2008年03月15日
Elliotte Rusty HaroldのXMLの未来予言(2)
昨日の続き
■Atom Publishing Protocol (APP)
1.従来、クライアントからサーバへのアップロードはFTPであった。しかし、初心者にはFTPは理解できない。
2.APPを使えば、URLとユーザ名とパスワードだけで、WebにPOSTできるので、この問題は解決する。
■データベース
1.XMLをファイルシステムに置くのは、データの重複、検索などの都合上、効率が良くない。
2.リレーショナル・データベースは、XMLの保存には、データ構造上適切でない。
3.XMLデータベースが増えてきた。
ロー・エンド: eXist, Berkeley DBXML
ハイ・エンド:Mark Logic, IBM DB2 9pureXML
■XQuery
1.XQuery 1.0 は何年もの開発の後、とうとうリリースされた。2008年には更新が完成しないかもしれないが、十分使えるレベルである。
2.2008年には、javax.xml.xqueryもリリースされるはず。
-----ここまで----
【私的感想】
Elliotte Rusty Harold氏は、さすがに、 「XMLバイブル」の著者だけあって、なかなか、よく状況をまとめていると思います。しかし、私には、あまり同意できない箇所もあります。
特に、オーサリングのあたりはあまり同意できません。特に、次の点。
1.彼はPublishingと言いながら、XHTMLとHTMLしか頭に無いようです。HTMLにするだけなら、わざわざOfficeを使わなくっても、「ホームページ・ビルダー」で十分じゃないかと思います。
2.OfficeでXMLをまともにオーサリングするのは至難だと思います。一番困るのは、属性を入力する方法がないということ。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年03月14日
Elliotte Rusty HaroldのXMLの未来予言(1)
The future of XML(Elliotte Rusty Harold)
■夢占い
1.過去3年間は、Webアプリケーションが、伝統的なWebサイトの遥か先まで進んだ時期であった。ワープロ、表計算。。すべてブラウザに乗った。
2.Sunの夢は、Javaではなく、JavaScriptで実現した。Sunの最大の誤算。
3.ブラウザがOSに取って代わるというetscapeの夢が実現しつつある。もはやOSを気にする人は居ない。
4.Ajax=JavaScript+XML。xはXMLを表すとはいうものの、XMLはこの動きにそれ程関係していない。
5.DOMが問題。開発者はDOMしか知ろうとせず、DOMとXMLの区別を知らない。DOMは、XMLを処理するのには最悪のAPIである。
6.DOMは、XMLの首に掛かった重荷。ソフトウエア業界がXMLを採用を進めるための最大の障害である。W3Cは、悪い仕様を廃止すべきだ。
7.XMLは死んだのか?
■XMLのルーツ
1.XMLの基本仕様はどれもソフトウエア開発用に設計されたものではない。出版/Web出版を意図したものだ。
2.XMLの前身であるSGMLは出版用。SGMLの最大の成功であるHTMLは最大の失敗例でもある。ブラウザ開発者もデザイナも誰一人SGMLを知らず、勝手な拡張でSGMLパーサもHTMLを解析できない。
3.XMLはSGMLを軽くする目的では成功。しかし、Webに整合性をもたらす目的では失敗。XHTMLはHTMLの方言に過ぎない。
4.XMLソフト開発用ではないが、プラットフォーム独立、国際的なデータ形式、入手しやすい無償パーサで、開発者の役に立っている。
5.出版という点では、編集、出版、読者について考えてみることが必要。
■編集
1.編集という意味では戦いはXMLの勝利で終わった。MS Office、OpenOfficeなどすべてXML形式になった。
2.政府が、OpenDocやオープン・ソースに移行することで、MS Officeは徐々にシェアを失うだろう。
3.XML形式になって、バイナリ形式と比べて、他の形式に変換するのが格段に楽になった。
4.2008年は、ゲームの枠を変えるXML最大の技術XSLT誕生10周年である。フォーマットについて、あまり気にしなくても良くなり、ベンダー・ロックインが問題でなくなった。
5.OOXML、OpenDocからHTMLへの変換が重要。
6.XMLとXSLTで過去の隠れたデータも表に出てくる。
7.編集ツールは、WordやOpenOfficeで決まりだ。
---続く---
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年09月05日
DITA導入の効果について
YahooのDITAユーザズ・グループの議論を見ていましたら、参考になりそうな、興味深い議論がでていましたので、以下に簡単に紹介します。
■8月30日に、DITA初心者のCrystalさんが投げた質問からスタートしています。
質問は、概略で、次のようなものです。
「現在、Crystalさんの会社では、RoboHelpとFrameMakerを使って、WebHelpとPDFを作っているのですが、なにか変更がある度に2つのツールで内容を変更しなければならない。DITAを使えば、ひとつのレポジトリにデータを保管しておき、印刷とオンライン・ヘルプの両方ができそうに思えるだが、どうだろうか?なにかアドバイスは?」
これに対していろいろな人が回答して、かなり長いストーリーになっています。
■8月31日 Markさんの回答
・DITAは、まだ成長途中だ。私は、最近、FrameMaker+DITAに移行した。いまは動いているが、移行するのに6ヶ月も掛かって、かなり大変だった。現在は、OpenToolKitでHTML Helpを作成し、FrameMakerでPDFを作っている。しかし、急ぐのでないなら、あと、1年位待つ方が良いのではないかな?
・FrameMakerは、DITAのグローバルな検索ができないのは悲しい。ファイルを跨る検索には、サードパーティのテキスト・エディタを使わなければならない。
■8月30日 Troyさんの回答:この人はOracleのInformation Archtectの肩書き
・いままで7年ほどXMLのプロジェクトを担当していて、いろいろやってきたが、いまはDITAを使っている。
・DITAはものすごく柔軟でいろいろなことができ、プログラムの能力さえあれば、なんでもできる。
・DTPのようなスタイルとコンテンツが分離されていないシステムから、DITAを使ってコンテンツとスタイルを分離することで大きな効果がある。
-XMLからPDFやHTMLをビルドするシステムを作っておき、
-翻訳部門にXMLを渡して、翻訳してもらう。
-他の言語を英語と同じ、ビルド・プロセスを通して、PDFやHTMLを作るようにする。
-旧システムでは、大勢の人間が関与していたが、新しいシステムでは自動的に多言語のアウトプットを得られる。こうしたことで、非常に大きなコスト削減になる。
・データにプレゼンテーション(見栄え)を埋め込むのを止めることが、最も基本的なことである。
・次に構造を抽象化するのが第二ステップ。
・そして、ファイルからのリンクを関係表に抽象化する。
ある程度の規模の会社になれば、ドキュメントをビルドする仕組みの面倒をみることのできるエンジニアがいるが、DITAについても同様で、XSLTや他のXMLのスキルのある人間が必要である。レガシーなドキュメントを構造化するのは、一から始める必要がある。
DITAを実装するのは、脳外科の手術のようなものだ。手術の最中には、スキル、注意、麻酔などが必要だけど、手術が終われば完全に新しい脳を手に入れることができる。
※ちなみに、Troyさんは、9月1日のメールで、前回のプロジェクトでは、DITAからPDFを作るのにAntenna HouseのXSL Formatterを使った。DITAの数千のトピックを扱えるのは、XSL Formatterしかなかった。他の製品は皆、途中で、沈没する船のようにメモリ不足で沈んでしまった、と述べています。
この部分、引用しておきましょう。
"In a past project, my team and I explicitly went out of our way to avoid Frame as an intermediary for PDF production, using a common XML source for both online and PDF presentations. We used XSLT for online help and XSL:FO with the Antenna House processor for the PDF production. At the time, the Antenna House processor was the only solution that could handle the overhead of thousands of topics. Everything else leaked memory like a sinking ship. The Antenna House XSL:FO processor isn't open source, but the license cost was nothing compared to the former production costs of manually adjusted PDFs."
ライターは、構造化文書について詳しくないなら、新しい情報アーキテクチャを勉強する必要があり、プログラマのように考える必要がある。とにかく、ツールではなく、スキルが重要。
■8月31日Bobさん
・確かにスキルが重要なことは賛成する。トピックを書いて、出版のためにマップに組み立てるのは、プログラマのスキルが必要。
■8月31日Markさん
・現在のところ、DITAの最適なツールはない。特に、50人程度の規模の小さな会社に向いたのはない。使いやすいDITAのツールで多数のフォーマットを出力してくれるようなものは、だいぶ先じゃないか?
■8月31日Keithさん
・昨年と今年、かなりDITAのことを調べたが、使うには複雑すぎると思った。いまのところ、FrameとWebWorksをまだ使っていて、小さなプロジェクトだけ、DITAを勉強するために使っている。
このあたりの議論を読んでいますと、次のような印象をもちます。
比較的大きな規模の会社だと、専門のプログラマ・技術者をアサインして、ドキュメントをビルドする仕組みを用意できるので、システムを作ってDITAに移行すると生産性がかなり上がる。しかし、小さな会社だと技術的なスキルを持った人がいないので、ツール頼みにならざるを得ない。しかし、まだツールは十分に簡単になっていない。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月15日
XMLによる法制システム — ニュージーランドPALのケース
先日のOpen Publishで、XMLによる法制システムのとても興味深い報告がありました。このことは、
2007年03月10日Open Publish Conference — XML オーサリングで少し触れたのですが、Webで調べてみましたところ、ニュージーランドでは、法律を公衆に公開するシステム(Public Access to Legistlation)の大掛かりなプロジェクトが進んでいるようです。
ところがこのプロジェクトが、途中で大幅に遅延し、開発費が大幅増になって、問題になったのですね。このプロジェクトは、2003年2月から運用を開始する予定だったようですが、いろいろ問題があり、2003年~2004年は停止、結局、2005年に復活、しかし2006年の秋現在ではまだ完成していません。Web上では2007年央から稼動の予定となっています。
プロジェクトを行っているのは、議会書記局です。システム開発はUnisys。議会書記局のWebページにプロジェクトの経費がどうなったのか、ということまで様々な情報が公開されています。この情報公開の姿勢は日本政府もぜひ見習って欲しいものです。
Parliamentary Counsel OfficeのWebページ
Public Access to Legislation Project
まだ、全ての情報を詳しく読んでいないのですが、このシステムは立法のための草稿から完成までをXMLで行うもののようです。
政府レベルの話なのでかなり大掛かりなものですが、ケーススタディとしてもなかなか興味があります。
XML編集システムは、PTC/ArborTextのEpicEditorを使い、組版はFOSIを採用、ArborTextのPrintComposerを使おうとしたようです。
ところが、システムのパフォーマンスに大きな問題がありました。大勢の人が懸念をもち、外部のコンサルタントに依頼してシステムについて技術レビューを行っています。
Final Report—New Zealand PCO Technical Assurance Review(技術レビュー)
特にFOSIの複雑さ、メンテナンスの悪さ、パフォーマンスの悪さが問題のようです。
6.2.2 Epic Print Composer—the Print Rendering Tool
には、PrintComposerのパーフォーマンスの悪さが書かれています。
誰か他の人が大きなBillを作っていると、20分も待たされると。
結局、組版エンジンがかなり大きな問題になったようで、組版エンジンだけで次のレポートがあります。
Rendering Engine Review—Final Report(組版エンジンの評価レポート)
ここで評価の対象になっているのは、
3.1 ArborText E3 (ADG)
3.2 XyVision XPP (XyVision or ADG)
3.3 Advent Publishing 3B2 (Allette Systems)
3.4 Elkera XML Print (Elkera)
でXSL-FOは残念ながらまだ代替候補になっていません。将来は、XSL-FOに変わるかもしれない、というような書き方です。2004年にしては感度が鈍すぎると思いますが。アンテナハウスのXSL Formatterを選んでいれば、プロジェクトがこんなに難航しなかったのではないか、と言ったらいい過ぎでしょうか。
2000年に、実装協力者を募集していますので、XSL-FOには少々早すぎたのかもしれません。しかし、2004年の再評価には立候補するべきでした。知っていれば!!ニュージーランドまで行ったのですが、残念です。
XSL Formatterは国レベルの立法システムでは、カナダ政府で2000年代前半から使われています。カナダでは、英語とフランス語で翻訳ではなく、平行して法律を作るようです。やはりニュージーランドよりはカナダの方が進んでいる?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年12月12日
XSL-FO 2.0 Workshop続き
先週、ボストンでXML Conference 2006 がありました。残念ながら私は参加できませんでしたが、XSL-FO 2.0 についての発表があったようです。
XSL-FO 2.0といえば、10月のハイデルベルグでの会議の報告が公開されています。
Report from International Workshop on the future of the Extensible Stylesheet Language (XSL-FO) Version 2.0
以前に、ブログの第367話~370話で、この会議のことを報告しましたが、会議のレポートが公開されていますので、少し補足してしたいと思います。
レポートは3部に分かれています。
Vertical Text
XSL-FO 2.0 作業委員会では、まず、日本の印刷技術協会の作業委員会を代表して、ジャストシステムの大野氏が、Japanese Document Layout Presentation というタイトルでプレゼンテーションを行っています。このプレゼンテーションのファイルが公開されています。この作業委員会は、ジャストシステムの提唱で設立されたもののようですが、XSL-FO・CSSに日本語組版の機能を追加するように要求を出そうということで、2006年春先からずっと準備していたものなのです。ドイツでの報告はそのサマリのみでしたが、当日は参加者から大変な注目を集めました。
その翌日に、XSL-FOワーキング・グループのみの会議がありました。アンテナハウスはワーキング・グループにも参加しましたが、そこで大野氏のスライドについてもう一度、1枚ずつ、解説を求められまして、みんなでおさらいをしたくらいです。
XSL-FOワーキング・グループは、日本語組版にも大きな関心をもっていることは確かです。ただし、実際のところ、日本語組版について彼らのところに情報があまり入っていないということが実態なんですね。
JIS X4051の英語版(翻訳)が欲しい、と言っていましたが、その後、どうしたのでしょうか。
Requirements
その次は、1998年にXSLのワーキング・グループスタート時点でのXSL Requirements Summaryの話が出ています。8年前の要求事項について、再度、必要度の確認をしています。
レポートの最後に、CSS Compatibilityという見出しがありますが、これはアンテナハウスから提出したレポートについてのことです。
Everyone wanted it, but in fact there were zero votes for compatibility with 3.0, one or two votes for compatibility with CSS 2.1, and none for CSS 2.0; no-one wanted to lost backwards compatibility with XSL-FO 1.0 or 1.1 in order to improve compatibility with the CSS 3 working drafts.
CSSとの互換性は総論賛成、各論反対。だれもCSS 3.0との互換性は望んでないとか、書いてあります。ホントにそうなんでしょうかね。
【参考】
# 第370話 2006年10月21日 W3C Print Symposium 2006 (4) XSL-WG
# 第369話 2006年10月20日 W3C Print Symposium 2006 (3) XSL-FOとCSSの互換性
# 第368話 2006年10月19日 W3C Print Symposium 2006 (2)
# 第367話 2006年10月18日 W3C Print Symposium 2006 (1)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月26日
XSL-FO 2.0
XXX 2.0流行のこの頃ですが、XSL-FO 2.0会議が10月18日に開催されます。
Workshop on the Future of the Extensible Stylesheet Language (XSL-FO) Version 2.0
18 October 2006
Heidelberg, Germany
Located at offices of Heidelberger Druckmaschinen AG
XSL-FOは、そろそろV1.1が勧告になりますので、次は2.0を作ろうということです。
W3CでXSL-FOの開発が始まってからそろそろ8年(もう8年というべきでしょうか)。
アンテナハウスがXSL Formatterを開発初めてからちょうど7年になります。
XSL-FOは海外ではかなり普及していると思います。
しかし、日本では、実際のところ、かなり良い利用例も出てきているのですが、今ひとつ普及が進んでいないように思います。
先日、ジャストシステムの「2006年3月決算期事業戦略説明会」の資料をみてましたら、27ページにXML技術に関するHype Cycleという図が出ていました。(出展はガートナーグループの資料となっています。)
この図では、XSL-FOは、Peak of Inflated Expectations(過剰に膨らんだ期待のピーク)に分類されています。しかし、ちょっと違うんじゃないかな?もう、とっくにピークもTrough of Disillusionment(幻滅の時期)も過ぎて、安定した実用の時代に入っているように思います。
なんにしてもXSL-FO 2.0には期待大です。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年08月24日
DITA への関心が急激に高まっています
日本でDITA(Darwin Information Typing Architecture)について知っている人は、XMLについてかなりのディープな人だと思いますけれども、欧米では、DITAへの関心が急激に高まっているようです。
次の図は、YahooのDITA-Usersのメッセージ投稿数の月別推移です。
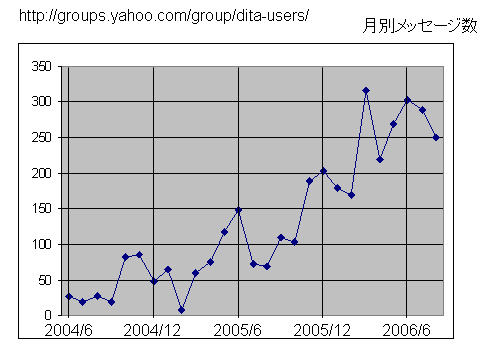
これを見ますと非常な急カーブでメッセージ投稿数が増えていることが分かります。
DITA-Usersグループは、DITAについて関心を持っている人が参加して情報交換するメーリング・リストなのですが、メッセージ投稿数が増えているということは、欧米でDITAに関心をもつ層が急速に増えていることを示しています。
DITAは、2005年5月にOASISの標準として策定されました。また、2005年9月に多言語組版研究会で取り上げましたが、その頃から比べてもメッセージ投稿数が2倍~3倍になっています。
今年の11月には、ヨーロッパで第2回DITAヨーロッパ会議もあります。要注目です。
ちなみに、DITAをPDFにするスタイルシートは、アンテナハウス、IBM、IDIOMの3社からオープンソースで提供されています。
※参考資料
DITA XML (Darwin Information Typing Architecture)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月07日
書籍の自動組版について
今日は、あるIT系の出版社に行きまして、「書籍の自動組版について」というテーマで簡単なプレゼンをしました。
プレゼン資料をここにあげておきます。
書籍の自動組版について
今日のミーティングでは、自動組版には拒否反応がありました。一般的に言って、出版社の人達は、IT系であろうがなかろうが、保守的な人が多いように感じます。
こう書いて、何年か前に、ある出版社の人がまったく同じことをいってたな、と思い出しました。どこの会社か忘れてしまいましたが。
しかし、私自身は、もはや書籍を、QuarkやInDesignで1ページ幾らで制作会社に発注して制作する時代はとっくに終わったと思っています。
ところで、このプレゼン資料を作るにあたり、O'Reillyの書籍のサンプルページをいくつかダウンロードしてみましたところ、FrameMakerで制作しているものが多いようです。書籍をFrameMakerで制作するのは日本では珍しいのではないでしょうか。
特に、米国や英国の出版社は、教科書などを含めて、インドなどにアウトソースする傾向があります。アウトソースするには、コンテンツとレイアウトを分離すると便利なんだそうです。そういう点からもコンテンツのXML化が進んでいると聞いています。このあたりにも日本と米欧の違いを感じます。
日本の出版社にもなんとかしてXMLとXSL-FOで本を自動組版する時代をもたらさねばならないとひそかに決意している次第です。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年07月02日
XSL-FOによるXMLのPDF化 まとめ
6月6日から7月1日まで、お話してきました、
「XSL-FOによるXMLのPDF化」
の内容を少し整理して、XML資料室にアップしました。
こちらからご覧いただけます。
資料がお役にたてれば、また、皆様のご意見、ご感想をいただければ幸いです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月01日
XSL-FOによるXMLのPDF化(22) XSL-FOはマークアップ文書スタイル付けの正統派
いままで見てきましたように、XSL-FOでは、フォーマット化オブジェクトに対して、フォーマット化特性を指定して、組版結果の見栄えやレイアウトなどをきめ細かく指定できます。
フォーマット化オブジェクト毎に指定可能な特性が多数ありますので、この組み合わせは膨大になります。この結果、XSL-FOではCSSよりも遥かに詳細なレイアウト設定が可能になります。
XSL-FOでなぜこのような詳細な仕様ができたかと言いますと、これには、米国を中心とする企業のタグ付き文書の組版への取り組みの歴史があります。
XML以前にSGMLというタグ付き文書の仕様があったことは、前にお話しました。
SGMLにレイアウトを指定して組版するためにDSSSL仕様が1986-87年に開発が始まったと言います。DSSSLの仕様は、10年近い年月をかけてISO/IEC 10179:1996になりました。
この間、DSSSLの仕様完成を待てずに、FOSIの仕様が作成されました。FOSIは暫定的なものとして位置づけられたようで、1997年の仕様が最終版となっています。
XSL-FOのV1.0仕様策定の中心になったのは、IBMのSharon Adler女史とAnders Berglund氏ですが、この二人は、DSSSLの仕様策定にも参画したようです。こうしてDSSSLの仕様がXSL-FOに大きな影響を及ぼしていることになります。
XSL-FOはCSSよりも後に開発が始まったことから、いままで説明しましたようにCSSの仕様も取り込んでいます。XSL-FOが、マークアップ文書を組版するための血統をすべて引き継いだ仕様となっているわけです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月30日
XSL-FOによるXMLのPDF化(21) XSL-FOの概要 10
(26) その他の特性
V1.0では、次の9つの特性が定義されています。
content-type
id
provisional-label-separation
provisional-distance-between-starts
ref-id
score-spaces
src
visibility
z-index
V1.1では、次の特性が追加になりました。
change-bar-class
change-bar-color
change-bar-offset
change-bar-placement
change-bar-style
change-bar-width
intrinsic-scale-value
page-citation-strategy
scale-option
change-bar-* は、改訂バーのスタイルを指定するものです。また、page-citation-strategyは、新しく追加されたfo:page-number-citation-last(参照先領域の最終ページを示す)に適用して、最終ページの種類を全て、本文、非ブランクページ(ヘッダ、フッタなどのみのページ)のどれかに指定するものです。
(27) 簡略記述特性
例えば、border(境界線)は、4つの辺にそれぞれ幅、線種、色などを指定できます。簡略記述は、それらをまとめて指定すると、組版エンジンが個別指定として設定するものです。
background
background-position
border
border-bottom
border-color
border-left
border-right
border-style
border-spacing
border-top
border-width
cue
font
margin
padding
page-break-after
page-break-before
page-break-inside
pause
position
size
vertical-align
white-space
xml:lang
一般に、XSL-FOでは、CSSよりも詳しい指定ができるのですが、CSSの指定を簡略記述として、XSL-FOの指定に置き換えるようになっています。
例えば、簡略記述white-space(CSS2と同じ)は次のようにXSL-FOの複数の特性に置き換えられます。
white-space="normal"
linefeed-treatment="treat-as-space"
white-space-collapse="true"
white-space-treatment="ignore-if-surrounding-linefeed"
wrap-option="wrap"
white-space="pre"
linefeed-treatment="preserve"
white-space-collapse="false"
white-space-treatment="preserve"
wrap-option="no-wrap"
white-space="nowrap"
linefeed-treatment="treat-as-space"
white-space-collapse="true"
white-space-treatment="ignore-if-surrounding-linefeed"
wrap-option="no-wrap"
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月29日
XSL-FOによるXMLのPDF化 (20) XSL-FOの概要 9
(22) 数値から文字列への変換に関する特性
数値から文字列に変換する時の形式を定義しています。ページ番号などの書式を設定するのに使います。
format
grouping-separator
grouping-size
letter-value
例えば format="ア" と指定するとカタカナで番号をつけることになります。
V1.0とV1.1で変わりません。
(23) ページ付け及びレイアウト特性
blank-or-not-blank
column-count
column-gap
extent
flow-name
force-page-count
initial-page-number
master-name
master-reference
maximum-repeats
media-usage
odd-or-even
page-height
page-position
page-width
precedence
region-name
(24) 表特性
表のスタイルを指定する特性です。表の罫線、カラム幅、カラムスパンなどを指定できます。
border-after-precedence
border-before-precedence
border-collapse
border-end-precedence
border-separation
border-start-precedence
caption-side
column-number
column-width
empty-cells
ends-row
number-columns-repeated
number-columns-spanned
number-rows-spanned
starts-row
table-layout
table-omit-footer-at-break
table-omit-header-at-break
V1.0とV1.1で変わりません。
(25) 表記方向関連特性
文字を書き進める方向に関係するものです。
direction
glyph-orientation-horizontal
glyph-orientation-vertical
text-altitude
text-depth
unicode-bidi
writing-mode
directionは、CSSの仕様から来ているもので行内の文字を進める方向のみを指定します。writing-modeはXSLの仕様で行を進める方向と行内で文字を進める方向の両方を指定できます。unicode-bidiは、日本の文字や英語の文字のように左から右へ書く文字とアラビア文字のように右から左へ書く文字が混在したときに文字を書く方向を制御するための特性です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月28日
XSL-FOによるXMLのPDF化 (19) XSL-FOの概要 8
(16)保持及び区切り特性
ブロック領域、箇条書き、表の行に適用されます。当該の領域の前後でページや段を区切るかどうかを指定するのがbreak-*、前後の領域とページや段が分かれないように指定するのが、keep-*です。
break-after
break-before
keep-together
keep-with-next
keep-with-previous
orphans
widows
V1.0とV1.1で変更ありません。
(17) レイアウト関連特性
この中でreference-orientationはページまたは枠のような領域に指定し、領域を回転させることができます。
clip
overflow
reference-orientation
span
V1.0とV1.1で変更ありません。
(18) リーダ及び罫線特性
リーダ線や罫線のパターン、太さなどを指定します。
leader-alignment
leader-pattern
eader-pattern-width
leader-length
rule-style
rule-thickness
V1.0とV1.1で変更ありません。
(19) 動的な効果があるフォーマット化オブジェクトに関する特性
external-destination、internal-destination使って、PDFの内部リンク先、外部リンク先を指定できます。
active-state
auto-restore
case-name
case-title
destination-placement-offset
external-destination
indicate-destination
internal-destination
show-destination
starting-state
switch-to
target-presentation-context
target-processing-context
target-stylesheet
V1.0とV1.1で変更ありません。
(20) 索引に関する特性 (V1.1新設)
V1.1で追加された索引作成機能で使うための特性です。
index-class
index-key
page-number-treatment
merge-ranges-across-index-key-references
merge-sequential-page-numbers
merge-pages-across-index-key-references
ref-index-key
(21) マーカに関する特性
V1.0では、ページ単位でランニング・ヘッダ、爪などを作るために使うことができました。
marker-class-name
retrieve-class-name
retrieve-position
retrieve-boundary
V1.1で次の二つの特性が追加されました。これは、表の前後でマーカを検索するための追加機能です。
retrieve-boundary-within-table
retrieve-position-within-table
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月26日
XSL-FOによるXMLのPDF化 (18) XSL-FOの概要 7
(12) ブロック及び行関連特性
ブロック領域の中で行をどのように配置していくかを指定する特性です。line-height、text-align、text-indentはCSSに由来します。さらにXSL-FOではきめ細かい指定ができます。
hyphenation-keep
hyphenation-ladder-count
last-line-end-indent
line-height
line-height-shift-adjustment
line-stacking-strategy
linefeed-treatment
white-space-treatment
text-align
text-align-last
text-indent
white-space-collapse
wrap-option
V1.0とV1.1で変更ありません。
(13) 文字特性
テキストの文字間を調整するletter-spacing、飾りを指定するtext-decoration、text-shadow、大文字・小文字の調整を指定するtext-transform、単語間の調整用のword-spacingなどはCSSから由来しています。XSL-FOでは更にきめ細かく調整できるようになっています。
character
letter-spacing
suppress-at-line-break
text-decoration
text-shadow
text-transform
treat-as-word-space
word-spacing
V1.0からV1.1で変更ありません。
(14) 色特性
色の指定のための特性です。
color
color-profile-name
rendering-intent
V1.0とV1.1で変更ありません。
(15) 浮動体関連特性
浮動するボックスの配置に関する指定で、CSSに由来します。
clear
float
intrusion-displace
CSS2ではleft、rightなどの指定をしますが、XSL-FOのV1.0でstart、endが拡張されています。
さらに、V1.1でoutside、insideの拡張がなされました。これで浮動ボックス領域を見開きページの外側、内側へ配置できるようになりました。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月25日
XSL-FOによるXMLのPDF化 (17) XSL-FOの概要 6
(8) 一般的なマージン特性-行内
行内レベルの領域では、領域の前方(start)と後方(end)に空き量を指定できます。この場合の前方、後方というのは、横書きでは、それぞれ領域の左、右になります。
space-end
space-start
この空き量も、スペース指定子を使って最小値、最適値、最大値を指定します。
V1.1仕様書では次の4つの特性が追加されています。
margin-top
margin-bottom
margin-left
margin-right
但し、これは仕様書の書き方が変わっただけです。もともと margin-* はCSSでの指定方法です。これはXSL-FOでは、ブロックレベルの space-before, space-after, start-indent, end-indent とインラインレベルの space-start, space-end のどちらにも変換されるようになっていました。
(9) 一般的な相対位置決め特性
CSS2から引き継いだものです。V1.0ではひとつだけです。
relative-position
CSS2 では position プロパティだったのが、XSL では absolute-position プロパティと relative-position に分かれ、position プロパティは shorthand の扱いとなりました。
V1.1で次の4つの特性が追加になりました。
top
right
bottom
left
これもmargin-* と同様、仕様書の書き方が変わっただけで、内容は変わっていません。top、right、bottom、left プロパティは、absolute-position とrelative-position の両方で使われるものです。XSL 1.0 の仕様書の書き方では、両方にあてはまるものは一方にだけ記載されていたのが、XSL 1.1 では両方に記載されるようになりました。
(10) 領域配置特性
行内レベルのオブジェクトや表のセル、箇条書きの項目を行の上、下、各種のベースラインの位置などに対してどのように配置するかをきめ細かく指定するための特性です。
alignment-adjust
alignment-baseline
baseline-shift
display-align
dominant-baseline
relative-align
V1.0 とV1.1で変わっていません。
(11) 領域寸法特性
ブロックレベルの領域の大きさ、あるいは行内レベルの領域の大きさなどの寸法を指定するための特性です。V1.0では次の12項目が定義されています。
block-progression-dimension
content-height
content-width
height
inline-progression-dimension
max-height
max-width
min-height
min-width
scaling
scaling-method
width
CSSでは、height(高さ)、width(幅)しかありません。これに対して、XSL-FOでは、writing-modeで行と文字の進行方向の指定ができますので、height(高さ)、width(幅)の指定では不十分です。そこでブロックの進行方向の寸法(block-progression-dimension)、行内の進行方向の寸法(inline-progression-dimension)という指定方法を導入しています。例えば、widthは横書きではinline-progression-dimensionに対応しますが、縦書きではblock-progression-dimensionに対応します。
V1.1では、新しく、次の2項目が追加になりました。
allowed-height-scale
allowed-width-scale
これらは、グラフィックスを拡大縮小させるときの制約を指定するのに使います。
投稿者 koba : 09:30 | コメント (0) | トラックバック
2006年06月24日
XSL-FOによるXMLのPDF化 (16) XSL-FOの概要 5
(5) 一般的なフォント特性
fo:blockに適用するフォントの特性を指定するものです。これらの特性は全てCSS2と同じです。
font-family
font-selection-strategy
font-size
font-stretch
font-size-adjust
font-style
font-variant
font-weight
V1.0とV1.1で変更はありません。
(6) 一般的なハイフン付け特性
西欧の言語を組み版する時のハイフネーションの指定方法です。
country
language
script
hyphenate
hyphenation-character
hyphenation-push-character-count
hyphenation-remain-character-count
country、language、scriptはハイフネーション規則を切り替えるためだけではなく、例えばフランス語とドイツ語では組版の規則も多少の違いがありますので、そういった組版規則の切り替えにも使います。
これらの特性はV1.0とV1.1で変更ありません。
(7) 一般的なマージン特性-ブロック
ブロック領域の周囲の空き量を指定します。4種類のmargin特性はCSS2との互換性のために設けられたものです。XSL-FOでは、margin指定をspace、indentの指定に換算します。
margin-top
margin-bottom
margin-left
margin-right
space-before
space-after
start-indent
end-indent
空き量(space)の指定は、スペース指定子という仕組みで指定します。スペース指定子は、最小値,最適値及び最大値の3つの値を同時に指定することで、組版ソフトが、ページ内に入る行数などの調整を行なうことを許します。さらに前後のスペースをページの先頭や最後に来たときは無視するかしないかなどの条件付けをしたり、前後の空き量との優先順位も指定できます。
V1.0とV1.1で変更ありません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月23日
XSL-FOによるXMLのPDF化 (15) XSL-FOの概要 4
4.2.2 フォーマット化特性(Formatting Property)
組版の対象となるFOに対して、どのようにレイアウトするかを指定するのが、フォーマット化特性です。
(1) FOとフォーマット化特性の関係
例えば、fo:blockという段落を囲む領域については、背景の色、四辺の境界線の種類・色・太さ、インデントやマージン、前後のブロックとの空き量、フォントファミリー、フォントサイズなど、様々な特性を指定することができます。
fo:block-containerについても同じように背景、境界、マージンなどの特性を指定できます。しかし、fo:block-containerには直接テキストを含むことができませんので、フォント関連のようなテキストに対する特性は指定できません。fo:block-conatinerの中にfo:blockを配置して、fo:blockにテキストを含めます。
一方で、fo:block-containerには、reference-orientation特性を指定して、周囲に対して回転させることができます。また、writing-mode特性を使って縦書きも指定できます。block-progression-dimension (またはheight)特性で高さを指定したり、inline-progression-dimension (またはwidth)特性で幅を指定できます。
このように、それぞれのFOに対して適用できるフォーマット化特性が決まっています。
次にどのようなフォーマット化特性があるかを挙げてみます。これらの特性の多くはCSSを元にして、必要に応じて拡張されています。
(1) 一般的なアクセス性特性
V1.0とV1.1とも次の2種類があります。
source-document
role
(2) 一般的な絶対位置決め特性
V1.0とV1.1とも次の5種類があります。
absolute-position
top
right
bottom
left
(3) 一般的な聴覚特性
これは、PDF化というよりも、音声読み上げなどのタイプのレンダラを想定する特性です。XMLからPDFに変換するタイプの組版エンジンは未対応となっています。リストは省略します。
(4) 一般的な境界,パディング及び背景特性
領域の背景、境界線に関する特性です。領域の4辺について別々に指定できます。before、after、start、endという指定方法とtop、bottom、left、rightという指定方法があります。一般的な横書きでは、beforeはtop、afterがbottom、startがleft、endがrightになります。縦書きでは、beforeはright、afterはleft、startがtop、endがbottomに対応します。パディングは、境界線と文字を配置する内容領域の間隔です。V1.0 とV1.1で変わりありません。
background-attachment
background-color
background-image
background-repeat
background-position-horizontal
background-position-vertical
border-before-color
border-before-style
border-before-width
border-after-color
border-after-style
border-after-width
border-start-color
border-start-style
border-start-width
border-end-color
border-end-style
border-end-width
border-top-color
border-top-style
border-top-width
border-bottom-color
border-bottom-style
border-bottom-width
border-left-color
border-left-style
border-left-width
border-right-color
border-right-style
border-right-width
padding-before
padding-after
padding-start
padding-end
padding-top
padding-bottom
padding-left
padding-right
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月22日
XSL-FOによるXMLのPDF化 (14) XSL-FOの概要 3
(6) 動的な効果:リンク及び多重フォーマット化オブジェクト
V1.0 では次の6つのオブジェクトが定義されています。
fo:basic-link
fo:multi-switch
fo:multi-case
fo:multi-toggle
fo:multi-properties
fo:multi-property-set
basic-linkは、PDFを生成したとき、内部リンク(例:<:basic-link internal-destination="appendix-a">)や外部リンク(例:<:basic-link external-destination="http://www.antenna.co.jp/...">)を設定するのに使われます。
V1.1での追加はありません。
(7) 行外フォーマット化オブジェクト
V1.0 では次の3つのオブジェクトが定義されています。
fo:float
fo:footnote
fo:footnote-body
V1.1での追加はありません。
(8) その他のフォーマット化オブジェクト
V1.0 では次の3つのオブジェクトが定義されています。
fo:wrapper
fo:marker
fo:retrieve-marker
V1.1では、次の3つが追加になりました。
fo:change-bar-begin
fo:change-bar-end
fo:retrieve-table-marker
change-barというのは、改訂された箇所の欄外に印の線を引く機能です。FOSIの重要な機能だそうです。
retrieve-table-markerによって、表が前のページから続いていたり、次のページに続いていることを示すことができるようになります。
V1.0にはなくて、V1.1で新たに追加されたカテゴリーとして次のものがあります。
(9) 索引のためのフォーマット化オブジェクト (V1.1で新設)
fo:index-page-number-prefix
fo:index-page-number-suffix
fo:index-range-begin
fo:index-range-end
fo:index-key-reference
fo:index-page-citation-list
fo:index-page-citation-list-separator
fo:index-page-citation-range-separator
これらのオブジェクトをサポートすることによって、書籍などで使う、高度な巻末索引を作成することができます。V1.0で索引機能がなかったため、主要なXSL-FO組版エンジンが独自拡張していました。V1.1ではそれらを包含する強力な索引機能が標準で定義されました。
(10) しおりのためのフォーマット化オブジェクト (V1.1で新設)
fo:bookmark-tree
fo:bookmark
fo:bookmark-title
PDFのしおりを作成するための機能です。XSL-FOはPDF作成のために使われるケースが多いのですが、V1.0には、しおり機能がなかったためXSL-FO組版エンジンがそれぞれ独自拡張していたのですが、これが統一仕様となりました。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月21日
XSL-FOによるXMLのPDF化 (13) XSL-FOの概要 2
(2) ブロックレベルフォーマット化オブジェクト
FOでは領域をブロック領域と行内レベル領域に分類しています。ブロック領域とは行または複数の行を含むような矩形の領域です。
V1.0では次の2つを定義しています。ブロックは段落を囲む領域、ブロックコンテナは、Microsoft Wordなどでいう枠に相当します。枠の中に段落が入ります。
fo:block
fo:block-container
V1.1での追加はありません。
(3)行内レベルフォーマット化オブジェクト
V1.0では次の10種類を定義しています。
fo:bidi-override
fo:character
fo:initial-property-set
fo:external-graphic
fo:instream-foreign-object
fo:inline
fo:inline-container
fo:leader
fo:page-number
fo:page-number-citation
V1.1で次の4種類が追加されました。
fo:page-number-citation-last
fo:folio-prefix
fo:folio-suffix
fo:scaling-value-citation
(4) 表対応のフォーマット化オブジェクト
XSL-FOの表は、HTMLの表に似ています。V1.0では次の9種類を定義しています。
fo:table-and-caption
fo:table
fo:table-column
fo:table-caption
fo:table-header
fo:table-footer
fo:table-body
fo:table-row
fo:table-cell
表については、V1.1でも変わっていません。
(5) リスト対応のフォーマット化オブジェクト
XSL-FOのリストは、リストのラベル部分(list-item-label)とリストの本体部分(list-item-body)を別々に指定できる点に特色があります。V1.0では4つのオブジェクトを定義しています。
fo:list-block
fo:list-item
fo:list-item-body
fo:list-item-label
リストについては、V1.1でも変わっていません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月19日
XSL-FOによるXMLのPDF化 (12) XSL-FOの概要 1
4.2 XSL-FO
XSL-FOの仕様は、XSLTの勧告よりも約2年遅れて、2001年10月に勧告となりました。
XSL-FO仕様書
オリジナル:Extensible Stylesheet Language (XSL) Version 1.0 (W3C Recommendation 15 October 2001)
日本語訳:標準情報(TR) TR X 0088:2003 XSL 1.0
XSL-FOは、現在、V1.1の策定作業の最終段階になっています。
V1.1仕様書オリジナル:Extensible Stylesheet Language (XSL) Version 1.1
(W3C Candidate Recommendation 20 February 2006)
XSL-FO仕様は、組版対象オブジェクトを定義しています。これをフォーマット化オブジェクト(Formatting Object:FO)と呼びます。FOをどのように実際のページに配置していくかということを、フォーマット化特性(Formatting Property) によって指定します。
FOにフォーマット化特性を指定した結果がどのようにページの上に配置するかはレイアウト・モデルによって決まります。
4.2.1 FOの種類
(1)宣言,ページ付け及びレイアウトフォーマット化オブジェクト
これは、主にマスターページとそのマスターページをどのように組み合わせてページを生成するかを規定するものです。V1.0では次の19種類があります。
fo:root
fo:declarations
fo:color-profile
fo:page-sequence
fo:layout-master-set
fo:page-sequence-master
fo:single-page-master-reference
fo:repeatable-page-master-reference
fo:repeatable-page-master-alternatives
fo:conditional-page-master-reference
fo:simple-page-master
fo:region-body
fo:region-before
fo:region-after
fo:region-start
fo:region-end
fo:flow
fo:static-content
fo:title
V1.1で次の7つのオブジェクトが追加されています。
fo:page-sequence-wrapper
fo:flow-map
fo:flow-assignment
fo:flow-source-list
fo:flow-name-specifier
fo:flow-target-list
fo:region-name-specifier
V1.1では、様々な実装が独自に拡張しているものを仕様に盛り込むことが目標の一つでしたが、このマルチプル・フロー(本文をひとつのフローのみでなく、複数のフローで流していく)は、アドビのDocument Server (ADS)が行っているFO拡張を標準に取り込むものです。ADSはFrameMakarをべースに開発されたと思われますので、新しいXSL-FOはFrameMakerとの互換性が高くなるだろうと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月18日
XSL-FOによるXMLのPDF化 (11) XSL Formatter開発の経緯(続)
さて、そうこうしているうちに、SGMLをもっと簡単にしたXML仕様が提案され、1998年にW3Cの標準仕様となりました。
XML仕様は、プログラムを実装する立場からみてもSGMLよりもかなり簡単になっています。SGMLは理想としては良いものの、実装したツールが数少なく、しかも高価になっていたことが普及の妨げにもなっていました。XMLの登場によって、いままでなかなか普及しなかったSGMLに代わってXMLが普及していくことが予想できます。
2006年06月15日 XSL-FOによるXMLのPDF化 (8) XSL-FOの歴史にも述べましたが、XMLの仕様が策定されるのとほぼ同時に、XMLにスタイルを与えて印刷するためのXSL仕様の策定作業が始まりました。
DSSSLのツール開発を見送って、次の機会を待っていた当社には絶好のチャンス到来ということになりました。
早速、XSLを実装することを計画し、1999年に開発をスタートしました。
XSL-FOの仕様が、W3Cの勧告になったのは2001年10月です。このタイミングで、うまく、XSL Formatter V2をリリースできました。この時、XSL-FOの仕様を実用的なレベルまで実装できていたのは、世界で、XEP、FOPおよびXSL Formatterの3つ。
この3つのツールが市場の3強と目される状況は、5年後の現在でも変わっていないと思います。
4.XSL-FOの概要
XSL仕様は、開発中に、XMLのツリー構造を変換するためのXSL Transformation(XSLT)と、レイアウト対象オブジェクトの仕様であるXSL Formatting Object(XSL-FO)に分割されました。
4.1 XSLT
ドキュメントの印刷・PDF化においては、XSLTを使うことで、印刷対象となるXML文書にはない表紙や目次を、印刷の段階で自動的に生成したり、あるいは、索引を印刷段階で自動生成するなどの文書の自動処理を行うことができます。
DSSSLでも、このような前段の処理と、レイアウトされたオブジェクトをページアップするという組版処理に分かれています。DSSSLでは、前段のツリー構造変換をスキーマというプログラム言語を使って行います。
XSL Transformations 仕様書
オリジナル: XSL Transformations (XSLT) Version 1.0
日本語訳: XSL Transformations (XSLT) バージョン 1.0
なお、XSLT仕様は、2006年6月にV2.0の勧告候補が出ています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月17日
XSL-FOによるXMLのPDF化 (10) XSL Formatter開発の経緯
昨日は、文書ファイルの変換ソフトの開発に苦労した経験から、1990年代中旬に、ドキュメントをワードプロセッサと独立の、標準的な方法で表現することが重要と考えはじめたことをお話しました。
1980年代から使われているドキュメント表現用の標準技術としてSGMLというメタ言語があります。
SGML (Standard Generalized Markup Language)
このSGMLは、1980年代に国際標準規格になり、1992年にはJIS規格(X4151:1992)になっています。
そうしたことから、当社ではSGMLでドキュメントを表現する方法の検討に着手ました。
1990年代後半には、SGMLで文書を表現するための編集ソフトを試作したりしたのですが、「SGMLは静かなる革命」とも言われて、革命的な技術ですが、なかなか普及しませんでした。
SGMLも、タグとタグで囲った本文で文書を表現します。SGMLでドキュメントを表現すれば、当然、SGML文書にスタイルを与えてページの形に整形し、印刷するための方法が必要です。
このための方法としては、米国ではFormatted Output Specification Instance (FOSI)があり、軍事用の文書などを中心に普及したようです。
SGMLを印刷するための標準技術もあります。文書スタイル意味指定言語(Document Style Semantics and Specification:DSSSL)という仕様です。
DSSSL (Document Style Semantics and Specification)
DSSSLは、JIS X 4153:1998としてJIS規格にもなっています。
DSSSLを使ってSGMLを印刷するツールの必要性はあると考えられましたが、しかし、開発はかなり大変と予想されましたし、当時の市場を考えますとSGML自体がそれ程普及していないなかで、DSSSLツールを開発しても市場性が小さいと見られました。そこで、当社ではDSSSLツールの開発は見送ることにしました。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月16日
XSL-FOによるXMLのPDF化 (9) XSL Formatter前史
このPrinting XML: Why CSS Is Better than XSLですが、どうもHåkon Wium Lie氏のXSL批判はまとはずれなところが多いように思います。
Håkon Wium Lie氏は、この文書の中で、XSL Transformation(XSLT)のスクリプトが長く複雑なのにCSSは簡単である、だからCSSが優れているという趣旨の発言を繰り返しています。しかし、XSLTは、XMLのツリー構造を操作する言語なので、これをCSSと比較するのは不適切です。
【参考】
XSLT (XSL Transformations)
XSLTはXSL-FOを作り出すための最も主要な方式なのですが、XSLTを使わなくてもXSL-FOを作り出すことができます。
特にサーバサイドではデータベースなどから検索したデータとテンプレートを使ってダイナミックにXSL-FOを作り出すこともできるでしょう。
また、例えば、XML文書にもともと存在しない目次や索引をXSLT変換で作りだすことができます。こうして作り出した目次や索引にCSSを適用することもできます。このように、XSLTとCSSを組み合わせて使うこともできます。
ですので、スタイルシートの機能を比較するなら、CSSとXSL-FOを比較しなければならないのです。そしてCSSとXSL-FOはレイアウトモデルの観点では、兄弟の関係になります。つまり50歩100歩。お互いに批判するにしても兄弟喧嘩になるに過ぎません。
3.当社のXSL Formatter開発の経緯
時々、当社がなぜ、XSL Formatterの開発に取組んでいるのか、という質問を受けることがあります。XSL-FOの歴史をお話するついでにそのことをお話しましょう。
当社は、1989年にリッチテキスト・コンバータの開発を開始しました。リッチテキスト・コンバータの開発はかなり四苦八苦をしたのですが、漸く1995年頃には大きな収益を出すことができるようになりました。
リッチテキスト・コンバータの開発になぜ苦労したかと言いますと、ワープロ文書はバイナリ形式といってコンピュータでしか理解できないデータになっていて、文書の文章内容と制御用データが渾然一体となっていること。そして、レイアウト、スタイル、罫線の情報などが、各ワープロ独自の仕様になっていること。例えば、日本語ワープロでは、表を罫線で作りますが、Microsoft Wordを初めとして西欧言語のワープロでは表をセルを積み重ねて作ります。このようにそもそも文書のモデルが違うのです。
このため、データ変換ソフトは完全なレイアウト互換性をもたせることが困難です。苦労した割りに満足できる結果になりにくいのです。
そこで、次の製品プロジェクトを開始するにあたり、もっと標準的な文書表現方法がないものか、といろいろ考えました。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月15日
XSL-FOによるXMLのPDF化 (8) XSL-FOの歴史
2.XSL-FOの誕生
さて、ようやくXSL-FOにたどり着きました。
XSL-FOは、XMLをページに整形してPDF化するための標準技術です。XSL-FOの標準化はXMLが標準技術として勧告された1998年から始まっています。
XSLの標準化を提唱したのは、Microsoft、ArborText、InSoの3社だったと記憶しています。不確かです。提案資料は、今、見当たりません。
XSLを作ろうという動きは、恐らく1997年からはじまっているようです。1998年1月には、XSLの開発のための作業委員会の活動が始まっています。
従って、CSSよりも数年遅れてスタートしたことになります。
改めて、W3CのXSL開発作業委員会のメーリング・リストの書庫を少し見てみましたが、CSSでは、複雑なXMLのスタイル付けは難しいということがXSLの開発意図になっているようです。このあたりは、Jon Bosak氏あたりが主張しています。また、同じくSunのNorman Walsh氏あたりもXSL推進派です。
これに対して、CSSの開発者であるHåkon Wium Lie氏が激しく反論するなどCSSとXSLの位置づけについては、当初から議論があります。
Håkon Wium Lie氏は、Operaのホームページで、Formatting Objects considered harmful
というような、XSL-FO批判を行っています。
(2006年の現在から振り返ってみますと、Håkon 氏のこの文章は、XSL-FOの可能性を認識していない、的外れの批判になっています。上の文章で、Håkon 氏は、XSL-FOはWebでは使えないといって批判しています。しかし、実は、XSL-FOはWebではなく、XMLからPDFを生成する技術、特に、SGML時代のDSSSLの後継として広く利用されるものです。当時のHåkon 氏は、DSSSLの意義、PDFの重要性が分かっていなかったのだろうと思います。)
その後、しばらくの間は、Web用のCSS、PDF生成用のXSL-FOという棲み分けがなされていました。
ところが、XSL-FO派のNorman Walsh氏が、CSSは、いつまで経っても完成しないじゃないか("CSS is never going to fix it.")と挑発したため、また、両陣営の争いが勃発しています。
Norman Walsh氏のブログ
http://norman.walsh.name/2004/12/07/webarchPdf
これに対して、Håkon氏がPrinting XML: Why CSS Is Better than XSLで、XSL-FOよりCSSが優れている主張。次に、昨日紹介しましたように、Princeを使ってHTML+CSSをPDF化して書籍を作って、XSL-FOに挑戦しています。
このように、XSLは仕様の誕生時点から、先行するCSSとの位置づけが議論の対象になっています。今後、CSS3の進展で、XSL-FOとの関係がどうなるか、楽しみです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月14日
XSL-FOによるXMLのPDF化 (7) XML+CSS でPDF生成
CSSは、HTMLをブラウザで表示する時に使用する用途を意図して提唱されたのだろうと思います。次の表でブラウザのCSSサポート状況を見ることができます。
【参考資料】
ブラウザのCSSサポート一覧
これを見ますと、CSS2.1レベルのサポートはFireFoxが比較的進んでいます。IE6、IE7ともCSS2.1サポートはそれ程進んでいないように思います。
特に、紙・PDFに印刷するためのページを指定するために使う@Pageルールは、IE6、IE7、FireFoxもサポートしていません。もともとブラウザは画面表示を想定しているため、奇麗にページに整形してPDFに出力することは重視していないのだろうと思います。
CSS3のサポートは、どのブラウザもまだまだです(仕様が草稿レベルですので当然ですが)。
一方、ブラウザとは別に、最近は、XMLにCSSでスタイルを与えて、PDFにするソフトが幾つか出てきました。これは新しい動きと言えるでしょう。
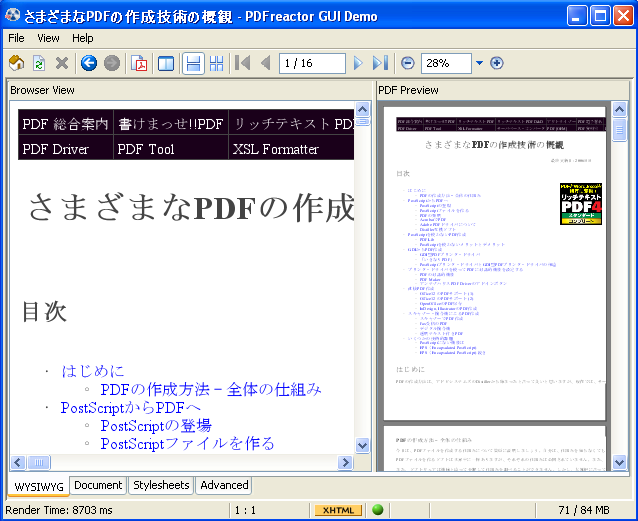
JAVAで書かれています。GUIにブラウザビュー、PDFプレビューを表示できます(上の画面)。この他、ドキュメント(XML)のソースを表示して編集したり、スタイルシートを表示します。
JAVAのためか少し動作が鈍いのが気になりますが、簡単なドキュメントを整形してPDFにする用途なら十分使えそうです。ハイフネーションなどの高級な整形はできないようです。
・Prince(YasLogic社)
Princeは、2003年4月に初版(V1.0)がリリースされており、2003年5月にV2.0(1ヶ月でV1からV2へ)、2003年12月V3、2004年10月V4、2005年10月V5になっています。
2005年4月に出版された「Cascading Stylesheets - Designing for the Web」 (Håkon Wium Lie and Bert Bos)という書籍は、HTMLで記述されCSSでスタイルをつけて、PrinceでPDF化されたそうです。
YasLogic社はオーストラリアの会社ですが、Håkon 氏がCTOを勤めています。
■日本
・CSSJ
まだ初歩的なレベルのようですが、HTMLを整形してPDFを出力できます。
ブログのPDF化のサイト「ブログ出版局」に使用されています。
このようにHTML(XML)+CSSは、簡単なレイアウトの書籍を出版できるレベルにまでなってきているようです。CSS3仕様が完成して、それをきちんと実装すれば大化けするかもしれません。何年先のこと?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月12日
XSL-FOによるXMLのPDF化 (6) XMLのスタイル指定
XSL-FOによるXMLのPDF化 (3) 描画情報を規定するXMLタグおよびXSL-FOによるXMLのPDF化 (4) 特定アプリケーションのXMLタグで説明しましたような、”一般的でない”XMLのタグは、表示用の特にスタイルを指定しなくても表示することができます。但し、SVGやMathMLを表示アプリケーションは必要です。
これに対して、一般のXMLタグは、そのタグ自体、あるいはタグで囲った内容を画面に表示するためのスタイル情報がありません。
スタイル情報をもたないXMLファイルをブラウザで表示しようとしますと、次のように、「スタイル情報がないので、ドキュメント・ツリーを表示します」と言われてしまいます。
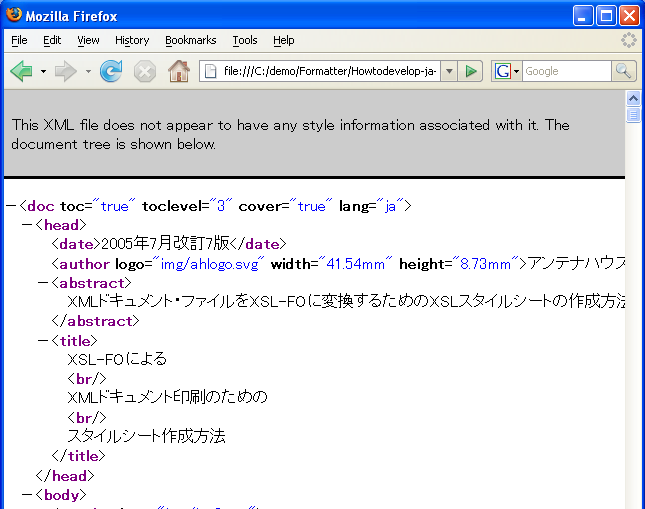
このようなXMLファイルを、ページに整形して表示するための方法として、(1)標準技術に基づく方法と、(2)各ベンダの独自技術に基づく方法があります。
独自技術の方は、それこそ、いろいろなアイデアがあるだろうと思いますが、ここでは取り上げません。
比較的広く使われている標準技術には、CSSとXSL-FOの2種類があります。
1.CSS
現在、ノルウェーのOpera SoftwareでCSSの開発に携わっているHåkon Wium Lie氏が、1994年に提唱したものです。
1996年にはCSSレベル1がW3Cの標準として策定されました。現時点での仕様策定動向を、W3CにおけるCSS仕様策定の動向にまとめましたとおり、現在、レベル3の開発が行われていますが、レベル3の作業委員会は1999年に最初に任命されましたが、なかなか作業がはかどっておらず、まだ全てのドラフトが揃っていません。
従って、現在、標準仕様として使えるのはCSS2ということになります。
CSSの開発の進捗、および普及はなかなかはかばかしくないように思えます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月10日
XSL-FOによるXMLのPDF化 (5) Office Open XML Format
ちょっと話が横道にそれてしまうかも知れませんが、ここで、Open XML Formatについて考えて見ます。
このブログでも何回か書きましたし、既にご承知の方も多いと思いますが、Microsoftは、次期Office 2007のファイル保存形式をデフォルトでXML形式にすることになっています。
例えば、Word2007の文書は、デフォルトでは、docxまたはdocmという拡張子が付きます。このファイルは内容はXML形式で、昨日説明しましたWordprocessingML(WordML)と同じようなものになります。
そうして、Microsoftは、Office 2007の文書形式をOpen XML Formatという名称をつけて、世界標準仕様にすることをもくろんでいます。
現在、EcmaでOpen XML Formatの標準化作業を進めており、中間段階の仕様書がここに公開されています。
Microsoft Officeの文書形式がこういう形で公開されること自体は大変歓迎すべきことです。これによって、文書データの交換が非常にスムーズに進むようになるでしょうし、いままでよりも格段にユーザにとって便利になると思います。
では、このOpen XML Formatは世界標準になりえるものなのでしょうか?
私は、「Open XML Formatは世界標準の資格がないのではないだろうか」と考えます。
その理由は、このファイル形式は特定のアプリケーションを前提とするものだからです。つまり、Microsoft Officeがないと、Open XML Formatで記述された文書を正しく解釈して、正しくページを表示することができないのです。
もう少し詳しく言いますと、Open XML Formatは、Microsoft Officeというアプリケーション・ソフトウェアが存在して初めて意味があります。Open XML Formatを表示するソフトを開発しようとすると、Microsoft Officeの動き方を詳細に観察して、Microsoft Officeと同じように動くアプリケーション・ソフトウェアを開発しなければなりません。つまり、Open XML Formatで書かれた文書をPDFにするソフトを開発して欲しいという仕事を依頼されたとして、Open XML Formatを読むだけではその業務を行うことはできないだろうと思います。文字だけ取り出してPDFにして欲しいという程度ならできるかもしれませんが。
SVGやMathML (2006年06月08日 XSL-FOによるXMLのPDF化 (3) 描画情報を規定するXMLタグを参照)では、その仕様書を読むだけで、SVGやMathMLを表示するアプリケーションを作ることができます。
このように、このふたつの種類のXMLフォーマットには、根本的な違いがあるように思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月09日
XSL-FOによるXMLのPDF化 (4) 特定アプリケーションのXMLタグ
2.”一般的でない”第2のグループは、特定のアプリケーションで描画することを想定するXMLタグです。
この一番、典型的な例は、Microsoft Word 2003 のWordprocessingML(WordML)です。
例えば、Word2003で次のような文書を作成します。
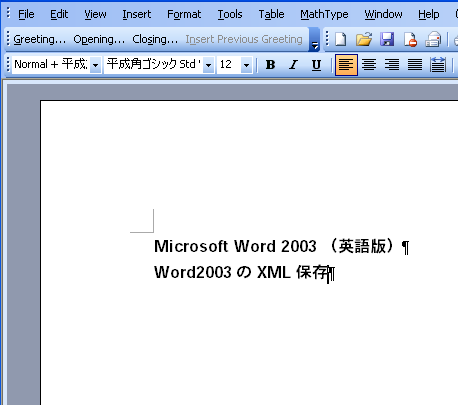
(図A)
これを、XML形式で保存すると次のような内容のファイルができます。
WordML文書の例
WordMLのXMLタグの付け方は、Microsoftが仕様を公開しています。
一般の書籍も出ています。
Simon St. Laurent 他 「Office 2003 XML, Integrating Office with the Rest of the World」 2004年6月刊 ISBN: 0-596-00538-5, 576 pages, US$39.95, O'Reilley
さて、上のWordMLの例には(文書本文)に次のような部分が出てきます。
<w:p>
<w:ppr>
<w:rpr>
<w:rfonts w:ascii="平成角ゴシック Std W7" w:fareast="平成角ゴシック Std W7" w:h-ansi="平成角ゴシック Std W7" w:hint="fareast"/>
<wx:font wx:val="平成角ゴシック Std W7"/>
<w:sz w:val="48"/>
<w:sz-cs w:val="48"/>
</w:rpr>
</w:ppr>
<w:r>
<w:rpr>
<w:rfonts w:ascii="平成角ゴシック Std W7" w:fareast="平成角ゴシック Std W7" w:h-ansi="平成角ゴシック Std W7" w:hint="fareast"/>
<wx:font wx:val="平成角ゴシック Std W7"/>
<w:sz w:val="48"/>
<w:sz-cs w:val="48"/>
</w:rpr>
<w:t>
Word2003のXML保存
</w:t>
</w:r>
</w:p>
これは、XMLの文書自体に、テキストのみでなく、文字の大きさやフォントの種類の情報が入っています。このWordMLを読んで上の図Aのように表示するためには、各タグをどのように表示するかという知識が前提として必要です。
昨日説明しました、SVG、MathML(表現用タグ)では、各タグをどのように表示するかが、W3Cの定める仕様として決まっています。
ところが、WordMLの各タグをどのように表示するかという仕様は(すくなくともパブリックには)存在しません。この仕様はMicrosoft Wordというソフトウェアの中に知識として内蔵されているのです。
このため、WordMLで書かれたXML文書を正しく表示したり、PDF化するには、Microsoft Word 2003 (Word ビューアを含む)、または、Microsoft Wordと表示機能において互換のアプリケーションが必要です。
例えば、当社のサーバべース・コンバータは、Microsoft Wordと互換のWordML表示・PDF化を実現することを狙って開発されているアプリケーションのひとつです。
ちなみに、WordMLをXSL-FOに変換してから表示したり、PDFにするソフトウェアは世界に幾つかあります。例えばこちらをご覧ください。しかし、XSL-FOではWordMLをあまりうまく表示することができません。それは、Microsoft Wordが内蔵している組版モデルと、XSL-FOの組版モデルはかなり異なったものだからです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月08日
XSL-FOによるXMLのPDF化 (3) 描画情報を規定するXMLタグ
昨日説明しましたように、一般的なXMLのタグには、表示のスタイルが規定されませんので、表示するには、何らかのスタイルを与える必要があります。
さて、ここまで”一般的な”という言葉を定義しないで使ってしまいましたが、もう少し詳しく検討してみます。”一般的”というのは説明が難しいので、”一般的ではない”ものを取り上げてみます。
1.”一般的ではない”ものの最初のグループ —タグ自体に描画情報を含むもの。
ベクトル・グラフィックスを表現するためのSVG(Scalable Vector Graphics)、数式を表現するためのMathMLなど。
・SVGのタグは、それ自体がベクトル・グラフィックスへの描画を規定しています。
上のSVGファイルを、XSL Formatter で表示すると次の図のようになります。
・MathMLには、表現用タグ(プレゼンテーション・マークアップ)と内容タグ(コンテンツ・マークアップ)の2種類があります。表現用タグの場合は、そのタグ表現自体を見るとどのように表示するかが大体決まります。
例.
MathMLのサンプル(MathTypeで作成したMathMLファイル)
上のMathMLファイルを、XSL Formatter で表示すると次の図のようになります。
![]()
SVGやMathMLを記述するためののタグは、タグ自体の仕様に画面にどう表示するかが決まっています。従って、外部から特にスタイル情報を与える必要がありません。
【参考資料】
・Scalable Vector Graphics (SVG)
・MathML
・MathML2.0仕様に関する概要
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月07日
XSL-FOによるXMLのPDF化 (2) タグとスタイル
昨日のXHTMLでは次のようなタグが出てきました。
hr、h1、h2、ul、li、a
これらのタグ自身には、タグそのものまたはタグが囲むテキストなどの情報をどのように表示するかという定義はありません。
例えば、hrは、水平線(罫線)を引くという用途で使われるタグです。
ブラウザは、hrというタグを見つけると水平線を引こうとします。しかし、実際には、水平線を引くと言っても、次のような属性が決まらないと引くことができません。
・線を引く位置は?
線の位置(前の行との間隔、次の行との間隔)
水平線の開始位置、終了位置 (線の長さ)
・線の太さは?
・線の種類は?(実線、点線、破線、など)
・線の色は?
・線には、影を付けるかどうか?
・線の終端は丸めるか、丸めないか?
なにも指定していない場合、ブラウザはそれ自身の内部で既定値としてもっている情報を使って線を引きます。
さらに、これらの水平線の引き方を、次のようにhrタグに属性をつけて指定することもできます。
【例】
上から順に、線の太さ10px、長さ100px、左寄せ。線の太さ20px、長さ200px、中央。線の太さ30px、長さ200px、右寄せ。線の太さ30px、noshadeの線を引く。
<hr size="10px" width="100px" align="left" />
<hr size="20px" width="200px" align="center" />
<hr size="30px" width="300px" align="right" />
<hr size="30px" noshade="noshade"/>
これを、FireFoxで表示すると次の図のようになります。
![]()
最近のXHTMLでは、これらの表示時用の属性をhrタグの属性として指定するのではなく、タグにstyle属性をつけてCSSとして与えるか、あるいはCSSスタイルシートを使って外部から指定するのが推奨されています。できるだけ、コンテンツを示すタグと表示属性を指定するスタイルとは独立にすることで、Webのメンテナンスをし易くしたり、見栄えを変更するのが簡単にできるようになるからです。
このように、XMLのタグには、一般にはどのように表示するかという情報は内在しておらず、表示の方法はスタイルとして別途与えるようになっています。ブラウザは、XHTMLのタグに指定されたスタイルを使ってコンテンツを画面上に整形することになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月06日
XSL-FOによるXMLのPDF化 (1) コンテンツのXML表現
XSL Formatter V4のリリースを機会に、XSL-FOによるXMLのPDF化について、少し説明してみたいと思います。
最初にコンテンツとスタイルについて考えて見ましょう。
最初に簡単な例で説明します。次の例はアンテナハウスのPDFの総合情報ページのソースです。このページはXHTMLで書いてあります。XHTMLというのは、XMLの文法に従って、Webページを記述するための言語です。XMLのタグセットの一例とお考えください。
---ここから---
<hr />
<h1>お知らせ</h1>
<ul>
<li>6月1日<a href="../XSL-FO/"><strong>『XSL Formatter V4.0』</strong></a>
出荷開始。<a href="http://www.antenna.co.jp/XSL-FO/V4/">詳細情報はこちらをご覧ください。</a></li>
</ul>
<ul>
<li><a href="http://www.antenna.co.jp/ptl/">PDF Tool V2</a> ご案内を開始しました。</li>
</ul>
<ul>
<li>2006年4月より<a href="http://www.pdfxplus.jp/">PDF/X-PlusJ推進協議会</a>に加盟しました。<a href="http://www.antenna.co.jp/OEM/PDF/index.htm#h2n2">アンテナハウスPDF生成ライブラリー</a>でPDF/Xができます。</li>
</ul>
<ul>
<li>2006年1月17日 PDFに文字をスラスラ書ける!<a href="http://www.antenna.co.jp/KPD/">書けまっせPDF</a> を出荷開始しました。</li>
</ul>
<ul>
<li>2005年12月15日<a href="http://www.antenna.co.jp/RTC/RtcPDF/">リッチテキストPDF V1.1</a>を出荷開始しました。</li>
</ul>
<hr />
<h1>デスクトップPDF製品</h1>
<h2>PDFファイルのデータを再利用</h2>
---ここまで---
このようにXHTMLでは、テキストやリンクなどの情報をXHTMLのタグ(<と>で囲まれた部分)で囲ってコンテンツを表現します。
これをブラウザ(FireFox)で表示すると次のようになります。

XHTMLをご存知でない方のために簡単に、次の図でタグと表示画面とを対応付けてみました。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年10月31日
PDFからXMLへのデータ変換(3)
PDFからXMLへのデータ変換の例として、最近、アンテナハウスが、あるお客様向けに開発したプログラムのあらましをご紹介します。
これは、固定レイアウト帳票のPDFファイルから、各ページの指定位置の項目の情報を取り出して、結果をXMLファイルにするというものです。
用途は、取引先から毎日膨大な量の帳票データがPDFで送られてくるのですが、その帳票PDFデータの中の一部の情報を取り出して、データベースに蓄積して管理したい、ということです。
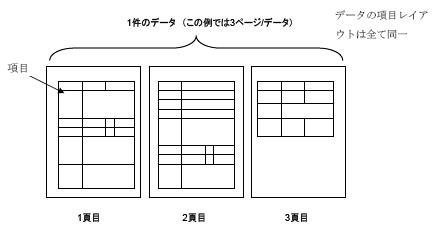
①オリジナルの帳票を簡単な図で表すと次のようになります:
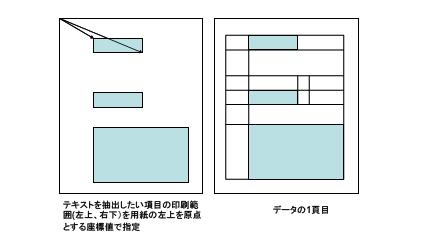
②やりたいことは、この中の一部の項目の情報を取り出す:
解決策は次のようになります。
①PDF Viewerで、帳票PDFファイルの雛形を画面に表示して、それを見ながら抽出したい範囲(矩形)の座標値を取得します。
②抽出範囲の指定値およびXMLへの出力方法について、出力形式設定ファイルを作成します。
③変換プログラムの動作は、実際のデータが入った帳票PDFファイルを読み、②で作成した出力形式設定ファイルを参照しながら、指定範囲内のテキストなどの情報を取り出し、XML化して出力します。
④あとは、変換プログラムを動かして、帳票PDFファイルを自動的に処理するシステムを作り、自動運転することになります。
【この開発を通じて、感じたこと】
PDFからXMLに変換にする際に、PDFのデータを解析して構造を取得すると考え勝ちです。しかし、そうではなく、外部からXML構造を与えるという方法も、実際のところは、かなり有効な、コストパーフォーマンスが良い方法でしょう。
このプログラムに関してのお問い合わせは、sis@antenna.co.jpまでお気軽にどうぞ。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2005年10月29日
PDFからXMLへのデータ変換(2)
PDFからXMLへの変換を熱心にやっている会社に、カナダのExegenixという会社があります。変換ソフトウェアも作っているようですが、どちらかというと、変換サービス中心の会社のようです。特に、インドのタタグループに属するTata Infotechが出資して設立されたのが注目です。
いま、米国ではアウトソーシングが非常に盛んです。その、アウトソース先として、英語が通じる国ということでインドが選ばれることが多いようです。出版関係のサービスもインドにかなりアウトソースされてますので、Tata Infotechもそういうところに眼をつけて、米国のXMLデータ変換サービスをインドにもっていこうとしているのでしょう。
Exegenixは、毎年、秋に米国、春に欧州で開かれるXML Conferenceに、ずっと出展しています。アンテナハウスも2001年秋から、毎年、春と秋にXSL Formatterなど出展しているので、お互いに顔見知りになっています。
今年のXML2005も両社とも出展します。XML2005の出展社一覧:
http://2005.xmlconference.org/exhibits/participants
ある時、ちょっと話して見ましたが、たとえば、Microsoft Wordの文書(doc)をXMLに変換するにも、一旦、WordからPDFに変換し、PDFからXML変換するんだということを聞いてびっくり。
WordからXML変換もPDFからXML変換も、非構造化文書から構造化文書への変換という意味では近いのです。
ですが、Wordの方がどちらかというと、PDFより構造化されています。PDFというのは、最も、非構造化された文書形式。だから、WordとXMLの距離の方が、PDFとXMLの距離よりずっと近いと言えます。
なので、当然、WordからXMLに変換するのだろうと思っていたのですが、あらゆる文書を、一旦、PDFに変換してしまって、そこからXMLに変換する、つまりわざわざ遠回りする、と聞いてびっくりしたわけです。
なるほど、いろんな文書形式からXML変換を、ひとつずつ開発するのは工数が大きくなるが、PDFからXML変換に開発努力を集中すれば効率がよくなるんだな、いうところで、ちょっと眼からうろこが落ちた思いがしたものです。
構造化文書ってなに?PDFが非構造化文書の最たるもの?分からないなあ、という方に、このあたり、また、後日にお話ししたいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年10月27日
PDFからXMLへのデータ変換(1)
xmluserのメーリングリストで、このブログが紹介されました:
http://www2.xml.gr.jp/log.html?MLID=xmlusers&TID=9356&F=0&L=10&R=1
そこで、今日はこの機会に、PDFからXMLへの変換について少し話してみたいと思います。
昨日、DATABASE TOKYO2005に立ち寄って「PDF2XML」を見てきました。以前から、ウオッチしていた製品なので、どこまで進んだか関心があったのです。
さて、「PDF2XML」は、その名前の通り、PDFをXMLに変換するためのソフトウェアです。
アメリカのXMLCitiesというベンチャ企業で開発したもので、(株)データプレイスが日本の総代理店となって販売しています。XMLCitiesには三菱商事がかなり投資しているとのことです。商事にXMLが好きな人がいるのかもしれませんね。
以前に聞いた説明では、確か、PDFのファイルを解読し、テキストを取り出して中間形式に変換し、中間形式からターゲットXMLにパターンマッチングで変換するという2ステップ変換を取っていたと記憶しています。
製品紹介資料には、テキストだけでなくスタイルも取り出せるという説明があります。
今日のデモでは、日刊工業新聞の企業人事面(新聞記事)PDFを解読して、自動的にXMLにするところを見せてもらいましたが、結構良く出来てましたね。
価格はお安くありません。開発会社が使う開発ツールが税込み100万円。さらに、エンドユーザで使うときは、ランタイムライセンスが、例えばクライアントサーバタイプだとサーバ1CPUで税込み200万円です。
さらに、開発会社では、XMLのスキーマにあわせて、適切なルールを開発しなければなりません。この開発費がプラスされます。この開発費はバカになりません。本当に使えるようにするには、相当にかかるでしょう。かなり大きなシステムでないと投資効果がでないように思います。
私の経験では、この方式は、中間形式の仕様と、パターンマッチングとルール開発というのが難点で、なかなかうまくいかないものでした。
以下は、あくまで私が同じようなことをした時の経験です。「PDF2XML」にはあてはまらないかもしれませんが、その前提で聞いてください。
(1)原データから中間形式まで持ち込む際に情報がなくなってしまうと、後段で取り出せないので、中間形式をどう設計するかが大きな課題となります。うまく行くも行かないも、中間形式次第ということ。
(2)パターンは一般化するのが難しく、対象個別になりがち。任意のPDFとXMLの組に当てはめるのは無理なように思います。つまり汎用化困難。
(3)パターン処理プログラム開発は、XSLTのような標準技術であれば、技術者も多いので安くできるかもしれませんが、固有のマッチングルールだと、開発できる人の育成から始めなければなりません。これはコストアップの要因になります。
いづれにせよ、PDFからXMLというのはなかなか難しいテーマなんですね。というわけで、続きはまた後日。