字にする、ということができそうです。
ということで、この機能をXSL Formatter V4.0のα版に組み込んでもらいました。組み込みは簡単で、数日で、できてきましたので、次に、ちょっと試してみましょう。ほんとにうまくいくのでしょうか?
※XSL Formatter V4.0 α版はまだ一般公開はしていませんが、近いうちに一般公開の予定のものです。
※ご参考
NFD、NFCについては下記にも良い情報があります。
Unicode正規化とは
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月29日
PDFと文字 (36) – 文字の合成方法(続き)
さて、昨日の説明をお読みになって、Unicodeでは、コードポイントを与えられていない文字についても、基底文字と結合文字から合成することのできる文字なら、必要に応じて合成できるのか、これは便利だな、とお思いになった方も多いと思います。
実際、Unicodeの仕様書には文字をダイナミックに合成できそうなことがいろいろと説明してあります。仮にラテンアルファベットに限ったとしても、本当にそんな便利なことができるのでしょうか?そのあたりの記述を取り上げて整理してみましょう。
基底文字とダイアクリティカルマークの文字列(pp. 44-45)
・Unicodeでは、基底文字に結合するダイヤクリティカルマークを、基底文字に続けて適用する順番で使用します。
・二つ以上のダイヤクリティカルマークをひとつの基底文字に適用することがあります。規定文字に続く結合文字の数は制限していません。
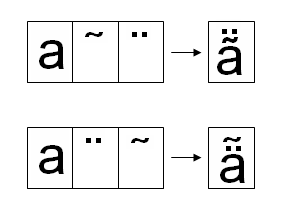
・ダイヤクリティカルマークは、出現順に内側から外側に向かって配置していきます(これをインサイドアウトルールと言います)。従って、ダイヤクリティカルマークの順序に意味があります(下の図)。
結合文字の適用(pp. 82-83)
・囲み記号は先行する文字の周りを順番に取り囲みます。従って、囲み記号が順番に出現すると後の記号は前の記号の周囲を囲むことになります。
・二つの文字に結合する二重のダイヤクリティカルマークは他の字幅のない記号(non spacing mark)よりもルーズに結合します。従って他の字幅のない記号の外側に配置します。
結合クラス(pp. 97-98)
結合文字の結合クラスは、その文字が基底文字に対してどこの位置に配置されるかを示します。(これは昨日の図で示しました)。
字幅のない記号の可視化(Rendering)(pp.125-127)
・インサイドアウトルールは既定値ですが、タイポグラフィーの規則によっては変更することができます。例えば、ベトナム語では、アキュートまたはグレーブ・アクセントは、サーカムフレックス・アクセントの上ではなく、やや左右に配置されます。コードチャートのU+1EA4以降に、ベトナム語表記用のラテン拡張文字があります。
・文字の並びを合成したものが、可視化可能でないときの救済の方法としては、Unicodeの仕様書のように結合文字を点線の円と共に、基底文字とは別に表示するか、単純に基底文字に重ねます。
・文字間を広げる際の字幅のない文字の取り扱いについては、基底文字と結合文字の組がずれないようになど、結合文字の配置についての記述がいろいろあります。
仕様書7.2 Combining Marksの節にも結合文字の可視化の方法について繰り返して類似のことを説明しています。
このような記述は、いかにも、基底文字と結合文字を使ってその組み合わせの文字を画面に奇麗に表示したり、印刷したり、PDF化ができることを期待しているように思えます。
しかし、実際にそのようなことが自由にできるようには、相当なインテリジェントをもつフォントとそれを使いこなせるアプリケーションが必要でしょう。
例えば、上の図に示しました基底文字aにCombing tilde (U+0303)とCombining Diaeresis (U+0308)をつけた合成文字はUnicode4.0にはコードポイントがありません。では、この合成文字をa, U+0303, U+0308の並びから合成して表示できるかと言いますと、例えば、Microsoft Wordではできません。次図のようになってしまいます。
一番右がMicrosoft Word2003で文字列を表示したところ。(フォントはTimes New Romanを指定)
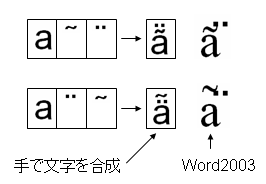
Wordは、tildeの高さの制御を行っています。もしかすると<U+0061,U+0303>という文字列をU+00E3(Latin small letter with tilde)に置換しているのかもしれません。
このように、任意の合成文字を正しく表示するには結合文字の位置を自在にあやつることができないと無理なことがわかります。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月28日
PDFと文字 (35) – 文字の合成方法
Unicodeでは基底文字と結合文字があり、基底文字と結合文字を合成することができることを説明しました。次に合成の実際について少し検討してみたいと思います。
まず、基底文字になることができるのはどんな文字で、結合文字になることができるのはどんな文字かを調べてみます。
Unicodeでは各コードポイントの文字に対応する属性のデータベースとしてUnicode Character Databaseを提供しています。
このデータベースではUnicodeでコードポイントが与えられる全ての文字を、アルファベットや漢字など通常の文字(L)、マーク(M)、数字(N)、句読点(P)、数学・通貨記号(S)、空白・改行などの分離子(Z)、その他(C)の7つの大きなカテゴリーに分けています。
結合文字はカテゴリーMに分類されます。カテゴリーMは、さらに、字幅のない記号(Mn)、字幅のある記号(Mc)、囲み記号(Me)に分類されています。囲み記号は今まで出てきませんでしたが、丸付き数字などを合成して作りだすための○記号などになるのでしょう。
さらに各コードポイントには結合クラスという数字が定義されています。基底文字は結合クラスがゼロ(0)の文字とされています。これに対してカテゴリーMの記号には、1から240の数値が与えられます。
数値の意味は次の通りとなっています。
1:上書きまたは文字の内部
2:ヌクタ(Nukta:デバナガリ文字の結合記号)
3:ひらがな・カタカナの濁音・半濁音
4:ヴィラマ(Virama:デバナガリ文字の結合記号)
10から199:固定の位置
200~240:基底文字の上下左右の位置(図)
実際に、これまでに出てきました結合文字の結合クラスを調べてみましょう。
| 文字名 | コードポイント | カテゴリ | 結合クラス |
|---|---|---|---|
| Hamza Below | U+0655 | Mn | 220 |
| Kasra | U+0650 | Mn | 32 |
| Shadda | U+0651 | Mn | 33 |
| Fatha | U+064E | Mn | 30 |
| Combining circumflex accent | U+0302 | Mn | 230 |
| Combining macron below | U+0331 | Mn | 220 |
| Combining macron low line | U+0332 | Mn | 220 |
| Combining grave accent | U+0300 | Mn | 230 |
| Combining tilde | U+0303 | Mn | 230 |
| Combining diaeresis | U+0308 | Mn | 230 |
| Combining macron | U+0304 | Mn | 230 |
| Combining macron over line | U+0305 | Mn | 230 |
| Combining accute accent | U+0301 | Mn | 230 |
| Combining cedilla | U+0327 | Mn | 202 |
| Combining ring above | U+030A | Mn | 230 |
| Devenagari vowel sign aa | U+093E | Mc | 0 |
| Devenagari vowel sign i | U+093F | Mc | 0 |
| Thai char. sara i | U+0E34 | Mn | 0 |
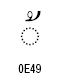
| Thai char. mai tho | U+0E49 | Mn | 107 |
実際のデータではデバナガリ文字や、タイ文字では結合文字の属性をもちながら、結合クラスがゼロになっている文字があります。
基底文字に続く結合文字の並びは、その結合クラスの値を参照して基底文字の上下左右に配置するのだな、ということが想像できますね。そうして、Unicodeの合成規則は、ラテンアルファベットとダイアクリティカルマークを対象に考案されていて、アラビア文字、タイ文字、デバナガリ文字には適用できそうもないこともなんとなく想像されます。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月27日
PDFと文字 (34) – Unicodeの結合文字
ラテンアルファベット、アラビア文字を初めとして、世界の文字にはひとつの文字の上下、あるいは左右に別の文字または記号をつけて発音の変化や声調の変化を表すものが数多くあります。
これらの文字はUnicodeでは結合文字(Combining Character)と言われています。結合文字とはプレーンテキストの文字列を表示・印刷・PDFにするとき、文字列の中で先行する基底文字にくっついて図形的にひとつの塊になる文字ということができるでしょう。
結合文字には次のようなものがあります。
・アラビア文字のHarakat: 2006年01月22日PDFと文字 (30) – アラビア文字Harakatの結合処理
・ラテンアルファベットのダイアクリティカルマーク:2006年01月26日PDFと文字 (33) – ラテンアルファベット
・キリルアルファベットのダイアクリティカルマーク:例えば、ロシア語の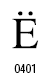 や
や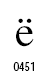 は、基底文字E、eに結合ディアレシス(ウムラウト)
は、基底文字E、eに結合ディアレシス(ウムラウト) を付加したもの。
を付加したもの。
・デバナガリ文字の母音記号:

・タイ文字の母音や声調記号など: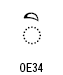
結合文字は、一般に、次のような特徴を持ちます。
(1)原則として単独では使われません。
(2)点線の円の位置には基底文字が置かれることを想定しています。
(3)文字の大きさやスタイルは基底文字と同じになります。
既に見ましたように、ラテンアルファベットでは、基底文字と結合文字を組み合わせて合成した文字についても沢山のコードポイントが与えられています。これらは合成済み文字(pre composed character)と言います。理論的には、任意の基底文字に結合文字を組み合わせる処理ができるはずですので、コードポイントが与えられている合成済み文字は、基底文字と結合文字の組み合わせの一部に過ぎません。合成済み文字は、既存の様々な文字規格に収録されていたものから、既存の文字規格との互換性のために採用されているとも言えるかもしれません。
結合文字の中には、基底文字の表示位置と同じ位置に表示されるものがあります。この属性をもつ結合文字は字幅のない記号(non spacing mark)といわれることもあります。
図 字幅のない結合文字
結合文字には字幅を取るものもあります。これは、字幅のある記号(spacing mark)です。
ところで、現在、多くのパソコンのキーボードには、チルダ、サーカムフレックスなどの結合文字と似た形をもつ文字のキーが幾つかあります。これらの文字は字幅のある文字(spacing character)とされていて、Unicodeの仕様では結合文字として扱わないとされています。対応する結合文字には別のコードポイントが与えられていますので使い分けが必要です。
| 字幅のある文字 | 類似の形の結合文字 | ||
|---|---|---|---|
| Circumflex Accent | U+005E | Combining circumflex accent | U+0302 |
| Low Line | U+005F | Combining macron below | U+0331 |
| Combining macron low line | U+0332 | ||
| Grave Accent | U+0060 | Combining grave accent | U+0300 |
| Tilde | U+007E | Combining tilde | U+0303 |
| Small Tilde | U+02DC | ||
| Diaeresis | U+00A8 | Combining diaeresis | U+0308 |
| Macron | U+00AF | Combining macron | U+0304 |
| Combining macron over line | U+0305 | ||
| Accute Accent | U+00B4 | Combining accute accent | U+0301 |
| Cedilla | U+00B8 | Combining cedilla | U+0327 |
| Degree Sign | U+00B0 | Combining ring above | U+030A |
| Ring Above | U+02DA | ||
参考資料
UnicodeV4.0仕様書 より
・ダイアクリティカルマークの幅をもつクローン (pp.167)
・3.6 結合 (pp.70-71)
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年01月26日
PDFと文字 (33) – ラテンアルファベット
Unicodeのラテンアルファベットについて検討してみます。ラテンアルファベットのベースは、英語のアルファベット26文字の大文字A~Z、小文字a~zです。ご承知のように、英語はアルファベット26文字で表記できますが、他の言語ではこれに様々な発音符(diacritical mark ダイアクリティカルマーク)をつけた文字を追加しています。
Unicodeでは、ラテン文字は次のブロックに規定されています。
・基本ラテン (Basic latin):U+0041~U+007A コードチャート
アルファベット26文字と基本的な記号類
・ラテン-1追補 (Latin-1 Suppliment):U+00C0~U+00FF コードチャート
ヨーロッパの主要言語で使用するダイアクリティカルマーク付きの文字
・ラテン拡張A (Latin Extended-A):U+0100~U+017F コードチャート
さらにその他の欧州言語で使用するラテンアルファベット系の文字
・ラテン拡張B (Latin Extended-B):U+0180~U+024F コードチャート
中欧から東欧にかけての言語で使う特別な文字など
・ラテン拡張追加 (Latin Extended Additional):U+1E00~U+1EFF コードチャート
ダイアクリティカルマーク付きの文字各種、ベトナムの文字など
上で定義されているラテンアルファベットの多くは、基本ラテン文字とダイアクリティカルマークを結合したものに対してコードポイントを与えているものです。
一方でダイアクリティカルマークマークは、単独でもコードポイントを与えられています。
・結合ダイアクリティカルマーク(Combining Diacritical Marks):U+0300~U+036F コードチャート
結合グレーブアクセント(U+0300)、結合アキュートアクセント(U+0301)、結合サーカムフレックス(U+0302)などの一般的なものを初め、他の文字の上に乗せるアルファベットのようなめったに使いそうもないような文字まで107種類のマークが網羅されています。
・結合ダイアクリティカルマーク追補(Combining Diacritical Marks Supplement):U+1DC0 - U+1DFF コードチャート
使用頻度の少ないマークが4種類、Unicode 4.1で追加されています。
ラテン文字の表示・印刷・PDF作成と言う点で注意しなければならないのは、この結合ダイアクリティカルマークおよびリガチャでしょう。
結合ダイアクリティカルマークのブロックに収録されているマークは、一般に、結合文字といわれます。先日、2006年01月22日 PDFと文字 (30) – アラビア文字Harakatでも説明しましたが、結合文字は先行する基底文字と結合されるという属性をもちます。
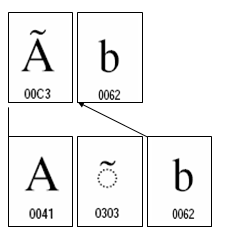
そうしますと、Unicodeのラテンのブロックで結合済の形でコードポイントを与えられている文字の多くは、基底文字と結合文字の並びで表すこともできそうです。
ひとつの例を示します。
グレイブアクセント付きラテン大文字Aは、ラテン大文字Aと結合グレイブアクセント文字の並びでも表すことができそうに思います。このような場合、結合済の文字とそれを分解した文字は、同等の扱いをするべきなのでしょうか。
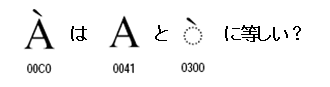
もし、同等とするならば同じ文字を2通りの符号化ができるということなのでしょうか?また、同等か同等でないかの判断をどうしたら良いのでしょうか?様々な疑問が沸きますね。これについては明日また続けて検討してみたいと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月25日
中国のOffice文書標準XML形式 UOFの動向
CICC(国際情報化協力センター)の主催で、「IT標準化技術交流セミナー」という日中関係者によるセミナが、1/18~1/20 に北京で催されました。そこで、文書フォーマットに関する分科会があり、中国の国家プロジェクトとして策定が進んでいるUOF (Uniform Office Format) のプレゼンテーションがなされたとのことです。
UOFについて以前に聞いていた話から、私は、UOFというのは中国政府が推し進めている国家的標準文書フォーマットと理解していました。しかし、今回の報告では、どうも外部文書形式を定義するだけではなく、UOFでは、文書処理系まで開発し、ユーザインタフェースの統一まで目論んでいるようです。
今回のプレゼンでは、UOFの処理系の開発技術者が出席して、UOFの処理系が動くところを実際に見ることもでき、直接いくらかの質問をすることもできたとのことです。〔興味深深〕
中国でのオフィス文書ソフトウェアのベンダは4社あり、それぞれの文書フォーマットが異なっているため、文書交換に難儀をしていた。そこで中国政府は、統一文書フォーマットを制定すべくUOFプロジェクトを立ち上げたという経緯です。この4社は独自にUOFを扱うソフトウェアを開発中であり、現在ほぼ標準的な機能は実装済みで、それぞれが同じ出力となるように試験中とのこと。Microsoft Office の 98%くらいできていると豪語したそうな。〔おおーー! OpenOffice.orgよりすごいぞ。〕
WindowsとLinuxで稼動しているとのこと、Windows版を見ることができたそうですが、見た目は、Microsoft Office と酷似していたようです。
文書フォーマットとしてはXMLであり、UOF用のスキーマが定義されているということ。UOFの出だしは次のような感じ。
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
<uof:UOF xmlns:uof="http://schemas.uof.org/cn/2003/uof"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:表="http://schemas.uof.org/cn/2003/uof-spreadsheet"
xmlns:演="http://schemas.uof.org/cn/2003/uof-slideshow"
xmlns:字="http://schemas.uof.org/cn/2003/uof-wordproc"
xmlns:图="http://schemas.uof.org/cn/2003/graph"
uof:locID="u0000" uof:version="1.0" uof:language="cn">
<uof:元数据 uof:locID="u0001">
<uof:创建者 uof:locID="u0004">user</uof:创建者>
<uof:作者 uof:locID="u0005">user</uof:作者>
<uof:创建日期 uof:locID="u0008">2006-01-19T17:24:06</uof:创建日期>
<uof:最后作者 uof:locID="u0006">user</uof:最后作者>
<uof:编辑次数 uof:locID="u0009">2</uof:编辑次数>
<uof:编辑时间 uof:locID="u0010">PT2M47S</uof:编辑时间>
<uof:用户自定义元数据集 uof:locID="u0016">
<uof:用户自定义元数据 uof:名称="信息1" uof:locID="u0017" uof:attrList="名称 类型" />
<uof:用户自定义元数据 uof:名称="信息2" uof:locID="u0017" uof:attrList="名称 类型" />
<uof:用户自定义元数据 uof:名称="信息3" uof:locID="u0017" uof:attrList="名称 类型" />
<uof:用户自定义元数据 uof:名称="信息4" uof:locID="u0017" uof:attrList="名称 类型" />
</uof:用户自定义元数据集>
<uof:页数 uof:locID="u0020">1</uof:页数>
<uof:段落数 uof:locID="u0025">1</uof:段落数>
<uof:字数 uof:locID="u0021">1</uof:字数>
<uof:对象数 uof:locID="u0026">0</uof:对象数>
</uof:元数据>
<uof:式样集 uof:locID="u0039">
<uof:字体集 uof:locID="u0040">
<uof:字体声明 uof:locID="u0041" uof:attrList="标识符 名称 字体族" uof:标识符="Tahoma" uof:名称="Tahoma" uof:字体族="Tahoma" />
<uof:字体声明 uof:locID="u0041" uof:attrList="标识符 名称 字体族" uof:标识符="宋体" uof:名称="宋体" uof:字体族="宋体" />
<uof:字体声明 uof:locID="u0041" uof:attrList="标识符 名称 字体族" uof:标识符="Times_New_Roman" uof:名称="'Times New Roman'" uof:字体族="'Times New Roman'" />
</uof:字体集>
<uof:自动编号集 uof:locID="u0042">
<字:自动编号 uof:attrList="标识符 名称 多级编号" uof:locID="t0169" 字:标识符="缺省章节大纲级别式样">
<字:级别 uof:attrList="级别值 编号对齐方式 尾随字符" uof:locID="t0159" 字:级别值="1" 字:尾随字符="none">
<字:编号格式 uof:locID="t0162">decimal</字:编号格式>
<字:编号格式表示 uof:locID="t0163">%1</字:编号格式表示>
<字:缩进 uof:attrList="左缩进绝对值 左缩进相对值 首行缩进绝对值 首行缩进相对值" uof:locID="t0165" 字:左缩进绝对值="0" 字:首行缩进绝对值="0" />
</字:级别>
【某氏コメント】
・世界的な仕様にしようとしているようだが、XMLのタグは中文である。こんなのが世界仕様になるわけがないと思うが、中国人は世界中の人が扱えると考えているのだろうか。
・文書構造とスタイルは分離していない。WordMLと同様に、このXMLはどうレンダリングされるべきかが決まっている。
・ルートタグに uof:language="cn" という属性がある。 languageだから、当然ISO-639の言語コードでしかるべきだが、cn はISO-3166の中国の国名コードだ。ちなみに、中国語の言語コードは zh または zho である。
・すべてのUnicodeを扱えると言っているが、表現できる文書には基本的に中文のことしか考えていない。現在の版でできるのは、中文の他には日本語と韓国語くらいであるが、日本語の禁則処理ができるかは疑問である。英文にしても、ちゃんと組めるとはお世辞にも言えない。
(以下省略)
〔世界的な仕様ですか?なにかの間違いじゃないの?でも、漢字タグが世界標準仕様になったらって、想像するだけでも愉快だよね。〕
※文中〔 〕内は、私の感想。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月24日
PDFと文字 (32) – 文字コードと情報交換を考える
日本のJIS規格に関する議論、さらにUnicodeについても議論でも、字の形と文字コードが1対1になることを暗黙に想定した議論が多いように思います。しかし、アラビア文字はその典型的な例ですが、文字コードと画面表示・印刷される字形は1対1になっていません。
この仕組みを次のような簡単な絵で表してみました。
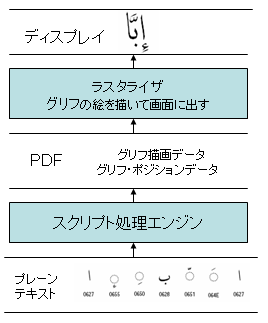
この図の中の言葉の意味は次の通りです。
・プレーンテキストとは、2005年12月15日のPDFと文字(4) – 文字の取り扱いで述べました、飾りのない本文文字にあたります。
・グリフ描画データとは文字の形を描画するためのデータまたはプログラムです。2006年01月13日PDFと文字(22) – グリフとグリフセットあたりをご覧ください。グリフポジションデータとは、そのグリフをどの位置に描画するか、というデータと理解してください。PDFの中には、かなり抽象化して言いますと、テキストを表示・印刷するためのグリフ描画データとグリフポジションデータが収容されているということができます。
さて、コンピュータで電子ドキュメントを情報交換する場合、まず、どのレベルで情報交換をするか、ということを考えなければならないでしょう。上の図で言いますと、プレーンテキストを情報交換するか、それとも、例えば、PDFのレベルで交換するかということになります。両方セットで交換することももちろん可能でしょう。
プレーンテキストレベルで交換した場合、受け手の側に、送り手と同じスクリプト処理エンジンが必要となります。具体的に言いますと、例えばWindowsではUniscribeというスクリプト処理エンジンがあり、これがUnicodeのテキスト文字列を受け取って正しいグリフの列や位置を割り出す処理をしているようです。Linuxなどでこのプレーンテキストを表示しようとしますと、同等の機能をもつエンジンを使わないと正しく表示できないことになります。携帯電話などで読もうとするときも同じです。
このように見ますと、プレーンテキストレベルでの情報交換は必ずしも最適解ではないケースが多いだろうと思います。
これに対して、PDFのレベルであれば、スクリプト処理エンジンの出したデータを交換するわけですから、オリジナルの情報を加工するとき、例えば、WindowsでUniscribeを使ったとしても、受け手には同じ機能は不要です。
このように、文字コードと画面表示・印刷される字形とを分離させて考えることは、漢字の場合にも有効なように思います。
漢字については、2000字も使えれば、一般的のコミュニケーションは可能でしょうし、さらに、5000字を使えれば相当なもの。1万文字を使いこなせる人は日本にも殆どいないでしょう。このような現実に対して、7万を超える文字にひとつづつ情報交換用のコードポイントを与えても情報交換という意味ではあまり意味がないように思います。どうしても文字の形状を交換したいのであればグリフデータを交換することを考えるのも有益だろうと思います。
※参考資料
Uniscribeについてはこちらにも説明があります。
Uniscribe
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月23日
PDFと文字 (31) – リガチャ
アラビア文字のもう一つの特徴はリガチャ(合字)です。結合文字は基底文字を主とすると、その基底文字の上・下に付く従たる文字と言って良いと思います。
これに対して、リガチャは特定の二つ以上の文字が並んだときに、二つの文字のグリフを並べる代わりに別のグリフに置き換えるものです。アラビア文字ではラムとアレフの2文字が連続したときは、リガチャにするのが必須です。
ラテンアルファベットにもリガチャはありますが、アラビア文字のリガチャは文脈依存のグリフとの組み合わせになるため複雑です。
・ラムとアレフのコードポイント
| 名称 | コードポイント |
|---|---|
| ラム | 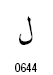
|
| アレフ |  |
ラムは、文脈依存のグリフを4つもちます。これに対して、アレフは常に単独形となります。この二つの文字が連続する場合、リガチャがなければラムの左にアレフが接続したU型のカーブをもつ文字になりそうなものです。(あるいは、ふたつの文字はつながらない?)しかし、リガチャにより別の形になるとされています。
(次の図を参照)。

※フォントは、Arabic Typesettingを指定。実際のところはアレフは次の文字(左)に接続しませんので、ラムとアレフのリガチャは、単独形と右接形(FinalForm)しかもたない、というべきかもしれません。また、上の図でリガチャなしは無理やり作成したもので正しくないものですので、ご注意ください。
PDFと文字 (28) – アラビア文字のプログラム処理の(1)文字の結合(Cursive Joining)の項に出てきましたが、Unicodeにはゼロ幅接合子(Zero Width Joiner:U+200D)、ゼロ幅非接合子(Zero Width Non-Joiner:U+200C)という文字があり、これを使うことで擬似的に接続状態を制御して文脈依存のグリフの切り替えを行うことができます。
例えば、上のリガチャの図では対象文字の接続する側にU+200D、接続しない側にU+200Cを配置しています。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月22日
PDFと文字 (30) – アラビア文字Harakatの結合処理
さて、アラビア文字の検討で、1月20日アラビア文字のプログラム処理でHarakat(母音記号)とリガチャが出てきました。この二つについて、Unicodeによる取り扱いをもう少し検討してみます。
まず、Harakatについて検討します。次の画像をご覧ください。

これは、聖典クルアーンの一部ですが、文字の上と下に記号が付加されています。アラビア語では、原則として子音を文字として筆記する方式です。ビジネス文書や操作説明書などではそれで十分なようですが、クルアーンなどでは読み方を明確にするため、母音記号や子音の発音のバリエーションを示すための記号類を付加することがあります。
このオプションとして使われる記号類を総称してHarakatと言います。上の例では、右から次のような文字を見ることができます。
| 名称 | 役割 | コードポイントと文字 |
|---|---|---|
| Hamza Below | 声門閉鎖音を表す |  |
| Kasra | 短母音iを表す | 
|
| Shadda | 子音の連続(重子音)を表す |  |
| Fatha | 短母音aを表す |  |
上のような文字は、一般に結合文字(Combining Character)と呼ばれています。表示したり、印刷・PDF作成したりするときは先行する基底文字の上または下に配置します。
そうしますと、先頭(右)からUnicodeの文字列として表しますと、次のようになるでしょう。
A. 
最初の2文字を結合した文字は、結合した形のコードポイントも与えられていますので、次のようにあらわすこともできます。
B. 
このように、Unicodeでは基底文字と結合文字の組によっては、結合済の形でコードポイントを与えれられているものもあります。その場合、基底文字と結合文字を分離したものと同等になります。すなわち、上のAとBの文字列は同等として扱わねばなりません。
上の文字列を実際に表示・PDF化しますと次のようになります。
![]()
※Arabic Typesettingフォントを指定
※ご注意
私は、アラビア語はわかりませんので、上の説明の中でアラビア語に関する部分の説明は、必ずしも正確でないかもしれません。ここでは、Unicodeのアラビア文字でどうやってアラビア語を表すかという例としてご理解ください。また、誤りがありましたらご指摘いただければありがたいです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月21日
PDFと文字 (29) – アラビア文字表示形
Unicodeには、アラビア文字表示形のブロックが二つあります。
表示形A(Form-A):U+FB50~U+FDFF
表示形B(Form-B):U+FE70~U+FEFF
なぜ、このような二つのブロックが用意されているのでしょうか?
まず、表示形Bを見ますと、ここにはアラビア文字が140種類あります。
先頭のU+FE70~U+FE7Fには、1文字(U+FE73)を除いて、Harakat(母音記号など)を基底文字と分離した形で表示・印刷する形式、およびHarakatをカシダ(Tatweel:U+0640)の上下に配置した形式の文字があります。
ちなみに、カシダとはアラビア文字の単語を左右に伸ばすときに接合部を引き伸ばすために挿入する横線です。下の例をご覧ください。
・単語にカシダを挿入してない状態

・単語にカシダを挿入した状態

アラビア語の文章を両端揃え(Justification)するときは、単語にカシダを挿入して単語を横に伸ばします。カシダは文字と文字の間に挿入するのですが、どこにいくつのカシダを挿入するべきかは分かっていません。Unicode仕様書にはフォントと可視化ソフトに依存する、とのみ書いてあります。このあたり、まだUnicodeの仕様書を書いている人にもきっと分かっていないのでしょうね。
ご存知の方がいらっしゃいましたら、お教えいただきたいと思います。
次のU+FE76からU+FEF4の区間は、アラビア文字の基本形(U+0621~U+064A)に対して、単独形、左接形、両接形、右接形を全て登録しています。その後ろのU+FEF5からU+FEFCは、ラムとアレフのリガチャのいろいろな形が載っています。すなわち、この部分は、昨日説明しましたプログラムによるCursive接続とリガチャの処理を施したあとのグリフ(以下では、これを文脈依存のグリフと言います)を登録しているわけです。
ここの文字は過去の規格との互換用として用意しているとされています。通常は、適切なグリフをプログラムで選択するべきものです。
一方、表示形A(U+FB50~U+FDFF)の範囲を見てみます。こちらはまさにアラビア文字の符号化の難しさを象徴している部分です。
・ペルシャ語、ウルドゥ語、シンディ語などで拡張された文字に対する文脈依存のグリフ:U+FB50~U+FBB1
・中央アジアの言語で拡張された文字に対する文脈依存のグリフ:U+FBD3~U+FBE9
・2文字のリガチャ:U+FBEA~U+FD3D
ラムとアレフの2文字が連続した場合はリガチャが必須になります。しかし、それ以外の2文字にもオプションのリガチャが使えます。ここではそれらのリガチャのグリフにコードポイントを与えています。
・3文字のリガチャ:U+FD50~U+FDC7
3文字の並びからできるリガチャを文字として扱っているものです。ちなみに、ラテンアルファベットの3文字のリガチャについてはffi(U+FB03)、ffl(U+FB04)の二つにコードポイントが与えられています。
最後の方では、ほとんどロゴマークといってよさそうなリガチャにまでコードポイントを与えています。
Arabic Ligature Jallajalalouhou:U+FDFB 
これは、U+062C, U+0644, U+0020(空白), U+062C, U+0644, U+0627, U+0644, U+0647の、実に8文字の並びからできるリガチャを文字として扱っていることになります。
現在の時点で、このブロックをすべて実装したものはない、とされています。
(Unicode仕様書V4.0 p.204)
※参考資料
リガチャ(合字)については、以下をご参照ください。
日本語:合字(未完成)
英語:Ligature
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月20日
PDFと文字 (28) – アラビア文字のプログラム処理
アラビア文字はアラビア語以外の表記に使われるようになる際、文字が追加されています。Unicodeのアラビア文字ブロックには、アラビア語以外の言語用に追加されたアラビア文字も含まれています。
拡張アラビア文字(Extended Arabic Letters)という見出し付きで、ペルシャ語(イラン)、ウルドゥ語(パキスタン)、パシュトゥー語(アフガニスタンほか)、シンディー語(インド)など各種の言語用に追加された文字が規定されています。
アラビア文字を表示・印刷・PDFに処理するプログラムは、単に文字コードからグリフに対応つけるだけではなく、幾つかの必須処理を行わねばなりません。
次に簡単に紹介しておきます。
(1) 文字の結合(Cursive Joining)
アラビア文字は接合に関して次の6つのクラスになります。
・接合しない文字:ゼロ幅非接合子(Zero Width Non-Joiner U+200C)など
・右接形のみ:印刷の際に右の文字にのみ接合する文字
・両接形:両方の文字に接合する文字
・接合を起こす文字:ゼロ幅接合子(Zero Width Joiner U+200D)など
・接合に対して影響を与えない文字
※左節形しかないものはありません。
プログラムはアラビア文字自身がどのクラスに属するか、及び、左右の文字のクラスを見て、その文字の表示・印刷・PDF作成用のグリフを選択します。
(2) Harakatの処理
アラビア文字にはHarakat(母音記号など)があります。Harakatは基底になる文字の上、または下につけて発音を表します。Unicodeでは、Harakatに基底の文字とは別のコードポイントを与えていますので、表示・印刷・PDF作成では、プログラムで基底文字と結合し、Harakatを基底文字の上あるいは下に配置しなければなりません。
(3) リガチャの処理
アラビア文字を筆記するには、必須とされている2文字のリガチャがあります。必須リガチャについては、単に接合させるだけではなく、2文字を組みにした新しいグリフに入れ替えなけばなりません。
アラビア文字を表示したり、印刷・PDF作成では、文字のコードポイントから単純に該当するグリフを取って来るだけではなく、プログラムで(1)から(3)の処理を行わねばなりません。そのためのロジックは、昔ならば、各アプリケーションのメーカが研究したものでしょう。ロジックをゼロから研究するにはアラビア語を理解して、アラビア文字を独自に研究する必要があります。
Unicodeの仕様書に標準のアルゴリズムが掲載されていることで、これを忠実に実装すれば、アラビア語を全然知らなくても、最低限のアラビア文字処理ができることになったわけです。
アンテナハウスでは、XSL-FOに準拠する組版ソフトXSL Formatterを開発・販売しています。XSL Formatterは、2002年にアラビア文字の組版・PDF化を、この分野の製品としては世界で始めて実装しました。これにより、自動車、OA機器などのアラビア語などのマニュアル作成用途として、メーカやローカリゼーションの関連の多数の会社に採用していただくことができました。XSL Formatterの成功のきっかけは、アラビア語組版を、世界で一番最初に実現したことにあるともいえます。
その後、他のXSL-FO組版エンジンのメーカもアラビア文字組版を実現してきているようです。誰でもできるわけですから、その分、ソフトウエアのグローバルな競争も厳しくなるわけですね。
※参考資料
Unicode 4.1.0 Middle Eastern Scripts
Unicode4.0仕様書pp.199~202
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月19日
PDFと文字 (27) – アラビア文字の扱い
アラビア文字がアラブ文化圏の広がりとともに、様々な国で使われていることについては、12月13日に簡単に触れました。
ここでは、Unicodeでアラビア文字がどのように扱われているかをまとめてみましょう。
アラビア文字が定義されているブロックは、アラビア文字(U+0600~U+06FF)、アラビア文字追補(U+0750~U+076D)、アラビア文字表示形-A (U+FB50~U+FDFF)、アラビア文字表示形-B (U+FE70~U+FEFF)の3ブロックになります。これらについて検討します。
アラビア文字の書法は印刷でもcursive、日本語でいう連綿体(書道で、草書や仮名の各字が次々に連続して書かれている書体)になります。このため多くの文字は、単語の中で出現する位置によって形 (form) が変わり、単独形、左接形、両接形、右接形の4つの形をもつことになります。
次の図の上は、全部、文字を単独形で並べたもの、下は、単語の中の文字を接続させたもの(通常)です。

アラビア文字:U+0600~U+06FF コードチャート
ISO/IEC 8859-6 (Part 6 Latin/Arabic Alphabet) 規格と同じ順序で文字を並べています。但し、Unicode独自で追加した文字もあります。掲載している文字の形は単独形のみです。
アラビア語の表記では、主にフランス語系統の句読点や括弧類を使います。括弧類はラテンアルファベット用のものを鏡に写した像の形になります。形が大きく違っているものは独自のコードポイントが与えられています。アラビア文字ブロックにコードポイントのある句読点は次のものです。これ以外の句読点はラテン文字と共用になります。
| 名称 | コードポイント | 形 |
|---|---|---|
| Arabic Comma | U+060C |  |
| Arabic Date Separator | U+060D | 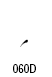 |
| Arabic Semicolon | U+061B | 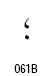 |
| Arabic Question Mark | U+061F | 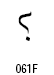 |
| Arabic Percent Sign | U+066A |  |
| Arabic Decimal Separator | U+066B | 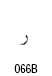 |
| Arabic Thousands Separator | U+066C | 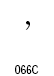 |
| Arabic Five Pointed Star | U+066D |  |
| Arabic Full Stop (ウルドゥ語用) | U+06D4 | 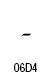 |
アラビア文字の数字は2種類が定義されています。
| 数字の名称 | Arabic Indic | Eastern Arabic-Indic |
|---|---|---|
| コードポイント | U+0660~U+0669 | U+06F0~U+06F9 |
| 0 |  |

|
| 1 |  |

|
| 2 | 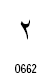 |
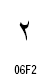
|
| 3 | 
|
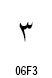 |
| 4 | 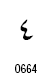
|
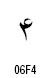 |
| 5 |  |
 |
| 6 | 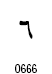
|
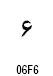 |
| 7 | 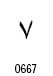
|
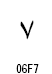
|
| 8 | 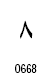
|

|
| 9 |  |
 |
【参考資料】
・"Arabic Typography, a comprehensive sourcebook" (Huda Smitshujizen AbFares, Saqi Books, 2001, ISBN0863563473(pb))
・第10回多言語組版研究会配布資料(PDF)
・多言語組版研究会ホームページ
・アラビア系文字
・「アラビア系文字の基礎知識」
なお、アラビア文字は右から左に書きますが、数字は左から右に書きます。また、ラテン文字用の句読点、あるいは数字を共用します。右から書き表す文字や記号と、左から書き表す文字や記号が混在すると、画面表示や印刷時の、文字の進行方向を決定するのが複雑になります。Microsoft Word のようなWYSIWYGのワープロを使って書くとわけがわからなくなってしまうようです。このような表記の問題については、別途、改めて検討したいと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月18日
PDFと文字(26) – ハングルの扱い
漢字の場合は、ひとつの字体にひとつの文字コードを与えるのが原則ですが、そう単純ではないしくみの文字も世界には沢山あります。お隣の韓国・北朝鮮の言語である朝鮮語を書くための文字ハングルもそのひとつです。
ハングルは、李氏朝鮮の世宗大王が15世紀に学者の協力を得て定めた文字とされていて、比較的新しいこともあり、科学的な発想による仕組みをもつ文字と言われています。
ハングルでは、頭子音(初声)、母音(中声)、終子音(終声)を表す3つの字母(Jamo)を組み立てて音節文字を作ります。頭子音は19種類、母音は21種類、終子音は27種類の形があります。但し、頭子音と終子音には同じ形状のものがあります。
音節文字の数は、理論的には次の(1)と(2)の合計11,172種類となります。
(1)頭子音と母音で組み立てる文字:19×21=399種類
(2)頭子音、母音、終子音の3つを組み立てる文字:19×21×27=10773種類
ハングル文字の符号化方法には、字母を符号化する方法と、組み立て済の文字を符号化する方法の2種類があります。韓国の国内文字規格には、この両方の方法に基づくものがあり、それぞれ、かなり頻繁に改訂されたため、大変分かりにくくなっています。
Unicodeにも、2種類の符号化方式を採用したものが盛り込まれていて、それぞれ、コードチャートの次のブロックに定義されています。ハングルを処理するプログラムは両方の符号化方式を正しく処理できないといけないようです。
・ハングル字母(Jamo):U+1100~U+11FF
組み立て前の字母を登録しています。コードチャートを見ますと、頭子音が90種類、母音が68種類、終子音が82種類もありますね。ここの字母は、UnicodeV4.0 仕様書の3.12節に組み立てる方法が説明されています。この範囲のハングル文字コードの並びが表れた時は、それを表示したり、印刷、PDF化するときは、その並びを判断して音節文字に置き換える必要があります。
・ハングルの互換字母(Compatibility Jamo)全角形:U+3130~U+318F
韓国の文字規格 KS X1001:1998 のハングル字母に準拠する全角形94種の文字が定義されています。このブロックの互換字母は組み立てなくても良いようです。
・ハングルの互換字母半角形:U+FFA0~U+FFDF
ここに半角形の互換字母もあります。
・ハングル音節:U+AC00~U+DA73
韓国の文字規格KS C 5601-1992から収録した組み立て済の音節文字が11,172個登録されています。これをJohab文字セットと言います。これらは、ハングル字母の並びから対応つけることができます。対応付けのロジックは、Unicode仕様書3.12節にあります。また、プログラムで字母を組み立てて、音節文字の字形を作ることもできます。
但し、古ハングル文字にはJohab文字セットにないものもあり、その場合は、ハングル字母の並びで表すしかないようです。この場合は、プログラムで音節文字の字形を作り出すことになるのでしょう。
【参考資料】
「文字符号の歴史 アジア編」(三上 喜貴著、共立出版、2002年、ISBN4-320-12040-X )pp.165~174
ハングル フリー百科事典『ウィキペディア(Wikipedia)』
投票をお願いいたします
投稿者 koba : 08:00 | コメント (7) | トラックバック
2006年01月17日
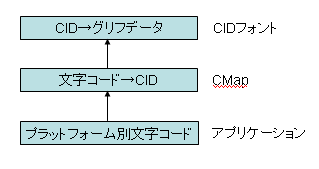
PDFと文字 (25) – CMapで文字コードからCIDへ変換
Adobe-Japan1、Adobe-GB1などのグリフセットでは、ひとつひとつのグリフにCIDという番号が付いていることは説明しました。CIDフォント・ファイルには、文字を画面表示したり印刷するためのグリフ・データを収容しています。フォント・ファイルに収容されているグリフ・データにアクセスするときはCID番号を使わなければなりません。
Windows、LinuxやマッキントッシュなどのOSや、OSの上で動くアプリケーションは、Unicode、または機種専用の文字コードを使ってテキストを処理します。一方、CIDフォントにあるグリフを使ってその文字を表示・印刷するには、文字コードからCIDに変換しなければなりません。
この文字コードからCIDへの変換を定義するのがCMapです。
図 CMapで文字コードからCIDへ変換
アドビシステムズはAdobe-Japan1、Adobe-GB1などのグリフセット毎に多数のCMapファイルを提供しています。古いCMapにはNECのPC、富士通のPC、Windows3.1、マッキントッシュなど機種依存文字コードからCIDへの変換用が沢山あります。しかし、最近のCMapはUnicodeからCIDへの変換用が中心になっています。
例えばAdobe-Japan1用の比較的新しいCMapには次のようなものがあります。
| CMap名称 | 内容 |
|---|---|
| UniJIS-UTF8-H | Unicode 3.2 (UTF-8) からCID |
| UniJIS-UTF8-V | UniJIS-UTF8-Hの縦書用 |
| UniJIS-UTF16-H | Unicode 3.2 (UTF-16) からCID |
| UniJIS-UTF16-V | UniJIS-UTF16-Hの縦書用 |
| UniJIS-UTF32-H | Unicode 3.2 (UTF-32) からCID |
| UniJIS-UTF32-V | UniJIS-UTF32-Hの縦書用 |
| UniJISX0213-UTF32-H | Unicode 3.2 (UTF-32) からCID Mac OS X Version 10.2互換 |
| UniJISX0213-UTF32-V | UniJISX0213-UTF32-Hの縦書用 |
各CMapファイルには、横書用(-H)と縦書用(-V)の2種類があることに注意してください。これは次のような仕組みです。
(1)文字によっては横書と縦書で表示・印刷用の字形が異なるものがあります。
(2)グリフセットには、これらの文字に相当するグリフには横書用と縦書用の2種類が用意されています。(次の例)
横書用グリフの例: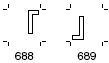
縦書用グリフの例:
※Adobe-Japan1-6 Character Collection for CID-Keyed Fonts p. 12, p. 76
末尾に-Hの付くCMapを使うと、文字コードから横書用グリフのCID番号に変換することになり、同-Vの付くCMapを使うと、縦書用グリフのCID番号に変換することになります。
OSやアプリケーションの文字コードを内部コードと言うと、CID番号の付いたグリフは表示層と言えます。この内部コードと表示層を分離して、CMapで仲立ちをさせていることになります。この仕組みでフォントをプラットフォームの文字コードから独立にした、ということがCIDフォントの意義ということになります。
但し、CMap方式で入力値として指定できるのは単一コードになります。縦書と横書に対してCMapを切り替えることで、単一の入力コードからそれぞれ異なるグリフを得るCIDフォント方式は、漢字やかなのような単純な記法の文字を使う日本語や中国語などしか適用できないでしょう。例えばアラビア文字や南インド文字、あるいはラテン文字の結合やリガチャには対処し難いように思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月16日
PDFと文字 (24) – Adobe-GB1, Adobe-CNS1, Adobe-Korea1
アドビシステムズのテクニカル・ノートでは、Adobe-Japan1の他に、Adobe-GB1, Adobe-CNS1, Adobe-Korea1の3つのグリフセットが公開されています。これらをざっと見ておきます。
Adobe-GB1は、中国の簡体字用のグリフセットで、GB 2312-80、GB 1988-89、GB/T 12345-90、GB 13000.1-93、GB 18030-2000用のグリフ29,063種類を含んでいます。
| 領域 | CID範囲 | Adobe-GB1 | 説明 |
|---|---|---|---|
| 追補0 | 0~7716 (7,717個) | Adobe-GB1-0 | GB 2312-80、GB1988-89文字規格用のグリフ。GB/T 12345-90で規定する縦書グリフを含む |
| 追補1 | 7717~9896 (2,180個) | Adobe-GB1-1 | GB/T 12345-90のグリフ。Adobe-GB1-0に繁体字を追加する。 |
| 追補2 | 9897~22126 (12,230個) | Adobe-GB1-2 | GBKとUnicodeV2.1の20,902漢字をサポートするためのグリフ |
| 追補3 | 22127~22352 (226個) | Adobe-GB1-3 | 半角とプロポーショナルグリフの回転済のもの。 |
| 追補4 | 22353~29063 (6,711個) | Adobe-GB1-4 | 大部分は、UnicodeV3.0のCJK統合漢字拡張A用 |
※Adobe-GB1-4 Character Collection for CID-Keyed Fonts 2000年11月30日
Adobe-CNS1は、台湾の繁体字用のグリフセットで、主にBig-5とCNS 11643-1992規格をサポートするためのものです。一部に香港用の文字を含んでいます。
| 領域 | CID範囲 | Adobe-CN1 | 説明 |
|---|---|---|---|
| 追補0 | 0~14098 (14,099個) | Adobe-CN1-0 | Big-5とCNS 11643-1992の1面、2面、およびBig-5のETen拡張用 |
| 追補1 | 14099~17407 (3,309個) | Adobe-CN1-1 | 香港政庁の漢字文字セット、モノタイプ、ダイナラブ社の文字の一部 |
| 追補2 | 17408~17600 (193個) | Adobe-CN1-2 | 半角とプロポーショナルグリフの回転済のもの。 |
| 追補3 | 17601~18845 (1,245個) | Adobe-CN1-3 | 香港の追加文字セット |
| 追補4 | 18846~18964 (119個) | Adobe-CN1-3 | 香港の追加文字セット(追加) |
※Adobe-CNS1-4 Character Collection for CID-Keyed Fonts 2003年5月27日
Adobe-Korea1は、韓国のKS X 1001:1992 (旧KS C 5601-1992)、KS X 1003:1992 (旧KS C 5636-1993)をサポートするためのグリフセットです。
| 領域 | CID範囲 | Adobe-Korea1 | 説明 |
|---|---|---|---|
| 追補0 | 0~9332 (9,333個) | Adobe-Korea1-0 | KS X 1001:1992、KS X 1003:1993とアップルのマッキントッシュ用の拡張 |
| 追補1 | 9333~18154 (8,822個) | Adobe-Korea1-1 | KS X 1001:1992のJohabとWindows 95の統合ハングルコード拡張 (UHC) |
| 追補2 | 18155~18351 (197個) | Adobe-Korea1-2 | 半角とプロポーショナルグリフの回転済のもの。 |
※Adobe-Korea1-2 Character Collection for CID-Keyed Fonts 2003年5月27日
しかし、これらはどうも古いですね。Adobe-GB1なんて2000年の日付になっています。それに肝心のGB18030がカバーされていません。Adobe-CN1、Adobe-Korea1いづれも2003年5月です。これに対して、Adobe-Japan1は2004年6月なので比較的新しいですが。中国や台湾ではアドビシステムズはあまりまじめにやってないのでしょうか?そんなことはないと思いますが。分かりません。
【2006/5/3 追記】
GB18030をカバーしてないんじゃないの?と書いて、ちょっと物議をかもしてしまったようなので削除しておきます。どうして、カバーしてないと書いたか忘れてしまいましたが、多分、間違いでしょう。Adobe-GB1で規定されている字形の総数(29,063)は、GB18030:2000で字形が記述されている文字数(28,522)よりは多いようです。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年01月15日
PDFと文字 (23) – Adobe-Japan1
Adobe-Japan1とは日本語表記に使う文字のグリフを集めて、各グリフを識別するCIDという認識番号を付けたものです。
0から6までの版があり、版数が大きくなるに従い、新しいグリフが追加されます。最新のAdobe-Japan1-6には、合計23,058種類のグリフを集めています。
各版に追加されたグリフの概要は次の表の通りです。
| 領域 | CID範囲 | Adobe-Japan1のセット | 説明 |
|---|---|---|---|
| セクション3 | 0~8283 | Adobe-Japan1-0 | JIS X 0208 1978と1983、JIS X 0201-1997、アップル、富士通、NECの文字セット。 |
| セクション4 | 8284~8358 | セクション3~4でAdobe-Japan1-1になる | マッキントッシュの漢字Talk7.1用文字、JIS X0208-1990、富士通とNECが追加したグリフなど。 |
| セクション5 | 8359-8719 | セクション3~5でAdobe-Japan1-2になる | Windows3.1J用のグリフを追加。 |
| セクション6 | 8720~9353 | セクション3~6でAdobe-Japan1-3になる | 半角とプロポーショナルグリフの回転済のもの。 |
| セクション7 | 9354~15443 | セクション3~7でAdobe-Japan1-4になる | 専門的、商業印刷に使うグリフを追加 |
| セクション8 | 15444~20316 | セクション3~8でAdobe-Japan1-5になる | JIS X 0213:2004標準を完全にサポートするためのグリフを追加 |
| セクション9 | 20317~23057 | セクション3~9でAdobe-Japan1-6になる | JIS X 0212-1990、共同通信のU-PRESS文字集合をサポートするためのグリフを追加 |
※Adobe-Japan1-6 Character Collections for CID Keyed Fonts, Technical Note #5078, 11 June 2004 (PDF)
Adobe-Japan1-6の仕様書の名称は、「Adobe-Japan1-6 Character Collection for CID Keyed Fonts」と言います。名前から想像すると、もともとCIDフォントの開発者向けに用意されたものと思います。しかし、CIDフォントは既に古いものになり、新しいOpenTypeフォントにとって変わられつつあります。従って、現時点でのAdobe-Japan1の役割は、OpenTypeフォント開発者向けのグリフ一覧表ということになります。
なお、Adobe-Japan2というJIS X 0212用グリフセットもありましたが、Adobe-Japan1-6のセクション9に吸収されて廃止されました。
Adobe-Japan1は、例えば、セクション3に90度回転済の半角文字のグリフが収容されていたり、セクション4にも回転済みのグリフが収容されています。これらはOpenTypeフォントにおける縦書用のグリフを提供するものです。
また、セクション7には商業印刷用の漢字と異形字(kanji variants)が2,124個収容されています。
※Adobe-Japan1-6 Character Collection for CID-Keyed Fonts p.96
これらの回転済みのグリフはもちろんのこと、漢字の異形字にはJISやUnicodeで規定されていないものを含んでいますが、これらはOpenTypeフォントでないと使うことができないとされています。
なお、小形克宏の「文字の海、ビットの舟」――文字コードが私たちに問いかけるもの 特別編26では、「まず「文字の形」から集め、次に文字コード規格と対応づける」と述べていますが、Adobe-Japan1は、まさしく文字の形をあつめたものに相当することになります。このようにアドビシステムズは、各種の国内標準規格や、主要なメーカ、ユーザが必要とする文字のグリフを集めてこれにCIDという番号をつけてフォントの開発者向けに提供しているわけです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年01月14日
「書けまっせPDF」 vs 「やさしくPDFへ文字入力」比較
アンテナハウスはPDFへ文字や図形を自由に記入するソフト「書けまっせPDF」を、1月17日より出荷開始します。
このソフトは、官公庁や企業の申請書のような固定の様式がPDFで配布されている場合、それに直接、テキストや図形を書き込んで新しいPDFを作成するソフトです。PDFをワープロの雛形文書として使えることを目標としています。
AcrobatなどPDFにコメントや注釈を書き込むソフトはいくつか販売されています。しかし、「書けまっせPDF」で記入するのはコメントや注釈ではなく、PDF本文のテキストやデータとなります。
類似の製品としては、メディアドライブより「やさしくPDFへ文字入力」シリーズが出ています。
次の表に「書けまっせPDF」と「やさしくPDFへ文字入力」シリーズの機能を比較をご紹介します。
この2つの製品の一番大きな違いは、オリジナルの帳票PDFの取り扱いにあります。
「書けまっせPDF」は、オリジナルの帳票PDFを独自のビューアで表示しています。そして、編集したPDFを保存するときには、オリジナルの帳票PDFのコピーを、入力したデータの背景として使用します。
「やさしくPDFへ文字入力」シリーズは、オリジナルの帳票をコンバータでPDF画像に変換します。この画像化した帳票の上に、テキストや絵を記入する方式です。このため編集したPDFを保存したときは、元の帳票が画像になってしまいます。「やさしくPDFへ文字入力」は、OCR技術を活用したもののように思います。
| 製品毎の機能 | 書けまっせPDF | やさしくPDFへ文字入力 | ||
| 編集・校正用 v.3.0 | フォーム入力用 v.3.0 | PRO v.5.0 | ||
| PDF表示 | 独自Viewerで表示。 | 画像化して表示。 | ||
| 読込時のパスワード解除 | ○ | ○ | ○ | ○ |
| 複数ページ編集 | ○ | ○ | ○ | ○ |
| サムネイル表示 | ○ | ○ | ○ | ○ |
| テキスト入力 | ○ | ○ | ○ | ○ |
| 縦書き指定 | × | ○ | ○ | ○ |
| 入力枠の自動作成 | ユーザが任意に指定した矩形領域のみ検索 | × | フィールドの自動作成機能により、ページ内のすべての矩形領域を検索 | |
| フォント指定 | ○ | ○ | ○ | ○ |
| 修飾(強調/斜体/下線) | ○ | ○ | ○ ¥、$マーク、カンマの追加・削除可 | ○ ¥、$マーク、カンマの追加・削除可 |
| 文字間行間指定 | 行間のみ可能 | 文字揃えのみ可 | ○Proと同等 | ○ フィールド内を指定した行数、桁数で分割する |
| 画像挿入(bmp/jpg/png) | ○ | ○ | ○ | ○ (TIFFも可能) |
| 印刷 | ○ | ○ | ○ | ○ |
| メールに添付 | ○ | × | × | × |
| PDF保存 | ○ | PDF保存した場合、元のPDFは画像化されているため、テキストの抽出等ができない。 但し、透明テキスト付きPDF保存ならテキスト抽出も可能。透明テキストの精度はOCR精度に依存。 | PDF保存した場合、元のPDFは画像化されているため、テキストの抽出等ができない。 但し、透明テキスト付きPDF保存ならテキスト抽出も可能。透明テキストの精度はOCR精度に依存。 PDFフォームの保存が可能 | |
| 円/四角の描画 | ○ | ○ | ○ | ○ |
| PDFへセキュリティ設定 | ○ | × | × | × |
| アノテーション | × | フィールド/日付/マーカー/矢印/URL/図形/画像/ファイル添付/スタンプ/電子印鑑/ページリンクを添付可能 | フィールド/日付/図形/画像/電子印鑑のみ添付可能 | フィールド/日付/マーカー/矢印/URL/図形/画像/ファイル添付/スタンプ/電子印鑑/ページリンクを添付可能 |
| データ差し込み | × | × | ○(Excel、Accessのデータをクリップボード経由で取り込み可能) | CSV、TXTの読み込み可、Excel、Accessのデータをクリップボード経由で取り込み可能 |
| PDF以外の読み込み形式 | × | BMP/ TIF/ JPG/ PNG | ||
| スキャナ出力取り込み | × | ×(画像とPDFのみ) | ○ | ○ |
| 表示の回転・補正 | × | ○ | ○ | ○ |
| データのみ印刷 | × | × | ○ | ○ |
| PDF一括処理(作成,分割・結合,セキュリティ設定解除) | × | 開いているファイルに追加で読み込むことのみ可能 | ||
| PDF生成ドライバ添付 | ○ | ○ | ○ | ○ |
| OCR機能 | × | ○透明テキストの作成にOCR機能を使用する | ||
| 出力可能な形式 | 独自ファイル形式/PDF (元のPDFを透かしとして出力) | 独自ファイル形式/ BMP/ TIF/ JPG/ PNG/ PDF | 独自ファイル形式/ BMP/ TIF/ JPG/ PNG/ PDF | 独自ファイル形式/ CSV/ BMP/ TIF/ JPG/ PNG/ PDF |
| 透明テキスト付きPDF保存 | × | ○ | ○ | ○ |
| フォーム付きPDF保存 | × | × | × | ○ |
| しおりを表示してのページ移動 | ○ | × | × | × |
| データトレー | ○ | × | × | × |
| 定価(税込) | 7,980円 | 5,229円 | 5,229円 | 13,440円 |
先行製品「やさしくPDFへ文字入力」を追い越すように頑張りたいと思っています。「書けまっせPDF」をよろしくお願いします。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年01月13日
PDFと文字(22) – グリフとグリフセット
符号化文字集合とは別の観点から文字を集めた集合にグリフセットというものがあります。PDFReferenceには次のようなグリフセットの名前が参照されています。
・Adobe-Japan1
・Adobe-GB1
・Adobe-CNS1
・Adobe-Korea1
※PDFReference(5版 PDF1.6) pp.416-417
グリフセットの仕様書は、アドビシステムズのFont technical notesのページのCJK/CID-Keyedfontsとして公開されています。
グリフセットの検討に入る前に、グリフ(Glyph)とはなにかについて調べてみます。
PDF Referenceには次のような記述があります:
「文字は抽象的な記号なのに対して、グリフは文字を可視化した形状である。...歴史的に、コンピュータによる組版の世界では、この二つは交換可能な用語として使われてきた。しかし、この領域の進歩によりだんだん意味の違いが明確になってきた。」
※PDFReference p.358
文字とグリフについて使い分けるようになったのは比較的最近のことのようです。このため、PDF Referenceの中には混同した名前が使われている箇所がある、と書かれています。
コンピュータで文字を表示したり印刷するときはフォントを使いますが、グリフのデータはフォント・ファイルに収容されています。各文字のグリフは、ビットマップ・フォントで表現されている場合もありますが、アウトライン・フォントではグリフをプログラムまたはそのパラメータとして記述しています。
フォント関連の用語については、フォント情報処理用語も参照してください。
なお、Answers.comでGlyphを引いてみますと、次のような文章が見つかります。
In computing as well as typography, the term character refers to a grapheme or grapheme-like unit of text, as found in natural language writing systems (scripts). A character or grapheme is a unit of text, whereas a glyph is a graphical unit.
For example, the sequence ffi contains three characters, but will be represented by one glyph in TeX, since the three characters will be combined into a single ligature. Conversely, some typewriters require the use of multiple glyphs to depict a single character (for example, two hyphens in place of a dash, or an overstruck apostrophe and period in place of an exclamation mark).
---ここまで---
(訳)
コンピュータ処理では、組版と同じように、文字は、テキストの書記素または書記素のような単位。...文字または書記素はテキストの単位であるのに対し、グリフは図形の単位である。
例えば、ffiは3つの文字を含んでいるが、TeXでは一つのグリフで表されるだろう。...逆に、タイプライターによっては、一つの文字を複数のグリフを用いて表す。
---以上---
用語にこだわるようですが、グリフという用語を調べていてグリフを字体としている文書がいくつか見つかりました。
たとえば、
(1) CHISEプロジェクトの「グリフ・字形情報の統合と合成」ページには、次のような記述があります。
文字データベースに字形やグリフ(字体)に関する情報を収録し、 文字に関する知識とグリフ・字形を統一的に扱うシステムを実現します。
(2) 「文字コード標準体系専門委員会報告書」(情報処理学会の情報規格調査会、2002年3月)のレポートでは、字体と字形を次のように定義しています。
字体 (glyph)
文字の抽象的な形 (骨格) の概念で、文字の骨組みなどともいわれ、具体的に視覚化することは不可能である。(ISO/IEC TR15285、国語審議会資料などから。)
字形 (glyph image)
印字・表示などの手段によってグリフ表現を表示 (presentation) することによって得られる“glyph”の可視化表現で、必然的に何らかの書体によってしか表示できない、一般的な意味で文字出力と言われるもの、あるいは、印字・表示・転写・手書きなどによって可視化された結果の文字。
※同報告書 p.69
どちらが正しいと即断はできませんが、グリフという言葉の意味するところに専門家の間でもかなりの違いがあることは確かに思います。とりあえず、このブログでは、PDF Referenceの使い方を採用します。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月12日
PDFと文字(21) – 大文字セット
漢字の大文字セットを使うことができるものには次のようなものがあります。
1.まず、今昔文字鏡です。
・文字鏡研究会のWebページ:
http://www.mojikyo.gr.jp/
・文字鏡関係製品のWebページ
http://www.mojikyo.com/
諸橋轍次著『大漢和辞典』に収録されている約5万の見出し漢字を含め、日本・中国・台湾・韓国・ベトナムの漢字12万字を収録しています。他に、また、梵字・甲骨文字などまで入っているようです。
文字鏡はなかなかすごいプロジェクトだと思います。日本で漢字についてこのようなデータが作成されていることはすばらしいことです。
2.次は、東京大学多国語処理研究会が作成しているGTフォントです。
http://www.l.u-tokyo.ac.jp/GT/
漢字が約67,000字TrueTypeフォントとして作成されているようです。
GTフォントはWindows上でも使うことができるようです。
また、BTRONをOSに使っている超漢字もGTフォントを使っています。
2005年12月の日経ネットの記事によりますと、TRONプロジェクトを率いる東大の坂村教授は、約12万字からなる世界最多の漢字フォント集を作成した、と発表しています。これは、文字数がGTフォントの2倍近くなっていますが、GTフォントとどんな関係なのでしょうかね?
3.それから島根大学のe-漢字データベースがあります。
http://ekanji.u-shimane.ac.jp/
・大漢和辞典((株)大修館書店発行) 50305字
・康煕字典の49188字
・Unicodeの20902字
・新字源((株)角川書店発行) 約9900字
の漢字コードから字形を検索できます。
それにしても、漢字の話になりますと必ずと言っていいほど、『康煕字典』が登場します。
この辞典はもともとは、清朝の皇帝が作ったものなのだそうです。清朝の国家プロジェクトということです。できたのは18世紀の初頭ですから、比較的新しいものですが、日本では江戸時代1780年ということ。そうしてみますと、漢字の歴史が数千年といっても、現代漢字の典拠ができてから、まだ300年経っていないと言って良いのでしょうか?
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月11日
PDFと文字(20) – 字体と字形
加藤 弘一氏の「ほら貝」には「文字コード問題を考える」というページがあり楽しい読み物が沢山公開されています。
ほら貝:文字コードの「二千年紀の文字コード問題」の2.小文字セットと大文字セットで、加藤氏は次のように述べています。
---加藤氏の文章引用:ここから---
①JISや Unicode側では、字体レベル以上の包摂をおこなっても、フォント名指定で字体を特定すればよいと考えているようである。文字コードは複数の字体をふくむ粗い網の目にとどめておき、個別の字体は文字コート+フォント名であらわすわけだ。この立場を小文字セットと呼ぼう。
②それに対して、個別の字体ごとにコードを割り当てていくという立場もある。字形を分類する網の目が密になり、コードポイントが増えるので、大文字セットと呼ぶことにする。
現在の文字コードをめぐる論点は、結局、小文字セットを選ぶか大文字セットを選ぶかの問題に集約されると考える。
---ここまで---
この文章の後ろの方で、加藤氏は要するに小文字セットを否定して、大文字セットが良いと言っています。また、氏は、漢字の統合、特に国を超えての統合には反対のようです。
小文字セットと大文字セットの対照はなかなか興味深いと思います。そこで、これを少し検討してみましょう。
ところで、ここ1、2週間、漢字を符号化文字集合として、どうやって扱ったら良いかという問題意識で、いろいろと資料に眼を通しています。そこで、まず感じたのは、最初に用語を定義しておかないといけないな、ということです。そうしないと、もともとヤヤコシイ話が、ますます混沌として訳が分からなくなってしまいそうです。少し用語を見ておきましょう。
例えば、上で引用しました加藤氏の文章での「字体」は、JIS規格の定義では、「字形」に相当するのだろうと思います。
JIS X0213の用語定義は次のようになっています:
i) 字体 図形文字の図形表現としての形状についての抽象的概念
h) 字形 字体を、手書き、印字、画面表示などによって実際に図形として表現したもの
※JIS X0213 : 2000 p.3より。
JIS X0213規格(以下、JIS規格と言います)の用語定義、特に、字体は理解しにくいですね。まず、文字を視覚的に表記することを想定し、視覚的表記には文字を表す図形を使うということを想定しています。
Unicodeではコードポイントと言いますが、JIS規格では面区点位置と言います。
JIS規格(漢字部分)は、コードポイントに漢字の字体を一つづつ割り当てます。この時、字体は抽象的なものなので、割り当て表は、具体的な例として例示字体を示し、字書の音訓、用例などを添えて定めている訳です。例示字体で示されている図形はあくまで例です。JIS規格では字形については規定していないと明記されています。
なお、Unicodeの用語では、抽象的形状(abstract shape)という言葉が使われていますが、これがJIS規格の用語では字体に相当すると思います。
フリー百科事典『ウィキペディア(Wikipedia)』で字体の項を見ますと、概ね、JIS規格と同じで、字体とは「図形を一定の文字体系の一字と認識し、その他の字ではないとしうる範囲に対する概念」となっています。
ここには、字形の説明もありますね。このWebページは書きかけの状態とされていますが、概ね、納得できます。そこで、今後は、ある漢字の字体というときは、抽象的形状を意味し、漢字の字形というときは、その漢字が具体的に印刷・表示される形状として使うことにします。
こうしてみますと、加藤氏の文章は、JIS規格と比べて字体と字形の言葉の使い方が逆じゃないでしょうか?
デザイン面に着目すると、字体はデザイン要素を捨て去ったものですが、当然、字形には文字デザインによる相違をも含んでいます。符号化文字集合で文字を区別する際にデザイン要素までを考慮せよ、という意見を述べる人はいないと思います。つまり、字体ではデザイン要素を捨て去って考えることについては合意されているでしょう。では、デザイン要素はどうなるの?ということは後で検討します。
字形と字体の相違はデザイン要素による相違だけではありません。その前に、もっと難しい問題があります。
一番ややこしいのが一般に異体字と言われているものです。先の『ウィキペディア(Wikipedia)』では、次のように説明されています。字体は同じだが異なる字形、ある正字体系の標準的な字形と異なる字形、或は字源は同一でも別の字体と認識される字体のこと。そうして、異体字の例を次の5種類に分けて示しています。
1. 字体の構成要素の位置が異なるもの。
2. 異なる音符を使ったもの。
3. 異なる意符を用いたもの。
4. 一方が形声で作られ、一方が会意で作られたもの。
5. 会意や形声の仕方が異なり、字形上の共通項がないもの。
さらに、ひとつの漢字には、正字・俗字という字形区分もあります。
日本では新字・旧字という字形の区分もあります。
中国では、1950年代に、簡体字を定めたため、ひとつの漢字に旧来の繁体字と簡体字というふたつの図形表現の体系ができてしまいました。
フリー百科事典『ウィキペディア(Wikipedia)』の漢字の項も参照。
このように字体を抽象的な形状というのは簡単ですが、では符号化文字集合を作る際には、特に漢字の場合、実際にどうやってこれを規定するかが難しいわけです。誰が作業しても同じに結果になるであろうような規定を定めない限り、科学的に符号化文字集合を作成することができません。
違う規定を使えば符号化文字集合は別のものになってしまうでしょう。Unicodeの漢字統合のように途中で規定が振れてしまえば、実際上、やむをえず使うにしても、理屈の上では破綻状態です。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年01月10日
PDFと文字(19) – 漢字統合問題再検討
Unicode4.0では、既に漢字を7万字以上も規定しています。さらに統合漢字拡張Cとして新たな漢字の追加を計画しているようです。
しかし、1月5日、1月6日には、①Unicodeの漢字統合の基礎になるはずの3次元モデルが曖昧で間違った解釈がなされていること。②その結果、統合ルールも不整合になっていること。③新しく追加した漢字の中には同じ抽象的字形を別のコードポジションに重複して登録しているものがあるなど、既に大きな問題を抱えていて、Unicodeの漢字統合は破綻していると述べました。
このような状況で新しい漢字を追加することは、新たな混沌をもたらすだけではないでしょうか?
これに対して、どのように考えたら良いのでしょうか?
「日本の苗字七千傑」というWebページのQ&Aを見ますと、
Q4.日本の苗字は何種類の漢字が必要か?
という項があります。
これによりますと、住民基本台帳ネットワークでは、非公開の統一文字コード(約二万一千字)を外字として使用していて、JIS X0213でも漏れている文字があるとのこと。さらに、苗字拾遺を見ますと、Unicode外(とされている)漢字の例も見ることができます。
このようなことからだけでも、標準文字規格に新しい漢字を追加して欲しい、という強い要望があるだろうことは容易に予想されます。では、その要望通り追加したら良いのではないか、と思われますが、事はそう簡単ではありません。標準規格に文字を追加することは、後で検討しますように、社会全体では相当に大きな額のコストがかかるだろうと思います。
しかし、自分の苗字位は正しく書きたいのは人情です。これに応えられなければ、プロの名が泣くというものです。
大口たたいたな。じゃあ、お前、解決策を示してみろ?と問われれば:
私は、現段階では実際のところ直感的にですが、PDFを使うことによって標準規格の漢字字種不足および漢字統合に関する問題を、すべて、比較的簡単に解決できるのではないかと考えています。このことについては、このブログですこしづつ検討したり、説明していきたいと思っていますので、お楽しみに :-)
つまり、私たちの時代は、漢字の標準規格に新しい漢字をそれほど沢山追加しなくても、世の中に出現する漢字を自由自在に取り扱う技術を有していると思うのです。ですので、これから、何万種類もの漢字を標準に追加したり、管理する作業は行わなくても良いのではないか、いや、むしろ社会的コストを考えますと漢字を増やすのはできるだけ止めるほうが良いのではないかと考えています。
そういっても、実際のところどうなの?本当にPDFですべての問題を解決できるの?ということもあると思います。
それに万人を説得できる証拠を提示することも必要でしょうし。そうなりますと、もう少し漢字のことを調べてみなければなりませんね。そんなわけで、漢字から先へ進めなくなってしまいました。そんなつもりじゃなかったんですが :-)
※補足
なお、統合漢字拡張Bには次のような疑問を感じる漢字もありますが、次の漢字は正しいのでしょうか?
・天地が逆ではないでしょうか?それとも逆さまであることに意味があるのかな?
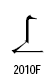
・白抜きの部分はどう解釈すべきでしょうか?


投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年01月09日
PDFと文字(18) –Unicodeの漢字関連ブロック
Unicodeには今までに述べた統合漢字、互換漢字以外に、漢字に関連するブロックが、①漢文、②部首、③漢字を組み立てるためのコードの3つがあります。
これらについて次に簡単にまとめておきます。
①漢文 U+3190~U+319F
中国語の漢字の文章を日本語で読むための記号です。学校の漢文の授業などでならったものです。
②部首 U+2E80~U+2FD5
辞書の索引などで使う部首が規定されています。
・康煕部首(U+2F00~U+2FD5) 214種類の部首用文字
・CJK補助部首(U+2E800~U+2EF3) 115種類の部首の派生形、または簡体字用部首
これらの文字は部首であることを示すため専用で、統合漢字と同等のものとして扱うことはできません。
③漢字を組み立てるためのコード
統合漢字や互換漢字はひとつひとつの漢字を図形文字として識別して番号を与えていくという方式です。これに対して、漢字を別の漢字の部品として使って、新しい漢字を組み立てるという考え方が、1970年代から研究されてきたようです。
この方式には、いくつかの方法がありますが、その一つがIDS(Ideographic Description Sequence)という方法です。このIDSで用いる文字をIDC(Ideographic Description Characters)と言い、U+2FF0~U+2FFBに12文字が規定されています。
IDCは結合文字(他の文字とまとめてひとつの文字にする文字)ではなく、また、通常の図形文字の代替表現を提供するために用いるものではないとされています。Unicode準拠アプリケーションは、IDS方式の文字の並びを表示する際、一つの文字として表さなくてもかまいません。
IDCは、もともと中国の文字規格GBKでGB2312-80にないUnicodeの文字を追加するために盛り込まれたものです。そこで、Unicodeでは、IDSをまだ符号化されていない文字を既存の文字を組み合わせて表現するための方法と位置づけています。
【IDSの応用例】
IDSを、既存の漢字の構造を表すために使っている例もあります。
京都大学の人文科学研究所の守岡氏らは、文字に関する知識データベースの作成とその利用を開発するCHISEプロジェクトを行っています。CHISEプロジェクトの中で、このIDSを用いて漢字を表す構造情報データベースを開発中です。
■参考資料
1.CHISEプロジェクトについて
http://www.kanji.zinbun.kyoto-u.ac.jp/projects/chise/
2.CHISE / 漢字構造情報データベース
http://www.kanji.zinbun.kyoto-u.ac.jp/projects/chise/ids/
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月08日
日本語の表記は世界で最も難しい?
”The Story of Writing” (Andrew Robinson著、Thames & Hudson Ltd.、ISBN0-500-28156-4, 1995年発行)と言う本は、考古学の対象になる古代の文字から、現代の主な文字と表記法について、350点の写真を交えて解説しているとても楽しい本です。
その中で、第12章が日本の表記法の説明になっています。10数ページに渡る説明がなされているのですが、その中で、日本の表記法が「世界で最も複雑」という表題が付いています。
日本語表記が世界で一番複雑という見出し

※The Story of Writing, p.205より
この中では、次のような日本語の表記の特徴を挙げています。
①日本語は中国語とはまったく違う言語なのに、表記に中国から渡ってきた漢字を応用している。
②漢字には、日本独自の音読みと、中国伝来の訓読みがあり、二通りの読みを使い分けている。
③日本人は漢字をもとに、50音を表記するひらがなを発明した。その上で西欧の言語が、アルファベットで表記するように、ひらがなだけで書けば良いのにわざわざ、漢字かな混じり文で表記している。
④ひらがなとカタカナの2種類の音節文字表をもっている。そして日本人は、用途に応じて、ひらがなとカタカナを使い分けている。
⑤1980年代には、ローマ字表記のアルファベットが、広告を通じて日本の表記法に広がった。最近の日本人は、ローマ字表記も使い分けている。
⑥普通の日本人は2,000種類の漢字を覚えているが、5,000種類もの漢字を覚えないと教育レベルの高い人とは言えない。
などなど。
日本語の表記の難しさを説明した上で、コンピュータ化の必要性が高まるにつれて、いつの日か漢字を捨てるに違いない、などと書いています。
外国人から見ますと、このように日本語では様々な文字を混在させ、しかも同じことを表記するのに、用途に応じて複数の文字を使い分けた表記ができるのは奇跡的に見えるようです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (5) | トラックバック
2006年01月07日
漢字統合の3次元モデルについてKen Lundeの誤り
Ken Lunde著「CJKV日中韓越情報処理」という本は、コンピュータによる漢字処理の専門家にとっては必読書とされている重要な書籍です。
この本のUnicodeの漢字統合の説明の箇所でUnicodeの3次元モデルが紹介されています。Unicode仕様書は英文しかありませんし、実際のところKen Lunde本で3次元モデルを見た人の方が多いかもしれません。ところが、今回、Ken Lundeの本に紹介されている3次元モデルの図は間違っていることに気が付きました。
Unicodeの仕様書の図は次のようになっています。
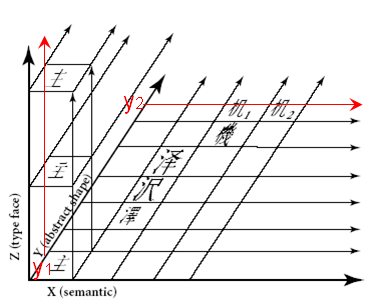
※「The Unicode Standard 4.0」 p.299の図を引用
赤の座標値と矢印は、私が追加。
Y軸の座標値が同じである漢字の例として、抽象的形状が同じでセマンテッィク(Ken Lunde本の訳では字義)が異なるとして、その例として、機械の”機”の略字![]() と”机”
と”机”![]() が出ています。
が出ています。
また、抽象的形状が同じで書体が異なる例が、Z軸方向に配置されています。
これに対して、「CJKV日中韓越情報処理」には図3-1 漢字の字形を比較する3次元モデルとして、次の図が掲載されています。

※「CJKV日中韓越情報処理」の日本語版(2002年12月刊)p.123の図を引用
赤の座標値と矢印は、私が追加。
Ken Lundeの図で、Y軸の座標値が同じである漢字とは、X軸、Z軸と平行な赤色の矢印で示す位置にある漢字となります。この図では、Y軸の定義とされている座標値が同じ文字は抽象的形状が同じが満たされていません。つまりKen Lundeの図は、Unicodeの3次元モデルの正しい説明になっていません。
ところで、この部分、日本語版の説明は次のようになっています。
漢字の字形は、3次元モデルによって比較することができる。X軸(字義)は、漢字を意味によって分け、Y軸(抽象形状)は、X軸上の漢字を抽象化された形状(同定し得る形状)毎に分ける。つまり、ある漢字の正字体と簡略字体は同じY軸の上に置かれる。Z軸(字形/書体)は漢字を字形の違いによって分ける。
(p.122 下から10行目~下から6行目)
このアンダーラインの部分は、座標軸としてのY軸の解釈を間違えていると思います。そこで念のため原文に当たってみたのですが、原文は次のようになっています。
...Traditionnal and simplified forms of a particular Chinese character fall into the same X axis position, but have different position along the Y axis. ..
(CJKV Information Processing, by Ken Lunde, January 1999, First Edition, p.124)
日本語版は訳が誤っていますね。正しくは、次のようになります。
中国の漢字の正字体と簡略字体は、X軸上では同じ位置になる、しかし、Y軸に沿っては異なる位置になる。
原書で図と本文の説明の意味が食い違っているため、図の意味が分からなくて、翻訳者たちも苦労したのでしょうね。「CJKV日中韓越情報処理」は、”バイブル”と言われている本ですので、ぜひ、誤りを修正してほしいものです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月06日
PDFと文字(17) – 統合漢字の理論
そもそも、日本、中国、韓国などの漢字を統合しようというのは誰が考えたのでしょうか?
Unicodeを最初に考えた人たちは、日本、中国などの漢字の文字数があまりにも多く、コードスペースの中に入りきらないという単純な動機から、同じ形の漢字に一つのコードポイントを与えようと考えたのではないかと思います。
しかし、その後の進展で、日本、中国、韓国などの専門家が参加するところとなり、漢字統合の理論を誰かが考えたようです。Unicodeの仕様書では、CJK統合漢字の理論は、3次元概念モデルとして、次のような図を用いて説明されています。この図は、漢字の簡体字が入っていますので、多分、北京の中国人の考案でしょう。
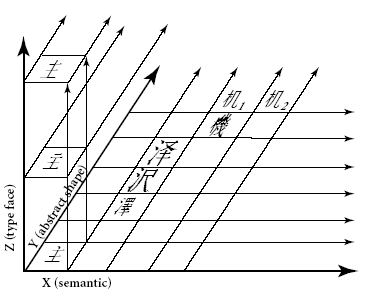
(Unicode仕様書 V4.0 Fig.11-3 p.299 より引用)
ここに、X軸はセマンティック(意味または機能)、Y軸は抽象的形状、Z軸はタイプフェース(書体)とされています。
この概念モデルに基づいて、日本、中国、韓国などの漢字をひとつにまとめたと説明しています。しかし、Unicodeの仕様書を読んでも、どうも統合にあたってのセマンティック軸の扱いが明確になっていません。そこで、この部分を私なりに検討してみました。
■仕様書V2.0では次のように書かれています。
Only characters that have the same abstract shape (that is, occupy a single point on the X and Y axes) are potential candidates for unification. Z axis typeface and semantic differences are generally ignored.
(Unicode V2.0 仕様書 p. 6-108、下から10行目~8行目)
※アンダーラインは私が付けました。以下、同じです。
3次元概念モデルでは、Y軸上で同じ位置の漢字が同じ抽象的な形状となります。抽象的形状が同じものをまとめるということは、Z軸とX軸を無視することになります。ですので上の文章は正しくありません。私の考えでは、正しくは次の文章になるはずです。
Only characters that have the same abstract shape (that is, occupy a single point on the Y axis) are potential candidates for unification. Z axis typeface and X axis semantic differences are generally ignored.
上の図の例で、セマンティックを無視すれば、![]() と
と![]() は統合され、ひとつのコードポイントが与えられます。
は統合され、ひとつのコードポイントが与えられます。
※ちなみに、この二つは字形が同じで意味が違う例として、![]() は”機械”を意味し、
は”機械”を意味し、![]() は、”机”を意味すると説明されています。
は、”机”を意味すると説明されています。
■ところが、V3.0仕様書から以降、この部分が次のように訂正されています。
Only characters that have the same abstract shape (that is, occupy a single point on the X and Y axes) are potential candidates for unification. Z axis typeface and stylistic differences are generally ignored.
(直訳)
同じ抽象的形状をもつ文字(すなわち、XとY軸の上でひとつの点を占める)のみが統合化の潜在的候補となる。Z軸のタイプフェースとスタイルの違いは一般に無視する。
この新しい説明では、セマンティック(semantic)がスタイル(stylistic)に代わってしまいました。そして、無視されるのはZ軸(タイプフェースとスタイル)のみとされています。
セマンティックの扱いは明確に書かれていません。しかし、X及びY軸で同じ位置にあるものが抽象的形状が同じ、と言っているわけですから、セマンティックが抽象的形状の一要因になったということに等しいわけです。言い換えるとセマンティックが違えば抽象的形状が違うとみなす、と暗黙に示したことになります。
このあたり、3次元(立体)で考えるのは難しいので、わかり易くするため、2つの軸、X軸×Y軸を1次元に展開して、図を書き直すと次のようになります。
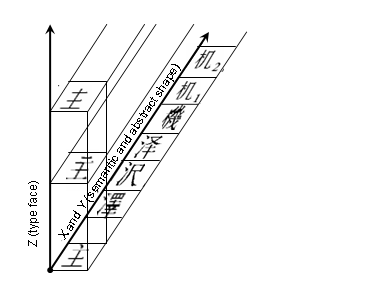
※この2次元の図は私が作りましたが、上の3次元の図と同等なはずです。
V3.0以降の仕様書では、この図でZ軸のみが無視されると言っています。ですので、![]() と
と![]() は別のコードポイントが与えられることになります。
は別のコードポイントが与えられることになります。
言い換えると、V3.0以降では同じ抽象的形状でもセマンティックが異なれば統合の候補にならない。抽象的形状とセマンティックが共に同じ漢字のみが統合の候補になると変更したことになります。
※しかし、仕様書には、統合ルールは、原規格分離規則以外は、変更してないとも書いてあります。従って、仕様書の説明に矛盾を含んでいます。
X軸、すなわちセマンティックについて考えて見ます。同じ字形の漢字でも言語によって意味が変わったり、新しい意味が付加されたりすることが多く、言語の違いがセマンティックに重要な影響を及ぼすのは明らかです。従って、字形が同じでもセマンティックが違えば別のコードポイントを与えるとなると、中国語、日本語、韓国語、ベトナム語という異なる言語の中で出現する漢字を字形で統合するのは至難になります。乱暴に言えば、セマンティックを無視しなければ、CJKVの漢字統合はできないのではないでしょうか。
結局、概念モデルではセマンティックを無視しないと言い、実際の作業はセマンティックを無視して漢字統合したということで、示した理論と実際にやったことが矛盾してしまったように思います。
V1.0でCJK漢字を統合すると言いながら、原規格分離規則によって、これを徹底できずにV3.0では原規格分離規則を廃止したというように、漢字統合ルールも振れています。
昨日、Unicodeの漢字統合は破綻してしまったと言いましたが、その原因を辿っていけば、ルールの基になる概念=3次元概念モデルが曖昧だったためではないでしょうか?
20世紀最大の偉業のはずなんですが。残念。漢字統合は、21世紀にもう一度やり直しが必要なんでしょうね。
[2006/3/15]
芝野先生のご指摘により、一部削除しました。
また、CJK統合理論が生まれた経緯につきましては、芝野先生、安岡先生にコメントをいただいていますので、そのあたりをご参照ください。
※英文にするときは、全体を修正しなければなりませんね。翻訳が遅れていますので、いつのことになりますか?
投票をお願いいたします
投稿者 koba : 08:00 | コメント (7) | トラックバック
2006年01月05日
PDFと文字(16) –漢字統合の破綻
Unicodeの漢字統合は、中国、日本、韓国で同じ字形の漢字をひとつのコードポイントにまとめた、と言いました(1月3日)。しかし、UnicodeV3.1の統合漢字拡張Bを調べてみますと、UnicodeのCJK漢字統合は破綻してしまったのではないかという印象をもちます。
ここにいくつかその例を挙げます。
1.一般統合漢字と同じ漢字が定義されている例
○一般統合漢字

○統合漢字拡張B
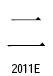
この2つの漢字は字形が完全に同じものではないでしょうか?なぜ、まったく同じ字形を別のコードポイントに追加したのでしょう?
2.一般統合漢字に統合されるはずの漢字が別に定義されている例
(1) ハネの有無
○一般統合漢字
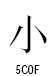
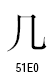
○統合漢字拡張B
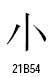
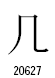
この2組の漢字は、ストローク終端のハネの違いです。ストローク終端のハネの違いは、書体の違いとして統合するという例がUnicodeの仕様書に出ています。しかし、統合漢字拡張Bで分離されて新しいコードポイントを与えてしまいました。
(2) 点の有無
○一般統合漢字


○統合漢字拡張B


この2組については、1月3日に日本語と中国語の字形の例で示しました。一般統合漢字では、点のある器と点のない器、点のある突と点のない突は、ひとつのコードポイントに統合されています。ところが、統合漢字拡張Bで、点のない器と点のない突が、新たに別のコードポイントを与えられてしまいました。
これは、統合漢字拡張Bのコードチャートを1,2時間ざっとみて見つけたものです。コードチャートを詳細にチェックすると他にもこのような例が一杯出てくるのではないかと思います。
Unicodeの仕様書では、一般統合漢字と統合漢字拡張の統合ルールは、原規格分離規則を除いて同一と説明されています。しかし、上の例で示しましたように、実際のコードチャートを見ると、それ以外にも統合ルールが違っていることになります。この統合ルールの変更は仕様書に書いてない、闇ルールということになります。
Unicode仕様書によれば、統合漢字拡張Bには、使用制限がなく、一般統合漢字と混在使用できます。従って、一つの漢字に複数のコードポイントを与えてしまった問題は、理論的に救済不可能と思います。
どうしたら良いんでしょうか?実装の段階で一方を使わないようにするんでしょうか?
それにしても困ったものです。実装者泣かせの仕様書ですね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月04日
PDFと文字(15) – CJK統合漢字拡張
UnicodeV4仕様書の付録A Han Unification Historyに漢字統合の歴史について書いてありますが、一般統合漢字の作成は中国、日本、韓国の関係者を集めたCJK-JRGという研究グループが行って、UnicodeコンソーシアムとISO 10646に提出したものです。
その後、CJK-JRGはISO/IEC JTC1/SC2/WG2の下の作業グループとなり、名前もIdeographic Rapporteur Group (IRG)と変わりました。UnicodeV3以降で統合漢字が拡張されていますが、この拡張作業はIRGが行ったものです。
また1994年にベトナムの規格を追加しています。
次に、Unicode4の仕様書本文第11章East Asian Scriptsの統合漢字拡張と互換漢字についての説明を要約してみましょう。
統合漢字拡張Aと統合漢字拡張Bは、一般統合漢字と比べてまれにしか使わない文字で、一般統合漢字に統合できない文字を追加したものです。
統合化の規則のなかで原規格分離規則は1992年で廃止されましたので、統合漢字拡張Aと統合漢字拡張Bには適用されていません。それ以外の統合化規則は、一般統合漢字と同じとされています。
統合漢字拡張AはIRGが1993年から1998年にかけて各国の規格と古典から集めて、Unicode3.0でコードスペースBMPに6,582字を規定したものです。
一方、統合漢字拡張Bは、UnicodeV3.0に含まれなかった42,711文字を補助多言語第2面に規定したものです。G(中国)、H(香港)、T(台湾)、J(日本)、K(韓国)、V(ベトナム)の6つの原規格から漢字を集めて整理したもので、ちなみに、日本の原規格として、J3 JIS X 0213:2000の第3水準と同第4水準が入っています。
一般統合漢字、統合漢字拡張A、統合漢字拡張Bの3つのブロックは使用上の制約がありません。
これに対して、互換漢字は、12文字(下記③の文字)を除き、原規格とラウンドトリップする用途のみに使用できる、という制限が付いています。
ラウンドトリップとは、各国別規格に準拠する文字符号化テキストデータをUnicode文字符号化テキストデータに変換し、また、元の文字符号化テキストデータに戻したとき、全ての文字が元のコードに戻るということです。
CJK互換漢字(U+F900~U+FAFF)
361文字が規定されていますが、4種類に分かれます。
①韓国のKS C 5601-1987仕様は一般統合漢字の原規格として使われましたが、その中の268文字は同じ漢字の異なる発音を符号化したものなので、原規格分離規則の例外として一般統合漢字には含めませんでした。そのままではKS C 5601-1987とのラウンドトリップを実現できなくなることから、互換漢字に含め、KS C 5601-1987とのラウンドトリップ専用に使います。
②22文字は他の原規格にあり、統合漢字に含まれる漢字の複製または統合できる派生文字です。原規格とラウンドトリップする目的で含まれているものです。
③12文字(U+FA0E, U+FA0F, U+FA11, U+FA13, U+FA14, U+FA1F,U+FA21, U+FA23, U+FA24, U+FA27, U+FA28, U+FA29)はUnicodeコンソーシアムから出した原典にあります。この12文字は統合漢字の拡張として使うことができます。
④U+FA30~U+FA6Aの59種類の互換漢字はJIS X 0213:2000とのラウンドトリップ専用で他の目的には使えません。JIS X 0213:2000には原規格分離規則が適用されないため、JIS X 0213:2000は統合漢字拡張Aに追加されたにも関わらず、59文字が他の文字と統合化されてしまったための救済措置なのでしょう。
CJK互換補助漢字(U+2F800~U+2FA1D)
CNS 11643-1992の面3, 4, 5, 6, 7,15とのラウンドトリップ専用で他の目的には使えません。これらのCNS文字集合はIRGの統合化規則と大幅に異なる統合化規則を使っていたため、一般統合漢字を決める際に原規格分離の例外として扱われていたのです。しかし、そのままではラウンドトリップができなくなるため救済したのでしょう。
Unicodeの仕様書の漢字の部分を要約しましたのは、Webでいくつか文書を読んでみましたが、どうも、仕様書を読み込まずに、書いているものがあるように見受けられたからです。
このように申し上げている私も、Unicodeの仕様書で統合漢字の部分を精読したのは初めてなんです。お陰でいろいろ分かりました。仕様書を読み込むのは大事ですね。やはり :-)
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月03日
PDFと文字(14) – CJK漢字統合問題
漢字に関する大きな問題は12月24日のUnicodeの誕生の記事で出てきましたCJK統合漢字に関するものでしょう。
CJK統合漢字は日本(J)、中国(C)、韓国(K)の3カ国の漢字で字形が似ている文字をひとつのコードポイントにまとめて作られたものです。
JIS X0221-1995(ISO 10646-1:1993に対応するJISの規格で、UnicodeV1.1と対応する)の規格書にはCJK統合漢字の各コードポイントにはC(中国、台湾)、J、Kの各字形が掲載されています。ひとつのコードポイントに最大4つの字形が見本として示されています。
コードポイントに示されている字形によっては、日本の漢字と中国の漢字で字の形が微妙に異なるものがあります。例を次の図に示します。各コードポイントの漢字は、日本の漢字にはMSゴシック、中国の漢字にはSimHeiフォントを指定して表示しましたが、このように期待する字形を表示するには、適切なフォントを指定しなければなりません。
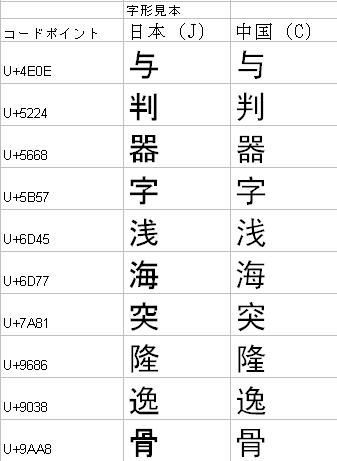
※この表は、「CJKV日中韓越情報処理」(Ken Lunde著、オライリー・ジャパン発行、ISBN4-87311-108-0、、2002年12月24日初版第一刷)のp.128の表3.82ほかの資料より作成。
Unicode4.0の仕様書、あるいは、コードチャートに掲載されている字形は中国の漢字字形になっています。
上のように、コードポイントのデータだけ、つまりUnicodeで符号化したテキストのみでは期待する漢字の形を指定できない場合があることになります。
どうしてこんなことになっているのでしょうか?これを知るために、CJK統合漢字について調べてみましょう。
CJK統合漢字は標準化時期により次の3つに分類されます。
(1)UnicodeV1.0から規定されている20,902文字。これを、このブログでは、便宜上、一般統合漢字と言うことにします。
(2)1992年~1998年に開発作業を行い、UnicodeV3.0で規定された統合漢字拡張A
(3)1998年~2002年に開発作業を行い、UnicodeV3.1で規定された統合漢字拡張B
この他に互換漢字というものがあります。
まず、一般統合漢字ですが、これは次のように作っています。
■原規格
G0 GB2312-80
G1 GB12345-90
G3 GB7589-87
G5 GB7590-87
G7 現代中国で一般的に使用する文字
G8 GB8565-88
T1 CNS 11643-1986/1面
T2 CNS 11643-1986/2面
Te CNS 11643-1986/14面
J0 JIS X 0208-1990
J1 JIS X 0212-1990
K0 KS C5601-1987
K1 KS C5657-1987
※The Unicode Standard V2.0 p.6-105, Table 6-21。V4.0の仕様書p.294, Table 11-1 ではTeが削除されている。
Gxは中華人民共和国、Txは台湾、Jxは日本、Kxは韓国の国内文字規格です。原規格から次のように文字集合を作り上げます。
1.G、T、J、Kの各グループ毎に、重複する文字は捨てて重複しない文字を集める。
2.1.で集めた文字に対して、3.の統合化規則に従って、同じ漢字に同じコードポイントを与える。
まず、概念モデルとして、漢字には①意味、②抽象的形状、③タイプフェース(文字デザイン)の違いがあるとして、②抽象的形状が同じものを統合化の候補とすると述べています。
3.統合化の規則
R1 原規格分離規則:原規格で別のコードポイントが与えられる漢字は別のコードポイントを与える(統合化しない)。
R2 形が似ていても起源が異なるものは統合化しない。
R3 同じ抽象的形状をもっていて、かつ、R1、R2規則で統合化を禁止されない漢字を統合化する。
抽象的形状が同じかどうかを決めるのは難しいと思うのですが、仕様書には次のように書かれています。
①漢字の部品の構造を比較する
②漢字の特徴を比較する
・部品の数
・部品の相対位置
・対応する部品の構造
・原漢字集合での扱い
・部品に含まれる部首
③上の特徴がひとつでも違うと異なる抽象的形状をもつとし、これらの特徴が同じなら抽象的形状が同じとする。
こうやって、CJKの漢字を国を無視して、同じような形状の漢字に同じコードポイントを与えたのです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月02日
PDFと文字(13) – Unicode文字の検討
Unicodeは、アメリカの企業を中心とする私的コンソーシアムが定めている仕様ですが、文字集合の決定、その符号化方式の仕様はISOという国際標準化団体と一緒に決めていることは、12月25日にUnicodeとISO 10646で説明しました。
(1) ISO 10646の仕様は、各国から代表が集まった委員会で議論・投票をして決定しています。このため、決定内容が各国の思惑の違いに左右されることがあるようです。
(2) そして、Unicodeに収容する文字は、ゼロから独自に集めたわけではなく、各国で決まっている標準規格等から収集しています。ここに各国の標準規格との関係をどうするかという課題が生まれます。
(3) また、当初のUnicodeは、16ビットでの実装用に企画されていたため2の16乗(65,536)個のコードポイントしかありませんでした。これは、実装の制限が仕様に影響を及ぼしたことになります。現在は、2005年12月26日に述べましたように、コードスペースが拡張されていますが、この拡張は極めてトリッキーな(tricky;巧妙な、ずるい)方法によるものです。
このような事情から、Unicodeの仕様には、いろいろと問題が出ている面もあるようです。これについて、以下に少し、まとめてみたいと思います。なお、私は、ISOの委員会にもJISの国内委員会にも参加していませんのであまり詳しいことは知りません。Webなどで調べながら書いていますので、誤りがありましたらぜひ指摘していただきたいと思います。
また、前にも申し上げましたが、私自身Unicodeは20世紀の偉業の一つと考えています。実際のところ、いまなにか製品を実装するとしてベースにする符号化文字集合にはUnicode以外の選択肢はないだろうと思います。
そのようなわけで、製品を実装する、あるいは利用する場合に理解しておくべき事柄として問題を整理してみたものです。このことを予めお断りしておきます。
1.漢字について
まず、最初に漢字について見てみましょう。Unicode4.0では次の表のように71,098文字の漢字が定義されています。(12月26日の表から漢字だけ取り出したもの)。
■Unicode4.0の漢字文字数
| 分類 | コード範囲 | 文字数 | 収容時期 |
|---|---|---|---|
| CJK統合漢字拡張A (CJK Unified Ideographs Extension A) | U+3400~U+4DB5 | 6,582 | V3.0 |
| CJK統合漢字 (CJK Unified Ideographs) | U+4E00~U+9FA5 | 20,902 | V1.0 |
| CJK互換漢字 (CJK Compatibility Ideographs) | U+F900~U+FA6A | 361 | V1.0で302文字 V3.2から361文字に増加 |
| CJK統合漢字拡張B (CJK Unified Ideographs Extension B) | U+20000~ U+2A6D6 | 42,711 | V3.1 |
| CJK互換補助漢字 (CJK Compatibility Ideographs Suppliment) | U+2F800~ U+2FA1D | 542 | V3.1 |
| 合計 | 71,098 |
※注意
1.正しくは、Ideographを表意文字と訳すべきですが、ここでは分かり易く漢字としています。
2.この表は、Unicode4.0仕様書のAppendix A Table D-2, Table D-3を元に構成したものなんですが、Unicode4.0仕様書の11.1 Han (p.293) の下から3行目では漢字は70,207文字とされています。891文字の違いはどこから来るか分かりません。
さらに、
http://www.unicode.org/Public/UNIDATA/DerivedAge.txt
を見ますと、UnicodeV4.1.0で128文字が追加されています。
| 分類 | V4.0 | V4.1で追加 | V4.1総数 |
|---|---|---|---|
| CJK統合漢字拡張A | 6,582 | 0 | 6,582 |
| CJK統合漢字 | 20,902 | 22 | 20,924 |
| CJK互換漢字 | 361 | 106 | 467 |
| CJK統合漢字拡張B | 42711 | 0 | 42,711 |
| CJK互換補助漢字 | 542 | 0 | 542 |
| 合計 | 71,098 | 128 | 71,226 |
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月01日
私がグーグルのアドワード広告を止めた理由 まとめ
新年おめでとうございます。
昨年末に、グーグルのアドワーズ広告について利用経験を紹介しました。アドワーズ広告は、Webサイトに顧客を集客したい企業にとっては、格好の媒体のように思えるのですが、しかし、大きな落とし穴があった、ということがお分かりいただけたと思います。
この経験から考えて見ますと、グーグルのアドワーズ広告およびビジネスの仕方には、次のような問題があるように思います。
1.アドワーズ広告はクリック数課金なのにも関わらず、異常なクリックが発生しても、その原因を特定できないようです。このため、悪意のある人による不正なクリックから広告主を防衛できていないと思います。
コンテンツターゲティング広告で、さまざまなサイトに広告が配信されるようになると、不正クリックで収入を得ようと考えるサイトの運営者が現れる可能性も大きくなると予想されます。
2.グーグルは、不正クリックを調査していると主張しています。また、調整金が時々として支払額より差し引かれることがありますが、調整金は一方的な通知になっていて、その計算根拠も不明です。いつの代金請求に対する調整金かということさえも明確ではありません。
3.不正クリックの調査に時間がかかり過ぎます。クレジットカード課金のため、代金徴収の方が、グーグルの調整金計算よりも早いため、不正クリックの金額を調整する前に、クレジットカードの保有者である広告主が破産してしまう危険があります。
4.今回のケースでは、調整金を返金すると約束しているにも関わらず、約束の期間に調整金を返金していません。また、その約束を守ろうという誠意・意思もないように感じます。
これに関連しまして、日本でクレジットカード会社と契約しているお店の場合、お店がクレジットカード会社に請求してからお店の口座への入金までに、数ヶ月かかっているはずです。つまり、日本ではお客さんがクレジットカードを使ってから、お店の口座にお金が入金するまでに数ヶ月かかるのが普通です。
しかし、米国ではそうではなく、クレジットカード会社からお店へは数日で代金が入金します。1週間かかることはないだろうと思います。従って、このケースでは、3月に発生した不正クリックに相当する代金(グーグルの言葉では調整金)は、遅くても4月初旬にはグーグルの銀行口座に入金しているはずです。これが年末まで経っても返金されていないというのは、グーグルは怠慢であるという誹りを免れないでしょう。
5.広告主からグーグルへの連絡手段が、FAXと電子メールしか公開されていません。広告に関する説明をしているインターネットのWebサイトを見ても、電話による連絡先が明記されていません。
今回紹介しました返金の手続きに関する、電子メールのやり取りでもお分かりいただけると思いますが、電子メールでは意思の疎通が難しい場面が多く、またなかなかスムーズに連絡が進みません。やはり、最悪の事態に備えて、電話によるコミュニケーションの道を作っておくべきだろうと思います。
私が、約1年数ヶ月に渡り、グーグルのアドワーズ広告を利用した経験をまとめますと、今回の問題を抜きにしても、グーグルのサービス姿勢は、①高慢、②一方的な押し付け、という印象が強く、顧客志向の姿勢がまったく感じられません。
以上により、このブログをお読みいただいた皆様には、次のことを勧めたいと思います。
①グーグルのアドワーズ広告は広告主にとって非常に危険な面を持つことを認識すること。
②グーグルはこの危険から広告主を守るために、顧客の立場にたってサービス、支援を提供していません。広告主はグーグルのサポートには頼れないということを認識すること。
③アドワーズ広告の広告主は自分で自分を守らねばなりません。このことに留意して、細心の注意を払って慎重にチェックしながら広告を利用すること。
さて、上に述べた問題の中のかなりの部分は人為的なものと思います。従って、グーグルの経営陣を初め関係者が、問題を率直に認識し、改善に真剣に取り組めば、解決できるでしょう。ぜひそのような方向に向かって欲しいものです。
投票をお願いいたします