« PDFの作成方法(17) – デジタル複合機 | メイン | PDFの作成方法(18) – InDesign, Illustrator »
2005年12月09日
透明テキスト付きPDF
紙に印刷された書類をスキャンして、スキャナーが生成したイメージからPDFファイルを作成した場合、次の問題があります:もともと文字で表されている情報なのに、PDFファイルでは文字情報として扱えないことです。
すなわち、コンピュータで文字情報を取り扱うためには、文字をコード化されたデータとして扱わなければならないのに、スキャンした結果は画像だからです。この問題を解決するのが透明テキスト付きPDFです。
透明テキスト付PDFとは、スキャナーで読み取った画像をOCR機能をつかって文字を認識し、コード化した情報(テキスト)として、PDFの画像の上に透明属性を持たせて重ねたもの。PDFファイルの内容である文字情報を利用したいときは、テキストを取り出して利用できます。また、PDFファイルの中を検索してヒットした文字列の該当部分を反転表示することもできます。
透明テキスト付きPDFのアイデアは、恐らくOCR関係者が考えたものと思います。仕組みを聞いてみれば、特に驚くほどのことはないですが、こういうアイデアを初めて考え出した人は、なかなかすごいものですね。
一昔前のスキャナソフトは、OCRで文字認識した結果を、MicrosoftWord、Excelあるいは一太郎に変換できるのが売りだったと思います。いまのOCRソフトはすでにそのレベルは超えて、多くのものは、透明テキスト付きPDFまで作ることができるようです。
OCRソフトの一通りの紹介は、例えばこちら:
OCRソフトの紹介
ところでOCRで文字認識した結果を、もとの画像に重ねるというアイデアはすごいものですが、実は、完全には重ならないようです。
次の例を見てください。これは、透明テキスト付きPDFをAcrobat6で表示して、「消費電力」という文字列を検索したものです。検索対象は、透明な文字で、ヒットした文字列に相当する部分が白黒反転されています。地の「消費電力」という文字と検索でヒットした文字の位置(白黒反転されている範囲)がずれていますね。
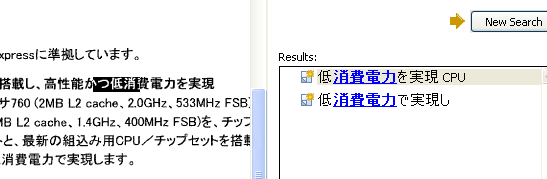
次の図は、同じファイルを「自在眼9」のPDF表示機能を使って、同じ「消費電力」という文字列を検索したものです。Acrobatと同じようにずれていますね。

というわけで、二つのPDF表示ソフトで同じようにずれてしまうのですが、これはPDFを作る際に透明文字の位置がずれているためです。このように画像と文字がずれてしまうこともあることは知っていると良いと思います。
画像と認識した文字をぴったり重ねるのは技術的には可能と思います。可能であるからには、完全に重なるようなOCRソフトもあるかもしれません。おそらく、このあたりはOCRソフト次第なのでしょう。
投稿者 koba : 2005年12月09日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/77
コメント
昨日、店頭でScanPaper for PDF見て即座に買いました。
「透明テキスト」を知らなかったのですがその機能を店頭で知り、それがが使えるというだけで買ってしまいました。
さっそく使ってみましたが、すでに作成していたPDFを入力ファイルに出来るのがよかったです。文字認識率は200DPI位のファイルでもまあまあです。
誤変換された全ての文字をキレイに1対1で完璧にしておくつもりはありません。 (個人利用の範囲では、)後で「あのファイル何処行った?]と思い出す時に必要なキーワードだけが文字になっていればよいので、その分だけ必要ならScanPaperで修正しておくという方法をとっていこうと考えています。
投稿者 プラウド : 2006年02月11日 09:29