« 2005年11月 | メイン | 2006年01月 »
2005年12月31日
私がグーグルのアドワード広告を止めた理由(4)
12月になっても、依然として返金がありません。そろそろ、2005年も終わりです。誰だって、こんな問題を年明けまで持ち越したくないですね。そこで、12月16日に、当社からどうなっているか確認の問い合わせをしました。
こんどは、こんな返事がありました。
■12月16日のグーグルからの電子メールの一部
返金の件に関しまして確認させていただきましたところ、カード会社様より有効期限が異なるとのお返事を頂戴いたしました。先日お知らせいただきました有効期限についてですが、こちらは 179,644円を請求されたクレジットカードと【同一】番号のクレジットカードで、有効期限のみ新しくなったということでよろしいでしょうか。
---ここまで---
こんどは、カードの有効期限が異なるとのこと。しかも、179,644円?を請求された、と言っています。こちらはずっと同じクレジットカードを使って支払っていますので、そんなことはないのですが。
その後のやり取りがあって、12月20日には次のメールが来ています。
■12月20日のグーグルからの電子メールの一部
当該クレジットカード会社様に237,423円の返金を試みましたところ、そのクレジットカードにはAdWordsご利用料金は179,644円までしか過去に請求をしておりませんでした。(その他のご請求は他のクレジットカードをお客様にてご利用であったと推察されます。)
そのため237,423円を過去にAdWordsにてご利用であったカードに各々返金する必要がありますが手続きが煩雑となり、お待たせすることを避けるため、直接お客様ご指定の銀行口座にお振込みをさせていただきたく存じます。
---ここまで---
最初に言いましたように、当社は、ずっと同じクレジットカードで支払っています。しかも、グーグルへの支払い金額は2005年分でも軽く合計200万円を超えています。なぜ、過去には179,644円までしか請求してないと判断したのでしょうか?
それに、そもそも返金するつもりがあるなら、返金先クレジットカードからの過去の支払い額など関係ないのではないと思いますがねえ。一体、本当に返金するつもりがあるのでしょうか?
というような次第で、こんどは当社の銀行口座の情報を連絡しました。12月21日のことです。
しかし、12月30日正午の時点では、まだ、銀行口座にグーグルからの振込みはありません。どうやら、調整金の返金問題は年を越しそうな気配です。
ここで紹介しましたように、一連の電子メールのやりとりで分かることは、グーグルの方には調整金を急いで返金するという意思はないようだ、ということです。普通、会社の経理ではこういう場合、預かり金に計上し、預かり金は早く返す処理をするべきなんですが。グーグルは、入金したものは全部自分のものだと思っているのかな?
ここにあげたのは、担当者間の電子メールのログの一部です。この間のやりとりを読むと、あまりのいい加減さに、怒りを通り越して、あきれてしまいそうです。グーグルにとっては、23万円などはした金かもしれませんが、人によっては1ヶ月の生活費ですからねえ。もう少し真剣に取り組んでもいいんじゃないでしょうか。
さて、今日は12月31日大晦日です。このブログを読んでいただいた方もまだ読んでいない方も1年間お疲れ様でした。
良いお年をお迎えくださいますように。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (3) | トラックバック
2005年12月30日
私がグーグルのアドワード広告を止めた理由(3)
さて、次にグーグルから連絡があったのは7月21日です。これは、前日7月20日に、当社がグーグルに、当社のクレジットカードに対して6月29日付けでグーグルから来た請求の明細を問い合わせたものに対する回答の一部です。
■7月21日のグーグルからの電子メールの一部
また、お客様のアカウントを確認いたしましたところ、6/29に調整額が発生しております。
調整額:2005/6/29 ¥-237,423
調整額とは、プロモーションの調整額、お客様のアカウントの無効なクリックに対する調整額などでございます。
(途中略)
弊社の調査結果より、無効なクリック対しての調整額として{¥-237,423}がアカウントに反映されておりますが、こちらにつきましては、全額クレジットカード会社様へご返金のお手続きをさせていただくよう手配中でございます。
---ここまで---
グーグルのいう調整額とは、不正なクリックと判定したものの課金を返金するというもののようです。ですのでかなり大量の不正クリックがあったと判断したので返金するということなのでしょう。
この調整額{¥-237,423}の計算根拠は明らかにされていません。2月までの請求額の傾向からみて、3月は30万円程増えているように思いますので、調整額はやや少ないかなという印象はありますが、まあ受け入れられる数字ともいえます。
その後、クレジットカード会社へ返金する手続きのために次のクレジットカード情報が必要という連絡がありました。
1.クレジットカード 確認コード( カードの裏の署名欄の最後にある 3桁の数字)
2.クレジットカードにご登録されているご住所
そこで、要求されたクレジットカードに関する情報をグーグルに連絡しました。7月26日のことです。
すんなり返してくれるなら、これまでのいきさつは水に流して、これで一件落着かと思いましたが。甘かったですね。まだまだ続きがあります。
返金に数ヶ月かかることもある、ということでしたのでずっと待っていたのですが、一向に返金されません。
そこで、10月24日に返金されないがどうなっているのか、という問い合わせをしました。この間に、3ヶ月経過しています。26日に返事がきました。
■グーグルからの10月26日の電子メールの一部
実は8月に下記メールを差し上げておりまして、カード番号およびカード名義人名の ご連絡をお待ち申し上げておりました。
誠に恐れ入りますが、ご返金処理のためカード番号ならびにカード名義人名をお知らせ下さい。
---ここまで---
どうやら8月16日に返金処理しようとしたところ、カード番号およびカード名義人名が必要だということになり、当社に問い合わせの電子メールを出したとのこと。だとすると、どうも電子メールを紛失してしまったようです。
しかし、なぜ、返事がないまま2ヶ月以上も放置してたんでしょう?
まあ、しようがない。そこで、要求された情報を提供し、また、待つことになりました。なかなか、返金がありません。
次に、11月中旬に次のような連絡がきました。
■グーグルからの11月15日の電子メールの一部
返金手続きを行いましたところ有効期限に関する照会エラーが発生いたしました。誠に恐れ入りますが、クレジットカードの有効期限をお知らせいただけますでしょうか。
---ここまで---
今度は、カードの有効期限に関する照会エラーだそうです。返金するのになぜ有効期限の照会が必要なんだろう?と思うのですが。
当社からは直ぐに有効期限を返答しています。11月16日のことです。
さて、素直に返金があれば、こんどこそ一件落着なんですが、なかなかそうはいきません。まだ続きます。(続く)
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2005年12月29日
私がグーグルのアドワード広告を止めた理由(2)
XSL Formatterのアドワード広告は、2004年には1日あたり50件程度のクリック数で推移し、2005年に入ってから少し増えて、1日平均80件から90件になっています。多い日でも1日127件です。このクリック数が、いきなり、1日500件から600件になることは、なにか異常事態が起きていると考えるのが普通でしょう。
そこで、急いで理由を問い合わせようとしました。事情を伝えるには電話が一番良いと思いますが、しかし、グーグルのアドワード広告については、電話による問い合わせはできないようです。
やむを得ず、電子メールやファックスで、急激にクリック数が増えた原因を調べて欲しい、と依頼をしました。
■グーグルからの回答 3月28日付け電子メールの要旨
お客様の広告は平均掲載順が高いため、現在、Google検索結果ページ(Google.co.jp)の上位2位の水色の掲載位置に、最上位のアドワーズ広告が掲載される場合がございます。
なお、この検索結果の上位掲載位置への表示には、一定のクリック率(CTR)が定められ、その基準を満たした広告のみが掲載されております。
この部分へ掲載された場合は、クリック数が増加する可能性がございます。
---ここまで---
要するに、上位2位の水色の掲載位置に掲載される場合があり、その場合、クリック数が増えるということです。しかし、XSL Formatterの広告は、広告の単価を高めに設定したこと、および、製品の優位性もあると思いますが、グーグルで「XSL-FO」をキーワードに検索した結果で表示されるアドワーズ広告の中では常に最上位になっていて、2004年から上位2位の水色の位置に定番で掲載されていました。従って、グーグルからの上の回答は、的を得ていません。
この点を指摘しましたところ、今度は、次のような回答が来ました。
■グーグルからの回答 3月29日付け電子メールの要旨
お客様のアカウントを確認させていただきましたが、該当のキャンペーンの表示回数およびクリック数の増加は、検索による広告掲載によるものではなく、コンテンツターゲティング広告での表示回数およびクリック数の増加によるものです。
コンテンツターゲティング広告とは、ウェブページのコンテンツにマッチするキーワードを持つ広告を自動的に選び出して、関連するキーワードや広告を設定されてい広告主様の広告が掲載される仕組みとなります。これらの広告が掲載されるサイトは、日々増加しており、コンテンツの内容も変化するため、お客様の設定されたキーワードや広告内容とマッチしたコンテンツが増加した場合などは、広告の表示回数が増加し、それに伴いクリック数も増加いたします。
---ここまで---
要するに、「グーグルのシステムが当社のXSL Formatterの広告に設定されているキーワードとマッチするWebサイトに広告を配信する。その掲載されるサイトが増えていて、そのクリックが増加している」、という説明です。
しかし、これはクリック数急増の合理的な説明になりません。なぜかといいますと、XSL-FOは、既に2000年頃から、専門家の間では重要なトピックになっていて、特に英文のWebサイトは、大体出揃った状態になっています。また、これらの関連サイトには、3月以前よりXSL Formatterの広告(英文広告)が配信されていることは確認済です。従って、クリック数の漸増要因の説明にはなるとしても、突然急増した理由とは考えられません。
このように、何回か質問と回答を繰り返したのですが、グーグルからの回答は、判で押したような紋切り型のものばかりで、結局、なぜクリック数が急激に増えたのかについての合理的な説明はなされませんでした。
また、調査をしてみるとの約束さえももらうことができず、原因不明のままでした。そこで、やむをえず、XSL Formatter の広告掲載は停止することにしました。この時点では、PDFなど他の広告は継続していたのですが、結局、6月5日ですべての広告を止めることにしました。
広告のクリック数に対して課金する以上は、広告主に対してクリックの発生状況について説明責任があると考えられます。しかし、これに関して合理的な説明ができない、ということはグーグルのアドワーズ広告は広告媒体として失格と判断したからです。
もちろん、これは私の判断ですから、皆さんにお勧めしているわけではありませんし、これで終われば、特に公開するほどのこともないことかも知れません。(続く)
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月28日
私がグーグルのアドワーズ広告を止めた理由
昨日は、アンテナハウスが、インターネットの広告に見切りをつけて、JRの秋葉原に看板を出したことをお話しました。これはグーグルのアドワーズ広告で大変に残念な経験をしたからです。
これについて、私は半年以上にわたって公開するべきかどうか、自問自答を重ねて考えてきました。しかし、公開するほうが世の中のためになるだろうとの結論に至りましたので、2005年の年末にあたり、ここに顛末を公開します。
グーグルのアドワーズ広告は、検索結果の画面に検索のキーワードに関連するテキストの広告を表示するものです。グーグルで検索しますと、検索結果が表示されているページの右側に「スポンサー」という欄があります。
ここに表示される広告がアドワーズ広告です。この広告をクリックすると、広告に関連付けられたWebページが表示されます。広告の表示順序は、広告主が設定したクリックあたりの単価になっているようです。
ですので、自社のWebページが、検索で上位に出てこない場合でも、アドワーズ広告を使ってWebの集客が可能になるわけです。広告主への課金は、クリック数に応じた課金で、しかも従来のクリック課金の広告より安いという大変に合理的な広告に思えます。
そこで当社は、世界の市場で販売するXSL Formatterの販売促進手段として最適と考え、英語版のXSL FormatterのWebページへのリンクを広告に掲載しはじめました。
当時、XSL Formatterの競合の製品が既に広告を出していたこともあり、当社は1クリック単価を比較的高めに設定しました。その後、キーワードをいろいろ工夫して増やし、また、広告の表現(メッセージ)を工夫することで、クリック数を増やすように努力しました。2004年5月から2005年2月まで、次の図のように順調なクリック数の増加を見ています。
異変が起きたのは、2005年3月のことです。
■2004年5月から2005年3月までのXSL Formatter アドワーズ広告月間クリック数の推移
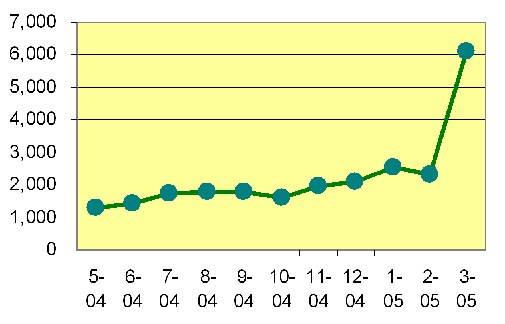
上の図を見ますと直ぐに気がつくと思いますが、2005年3月のクリック数が急激に増加しています。3月だけを取り出して、毎日のクリック数を見ますと次の図のようになります。
■2005年3月1日から毎日の1日あたりクリック数
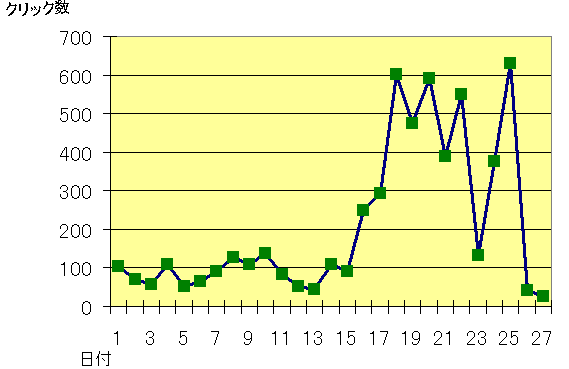
3月の16日から毎日のクリック数が200件を超え、18日602件、19日475件、20日590件、21日390件、22日550件となっています。23日は131件と少し減りましたが、24日 376件、25日631件となっています。
3月のクリック数の変化が起きる時点で、私の方では特に、アドワーズ広告の設定値の変更を行ったわけではありません。
このアドワーズ広告は、1クリックあたりの単価を広告主が設定することができ、グーグルからはクリック数×クリック単価にあたる金額を請求してきます。支払いは10万円毎にクレジットカードで支払うという方式です。いまは分かりませんが、当時はクレジットカード以外の支払いを認めていませんでした。
このため、クレジットカード請求が数日に1回届くということになってしまったわけです。次の表は、クレジットカード会社からの報告書に載っている、グーグルから来たクレジットカード請求日と請求金額です。
請求金額の単位は円です。また、全て同一のクレジットカードに対する請求です。
| 請求日 | 請求金額 | 請求日 | 請求金額 | 請求日 | 請求金額 | 請求日 | 請求金額 |
|---|---|---|---|---|---|---|---|
| 1月2日 | 102,999 | 2月1日 | 100,512 | 3月2日 | 109,300 | 4月1日 | 100,988 |
| 1月8日 | 100,340 | 2月6日 | 103,609 | 3月7日 | 104,806 | 4月17日 | 53,077 |
| 1月17日 | 98,878 | 2月10日 | 104,050 | 3月10日 | 103,778 | 4月28日 | 108,243 |
| 1月24日 | 103,593 | 2月14日 | 101,728 | 3月14日 | 100,651 | ||
| 1月28日 | 105,535 | 2月17日 | 65,734 | 3月17日 | 107,885 | ||
| 2月21日 | 103,101 | 3月19日 | 98,376 | ||||
| 2月25日 | 105,203 | 3月21日 | 101,297 | ||||
| 3月23日 | 108,330 | ||||||
| 3月26日 | 99,045 | ||||||
| 3月31日 | 102,373 | ||||||
| 1月合計 | 511,345 | 2月合計 | 683,937 | 3月合計 | 1,035,841 | 4月合計 | 262,308 |
※当時は、XSL Formatterのほか、PDF(日本語)などの広告も出していました。従って、上の請求金額には、XSL Formatter関連広告とPDF関連などの広告に対する請求金額の合計となります。クリック数のグラフと1対1対応ではありませんので、ご注意ください。
さて、請求額の急増に驚いて、急いでグーグルに問い合わせをしました。(続く)
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月27日
秋葉原駅にPDF広告
アンテナハウスでは、12月23日からJR秋原駅に、アンテナハウスPDFの看板を出しています。
■JR秋葉原駅の看板 (クリックすると拡大します)
 ">
">
■もっと奇麗に。。

掲載場所は、山手線の南行線路と北行線路の間で、南行側です。
JR山手線の東京方面行きのホームの中間あたり、階段を下りた位置とエレベータの間の位置からご覧になれます。
この広告は1年契約で約400万円です。ということは、この看板一つで両製品通算で1000本位売れないと黒字にならないんですね。
ぜひ、皆さん、看板をご覧になって、そうして製品も購入よろしくお願いします。
来年はPDF関係にもっと投資して、良い製品を作りたいと思っています。そのためにもぜひお客様のご助力をお願いします。松下幸之助の伝記に「家庭用テレビを最初に買った人のお陰で、家庭用テレビの製品がよくなり、そうして安くなる」、ということを話したというくだりがありますが、良い商品ができるにはやはりお金を払って購入していただくことが必要です。ソフトを買うのは善なる行いですよ、やはり :-)
ところで、最近、PDF関係の製品はインターネットに広告を出す会社が多いようです。しかし、最近、当社はインターネットに背を向けて、交通広告路線に走っています。(走るというほどでもないですが。。)
これは、JRに喜んでもらいたいというわけではなく、実は、今年、グーグルの広告で大変残念な経験をしたからということがあります。それで、インターネット広告に見切りをつけたわけです。これについては、明日、お話しましょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月26日
PDFと文字(12) – Unicode仕様の文字
さて、Unicodeについて、次のような観点から、少し詳しく検討してみたいと思います。
第1は、Unicode仕様で決めている文字の数について
第2は、その文字をどのようにコンピュータ同士で情報交換するかについて
第3に、その文字をアプリケーションでどのように処理するかについて
まず、Unicode仕様で決めている文字の数について、①Unicodeの文字の収容、すなわち、番号付けをどのように行っているかということ、ついで、②その番号位置にどのような文字を割り当てているかということ、を見てみます。
①Unicodeで決めているのは番号付けした文字です。Unicodeではこの番号のことをコードポイント(Code Point)と言い、番号の範囲をコードスペース(CodeSpace)と言います。コードスペースは0から10FFFF(16進表記、以下、コードポイントは全て16進表記します)で、1,114,112個のコードポイントを収容しています。
コードスペースを便宜上64Kずつのサイズの面に分けています。主な面には次のものがあります。
・基本多言語面(BMP、すなわちBasic Multilingual Plane):0000~FFFFまで。ここに大部分の通常使う文字が収容されます。
・第1面、または補助多言語面(Supplementary Multilingual Plane):10000~1FFFFまで。Lenear B(線状文字B)など歴史的な文字、音楽表記用の文字、数学表記用の文字(記号)のような特殊用途の文字用の面。
・第2面、または補助表意文字面(Supplementary Ideographic Plane):20000~2FFFFまで。BMP面に入りきらなかったCJK文字(漢字)を収容します。
②UnicodeのV1からV4までの各バージョンで収容されている文字数は次の通りです。
| 面 | 分類 | V1.0 | V2.0 | V3.0 | V4.0 |
|---|---|---|---|---|---|
| BMP | アルファベット・記号 | 4,748 | 6,509 | 10,236 | 11,649 |
| 漢字 | 20,902 | 20,902 | 20,902 | 20,902 | |
| 漢字拡張A | 6,582 | 6,582 | |||
| 互換漢字 | 302 | 302 | 302 | 361 | |
| ハングル音節 | 2,350 | 11,172 | 11,172 | 11,172 | |
| 図形文字(小計) | 28,302 | 38,885 | 49,194 | 50,666 | |
| 補助面 | アルファベット・記号 | 2,465 | |||
| 漢字拡張B | 42,711 | ||||
| 互換補助漢字 | 542 | ||||
| 図形文字(小計) | 45,718 | ||||
| 合計 | 28,302 | 38,885 | 49,194 | 96,384 | |
(注)仕様書Appendex D p.1356には、96,382文字と書いてありますが、合計は96,384文字になります。2文字の違いがどこから来るか分かりません。
さらに、Unicode 4.1 で、1,273文字追加したとあります。しかし、どこに追加したかはわかりません。
各文字の字形は、The Unicode Character Code Charts By Scriptで見ることができます。
たとえばLenear Bというのは考古学上の有名な文字らしいですが、Unicodeのコードチャート(次のURL)で見ることができるなんて、楽しいですね。
Linear B Syllabary (PDF)
Linear B Ideograms(PDF)
投稿者 koba : 08:00 | コメント (2) | トラックバック
2005年12月25日
PDFと文字(11) – UnicodeとISO 10646
Unicodeの仕様は4.1.0が現時点で最新です。
まず、印刷された出版物の最新版は、次の4.0版の書籍が最新です。
The Unicode Standard, Version 4.0
(The Unicode Consortium. Addison-Wesley, 2003. ISBN 0-321-18578-1),
これより新しい情報はWebサイトにあります。
まず、4.0以降の次の二つの更新情報があります。
Unicode 4.0.1
Unicode 4.1.0
また、5.0のベータ版が、2005年12月12日に公開されています。
BETA Unicode 5.0.0
Unicode4.1.0について、少し詳しく説明してみたいと思いますが、その前に、UnicodeとISO 10646との関係を簡単にまとめておきます。
WebサイトでUnicodeの解説をしているページを見ると、大抵、UnicodeとISO 10646との関係に触れていますので、このふたつはどういう関係なのだろうと疑問をもつ人が多いでしょう。
Unicode4.0の仕様書には、Appendix CにRelationshipt to ISO/IEC 10646(付属C ISO/IEC 10646との関係)という項があります。そこの説明をまとめると次のようになります。
1. ISO/IEC 10646-1: 1993 とUnicode Version 1.1 は、正確に一致する。
2. ISO/IEC 10646-1: 2000 とUnicode Version 3.0 は、正確に一致する。
3. ISO/IEC 10646-2: 2001 で初めて、補助面(Supplimentary Plane)を規定した。
4. Unicode 3.1 は、ISO/IEC 10646-2: 2001と同期を取った。
3. Unicode 4.0 は、ISO/IEC 10646: 2003(予定)と一致する。なお、ISO/IEC 10646: 2003は、10646-1と10646-2を合併したもの。
なお、UnicodeコンソーシアムのWebページには、Unicode and ISO 10646というページもあり、次のようなQ&Aが掲載されています。
Q. じゃあ、この二つは同じものなの?
A. いいえ。
文字コードと符号化方式は同期を取っていますが、Unicodeは実装上の適合性を重視しています。このため、ISO/IEC 10646で規定していない、拡張した機能文字、文字データ、アルゴリスム、背景資料などを提供しています。
ISO 10646を翻訳し、JISの国内規格との関係について解説を追加したものが、JIS X0221です。
投票をお願いいたします
投稿者 koba : 00:00 | コメント (0) | トラックバック
2005年12月24日
PDFと文字(10) – Unicodeの誕生
さて、地域別に符号化文字集合が異なるということは、コンピュータ・ソフトウエアの国際化にとっては非常に面倒なことになります。テキスト処理はコンピュータ・ソフトウエアにとっては基本的なものなのですが、そのテキスト処理を地域毎に変更しなければならなくなってしまうからです。
また、インターネットの普及に伴い、地域を超えて情報交換を行う必要性も高まっています。地域別に符号化文字集合が異なると、国境を越えたコミュニケーションの上でも大変不便です。
こうしたことから地球上の全ての文字を網羅するグローバルな符号化文字集合が必要なことは容易に理解できると思います。
この要請に応えて生まれたのがUnicodeです。Unicodeについての情報はUnicodeコンソーシアムのホームページで見ることができます。
Unicodeのアイデアが生まれ、実際に活動が始まったのは、1980年代の終わり頃です。Mark Davisの「Ten Years of Unicode 1988 - 1998」(Unicodeの10年、1988年から1989年)を見ますと、次のようなことが書いてあります。
Unicodeの基本設計は、1987年にゼロックスにいたJoe BeckerとLee CollinsおよびアップルにいたMark Davisが検討した。ゼロックスは、Star(Xeroxの研究所でStarを見たSteve JobsがMacintoshのアイデアを得たのは有名な話)の日本版J-Starを作る過程で、また、AppleはKanji Talk(Macintoshの日本語環境)を作る過程で、日本語化の問題に直面した、こんなことからUnicodeのアイデアについて意見を交換した。
1988年4月に初めてアップルがUnicodeテキストのプロトタイプを出し、TrueTypeでUnicodeをサポートすることを決めた。また、1988年7月にアップルはResearch Libraries Groupから中国語、日本語、韓国語(CJK)の文字データベースを購入し、CJK漢字の統一化(Unification)をはじめた。(これが、日本で悪名高いUnicodeのCJK統合漢字問題の始まりというわけです。)
こうして、Unicode制定への活動が始まり、その後、Sun、IBM、Microsoftなどの米国メーカの賛同を得て、次第に大きな動きになっていきました。
Unicode1.0の仕様書は1991年に出版され、1992年には、仕様書の第2巻が追加されUnicode1.0.1となりました。
1987年から始まったUnicode1.0の歴史は「Chronology of Unicode Version 1.0」(Unicode Version 1.0年代記)にあります。
私は、Unicodeはコンピュータ・ソフト分野における20世紀最大の偉業のひとつと考えていますが、こういう歴史が作られる過程をまざまざと見られるのは大変に興味深いものです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月23日
PDFと文字(9) – 中国の文字規格
漢字を生み出した国、中国でも独自の文字規格の制定が行われています。中国での文字規格は国家標準の略である「国標」のピンイン表記(Guo Biao)の頭文字をとって、GBxxという番号が付いています。
1バイトの文字集合には、GB11383-89(8ビット)、GB1988-89(7ビット)があります。また、簡体漢字を含む主要な標準規格には、GB2312、GBK、GB18030などがあります。
また、ISO 10646の中国語版であるGB13000-1-93という規格もあります。
GB2312-80は、簡体字6,763文字、記号682文字の合計7,445の文字と記号を定めています。従来、最も良く使われてきた文字集合ですが、近年は、GB18030に置き換えられつつあります。
GBK文字集合は、GB2312の拡張版です。GBという頭文字が付いていますが、標準規格ではなく指導的な規範とされています。MicrosoftのWindows95中国語版の内部コードとして実装されました。しかし、これもGB18030への過渡的な存在となりそうです。
現在、重要な存在になっていますのがGB18030です。これは、GBKに基づいて文字を追加して策定した国家標準で、2001年01月01日から発売する製品は必ず、この標準をサポートしなければならないと発表されています。GB18030には1バイト、2バイト、4バイトの3種類の長さで文字を収容していますが、4バイトの文字コード領域もあるため160万のコードをエンコーディングできるという巨大な収容量があります。ただし、GB18030-2000の仕様書に字形が記載されている文字の数は、28,522文字です。文字を追加する計画もあるようです。
さらに、中国政府は、この標準で定める文字を実装したフォントを開発して中国国内で販売する製品用に売り込んでいます。なかなか商魂たくましいものですね。日本のメーカ向けには、ダイナコムウェア社が販売代理店となって活動しています。
ダイナコムウェア社のページ中国新文字コード規格 GB18030
次の記事は、ダイナコムウェアの営業責任者 松田さんが寄稿したものです。
「漢字の国」にみる、電子機器の文字問題(1)
「漢字の国」にみる、電子機器の文字問題(2)
「漢字の国」にみる、電子機器の文字問題(3)
読み物としては面白いですが、少々、営業的側面?があるような気もしますね。
投稿者 koba : 00:00 | コメント (0) | トラックバック
2005年12月22日
PDFと文字(8) – JIS X0212, X 0213
さて、JIS X0208-1997で決めているのは6,879文字数で、そのうち漢字が6,355文字です。しかし、これでは当然漢字の種類が少なすぎるということで、JIS X0208:1990 と同時に、追加の文字を「補助漢字」として規格化したのがJIS X0212です。しかし、これはなぜか普及していません。
代わって、最近、話題を集めているのがJIS X 0213です。
X0213は2000年に制定され2004年に改正されました。
この規格書(2000年版)の先頭には、JIS X0208の6,879文字と同時に運用する4,344文字を含め、11,223文字を定めた、と書いてあります。もともとX 0212もX0208の補助漢字として定められたわけですから、この文章を読むと、X0212は止めて、X 0213で、X 0208の拡張をやり直したということがわかります。
JIS X 0213では、94×94の大きさの表を2面使って文字の番号表を定義しています。ひとつの面には理論上94×94=8,836文字が収容できますが、第1面には、JIS X 0208で定義されていた文字は、同じ位置にそのま収容し、さらに、JIS X 0208で空きになっていた位置に新しい文字を追加しています。第2面は新しい面で、2,436文字を定義しています。第2面にはだいぶ空きが残っています。
実装水準3の文字が8,787文字で、すべて第1面に割り当てられています。実装水準4では、第2面の2,436文字を含む全文字を実装することになります。
JIS X0213は、2004年2月に改正され10文字を追加しました。現在は、4,354文字をJIS X0213で新たに追加、X0208とあわせて合計11,233文字を定めています。
【参考資料】
JIS漢字コード表の改正について-報道発表-経済産業省
さて、最近話題というのは、マイクロソフトがWindowsVista用に、JIS X0213を実装する新しいフォントを作っているという発表です。
Windowsの次期バージョンWindows Vista(TM)において日本語フォント環境を一新
これによると、JIS X 0213:2004に対応したMSゴシック3書体、MS明朝2書体を新しく作っているということです。フォントはVistaだけでなく、XP向けにも提供されるということですので、期待したいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月21日
全角文字と半角文字について(蛇足)
JIS X0201で実際に使う文字はすべてX 0208に収容されています。このため、文字の種類だけを考えるのであればだぶりがあることになります。
X 0201の文字は半角文字、X 0208の文字は全角文字などとも呼ばれます。要するに、シフトJISコードでは、ラテンアルファベットや数字記号類、およびカタカナには、同一文字に半角文字と全角文字があるということです。これをどうやって使い分けたら良いでしょうか?
たとえば、IMEで文字を入力するとき、このような選択メニューが表示されます。
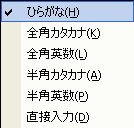
このメニューで半角文字を選ぶとX 0201の文字コードが入力され、全角文字を選ぶと、X 0208の文字が入力されることになります。
この使い分けの基準としては次のように考えれば良いと思います。
インターネットのアドレスなどは半角文字で入力することはご存知と思います。さらに海外とのやりとりをする場合、メールの本文、あるいはワープロの文書本文でもASCIIに定義されているラテンアルファベットや数字・記号類は半角文字を使うべきです。そうしないと、もし、海外のパソコンで文書を開いてみる可能性がある場合、全角のラテンアルファベットを使用すると、相手先で文字が化けてしまう可能性が大きくなるからです。ただし、¥マークは全角を使う方が良いでしょう。
一方、特別な事情がある場合を除いて、半角のカタカナは使わずに全角カタカナを使う方が良いと思います。
X 0201でなされた半角カタカナの拡張は、昔、コンピュータで使える資源が少なかった時代の名残で、将来はなくなるべきものだろうと思います。
もともと全角、半角という言葉は、どこから生まれてきたか知りませんが、文字の種類ではなく、キャラクタディスプレイで文字を表示したり、あるいはドットマトリックス・プリンタに文字を印刷するときの幅に由来していると思います。
シフトJISコードは、ある意味では初期のパソコンで和洋折衷をしたための妥協の産物です。今になって考えれば、ソフトウェアの国際化という観点からは、あまり望ましくない解決策ですので、個人的には、シフトJISコードはできるだけ早期に廃止されることを希望しています。
なお、次のページは、日本語中心ですが、文字コードについて、概略をわかり易く説明しています。
文字コード
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月20日
PDFと文字(7) – JISの文字規格
日本では、日本工業規格(JIS: Japanese Industrial Standard)で定めている文字集合についての規格があります。
現在、日本独自の規格として、次の4つの規格があります。
JIS X 0201 7ビット及び8ビットの情報交換用符号化文字集合
JIS X 0208 7ビット及び8ビットの2バイト情報交換用符号化漢字集合
JIS X 0212 情報交換用漢字符号-補助漢字
JIS X 0213 7ビット及び8ビットの2バイト情報交換用符号化拡張漢字集合
それから、ISO 10646という国際規格の日本語版として、JIS X 0221 国際符号化文字集合 (UCS) -第1部:体系及び基本多言語面
があります。
JIS X 0201は、ラテンアルファベットや記号類、およびカタカナ文字を定めています。ラテンアルファベットと記号類についてはISO 646をベースに一部の文字を日本特有にし、さらに独自にカタカナを追加したものです。
実用上、大きな問題は、ISO 646でバックスラッシュを定義していた文字番号を、X 0201では円記号を定義するように代えてしまったことでしょう。このため、X 0201は完全な国内規格であってインターネット時代には不適切です。日本語で円マークを書いたつもりでも、海外の人がみたらバックスラッシュになってしまうからです。
JIS X0208は、漢字類を定める基本的な規格で、
1978年に第一次規格 JIS C 6226-1978
1983年の第二次規格 JIS C 6226-1983(1987年にX 0208に移行)
1990年の第三次規格 JIS X 0208-1990
1997年の第四次規格 JIS X 0208-1997
と改訂されてきました。第二次規格で文字の番号の入れ替え(第一水準、第二水準間)を行い、罫線記号や特殊文字類71文字、漢字4文字の追加を行ったために1980年代後半には、旧JIS、新JISというような言葉が生まれるなど大きな混乱をもたらしました。
1990年の第三次規格でさらに2文字を追加して、合計文字数は6,879文字になりました。第四次規格では文字の番号や追加削除は行わず、規定の明確化に努めたとされています。
JIS X 0201 とJIS X 0208を同時に使うための工夫として、マイクロソフトなどが考案したのが、シフトJISコードです。
JIS X 0208-1997ではじめて、シフトJISコードを、JIS規格(付属書)として定めました。
なお、マイクロソフトのアプリケーションが出力するシフトJISは、丸囲数字などNEC拡張文字やIBM拡張漢字などJIS X 0208にない文字を追加しています。従って、厳密には、JIS規格で定めているシフトJISコードとは異なるものです。マイクロソフトのアプリケーションが出力するシフトJISコードの正式名は、Windows-31Jです。
参考
日本工業標準調査会
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月19日
ブラウザで表示できる文字符号化の例
インターネットのWebで、日本にいながらにして世界中の国のホームページを見ることができます。実際に各国の文字を見る機会は、PDFよりもブラウザを使っての方が多いかもしれませんね。
インターネット用ブラウザは、世界中の文字を表示できるようになっています。その中で、最近話題のMozilla Firefoxをチェックしてみましょう。
Firefoxでは、文字の符号化方式を自動的に判別できるようになっています。(Firefoxに限らず、電子メールソフトなどでも同じです。)しかし、もし正しく判別できなかった場合に備えて、自分でも文字符号化方式を選択できるようになっています。
文字符号化をCharacter Encodingといいますが、Firefoxでは文字エンコードメニューで符号化方式を選択します。自分で文字符号化を指定するメニューでは、次の符号化方式がリストされています。
| 地域 | 符号化方式 | 日本語メニュー |
|---|---|---|
| 西欧 | 
|
西欧ISO-8859-1 |
| 西欧ISO-8859-15 | ||
| 西欧IBM-850 | ||
| 西欧MacRoman | ||
| 西欧Windows-1252 | ||
| ケルト語ISO-8859-14 | ||
| ギリシャ語ISO-8859-7 | ||
| ギリシャ語MacGreek | ||
| ギリシャ語Windows-1253 | ||
| アイスランド語MacIcelandic | ||
| 北欧ISO-8859-10 | ||
| 南欧ISO-8859-3 | ||
| 東欧 |  |
バルト語ISO-8859-4 |
| バルト語ISO-8859-13 | ||
| バルト語Windows-1257 | ||
| 中欧IBM-852 | ||
| 中欧ISO-8859-2 | ||
| 中欧MacCE | ||
| 中欧Windows-1250 | ||
| クロアチア語MacCroatioan | ||
| キリル文字IBM-855 | ||
| キリル文字ISO-8859-5 | ||
| キリル文字ISO-IR-111 | ||
| キリル文字KOI8-R | ||
| キリル文字MacCyrillic | ||
| キリル文字Windows-1251 | ||
| キリル文字/ロシア語CP-866 | ||
| キリル文字/ウクライナ語KOI8-U | ||
| キリル文字/ウクライナ語MacUkrainian | ||
| ルーマニア語ISO-8859-16 | ||
| ルーマニア語MacRomanian | ||
| 東アジア |  |
簡体字中国語GB2312 |
| 簡体字中国語GBK | ||
| 簡体字中国語GB18030 | ||
| 簡体字中国語HZ | ||
| 簡体字中国語ISO-2022-CN | ||
| 繁体字中国語Big5 | ||
| 繁体字中国語Big-HKSCS | ||
| 繁体字中国語EUC-TW | ||
| 日本語EUC-JP | ||
| 日本語ISO-2022-JP | ||
| 日本語Shift_JIS | ||
| 韓国語EUC-KR | ||
| 韓国語UHC | ||
| 韓国語JOHAB | ||
| 韓国語ISO-2022-KR | ||
| 西南・東南アジア |  |
アルメニア語ARMSCII-8 |
| グルジア語GEOSTD8 | ||
| タイ語TIS-620 | ||
| タイ語ISO-8859-11 | ||
| タイ語Windows-874 | ||
| トルコ語IBM-857 | ||
| トルコ語ISO-8859-9 | ||
| トルコ語MacTurkish | ||
| トルコ語Windows-1254 | ||
| ベトナム語TCVN | ||
| ベトナム語VISCII | ||
| ベトナム語VPS | ||
| ベトナム語Windows-1258 | ||
| ヒンディー語MacDevanagari | ||
| グジャラート語MacGujarati | ||
| グルムキー語MacGurmukhi | ||
| 中近東 | 
|
アラビア語ISO-8859-6 |
| アラビア語Windows-1256 | ||
| アラビア語IBM-864 | ||
| アラビア語MacArabic | ||
| ペルシャ語MacFarsi | ||
| ヘブライ語ISO-8859-8-I | ||
| ヘブライ語Windows-1255 | ||
| ヘブライ語ISO-8859-8 | ||
| ヘブライ語IBM-862 | ||
| ヘブライ語MacHebrew |
これを見て気がつくのは、ISOなどの標準規格の他に、IBM、Macintosh、Windowsの名前を冠したメーカ定義の符号化方式もあるということです。このように、メーカが独自に文字符号化を定義しなければならなかったのは、旧来の文字規格では、標準化されている文字の種類がすくなく、各メーカがユーザの要望に応じて独自の文字を追加していたためです。
なお、Firefox(特に、日本語訳)では、言語と文字符号化方式をあまり厳密に使い分けていないようですね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2005年12月18日
PDFと文字(6) – 地域別文字規格
文字に関する標準規格には、主に各国の機関が定めている国別標準が昔から使われてきました。
一番古くから使われていて、有名なものにASCIIコードがあります。ASCIIコードはアルファベットを含む128種類の文字を定義しています。
ASCIIコードをベースに国際標準化したものが、ISO 646です。これはさらに、主に西欧言語用に文字コードを拡張してISO 8859シリーズとなっています。(下の表では、Latin Alphabet, Latin/ と表記したもの)。
これとは別に日本ではJISの文字コード規格があり、中国、台湾、韓国などでも同様の文字コード規格が定められています。
下の表に世界の言語に使われる地域別文字規格について、簡単にまとめてみました。
| 言語コード | 言語名称 | 言語名称(日本語) | 使用する文字の種類 | 地域別文字規格 |
|---|---|---|---|---|
| ar | Arabic | アラビア語 | Arabic | ASMO 449, Latin/Arabic Alphabet |
| bg | Bulgarian | ブルガリア語 | Cyrillic | Latin/Cyrillic Alphabet |
| zh-CN | Chinese(Simplified) | 北京中国語(標準中国語マンダリン) | 簡体字(漢字) | GB2312, GB18030 |
| zh-TW | Chinese(Traditional) | 中国語 | 繁体字(漢字) | BIG5 |
| hr | Croatian | クロアチア語 | Latin | Latin Alphabet No.2,10 |
| cs | Czech | チェコ語 | Latin | Latin Alphabet No.2 |
| da | Danish | デンマーク語 | Latin | Latin Alphabet No.1,4,5,6,8,9 |
| nl | Dutch | オランダ語 | Latin | Latin Alphabet No.1,5,9 |
| en | English | 英語 | Latin | Latin Alphabet No.1..10 |
| et | Estonian | エストニア語 | Latin | Latin Alphabet No.4,6,7,9 |
| fi | Finnish | フィンランド語 | Latin | Latin Alphabet No.4,6,7,9,10 |
| fr | French | フランス語 | Latin | Latin Alphabet No.9,10 |
| de | German | ドイツ語 | Latin | Latin Alphabet No.1..10(7除く) |
| el | Greek | ギリシャ語 | Greek | Latin/Greek Alphabet |
| he | Hebrew | ヘブライ語 | Hebrew | Latin/Hebrew Alphabet |
| hu | Hungarian | ハンガリー語 | Latin | Latin Alphabet No.2,10 |
| is | Icelandic | アイスランド語 | Latin | Latin Alphabet No.1,6,9 |
| id | Indonesian | インドネシア語 | Latin | Latin Characters |
| it | Italian | イタリア語 | Latin | Latin Alphabet No.1,3,5,8,9,10 |
| ja | Japanese | 日本語 | Latin、漢字、かな、カタカナ | JIS X0201, JIS X0208, JIS X0212 |
| kk | Kazakh | カザフ語 | Cyrillic | Extended Latin/Cyrillic Alphabet (Cyrillic Asean) |
| ko | Korean | 韓国語 | ハングル、漢字 | KS C5601, KS X1001, Johab |
| lv | Latvian | ラトビア語 | Latin | Latin Alphabet No.4,7 |
| lt | Lithuanian | リトアニア語 | Latin | Latin Alphabet No.4,6,7 |
| no | Norwegian | ノルウェー語 | Latin | Latin Alphabet No.1,4..9 |
| fa | Persian(Farsi) | ペルシャ語 | Arabic | Extended Latin/Arabic Alphabet (Arabic Character 28+ Original 4 Characters) |
| pl | Polish | ポーランド語 | Latin | Latin Alphabet No.2,7,10 |
| pt | Portuguese | ポルトガル語 | Latin | Latin Alphabet No.1,3,5,8,9 |
| ro | Romanian | ルーマニア語 | Latin | Latin Alphabet No.10 |
| ru | Russian | ロシア語 | Cyrillic | koi8-r, Latin/Cyrillic Alphabet 32 Chars (not compatible with Ukrainian) |
| sr | Serbian | セルビア語 | Cyrillic | Latin/Cyrillic Alphabet (Serbian) |
| sk | Slovak | スロバキア語 | Latin | Latin Alphabet No.2 |
| sl | Slovenian | スロベニア語 | Latin | Latin Alphabet No.2,4,6,10 |
| es | Spanish | スペイン語 | Latin | Latin Alphabet No.1,5,8,9 |
| sv | Swedish | スウェーデン語 | Latin | Latin Alphabet No.1,4,5,6,8,9 |
| th | Thai | タイ語 | Thai | TIS 620, Latin/Thai Alphabet |
| tr | Turkish | トルコ語 | Latin | Latin Alphabet No.5 |
| uk | Ukrainian | ウクライナ語 | Cyrillic | koi8-u, Latin/Cyrillic Alphabet 33 Chars |
| vi | Vietnamese | ベトナム語 | Latin | Extended Latin Characters |
言語コードは国際標準化機関ISOが、ISO 639規格を定めています。主に2文字コードが使われていますが、現在は、より多くの言語を表すことができるように3文字コードも決まっています。
参考資料
「bit別冊 インターネット時代の文字コード」 (小林 龍生ほか、共立出版、2001年4月号)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月17日
PDFと文字(5) – テキストを構成する文字
一昨日、テキストとは飾りのない本文文字のみで構成されるデータと言いました。では、そのテキストを構成する文字データとはどのようなものでしょうか?
文字については、コンピュータによる情報処理のために、様々な標準化作業が行われています。そういう標準化作業では、文字とは次のようなものであると言っています。
例えば、JIS X 0221 による定義では、文字(Character)とは、「データの構成、制御または表現に用いる要素の集合の構成単位」と言っています。難しい表現をしていますが、注意しなければならないのは、文字には表現用のものだけでなく、コンピュータのデータを制御するためのものも含むということです。具体的には改行するためのものや、ワープロなどで桁揃えするためのタブなども文字に含むということになります。タブを含むのは、タイプライター時代の名残なんでしょうね。
文字を集めたものを文字集合(Character Set)と言います。
そうして、集めた文字にはひとつづつ番号をつけます。なにしろ、コンピュータですから番号をつけないと処理できないんですね。
再び、X 0221を見ますと、番号のついた文字を符号化文字(Coded Character)、文字集合と符号化の規則をあわせて、符号化文字集合(Coded Character Set)と言っています。
難しい表現ですが、平たく言うと沢山の文字を集めてきて、整理して番号をつけて、その文字の集まりと番号のつけ方について標準化しているといって良いと思います。
文字に関する標準規格は、非常に沢山あります。昔から使われてきた国別の標準に加えて、比較的新しい国際標準であるUnicodeがあります。詳しくは、また別途お話したいと思います。
ところで、文字集合というのは英語のCharacter setの訳語のようですので数学的な集合と考えているのでしょうか。特に、X 0221の定義を見ますと、数学的に厳密にやろうと努力している傾向がうかがえますね。
一方、Unicodeの仕様書を読むと、あまり数学的に厳密にやろうとはしないで、実践的に問題を解決しようとしているという印象を受けます。
このように、文字集合が数学的な集合なのか、単に文字を集めた収集(Collection)なのかについては専門家の間でも議論があるようですね。
Dan Connollyは、Character Set Considered Harmfulで、数学的集合として扱うべきと主張していますが、それに対して、Glenn Adamsは、Re: Character Set Terminology, SC2 vs. SC18 vs. Internet Standardsで、そうじゃないと反論しているようです。
このあたりはとても難しい問題です。だんだん進歩して厳密な定義ができるようになるかもしれませんが、Unicodeは数学的厳密さをもっているとは、到底、言えないと思います。
参考資料
「国際符号化文字集合(UCS)—第一部 体系及び基本多言語面
JIS X 0221 1995」
「The Unicode Standard Version 4.0」 (The Unicode Consortium 著, Addison-Wesley, ISBN 0-321-18578-1, August 2003)
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月16日
「書けまっせPDF」 新発売
アンテナハウスは、新製品「書けまっせPDF」を来年1月下旬に出荷開始します。
「書けまっせPDF」を使うと、WebなどからPDFファイルで配布されている申請書にパソコン上で文字を記入して、記入した文字を含む新しいPDFファイルを作成することができます。文字だけではなく、簡単な図形を書き込むこともできます。
PDFファイルというのは読むだけで、文字を記入することはできないものと考えていた方も多いと思いますが、「書けまっせPDF」は、そんな常識を打ち破り、PDFの電子ファイルとしてのメリットを真に生かすことができるようにします。
企業内では、様々な書式の申請用紙などをPDFで管理しているケースが多いと思います。また、行政機関のホームページからは申請書などが多数PDFファイルとして配布されています。しかし、いままでは、PDF形式の申請書、申告書、申し込み用紙などが折角PDFファイルとして配布されていても、印刷して手書きで文字を記入するケースが多かったと思います。
しかし、これではPDFファイルが電子ファイルであることを生かしているとはいえません。「書けまっせPDF」を使えば、これらのPDFファイルに手元のパソコンを使って、直接、文字や図形記入して、新しいPDFファイルとして作成できますので、PDFファイルをいったん紙にプリントするというような面倒な手間はなくなります。
「書けまっせPDF」は、主に次のような機能をもっています。
①独自のビューアでPDF1.3~1.6仕様準拠のPDFを表示します。 ページのプレビュー機能、しおり機能により、編集したいページへ素早く移動。
②テキストボックスを使用して、PDF上に文字を入力できます。
③PDF上で文字を入力する箇所が実線の矩形で囲まれている場合、 マウスでその位置をクリックするだけで自動的に枠の大きさに合わせたテキストボックスを作成できます。
④文字の他に、四角形、楕円形、対角線、水平線、チェックマークの各図形を入力できます。
⑤データトレー機能は、文字入力を支援するための便利ツールです。氏名や住所、会社や自宅の電話番号など、頻繁に入力を要求される文字列をあらかじめ登録しておくことで、 テキストボックスに簡単に貼り付けることができます。
⑥画面から入力した文字や図形は、元のPDFとともにプリントアウトできます。
⑦入力した文字や図形は、別のPDFファイルに保存することができます。
⑧文字や図形を入力したPDFは、本製品から直接メールソフトを起動して、添付ファイルにして送信することができます。
⑨入力した文字や図形のデータと元のPDFはセットにして保存できます。保存したファイルは何度でも呼び出して変更できます。
標準価格は、7,980円(消費税別)とできるだけお求め安い値段にしました。
発売予定は、2006年1月下旬です。ぜひ、お使いになってみてください。
詳細は、こちらのWebページをご覧ください。
http://www.antenna.co.jp/KPD/
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月15日
PDFと文字(4) – 文字の取り扱い
さて、言語の文字による表現には様々な方法がありますが、例えば、次のような観点で分けてPDFでの扱いがどうなるかを概観してみましょう。
(1)プレーンなテキストとしての文字表現
(2)タイプセッティング、日本語では文字組版
(3)カリグラフィー、書道、あるいは超組版
(4)イラストレーション
まず、テキストとしての文字です。コンピュータ関係者はテキストというとバイナリとの対比をすぐに思いつきます。
ちなみに「テキスト バイナリ」をキーワードにしてGoogleで検索してみると:
[9] テキストとバイナリ - インターネットメールの注意点では「文字コードだけを使ったものをテキストといいます。」と言っています。これはちょっと乱暴すぎるのでは?文字コードってなに?
バイナリファイルとはなにか --- テキスト以外のファイルのことであるでは、「テキストとは、バイトの並びをアスキーコード等を使って文字の並びとして解釈したものです。」と言っています。うん、説明に苦労していることがわかります。
ファイルの保存形式についてでは、「テキスト形式ファイルは、画面に表示できる文字と改行やタブなどのいくつかの特殊文字だけで構成されます。」と説明しています。例えば、電子メールが文字化けして表示されることが時々ありますが、このように画面上で文字化けして表示されてもテキストなのかな?
というような具合でテキストという言葉を説明するのはそんなに簡単ではありません。実際のところ、テキストという言葉はうまい日本語がないように思います。明治の初めに活躍した福沢諭吉のような人なら、漢字をつかったうまい日本語を作るのでしょうが、今は、漢字をあてはめて造語するのではなく、英語のカタカナをそのまま日本語にしてしまうからでしょうね。で、日本語の意味を知るのに、英和辞典を引く、という変なことになってしまうのですが、諦めて英和辞典を引いてみると、「本文、原文」などとあります。これもちょっと違うように思います。
そういうわけで、ここでは、勝手な定義としてテキストとは、飾りのない本文文字のみで構成されるデータと言っておきます。さて、そうするとテキストはPDFでは次のような扱いができます。
①ビューアなどで検索対象になる
②ビューアなどで範囲を指定してコピーして、他のアプリケーションに文字列として貼り付ける
③テキスト抽出機能で文字列として取り出す アンテナハウスのTextPorterとかリッチテキストPDFなどを使って :-)
実は、PDFで表示される文字の中には、テキストとして扱うことができるものと、テキストとして扱うことができないものがあります。
AdobeReaderなどのPDFビューアで文字として見えていても上で述べたようなテキストとして扱えるとは限りません。テキストとして扱うためには、PDFファイルの中にそのための設定データがなければならないのです。
では、どういう時にテキストとして扱うことができて、どういう時にできないでしょうか?これにきちんと回答するのは、現時点ではとても難しくて泥沼にはまりそうなので、とりあえず、AdobeReaderの、![]() ツールで範囲を指定してコピーできれば、テキストとして扱えるとしておきます。範囲を指定しようとしてもカーソルが滑ったようになってしまって範囲を指定できなければ文字として見えていてもテキストとしては扱えません。
ツールで範囲を指定してコピーできれば、テキストとして扱えるとしておきます。範囲を指定しようとしてもカーソルが滑ったようになってしまって範囲を指定できなければ文字として見えていてもテキストとしては扱えません。
上の説明は、堂々めぐり、あるいは、ツールの動作で仕様を説明するという、実際、あまり好ましくない説明とは思いますけれど。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月14日
PDFと文字(3) – 言語と文字 その3
簡体字は中華人民共和国の漢字簡単化政策によって作り出されたもの、という話をしましたが、このように文字は政治や経済と密接な関係があります。
その際立った例をいくつか紹介してみましょう。
まず、イスラエルの国語である現代ヘブライ語があります。
ヘブライ語は、もともと古代パレスチナ人が使っていた言葉ですが、2000年以上前に誰も使わなくなってしまったものです。現代ヘブライ語は、いったん誰も使わなくなった言語をイスラエル建国の際に復活したものです。このヘブライ語を書き表すために使う文字がヘブライ文字です。
ヘブライ語
ベトナム語は、現在は、ラテンアルファベットに文字種を追加した文字で記述されています。この文字は19世紀にフランスの宣教師が考案したものらしいです。東南アジアの南方はインド文化の影響を受けているようですが、ベトナムとはもともと「越南」の読みなのだそうで、ベトナム語は漢字の偏旁を独自に組み合わせて作ったチュノムで表記されていたようです。
ベトナム語
ところで「三国志」では蜀の諸葛孔明が何度か南方遠征をしますが、ベトナムまで行ったのでしょうか?
フィリピンの公用語のひとつであるタガログ語も昔はインド起源の文字を用いていたようですが、現在は、ラテンアルファベット表記に変わっています。
タガログ語
政治的理由から比較的短い期間に、文字政策が変わった地域もあります。例えば、新疆ウイグル自治区は、1949年に人民政府に帰順して中華人民共和国の一部になりました。その当時は、ソ連と中国の蜜月時代ということもあり、ウイグル語をキリル文字で表記しようとしたそうです。ところが、中ソ緊張の時代になるとともにキリル文字はあっさり解消、次は、漢字のピンイン法案によりラテン文字表記をしようとしました。その後、1982年になって元のアラビア文字に基づく表記にもどったそうです。
中国・新疆ウイグル自治区における文字と印刷・出版文化の歴史と現状(菅原 純)
いままでお話しましたのは、ごく一部の言語の例です。世界には、数千種類(一説には6000種類)といわれる言語があります。
それぞれの言語は表記方法である文字がなければ記録として残すことができません。ですので表記の手段として文字をもつということは、その言語の文化を伝え、あるいは遠くの人と意思を伝えていくために大変重要なものです。
PDFは紙に表記された情報を電子的化するものですので、PDFでもこのような様々な文字を扱えなければなりません。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月13日
PDFと文字(2) – 言語と文字 続き
昨日、漢字のお話をしました。漢字は中国で生まれ、中国の文化と共に周辺の国に渡って、その国の言語を表記するのに使われるようになったということはご存知のことと思います。
漢字と同じように、文化圏の広がりと共に周辺地域に普及し、その地域の言語表記に使われるようになった文字にアラビア文字があります。
アラビア文字とアラビア語を英語で表すといづれもArabicとなるため混同し易く、よく間違えますが、この二つは別の概念です。間違えないように使い分けないといけないですね。
アラビア語は聖典クルアーンの言語として、世界各地のイスラム教徒に親しまれています。このイスラム教とアラブ文化圏の広がりに伴い、アラビア文字はペルシャ語(イラン・イスラーム共和国)、ウルドゥ語(パキスタン)、現代ウイグル語(中国新疆ウイグル自治区)などの表記にも使われています。アラビア文字の場合も、ラテンアルファベット同様に、アラビア語以外では、その言語特有の音を表記するための文字・記号類が追加されています。
アラビア系文字
「アラビア系文字の基礎知識」
キリル文字もロシアをはじめスラヴ系の多数の言語の表記に使われています。ソヴィエト連邦の解体にともない、キリル文字で表記していた言語の中でラテン文字表記に変更しているものもあるようです。このように表記する文字を変更することは世代間のコミュニケーションに深刻な問題をもたらす可能性があります。
キリル文字(フリー百科事典『ウィキペディア(Wikipedia)』)
東南アジアのタイ語、ラオス語、カンボジア語は、それぞれ特有の文字( タイ文字、ラオス文字、クメール文字)で表記されます。日本語のひらながとカタカナは50音というくらい、音節と文字が一対一の関係があります。これに対して、タイ語、ラオス語、カンボジア語では、発音の音素と文字字形(グリフ)が一対一に対応せず、並び時も発音順でないという複雑な関係になっています。
タイ語,ラオス語,カンボジア語(クメール語)の文字処理と組版における課題
東南アジア大陸部のインド系文字
インドには850~1700の言語があるようですが、その中でもヒンディー語は人口の約4割で使われているとのこと。ヒンディー語を表記するのに使われているのがデーヴァナーガリー文字です。この文字は、組み合わせによる表示形の変化(リガチャ)の種類が極めて多いため、コンピュータ処理の難関といえます。
インドの言語と文字
デーヴァナーガリー文字
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月12日
PDFと文字(1) – 言語と文字
さて、PDFは紙を電子化したものなので、紙の上に表現できるあらゆる情報を表現することができます。それらの情報の中で、特に、文字がPDFでどのように取り扱われているかを、これからしばらくの間、お話してみたいと思います。
文字とはなんでしょうか?こういう哲学的、大上段に構えた質問をしてしまうと、なかなか答えることが難しいものですね。そこで、少し、具体的に考えて見ましょう。
私たち日本人は、日常会話では日本語を話し、そうして日本語で書かれた新聞、雑誌、書籍、インターネットのページ、ブログページを書いたり読んだりしています。このような日本語の記事は、漢字、ひらがな、かたかな、句読点、括弧類などの記号を使って表記します。
ここから類推して、簡単に言えば、言語を表記するツールが文字であると考えて良いと思います。
長い年月でみれば、特定の言語の表記に使う文字の種類はかなり変遷します。例えば、江戸時代より以前、墨と筆で文字を書いていたときは、恐らく句読点や括弧類はなかったのでしょう。句読点が定着したのは明治三九年、文部大臣官房図書課が『句読法案』を発表してからのことなのだそうです。
句読点研究会
最近の携帯電話には、いろいろな絵文字が登録されています。このような絵文字が市民権を得て、皆が使う日がいづれ到来するのでしょうか?あるいは廃れてしまうのでしょうか?このように文字と認めて良いかどうか、意見が分かれる記号も沢山あります。
英語は、26種類のアルファベットの大文字と小文字、カンマ、ピリオド、感嘆符、引用符などの記号類を使って表記します。
フランス語ではアクセントを多用するため、26種類のアルファベットでは足りず、Accute accent, Grave accent, Circomflex accent, Diacresis, Cedillaの5種類のアクセントをつけた15文字を追加して使います。括弧記号も英語とは違います。
ドイツ語は、26種類のアルファベットに加えて、ドイツ語特有のウムラウト付き文字 (A with diacresis, O with diacresis, U with diacresis) とエスツェット (Sharp S) を追加しています。
お隣の韓国・北朝鮮の言語は朝鮮語ですが、現在は、ハングル文字による表記が主流です。ハングル文字は、1443年に発明された比較的新しい文字で、それ以前は朝鮮語の表記は漢字によっていたようです。
朝鮮語
漢字の本家、中国では、漢字簡易化政策の下に1950年、1960年代に漢字を簡体字にしてしまいました。このため、漢字には、現在、大陸で使われている簡体字と、台湾を中心に使われている繁体字の2種類があります。
「近現代中国における言語政策」 藤井 久美子 2003年2月23日 株式会社三元社発行
コンピュータの世界で、CJK文字といえば漢字のことを言うのですが、現在は、このように日本、中国、韓国の漢字事情は、それぞれ相当に異なっています。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月11日
PDFの作成方法(19) – まとめ
PDFの作成方法について、ひとまず、次の表のように整理しておきます。
アンテナハウス製品について、ブログではあまり詳しく言及しませんでしたが、ご参考までに、該当するものを入れておきました。
| 方式 | 主な製品・サービスなど | 特徴 |
|---|---|---|
| PostScriptファイルをPDFに変換 | Distiller、GhostScript | 既存のPostScriptファイルやEPSファイルのPDF化などに適用 |
| PostScritpプリンタ・ドライバ | Acrobat PDF、JawsPDFCreator | アプリケーションの「印刷」メニューで文書をPDF化する(EPSのPDF化、やり方によってカラーマネジメントなども可能) |
| GDIプリンタ・ドライバ | いきなりPDF 2/いきなりPDF Professional 2、アンテナハウスPDFドライバ | アプリケーションの「印刷」メニューでビジネス文書をPDF化する(EPSのPDF化ができない、カラーはWindows依存になる) |
| PDF生成ライブラリーを使い直接PDFを書き出す | PDFLib、アンテナハウスPDF生成ライブラリーなど各種ライブラリー | 主にサーバサイドPDF生成、XSL FormatterでXMLからPDF変換 |
| Adobe PDF Library | Illsutrator、InDesignなどで商業印刷用PDFを作成する | |
| スキャナーの画像をPDF化 | スキャナ製品 | 紙に印刷された書類の電子化用。Adobe Readerをビューアとして使える |
| Fax受信データのPDF化 | まいとーくサーバ、インターネットFaxサービス | Adobe ReaderをFax受信データのビューアとして使える |
| スキャナーの画像をOCRで文字認識して透明テキスト付きPDF化 | 複合機(スキャナとOCRソフト機能付き) | 紙に印刷された書類の電子化用。電子化文書(画像)中の文字情報をテキストとして扱って検索できる |
○記事へのリンク
全体
(1) 全体の仕組み
PostScriptファイルをPDFに変換
(2) PostScriptの登場
(3) PostScriptファイルを作る
(4) PostScriptからPDFへ
(7) Distiller互換ソフト
(8) PostScriptにない機能は
EPS
EPS 続き
プリンタ・ドライバ方式全般
PostScriptプリンタドライバとGDI型PDFプリンタドライバの相違
(13) PDFの対話的機能
(14) PDF Maker
PostScritpプリンタ・ドライバ
(5) AcrobatでPDF
(6) Acrobat PDF
GDIプリンタ・ドライバ
(11) GDI型PDFプリンタ・ドライバ
(12) いきなりPDF
PDFLibなど各種ライブラリー
(9) PDF出力ライブラリー
(10) PDFの大量生産へ
Adobe PDF Library
(18) InDesign, Illustrator
スキャナーの画像をPDF化
(15) スキャナーでPDF作成
Fax受信データのPDF化
(16) Fax受信のPDF
スキャナーの画像をOCRで文字認識して透明テキスト付きPDF化
(17) デジタル複合機
透明テキスト付きPDF
PDFを作成する方法として特徴的なものは、網羅していると思いますが、PDF作成ソフトは、フリーのものから高価格なものまで多数ありますので、漏れている方式があるかもしれません。私の知らない方法をご存知の方は、ぜひお知らせください。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2005年12月10日
PDFの作成方法(18) – InDesign, Illustrator
これまで、18回にわたり、PDFの作成方法をいろいろお話してきました。最後に、もうひとつ重要な、あるいは、印刷の専門家からみたら「これを説明してもらわなければもぐりじゃない?」という方法を説明して、ひとまず終わりにしましょう。
それは、IllustratorやInDesignなどで直接PDFを出力する、本家・本元のこれぞPDF葵の御紋というものです。
これらは、さすがに、ご本家の製品だけあって、IllustratorもInDesignもPDF作成機能は充実しています。そこで、簡単にPDFを作ってみましょう。
Illustrator(CS2)でPDFを作成するのは、「印刷」メニューではなく、「別名で保存」または「複製を保存」を使います。また、InDesignでは「書き出し」メニューでファイルタイプを「Adobe PDF」に指定します。
それぞれでPDFを作ってみて、プロパティを見ますと、次の図のようになります。通常、AcrobatでPDFを作成しますと、PDFProducer(作成者)はDistillerになります。しかし、IllustratorとInDesignで作成したPDFファイルはいずれも作成者がAdobe PDF Libraryになっています。このことから、恐らく、これらのアプリケーションはプリンタ・ドライバ方式ではなくて、PDFを直接生成する方式を取っていると推測できます。
○Illustratorで作成したPDFのプロパティ

○InDesignで作成したPDFのプロパティ

これは、IllustratorとInDesignでは、PDFを作成する時に、様々なPDFの機能をきめ細かく設定するためでしょう。
例えば、Illustratorでは、PDF作成時に、レイヤー化されたPDF、カラーマネジメントとPDF/X準拠のPDF作成、トンボと断ち落としの設定などができますが、これらはプリンタ・ドライバ経由でPDFファイルを作成する方法では難しいでしょう。
このようにPDFでは、ものすごく様々な機能を使うことができます。特に、高度な印刷用のPDFファイルを作ろうとしますと一般的なプリンタ・ドライバ方式では、それをPDFに設定することが難しくなります。
一般に商用印刷などに使うPDFを作るアプリケーションでは、①高度な機能をもつPDF生成ライブラリーを使い、②PDFを作成するアプリケーション側から、PDF生成ライブラリーをきめ細かく制御してPDFファイルを作成することが必要になります。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2005年12月09日
透明テキスト付きPDF
紙に印刷された書類をスキャンして、スキャナーが生成したイメージからPDFファイルを作成した場合、次の問題があります:もともと文字で表されている情報なのに、PDFファイルでは文字情報として扱えないことです。
すなわち、コンピュータで文字情報を取り扱うためには、文字をコード化されたデータとして扱わなければならないのに、スキャンした結果は画像だからです。この問題を解決するのが透明テキスト付きPDFです。
透明テキスト付PDFとは、スキャナーで読み取った画像をOCR機能をつかって文字を認識し、コード化した情報(テキスト)として、PDFの画像の上に透明属性を持たせて重ねたもの。PDFファイルの内容である文字情報を利用したいときは、テキストを取り出して利用できます。また、PDFファイルの中を検索してヒットした文字列の該当部分を反転表示することもできます。
透明テキスト付きPDFのアイデアは、恐らくOCR関係者が考えたものと思います。仕組みを聞いてみれば、特に驚くほどのことはないですが、こういうアイデアを初めて考え出した人は、なかなかすごいものですね。
一昔前のスキャナソフトは、OCRで文字認識した結果を、MicrosoftWord、Excelあるいは一太郎に変換できるのが売りだったと思います。いまのOCRソフトはすでにそのレベルは超えて、多くのものは、透明テキスト付きPDFまで作ることができるようです。
OCRソフトの一通りの紹介は、例えばこちら:
OCRソフトの紹介
ところでOCRで文字認識した結果を、もとの画像に重ねるというアイデアはすごいものですが、実は、完全には重ならないようです。
次の例を見てください。これは、透明テキスト付きPDFをAcrobat6で表示して、「消費電力」という文字列を検索したものです。検索対象は、透明な文字で、ヒットした文字列に相当する部分が白黒反転されています。地の「消費電力」という文字と検索でヒットした文字の位置(白黒反転されている範囲)がずれていますね。
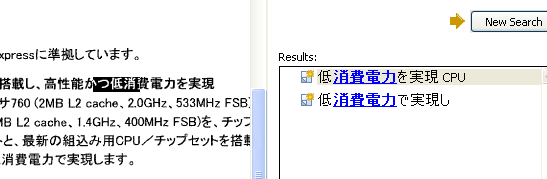
次の図は、同じファイルを「自在眼9」のPDF表示機能を使って、同じ「消費電力」という文字列を検索したものです。Acrobatと同じようにずれていますね。

というわけで、二つのPDF表示ソフトで同じようにずれてしまうのですが、これはPDFを作る際に透明文字の位置がずれているためです。このように画像と文字がずれてしまうこともあることは知っていると良いと思います。
画像と認識した文字をぴったり重ねるのは技術的には可能と思います。可能であるからには、完全に重なるようなOCRソフトもあるかもしれません。おそらく、このあたりはOCRソフト次第なのでしょう。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2005年12月08日
PDFの作成方法(17) – デジタル複合機
FAX、スキャナ、プリンタ、複写機を統合したデジタル複合機が増えています。複合機では、PDFの作成については、既に述べたスキャナーやFAX受信とほとんど同じといえるでしょう。
さらに、デジタル複合機は、コンピュータと同じようにOS(オペレーティング・システム)を搭載していて、いろいろなアプリケーションを連携して動作させることができるのが特徴です。
例えば、リコーのimagio Neoシリーズのニュース:
デジタル複合機だけで、さまざまなセキュリティ設定をしたPDFファイルを簡単に作成するimagio Neoシリーズ用アプリケーションソフト「imagio 暗号化PDF タイプA」を新発売
こういうビジネス用の高級機ならいろいろな機能があっても驚きませんが、ブラザーのデジタル複合機MyMio DCP-110Cなんて、Amazonで9,480円(税込み)なのに、 ドキュメント管理ソフトまでついていて、色々なフォーマットのファイルからPDFファイルを作成でき、複数枚の原稿を1つのPDFファイルにまとめることもできるようです。ちょっと驚きですね。
スキャナーで紙文書をスキャンしてPDFファイルを作成したり、FAXで受け取った文書をPDF保存したりするのは、単機能機でもできることは既に述べました。
さらに複合機になってコンピュータを搭載していれば、作成したPDFファイルを電子メールに添付して送信したり、OCRにかけて透明テキスト付きPDFにしたり、画像を圧縮したり、あるいは、PDFファイルに暗号を掛けるなど、アプリケーションを増やしていくことで機能の追加が可能になります。
既に紙になっている書類を電子化しようとしたら、一番手っ取り早いのはスキャナで読み取ることです。特に、e文書法の施行に伴い、従来紙で保存が義務付けられていた書類の電子保存が認められることになったということで、紙の書類を電子化する需要は拡大するものと思います。
こうしたことから、ビジネスから個人まで、しばらくは、デジタル複合機はうけに入りそうに思います。
ただ、問題は、このようなデジタル複合機で作成したファイルは基本的にはビットマップの画像データです。透明テキストをつけて検索可能にしたものも増えているとは言っても、このテキストは書式を持っているわけではないでしょう。
パソコンでOffice文書からPDFファイルを作成した場合、PDFの内部は命令の集合です。これに対して画像データをPDF化したものの実体は画像に過ぎません。表示した見かけは似ていても、中身はまったく違うものです。PDFファイルを再利用したり、検索したり、印刷したりという観点からは、相当に異なります。
なんでもPDFファイル化できるという柔軟さが混乱を招く結果にならなければ良いですが。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月07日
PDFの作成方法(16) – Fax受信のPDF
画像系PDFのもうひとつの作成方式として、FAXで受信した内容をPDF保存する方式があります。PDFが普及する前は、FAXソフトはFAX受信内容をTIFFやJPEGなどで保存していましたが、最近のFAX受信ソフトには、受信データをPDFにする機能がついているものがあります。
例えば、メガソフトの「StarFax2005」は、受信データをPDF化して電子メールに転送できます。
また、インターコム社の「まいとーくFAX Server5」は、受信FAXのPDFエクスポート機能がついています。
ソフトだけではありません。インターネットFAXサービスでは受信したFAXをPDFにしてメールで受け取ることもできます。
アンテナハウスのアメリカ法人でも、FAX受信にはインターネットFAX(eFax.com)を利用しています。このサービスでは、お客様からアメリカ法人のFAX番号宛に送られた注文書をPDF化して、電子メールで届けてくれます。そのPDFファイルは日本に転送されてきて、出荷担当に回ります。このサービスは確かに便利なのですが、FAX原稿は手書きが多いため、判読困難で困ることもあります。そんな訳で、FAXの受信データをPDF化しても、そのメリットはビューアとしてAdobe Readerを使えるということぐらいで、それ以外には大きなメリットはないようにも感じています。
Faxの受信データは、PDFではなく他の画像形式でも良いのではないでしょうか?
ところで、インターコムは、2003年に「マイトーク7Pro」に業界初のPDF送受信機能をつけたと発表しています→同社のニュースリリース。しかし、「マイトーク8Pro」にはその機能が見当たりません。なぜなんでしょうね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月06日
PDFの作成方法(15) – スキャナーでPDF作成
11月1日にPDFの作成方法(1)に示した図ではパソコンのアプリケーションでPDFを作成する方法を整理しました。しかし、重要なPDF作成手段が抜けていました。それは、スキャナなどで作成した画像をPDF化する方法です。
紙に印刷された文書を電子化するには、紙をスキャナーで読み取り、その結果を電子ファイルにします。PDFが普及する前は、スキャナーで読み取った結果はTIFFなどの画像形式で保存していました。しかし、現在は、スキャナーで読み取った結果をTIFFではなくPDFで保存する方がむしろ主流になっているように見えます。
Acrobatではスキャナから取り込んだ画像をPDF変換できます。
また、スキャナーにはPDF保存機能があります。例えば、新世代スキャナが仕事を変える?ペーパーレス化はビジネスマンの夢を見ると、大抵のスキャナはPDF保存機能が備わっているようです。
また、スキャナから取り込んだデータを整理するサード・パーティのソフトウエア製品でもPDF保存機能を使えます。Part3. PDFにして紙文書をデジタル化。
既にお話しましたようにPDFの起源はPostSriptです。そんなこともあり、私はスキャナの画像からPDFファイルを作るなんて邪道と思っていたのです。ところが、ブログで取り上げるために少し調べてみたところ、スキャナーでPDFを作る方法には、TIFFではできない様々なメリットがあります。
(1)PDFにすることで、無料配布のAdobeViewerdで誰でも内容を見ることができます。これに対してTIFFは様々な種類があり、あらゆる形式のTIFFを表示するのは困難です。この結果、TIFFの形式によっては表示できない可能性があります。
(2)PDF化することで検索可能にできます。最近は、画像の上に透明テキストを重ねる形式のPDFを作ることで、透明テキストを使ってPDFを検索できるようになっています。
(3)PDFで保存するとTIFFと比べてファイル形式を小さくできることになります。
PDFの起源からはスキャナーで読み取った結果をPDFにするという発想は出てきません。しかし、ブログを書いたお陰で、スキャナーで作成した画像からPDFを作成する方法についての自分の認識を改めることになりました。
【参考】
スキャナーの小咄: ファイル形式とデータ量について
投稿者 koba : 08:00 | コメント (2) | トラックバック
2005年12月05日
PDFの書籍一覧
現在、国内で販売されているPDFに関する書籍についてまとめてみました。
一覧は以下のように記述しています。
書籍名(Amazon.co.jpにリンクしています)
(著者、税込価格、出版社、ISBN、発売日)
【基本・入門】
はじめてのAcrobat 7.0
(大沢 文孝、1,995円、工学社、4777511413、2005/06)
ビジネスで活用するAcrobat 7.0入門
(Professional DTP編集部、2,415円、工学社、4777510980、2005/01)
WindowsユーザーのためのPDF&Acrobat7.0入門
(福田 良一、2,310円、オーム社、4274500209、2005/04/25)
事例引きPDF「作成・編集」ハンドブック
(森里 悠、1,680円、新紀元社、4775300458、2002/01)
【DTP】
Word+Acrobat DTP出力実践ガイドブック
(山木 大志、2,940円、毎日コミュニケーションズ、4839918392、2005/10)
クロスメディアパブリッシング FrameMaker7.0/Windows版
(臼井 理栄、4,200円、九天社、4901676415、2003/06)
最新WindowsDTP標準テキスト
(黒田 聡、永山 嘉昭、2,940円、日経BP社、4822281361、2002/05)
pdf+print2.0―PDFプリプレス読本
(Bernd Zipper、2,625円、工学社、4875934297、2003/06)
Acrobat6.0+PDF パワー・クリエイターズ・ガイド
(諌山 研一、チバ ヒデトシ、大橋 幸二、2,520円、アスペクト、4757209924、2003/09)
最新WindowsDTP標準テキスト
(黒田 聡、永山 嘉昭、2,940円、日経BP社、4822281361、2002/05)
DTP実務者のためのAcrobat PDF活用ガイド
(上高地 仁、2,940円、毎日コミュニケーションズ、483990698X、2002/03)
【仕様】
PDFリファレンス第2版 - Adobe Portable Document Format Version 1.3
(アドビシステムズ、7,140円、ピアソンエデュケーション、4894713381、2001/09)
【その他】
PDF Hacks
(Sid Steward、2,520円、オライリー・ジャパン、4873112222、2005/03)
PDFでスッキリ!情報アイデア整理術
(宝島社、1,155円、宝島社、4796648259、2005/08/29)
図解でわかるAcrobat・PDFのすべて
(山名 一郎、蛭田 龍郎、2,100円、日本実業出版社、4534030509、2000/03)
TEX+PHP+データベースによるPDF自動生成サーバの構築/運用
(ミッチー@rootbox、3,129円、技術評論社、4774121754、2004/11)
ユビキタスドキュメントがビジネスを超速化する!
(中島 洋、ユビキタスドキュメント研究会、1,260円、実業之日本社、4408106321、2005/07)
PostScript & Acrobat/PDF
(Thomas Merz、5,775円、東京電機大学出版局、4501528907、1998/11)
2005年12月04日
Microsoft XPSでPDFに対抗 (4) – XPS仕様(続き)
では、XML Paper Specification(XPS)とは、どのようなものでしょうか?
XPSの仕様書をざっと見てみましょう。まずXPSドキュメントの基本構成要素はFixedPage パーツです。FixedPageの概要は次のようなもので、要するにPDFまたは紙の1ページに相当します。
①FixedPageにはページ上に可視化するすべての視覚的要素、すなわちグラフィックスとテキストを含む。
②各ページは大きさと方向をもち、ページ上のレイアウトは決定済。
FixedPageをいくつかまとめるとFixedDocumentができます。このFixedDocumentに順序をつけて束ねたものがXPSのドキュメント本文パーツ(FixedDocumentSequence Part)となります。要するに紙を束ねた書類がドキュメントの本文パーツということです。
XSPドキュメントのパッケージには、本文パーツ以外に、①サムネイル・パーツ、②プリント・チケット・パーツ、③注釈パーツ、④フォント・パーツ、⑤イメージ・パーツがあります。
たとえば、本文パーツが使用しているフォントは、フォント・パーツにその実体をもちます。そしてXPSドキュメントの中にパッケージ化されます。これにより、XPSドキュメントを配布したとき、相手先のPCでは、生産者が指定したフォントがなくても、XPSドキュメントを指定どおりのフォントを使って印刷できることになります。
イメージを本文とは別のパーツにしているのは、本文で同じイメージを何回も使うとき、別のパーツとしてのイメージを参照することで、イメージの実体を一つだけもてば良いからです。
現在までに、Microsoftと協力してMetroの開発を行ってきた会社の殆どはプリンタ・メーカとプリンタ・メーカ向けにWindows用のプリンタ・ドライバの開発を行っているソフトウエア会社です。これは、Metroが従来のGDIベースの印刷サブシステムがもつ弱点を乗り越える新しい印刷パスとしての位置づけで開発されてきたといういきさつがあるからだろうと思います。
しかし、XPSの仕様書をみると、XPSは単なる印刷システム用のスプールファイル形式ではなく、紙に類似する用紙を定義し、その上にレイアウトされたドキュメントを配布するための機能を持っています。しかも、フォントの埋め込をすることもできますし、サムネイル、リンク、注釈などの機能ももち、限りなくPDFに近くなっています。
少なくとも、XPSはPDFに競合する使い方を意図して設計されているということはできるでしょう。
【参考資料】
XML Paper Specification
XPS と、Windows Vista でのカラー印刷の拡張機能
投稿者 koba : 08:00 | コメント (2) | トラックバック
2005年12月03日
Microsoft XPSでPDFに対抗 (3) – XPS仕様
Metroの仕様書0.7版は、「Open Packaging Conventions 0.75版」(OPC)と「An Open XML Paper Specification 0.75版」(XPS)に分割されました。
0.75版で仕様書を二つに分割した目的は、OPCの適用範囲を、XPSのみではなくMicrosoft Office12のXML文書などにも広げるためでしょう。つまり、XPSというのは印刷形式のファイルですが、それだけではなくOffice12のネイティブなXMLファイルまでOPCを使うことになりそうです。
OPCの仕様書では、情報の生産者と情報の消費者の間で、情報の内容や情報源をどうやってひとまとめに(パッケージ化)して受け渡すかを決めています。パッケージを作り出す生産者は、インターネット上のサーバ、LAN上のサーバ、デスクトップPCなどであり、パッケージを使う消費者は、デスクトップPC上のビューアや、LANやデスクトップPCに接続したプリンタにあたります。
パーツという基本構成要素をまとめてパッケージを作ります。例えば、XMLを使って外部の画像を参照するテキスト文書を作成するとき、テキスト部分がひとつのパーツ、画像がもうひとつのパーツになります。これを一まとめにしたものがパッケージです。
あるパーツからは、パッケージ内部のパーツのみでなく、外部のパーツも参照できます。パッケージには参照関係をまとめて定義する関係部もあります。
パッケージ全体はZIPで圧縮されて受け渡します。
OPC仕様の特徴は次の点です:
①パッケージのパーツや関係部の記述などすべてXML仕様に準拠している。
②消費者がパッケージを開けてみなくても内容がわかるようなサムネイルを付けることができるようになっていること。
③パッケージに対してデジタル署名を付けることができること。パッケージ全体はXMLで記述されますので、デジタル署名にはXML シグネチャを使います。
XMLでドキュメントを作成すると、外部参照している画像ファイルなど多数のファイルに分かれてしまうため受け渡しの際の管理が面倒、という問題があります。このOPCはXMLドキュメントの受け渡しのためのパッケージ化にも使えるかもしれませんね。
ところで今日のお話には、PDFが一回も出てきませんでした。代わりにXMLがいっぱい出てきて閉口した人もいるかもしれません。PDFとXMLというのは相異なる目的で生まれてきたものなのですが、しかし、現在は両方ともデータとドキュメントの表現には欠かせないものとなってきています。いづれ、PDFとXMLの関係について、まとめてお話したいと思いますので、ご勘弁ください。
【参考資料】
Open Packaging Conventions:Specification and License Downloads
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月02日
Microsoft XPSでPDFに対抗 (2) – XPSの情報源
まず、XPSに関する情報源をチェックしてみます。XPSに関する情報は10月以降相当な量で公開されていて、MicrosoftがXPSに対して並々ならぬ注力をしていることが伺われます。
但し、10月のMicrosoft PDCでの発表がひとつの山場だったとみえて、10月の発言が多いようです。11月になると開発者のブログへの書き込みは減っているようにも思います。なんとなく、思い付きでブログを開設して、あとが続いていない人もいるような印象も受けますけれども。
1. XPSのメインページ
XPS XML Paper Specification:日本語
XPS XML Paper Specification:英語
このメインページには、XPSに関する資料へのリンクが一通りあります。そこで、以下では、その一部だけを紹介することにします。
2.仕様書類
XML Paper Specification
Open Packaging Conventions
4月22日付けのMetro Specification and Reference Guide V0.7は、9月11日付のXML Paper Specification V0.75とOpen Packaging Conventions V0.75に置き換わりました。12月末までに、V0.8をリリースする予定で、その間の改訂情報は、XPSプロジェクトのブログページに掲載されるとのことです。
3.XPSプロジェクトのブログページ
XPS Team Blog - XML Paper Specification and the Open Packaging Conventions
2005年11月16日に開設されました。開設の目的は、XPSとOpen Packaging Conventionsの仕様に関して、改訂情報の提供と、プログラム、アイデアなどについて交換するためのブログ。18日付けでXSP 0.8に向けて仕様の改訂情報が公開されています。 このブログがプロジェクトの公式ブログになりそうです。
4.Microsoft関係者のブログ
Andy Simonds: XPS and the Digital Documents Team
Andy Simondsは、Windows Digital Documents Teamのグループ・プログラム・マネージャ。このブログは、10月5日から開始されています。
Feng Yuanは、MicrosoftでGDI, GDI+, Avalon and printingに関する開発に従事しています。このブログではプログラム開発者の立場での説明が多いようです。
Brian Jones: Office XML Formats
Brian Jonesは、Officeのファイル・フォーマットの普及活動の担当者のようです。OfficeでXPS保存する機能についての発言をチェックしましょう。
他にもありますが全部は見切れませんので、このくらいにしておきます。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月01日
Microsoft XPSでPDFに対抗 (1)
Microsoftが来年発売する新しいOS Windows Vistaの発表、ベータ版の配布が始まりました。Vistaには新しくMetroという印刷用の共通プラットフォームが用意されます。
2005/08/03 Windows Vistaの新しい印刷プラットフォーム“Metro”—@IT
Metroについての概要は4月に発表されたようですが、その発表以来、いろいろなメディアがMetroはPDFキラーではないかと書き立てています。
日本語で読めるMetroに関する記事には次のようなものがあります。これを読むと、Microsoftの発表に接した記者達が、MetroはアドビシステムズのPostScriptやPDFと似ているという印象をもったことがよく分かります。
2005/05/06 マイクロソフトの「Metro」はPDFキラーになるか— CNET Japan
2005/04/27 Microsoft の新ファイル形式は『PDF』キラー? — Japan Internet Com
2005/04/26 MS、PDF対抗の文書フォーマット「Metro」を披露— IT media
アドビシステムズとマイクロソフトの競争関係を含めて、MetroとPDFの関係についてはマスコミ関係者ならずとも関心の深いところでしょう。
Metroは開発コードでした。現在は、XPS(XML Paper Specification)と名前が変わっています。この名前の付け方からしても、いかにもPDF対抗という雰囲気がありますね。そもそもPDFは紙に相当する電子媒体です。XPSが紙(Paper)のXMLによる定義ということであれば、XPSというのは、まさにPDFをXML言語で表したということを意味します。なんとなくMicrosoftの野心が見えるような気がします。
そこで、少し、PDFとMetro(改めXPS)との関係について考えて見たいと思います。
(参考)
XPS XML Paper Specification