« 2006年07月 | メイン | 2006年09月 »
2006年08月31日
英文Wordで日本語フォントを使ってPDFを作る
ちょっとPrimoPDFを使ってみようと思って、簡単なデータをWordで作ってPDFを出してみました。
・この図はWordの編集画面のスクリーンショット

※Word2003英語版 WindowsはXP Service Pack 2英語版を地域のオプションを日本語にして使用
これをPrimoPDFでPDF化し、Adobe Readerで開こうとすると、次のようになります。
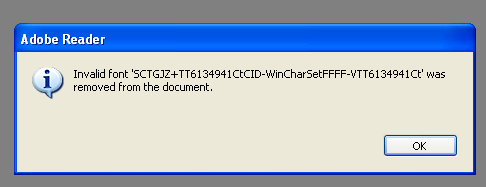
※不正なフォントが埋め込まれているというエラーメッセージらしい
強制的に開くと

となってしまいます。
おそらく、英文のWordを使って、英語OSを日本語モードで動かして、日本語のフォント名を使っているため、PrimoPDFで正しくフォント名を処理できていないのではないかと思います。
で、試しに、日本のある会社製(アンテナハウスではない)のPDFドライバでPDFを作ってみたのですが、驚いたことにこれもだめです。できあがったPDFをAdobe Readerで表示すると次のように文字が全部豆腐になってしまいます。
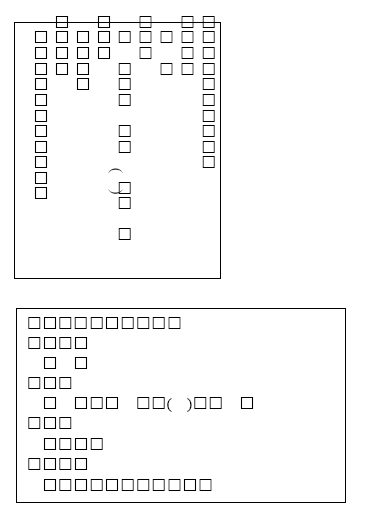
おそらくフォント名のハンドリングが正しくできていないのでしょう。この会社も、日本語フォント名を英文のシステムで使う場面まで考えてチェックしていないのではないかと思います。
PDFの仕様上は問題なくできるべきですが、なかなか色々な落とし穴があるものです。
ちなみに、Antenna House PDF Driver V3.0.6 で作成したPDFでは、次のように正しく文字が表示できます。


投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月30日
ベトナムでのソフト開発
ベトナムでのソフト開発は、中国よりも良いのではないかという噂は時々耳に挟んでいました。
今日、はじめて、実際にベトナムで開発したというパッケージ・ソフトのβ版を眼にし、その開発期間を聞いて、びっくりしました。
そのソフト、デモを少しみただけなのですが、良くできているという第一印象を受けました。
それだけならまあ驚くほどのことはないのですが、驚くべきはその開発期間、おそらく、ゼロから開発すれば、普通の日本の会社なら半年くらいはかかるであろうと思えるものが、なんとβ版まで3ヶ月とのこと。
このソフトを企画した人によると、日本のソフトハウス4社に話を持ちかけたが、すべての会社に3ヶ月でβ版のスケジュールは絶対無理と断られて、最後の頼みの綱としてベトナムの会社に発注したとのことです。
製品化するまでには、日本国内で仕上げが必要とのことですが、しかし、ベトナムの人たちが日本の会社ができないと断るような短納期の仕事を積極的に引き受けて、かつ、単価も日本の1/3から1/4でこなすとなると、日本のソフトハウスでのプログラマの仕事を維持すること、雇用確保するのは相当に大変なことだと、改めて気を引き締めた次第です。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月29日
PDFで使う圧縮方法
今日、営業で訪問した先で、PDFで使える圧縮についての話題がありました。以前に、一度、PDF/Xの時にもまとめましたが、もう一度、営業のQ&Aも兼ねて、整理しておきます。
PDF Reference 1.6版 2.2 Compression
PDFで使える圧縮には次のものがあります。
(1)カラー、グレースケール・イメージ
・JPEG
・JPEG2000 (PDF 1.5~)
(2)モノクロ・イメージ
・CCITT G3,G4
・ランレングス
・JBIG2 (PDF 1.4~)
(3) テキスト、グラフィックス、イメージ
・LZW
・Flate (PDF 1.2~)
以上が標準で使えるデータ圧縮方法です。
もうひとつ注意するべきこととして、圧縮の対象とする単位のことがあります。
PDFで圧縮対象となるのは、PDFを構成する細かいコンポーネント(オブジェクトなど)の中のデータ部分(ストリーム)です。PDFはオブジェクト毎のストリーム単位で圧縮されているのであって、PDFファイルを一括して大きな単位で圧縮しているわけではないのです。
ところが、PDF1.5から複数のオブジェクトをまとめて、ひとつのオブジェクトとし、複数のストリームをまとめてから圧縮することができるようになりました。Object Stream, Cross Reference Streamというものです。これによって、圧縮の効率が高まりました。
従って、圧縮に対応するかどうかは、各圧縮アルゴリズム用のフィルターをもつかどうか、ということと、Object Stream, Cross Reference Streamに対応するかどうかの2つの観点で考えなければなりません。
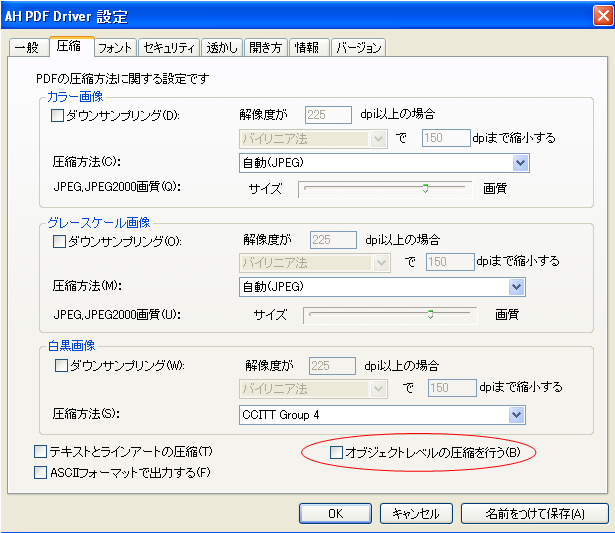
ちなみに、Antenna House PDF Driver V3.0 の圧縮機能は次の図のようになっています。
・テキストとラインアートの圧縮はFlate(ZIP)圧縮です。LZWは使っていません。これは過去にUNISYS特許問題という歴史的な問題があったため。
・画像についてはJBIG2以外の圧縮をすべて使用しています。使用可能なものから画像のタイプにより選択します。
・Object Stream, Cross Reference Streamについては、PDF1.5以上の時に表示される「オブジェクトレベルの圧縮を行う」をONにすると使用します。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月28日
Office Open XML File Format(OOX) ドラフト1.4公開
Microsoft Office 2007のXMLファイル形式 Office Open XML File Formatのドラフト1.4版が公開になりました。
Ecma Office Open XML File Formats Standard
1.3版が公開されたのが5月でしたので、3ヶ月ぶりの更新となります。
1.3版は、1冊(PDF)で4081ページでした。
1.4版では第一部から第五部の5分冊に分かれています。
part 1: "Fundamentals" 154ページ(PDF)
part 2: "Open Packaging Conventions" 134ページ(PDF)
part 3: "Primer"353ページ(PDF)
part 4: "Markup Language Reference"4741ページ(PDF)
part 5: "Markup Compatibility" 37ページ(PDF)
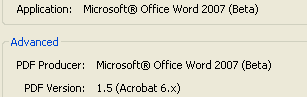
この第4部が、4741ページでXML文書仕様の中核と思います。この4741ページの仕様書のPDF ProducerがWord2007(β)になっています。
第5部として、将来のXMLマークアップの拡張のための「Markup Compatibility」が追加になったのが目新しいところです。
1.3版は、見出しだけあって本文のない部分がかなりありましたが、1.4版でどの程度まで本文が埋まったのでしょうか?後で見てみたいと思います。
PDF版だけではなく、Microsoft Word2007版(拡張子docx)もあります。但し、Office2007 のベータ版から仕様が変わったため、公開されているベータ版では開けないようです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月27日
XML技術のハイプ曲線
昨日は、XSL-FOがハイプ曲線のピークにある、ということはないのでは?という話をしました。そこで、もう少し調べてみました。
ガートナー・グループでは、XML技術のハイプ曲線2006年版というのを販売しています。
Hype Cycle for XML Technologies, 2006 11 July 2006には、レポートの目次が出てます。
それをみますと、XSL-FOはSliding Into the Troughの章で紹介されていて、XSL-FOはどうも幻滅の時期(反動期)に分類されているようです。
どうやら、ガートナー・グループではXSL-FOについて2005年が期待のピークで、2006年にはその反動で溝に落ち込んでいるという認識をしているようです。
ジャストシステムの資料に紹介されているのは2005年の図ですので、その中で、いくつかの項目をピックアアップし、2006年の位置づけと比較して、1年でどう変化したかを簡単にプロットしてみました。ガートナー・グループのレポートを買ったわけではありませんので、あくまで推測を交えた図なのですが、次のようになります。
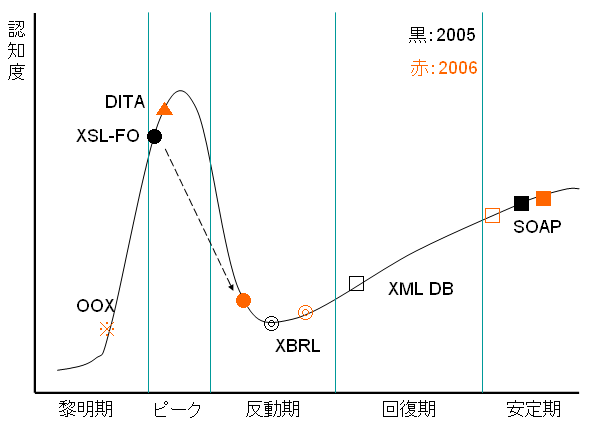
・2006年08月24日に取り上げましたDITAは、2005年のレポートでは登場していませんが、2006年に早くもピークという認識がなされてます。(そうなんでしょうか?)
・XMLデータベース(XML DB)は、2006年に安定期に入ったということです。
・そうかと思えば、XBRLのように2005年も2006年も同じ反動期に分類されているものもあります。
・今年、出現したOpen Office XMLファイル・フォーマットは黎明期で、これからということ。
こうしてみますと、大雑把にはあたっているといえなくもありません。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月26日
XSL-FO 2.0
XXX 2.0流行のこの頃ですが、XSL-FO 2.0会議が10月18日に開催されます。
Workshop on the Future of the Extensible Stylesheet Language (XSL-FO) Version 2.0
18 October 2006
Heidelberg, Germany
Located at offices of Heidelberger Druckmaschinen AG
XSL-FOは、そろそろV1.1が勧告になりますので、次は2.0を作ろうということです。
W3CでXSL-FOの開発が始まってからそろそろ8年(もう8年というべきでしょうか)。
アンテナハウスがXSL Formatterを開発初めてからちょうど7年になります。
XSL-FOは海外ではかなり普及していると思います。
しかし、日本では、実際のところ、かなり良い利用例も出てきているのですが、今ひとつ普及が進んでいないように思います。
先日、ジャストシステムの「2006年3月決算期事業戦略説明会」の資料をみてましたら、27ページにXML技術に関するHype Cycleという図が出ていました。(出展はガートナーグループの資料となっています。)
この図では、XSL-FOは、Peak of Inflated Expectations(過剰に膨らんだ期待のピーク)に分類されています。しかし、ちょっと違うんじゃないかな?もう、とっくにピークもTrough of Disillusionment(幻滅の時期)も過ぎて、安定した実用の時代に入っているように思います。
なんにしてもXSL-FO 2.0には期待大です。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年08月25日
Antenna House PDF ブランドについて
Adobeリーダなどで、PDFを表示して、PDFの文書情報を表示しますと、PDFを作成したソフト(Producer)の名前が表示されます。
アンテナハウスのPDF作成ソフト(XSL Formatter、PDF Driver)で作成したPDFには、ずっと、次の図のようにHyf PDF Output Library という表示になっていました。
![]()
しかし、7月からリリースした製品では、Antenna House PDF Output Libraryと変更しました。(次の図を参照してください)。
![]()
(Hyfとは、アンテナハウスが100%出資で北京に設立した「北京紅櫻楓軟件有限公司」の英文表記の略です。)
PDF生成ソフトにHyfと付けていたのは、中国の市場でPDF作成ソフトでビジネスを強力に進めるためでした。しかし、最近は、中国より日本でのPDFビジネスの方が中心になってきましたし、今後は、欧米の市場でも販売を強化することも考慮して、ブランド名を変更することにしたものです。
現時点で、特に開発体制が変わったわけではないですが、アンテナハウスと北京紅櫻楓軟件有限公司の開発者数を合わせますと、かなりの強力なメンバーになりますので、日本と中国の力を結集して、今後ますますPDFビジネスに力を入れていきたいと考えています。
どうぞ、よろしくお願いします。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月24日
DITA への関心が急激に高まっています
日本でDITA(Darwin Information Typing Architecture)について知っている人は、XMLについてかなりのディープな人だと思いますけれども、欧米では、DITAへの関心が急激に高まっているようです。
次の図は、YahooのDITA-Usersのメッセージ投稿数の月別推移です。
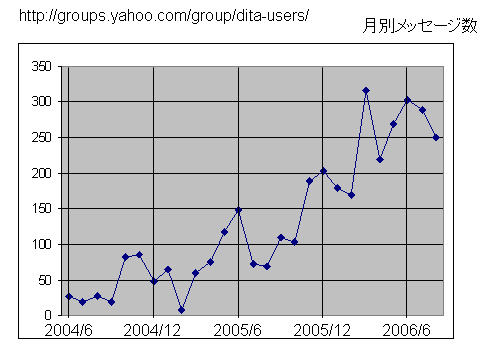
これを見ますと非常な急カーブでメッセージ投稿数が増えていることが分かります。
DITA-Usersグループは、DITAについて関心を持っている人が参加して情報交換するメーリング・リストなのですが、メッセージ投稿数が増えているということは、欧米でDITAに関心をもつ層が急速に増えていることを示しています。
DITAは、2005年5月にOASISの標準として策定されました。また、2005年9月に多言語組版研究会で取り上げましたが、その頃から比べてもメッセージ投稿数が2倍~3倍になっています。
今年の11月には、ヨーロッパで第2回DITAヨーロッパ会議もあります。要注目です。
ちなみに、DITAをPDFにするスタイルシートは、アンテナハウス、IBM、IDIOMの3社からオープンソースで提供されています。
※参考資料
DITA XML (Darwin Information Typing Architecture)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月23日
ブログをPDF化するサービス 続き
ブログをPDF化するサービスをもう少し調べてみました。
5.エキサイトブログ
エキサイトブログのPDF出版は、2年も前(2004年7月24日)に、極東ブログに「PDF出版とブログ」というタイトルの記事で紹介されています。
エキサイトブログは、オプションサービスのアドバンス(月々250円の有償サービス)に申し込みすると、毎日のブログをPDFで保存できます。
エキサイトブログで作成したPDFのプロパティをみますと、組版はLaTeXを使っています。PDF出力はdvipdfmxとなっています。
結構、大勢のブロガーが使っているようで、ブログの内容のPDF版をダウンロードできるようにしている人も見受けられます。
6.BookIt
BookItというのは、はてなダイヤリーなどのブログサービス会社と提携して、PDFを持ち込んで本をつくるサービスを提供しているんですね。
いろいろなブログのシステムでPDF化して、そのPDFをBookItに送って本に仕上げるということのようです。はてなダイヤリーが一番先だったようで、近藤社長のインタビューが紹介されています。
7.アメーバブログ
アメブロde本!というサービスをしています。アメブロde本!は表題の通り、PDF化というよりは、本にすることを主眼にしているようです。
Q&Aのページをみますと、目次ができない、画像の回り込みができない、など自動組版のレイアウト機能はあまり強力ではないようです。
アメブロのサービスでは、PDF化のことはまったく触れられていませんが、個人の趣味のブログでは、PDF化をアピールするよりも本にして楽しむことをアピールしているのでしょうね。
裏のしくみは推測になりますが、本を作る前にPDFを経由して印刷しているのではないかと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月22日
ブログをPDF化するサービス
ブログをPDF化・書籍化するサービスは結構いろいろなところで始まっていて、あまり新しい話題というわけでもないですが、どの位あるか調べてみました。
欧文印刷とイーストが行っているもの。
ブログをPDFに変換する無料サービス「mt2pdf」
簡単なレイアウトしか実現できません。
ムーバブル・タイプのインポート・エクスポート形式をPDFに変換する方式です。
無償サービスだそうです。
2.ブログ出版局
やはりブログからエクスポートしたデータをPDF化。
こちらは本を作成するサービスを中心としているようです。
無償でお試しPDFを作ることができるようです。
やはり横書きの簡単なレイアウトしか実現できません。
はてなダイヤリーブックは、日記を本にすることが主な目的のようです。見本のPDFを作るにもポイントが必要ということ。
mt2pdfとブログ出版局と比べると、レイアウトの種類がやや多く、横書きのみでなく縦書きもできます。
4.ココログ出版
サンプルPDFを作って、それで確認して本にします。
表紙、本文のレイアウト・パターンを幾つか選んで組み合わせるなどができます。横組みのほか、縦組みもできます。ココログ出版お申し込みフォームのページからデザインのサンプルのページを見ると、レイアウトパターンが充実しています。
で気になるのは、どんなPDF出力ツールを使っているかなんですが、
・BizPalブログ本作成サービス:iText
・ブログ出版局は、自前の組版エンジン:cssj
・はてなダイアリーブック:Adobe
・ココログ出版のサンプル:XSL Formatter
こうして見ますと、ココログ出版のレイアウトサンプルが一番よくできているように思います。やはり、組版ソフトにXSL Formatterを使っているということで差がでているのでしょう。
BizPalブログ本作成サービスなどでは、ブログのPDF版ではレイアウトを凝る必要がないと考えているのかもしれません。でも、利用者のコメントを読みますと、あまりレイアウトには満足していないような印象も受けます、改善の余地もあるのではないでしょうか。
※当初の記事にはココログ出版で使用しているツールについて記述に間違いがありましたので、訂正しました。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月21日
PDF/X シリーズまとめ
ISO 15930 (PDF/X) ファミリーの仕様書は、現在6冊あります。その概要をこれまで順次紹介してきました。
最後に簡単にまとめてみます。仕様の準拠レベルを大きく分けると、次の図のようになります。
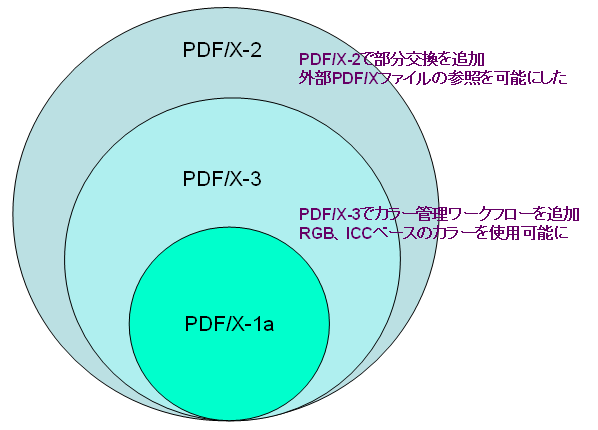
PDF/X-1aが基本で、これはPDFで使える機能に対して、主に次のような制限をつけたものです。
・すべての印刷用の複合実体をPDFファイル中に含むこと。
・カラーはCMYK、グレースケール、セパレーションカラー(特色)とそれをベースとするインデックスカラーなどに制限する
・出力インテントを使ってカラー印刷特性を設定する
・フォントは埋め込むこと
・データ圧縮はLZW、JBIG2を禁止
・ハーフトーンの制限
・PostScriptのプログラム埋め込み禁止
・暗号化禁止
・透明(PDF1.4)の使用禁止
これに対して、PDF/X-3では、RGB、ICCベースカラーの使用を可能にし、カラー管理ワークフローを実現できるようにしています。
さらに、PDF/X-2では外部のPDF/Xファイルを参照することができ、何回かに分けてPDF/Xファイル交換する部分交換が可能となります。
PDF/Xファイルを作成するソフトは、このような制限を満たすPDFを作りだせれば、PDF/X仕様準拠となりますが、PDF/Xファイルを読んで処理するプログラムは、すべての機能を正しく処理できなければなりません。従って、PDF/X-2準拠のリーダを作るのが最も大変ということになります。
※詳しくはこちらをご覧ください。
PDF/Xについて (1) PDF/X-1a
PDF/Xについて (2) PDF/X-3
PDF/Xについて (3) PDF/X-2
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月20日
FireFox とPDF
FireFoxで、WebページにリンクされたPDFを表示しようとすると、FireFoxが死んでしまうことがあります。どうもどこかで無限ループになるようですが、この現象、なかなか改善されません。
私のWindows2000では起きないのですが、Window XP SP2では、かなりの確率で起きます。
うまく表示して、Adobe Readerを抜けて、元のWebページに戻ることができることもありますが、どういう条件が揃ったとき、Adobe Readerから終了できるかわかりません。
FireFox、AdobeReaderもいくつかアップデートしてもあまり改善されず、Windowsについても、一回、完全に入れ替えたのですが、それでも変わらない。
FireFoxのナレッジベースには次の記述があります。
Acrobatの古いバージョンがあるとだめ?
最新版でも起きることがあり、鋭意調査を進めていますとありますが、1年経っても解決しませんね。
ちなみに、環境は次の通りです。
FireFoxのバージョン: 1.5.0.4
Windowsのバージョン: Windows XP Professional Version 2002 Service Pack 2
Adobe Reader: Version 7.0.8
Adobe Acrobat: Standard 6.0.0
このAcrobat Standard 6.0.0 が怪しいような気もします。
Acrobatのplug_insフォルダの中の一部のファイルだけを使ってみたらどうかどいうような対処策もブログにあります。しかし、やってみても解決しません。
Firefox PDF Acrobat Reader problem
というわけで、いまだに困っています。PDFにぶつかるたびに、注意してローカルに保存して開くしかないのかな?
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年08月19日
PDF/X-2について(5)
5.ファイル指定
前項で述べたReference XObject以外の方法により、PDF Reference 3.10項に定めるファイル指定機能を使うことは禁止です。
6.トラッピング
ファイルを交換するにあたり、info辞書のTrappedキーを使わなければなりません。Trappedキーでは、PDF/X-2ファイルそれ自身のトラッピング状態を示しますが、参照されるファイルや、PDF/X-2ファイルと参照されるファイル間の組合せにの間でのトラッピング状態を示すことはありません。
もし、PDF/X-2ファイルの中のすべての印刷要素についてトラッピングされているなら、Trappedキーの値はTrueになります。それ以外のケースでは、キーの値はfalseです。部分的にトラッピングされたファイルは許可されません。PDF/X-2ではTrappedキーの値にunknownは許されません。
Trappnet注釈を含むなら、Trappedキーの値はTrueでなければなりません。
FontFauxingキーの値についての条件は、PDF/X-1aと同じです。また、PCMキーの値の条件は、PDF/X-3と同じです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月18日
PDF/X-2について(4)
外部PDFを参照する元になる側のForm XObject(Reference XObjectのためのRefキーをもつもの)にも同じようにMetadataキーをもつ必要があります。
このMetadataキーの値となるメタデータ・ストリームには、XMPのxapMM:RenditionOf属性を含む必要があり、その値は、ResourceRef要素となります。また、xapMM:DocumentID、xapMM:VersionID、xapMM:RenditionClass属性を含まねばなリません。
xapMM:DocumentIDは、UUIDのような128ビット数のIDとし、ユニークになるように生成するべきです。
難しいですが、参照元のPDFのFormXObjectと、ターゲットのPDFをXMPのメタデータを使って対応関係を付けて、ターゲットを識別するということでしょう。
(3)ターゲットPDFの選択
PDF/X-2の仕様では、PDF/X-2のリーダが候補となるターゲットPDFを探す方法の機構までは定めていません。
但し、PDF/X-2のファイルは、OSや言語に依存しないように作るべきであり、PDF Referenceの仕様で言われている過搬性を満たすように注意するべき、とされています。
一旦、ターゲット候補となるPDFを認識できたならば、PDFの内部のオブジェクトのIDと、参照元とターゲットのメタデータを比較して、ターゲットを識別することができます。
(4)外部文書の描画
PDF/X-2のすべての内容は、同じ印刷特性設定になるように準備されねばなりません。
また、すべてのターゲット文書にある外部データを使って描画する必要があり、ターゲット文書が欠落した状態で描画してはなりません。
また、ひとつのPDFを描画する時は、そのPDFに埋め込まれたフォントを使用しなければならず、他のPDFに埋め込まれたフォントを使用してはなりません。
ターゲット文書を含むPDFとそれに含まれるPDF間のオーバ・プリンティングは、PDF Referenceの定義に従って行います。
Form XObject のBBエントリの座標は、ターゲットPDFのメディアボックスの左下隅に対して相対とします。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月17日
PDF/X-2について(3)
4.外部参照要素
(1) 仕組み
PDF/X-2のファイルでは、印刷要素を省略することができます。この場合、省略した印刷要素については、Form XObjectの機能を使って代理データを含めておく必要があります。代理データはプレビュー画像などでも問題ありません。
代理データは、Reference XObjectの機構を使って、要素を置換するための対象データを指し示さねばなりません。この参照辞書にはIDを含めなければなりません。
PDF ReferenceのXObjectというのは、一塊の完結したグラフィックス・オブジェクトのことを言います。これは、Image XObject、Form XObject、PostScript XObjectの3種類が代表的なものでしたが、PDF 1.4からReference XObject、Group XObjectが追加されています。
このReference XObjectの機構を使うとあるPDFファイルの中に、別のPDFの内容を持ち込むことができます。PDF/X-2ではこの機構を使って別のPDFファイル(ターゲットPDF)を参照することで、部分交換を可能とします。
Reference XObjectのターゲットPDFは、PDF/X-1a:2001、PDF/X-1a;2003、PDF/X-3:2002、PDF/X-3:2003またはPDF/X-2:2003のいづれかでなければなりません。
Form XObject、Image XObjectのOPIキーを使うことはできません。
(2) ターゲット文書の識別
ターゲットPDFのCatalog辞書にはMetadataキーがなければなりません。メタデータを構成するデータは、XMP準拠になっていることが必要で、xapMM:DocumentID, xapMM:VersionID, xapMMRenditionClassプロパティを含まねばなりません。多くの場合、 xapMMRenditionClassの値は、defaultとなります。
※XMPについては、こちらを参照してください。
XMP™ (Extensible Metadata Platform)仕様についてのメモ
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月16日
PDF/X-2について(2)
1.PDF/X-3との関係
PDF/X-2の仕様は、PDF/X-3:2003の仕様のほぼすべての制約を満たさねばなりません。
PDF/X-3:2003については、次を参照してください。
PDF/Xについて (2) PDF/X-3
上のWebページで説明しているPDF/X-3:2003についての制約の中で、PDF/X-2に適用されないのは、次の4項目です。
1.PDF/X-3 ファイル構造
4.ファイル指定
6. トラッピング
7. PDF/X-3ファイルの識別
PDF/X-3が完全交換を目的としていて、一回のPDFファイル交換ですべての情報を交換しなければならないのに対し、PDF/X-2は部分交換を目的とするため、複数回に分けて情報交換を行うことを認めていることから、制約条件が変わっていることになります。
次にPDF/X-3と異なる箇所のみ説明します。
2.PDF/X-2ファイル構造
PDF/X-2では、複合実体のすべての要素がひとつのPDF/X-2ファイルに含まれているか、それとも、後述の外部参照要素の規定に準拠して識別できなければなりません。
※この下線を引いた部分が、PDF/X-3と異なる部分です。
3.PDF/X-2のファイル識別
Info辞書のGTS_PDFXVersionキーの値を(PDF/X-2:2003)とします。
Info辞書のその他のキーの使い方はPDF/X-3と同様です。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月15日
PDF/X-2について
さて、しばらく間が空いてしまいましたが、PDF/Xシリーズの最後に、PDF/X-2について調べてみたいと思います。
PDF/X-2は、PDF 1.4を用いた印刷データの部分交換という副題がついていて、次の仕様書で規定されています。
ISO 15930-5:2003
Part 5: Partial exchange of printing data using PDF 1.4 (PDF/X-2)
準拠ファイルとツール
PDF/X-2に準拠しているかどうかの判断は、PDFファイルのバージョン番号でするのではなく、PDFファイルに含まれている印刷用の複合実体の交換に必要な特徴がISO 15930-5:2003の仕様書に沿っているかどうかで判断しなければなりません。なお、印刷用複合実体の再現には関係ない情報が含まれていても差し支えありません。
PDF/X-2準拠のライター(作成ソフト)は、PDF/X-2のファイルを生成することができれば良いのですが、PDF/X-2準拠のリーダ(読むソフト)はPDF/X-2だけではなく、PDF/X-1a:2001、PDF/X-1a:2003、PDF/X-3:2002、PDF/X-3:2003のすべてを適切に処理できなければなりません。
従って、PDF/X-2が、PDF/Xシリーズの最上位規格ということができると思います。
部分交換
PDF/X-2は部分交換という副題がついています。部分交換とは、一部の印刷要素、または要素の資源を、交換から意図的に除外しておき、別途入手可能とする方式です。データ交換で除外された要素をユニークに識別するための情報を提供することができるようになっています。
PDF/X-2の仕様は、部分交換を可能にすることで、他の仕様を補完するものとされています。
※用語については
2006年07月10日 PDF/X-1, PDF/X-1a (ISO 15930-1:2001)をご覧ください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月14日
Acrobat 8は2006年末リリース
New York Times 8月5日にAdobeのCEO Bruce Chizen 氏のインタビューが掲載されています。
Adobe Reaches Far and Wide
By JUSTON JONES
Published: August 5, 2006
New York Times
Technology欄
※日にちが経ったためか、既に、登録しないと全文を読めなくなってしまっています。
それによると、Acrobat 8が、今年(2006)年終わりにリリースされるそうです。
おそらく、Microsoft Office 2007 のリリースに合わせて、新しいリリースを出そうと考えているものと思いますけれども、また、一方で、Flashの統合どうなるかも興味があります。
※この記事は、最初8月13日付けで公開しましたが、都合により8月14日公開に変更しました。ご迷惑をおかけしましたことをお詫びします。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月13日
PDFで隠したはずの個人情報丸見え — について
オーシャンブリッジの高山社長のブログを見てましたら、「PDFで「隠したはずの個人情報丸見え 千葉市教委のホームページ」(2006年08月01日)という記事が眼に留まりました。
PDFを外部に配布するにあたり、秘匿したい部分に、「墨塗り」をして消したつもりで配布したところが、実際は、PDFのコンテンツには、塗りつぶされたはずの本文が残っていて、情報が取り出せてしまったという問題です。
この問題は、8月1日の朝日新聞に掲載されたもので、もうブログの世界の格好の話題だったようです。遅れていてすみません。
岡村 久道 IT弁護士の眼 ホームページ「部分黒塗りPDFファイル」事件や、Okumura's Blog他のブログでも取り上げられています。
「千葉市教委HP「墨塗り」丸見え、会見で謝罪」記事によると、「ワープロソフトで会議録を作成した際、個人情報の部分を『蛍光ペン』という機能を使って墨塗りしたが、元の文書を消していなかった。確認不足で、技術的に未熟だった」としています。
PDFを後処理したのではなく、ワープロソフトの蛍光ペン機能を使ったとなっています。としますと、この問題はPDFを作るときの注意事項です。
技術的問題というよりも、啓蒙活動が必要な類の話題ということになります。
そういう点では、高木浩光@自宅の日記ブログの■ 公務員研修で体験させておくべき演習 「蛍光ペンで墨塗り」の巻を読むのが良いですね。
文字を見えなくする方法としては、(1)ワープロの蛍光ペンを使って文字と同じ色で塗りつぶす、(2)不透明な矩形等(ワードではシェイプ)を文字の上に配置する、(2)文字の色を背景の色と同じにするなど幾つか方法が考えられます。これらの方法では、文字情報そのものを消しているわけではありません。ただ、画面上で文字を見えなくしているだけです。PDFにすると、その文字情報もPDF内に出力されます。PDFに限らずワープロ文書を配布する場合も同じなので、注意しなければならない、ということ。
ちなみに、アンテナハウスでは、5年程前に、あるSI会社からの依頼で、PDFで情報公開するための「伏字フィルター」を開発したことがあります。
この「伏字フィルター」は、単に塗りつぶすのではなく、PDFコンテンツの該当文字自体を、別の文字に置換してしまう、というもの。公開したPDFの中から元の情報そのものは完全に削除してしまっています。ですので、消したはずの情報を取り出すのは不可能で、「あらら、見えてしまう」ということは起こり得ません。
実際のところ、PDFで「隠したはずの個人情報丸見え」というような問題が頻発するなら、本物の「伏字フィルター」を広く社会に提供することが必要かもしれない、と感じた次第です。しかし、千葉市教委のPDF黒塗りファイル事件のような問題は、ツールだけでは防止できそうもありませんね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月12日
PDF千夜一夜 300日達成!
1000日連続更新を公約して始めた、このブログですが、今日で、300日連続更新を達成しました!
過去の記事一覧はこちらでご覧いただけます。
このブログは、企業ブログとしてマーケティング上の目的をもって始めたものですが、最近は、かなり大勢の方から「読んでいるよ」という声をかけていただき、多少は、アンテナハウスPDFのPRに繋がっているかな、と手ごたえを感じています。
昔から、「石の上にも三年」と言われています。
この言葉を、私は、どんなことでも3年間一生懸命やればなんとかなるという教えと解釈しています。
20数年企業を経営してきた経験からは、また、3年というのはビジネスの成否を判断するときのひとつの区切りにもなると思います。
3年は、ほぼ1000日に相当します。このブログを書いている3年の間で、アンテナハウスPDFをちゃんとしたビジネスにするということです。
既にその3割が経過してしまった訳で、月日が経過する速さは、まさに光陰矢の如しですが、残り700日頑張りぬいて、目標達成を目指したいと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年08月11日
Webレポート作成システム紹介セミナー のご案内
さて、来る9月14日(木)アンテナハウスと(株)ジャスミンソフト共催で「Webレポート作成システム紹介セミナー」を開催します。
今回のセミナーでは、XSL1.1仕様(勧告候補)に準拠したアンテナハウスの「XSLFormatter」、Webデータベースを構築・運用するジャスミンソフトの「Wagby」と、両ツールで実現したWebレポート作成システムの事例をご紹介いたします。
■開催日時
9月14日(木曜日) 14:00~16:00
■内容
14:00~14:40 アンテナハウス(株)長縄敏行
・XSLFormatterV4概要のご説明
14:50~15:40 (株)ジャスミンソフト贄良則
・ Wagby概要のご説明
・ Webレポート作成システムのご説明
15:40~16:00 質疑応答
■場所
アンテナハウス株式会社 本社セミナールーム
■ジャスミンソフトについて
ジャスミンソフトは、沖縄のソフトハウスで、ユニークで優れた製品を作っています。アンテナハウスのリセラーとしてもXSL Formatterを販売していただいています。
なお、アンテナハウスでは、システム製品を販売するためのリセラー・ネットワークを作っています。
アンテナハウスでは、今後、リセラー各社と合同でセミナー形式による情報提供を行うことで、お客様により良い情報を提供し、かつ、リセラー各社と共存・共栄を図っていきたいと考えています。
ぜひ、よろしくお願いします。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月10日
リッチテキストPDF2の変換例
さて、リッチテキストPDF2で、どの位までPDFをうまく変換できるのだろうか?と疑問に持たれる方が多いと思います。
そこで、ひとつ変換例を紹介してみたいと思います。
このPDF文書を変換元として、Wordに変換してみましょう。
このPDF文書は、2005年10月31日 PDFからXMLへのデータ変換(3)で紹介しましたが、PDF帳票のデータを取り出してXMLに変換するプログラムを開発するための仕様書です。
オリジナルは、私が1年ほど前に書いた文書です。
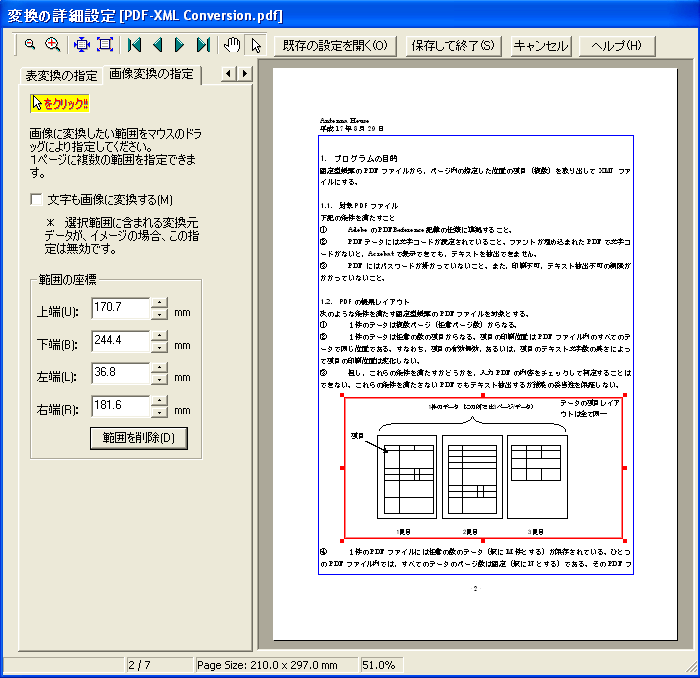
このPDFを、リッチテキストPDF2を使って、Microsoft Wordに変換するにあたり、次の設定をしました。
(1)このPDFには、ヘッダとフッタがあります。そこで、昨日示しましたように、PDFのプレビュー機能を使用して、本文の範囲を設定しました。
(2)さらに、線画で書いた図を含んでいますので、線画の部分を「画像変換の指定」を機能を使って、画像変換領域に指定しました。(次の図)
そして、この設定条件を使用して、MicrosoftWordに変換した結果は次のとおりです。
いかがでしょうか?
ヘッダ、フッタもほぼ正しく変換されていますし、線画がEMF形式として変換できます。
ワープロ文書と違って、PDFファイルは再利用を意図して作成されていませんので、完全な変換はなかなか難しいものですが、この文書の場合は、完全とはいえないまでも、かなり元のワープロ文書に近くなっていることがお分かりいただけると思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月09日
リッチテキストPDF2 近日発売
アンテナハウス株式会社は、8月下旬からPDF活用ツールの新版「リッチテキストPDF2」を発売いたします。
「リッチテキストPDF2」は、PDFからWord、一太郎、Excelにテキストやレイアウトまで含めて高精度に変換する機能と、PDF作成、結合・分割などPDF利用をサポートする機能を中心とするユーティリティソフトです。
1.PDFからWordや一太郎への変換では、段落書式や表書式、文字飾り、イメージ、線画まで、元文書のイメージに近い形で再現します。
(1) 新バージョンでは、PDFの解析機能を強化し、PDFからWord、一太郎への変換精度アップを行いました。
(2) 新たにPDFプレビュー機能を実装し、PDFを表示しながら、ページ単位で、余白の大きさや、表・画像に変換する領域の指定することが可能となりました。
a.PDFのページには余白(マージン)情報がありません。そこで変換にあたって、余白を推定します。しかし、ヘッダ、フッタがあると上余白や下余白を正しく推定できません。そこで、PDFビューアを使って、本文領域を設定することで、ヘッダやフッタを本文と分離して変換することができます。
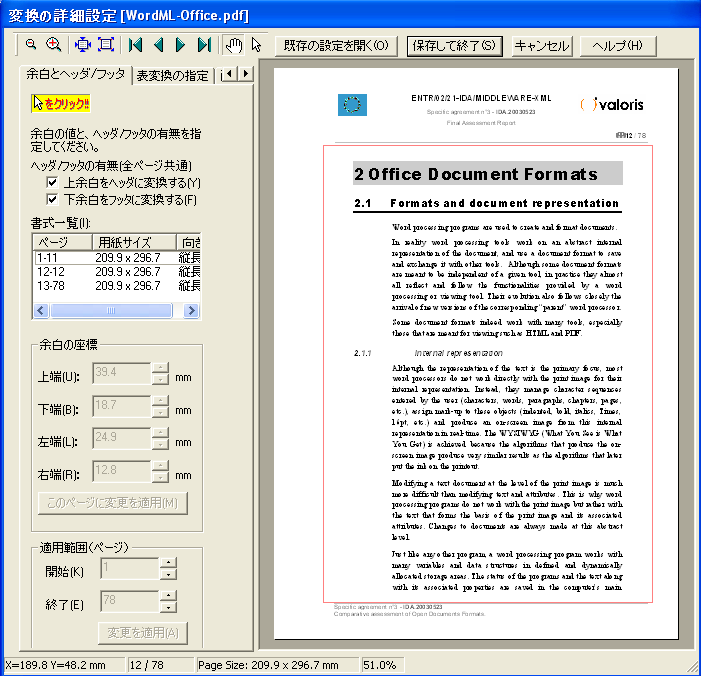
上の例では、PDFのページを表示して本文領域を設定します。上余白、下余白のデータはヘッダ、フッタとして変換します。
b.さらに、画像に変換したい領域を指定することでページの中の特定領域を線画に変換することもできます。
2.新バージョンでは、PDFからExcelへの変換についても表書式、文字飾り、イメージ、線画まで、元文書のイメージに近い形で再現可能となりました。
3.その他、Officeアドインが可能なPDFドライバを使用したPDF作成機能、PDFからテキストや画像を抽出するデータ抽出機能、PDFの分割・結合機能、セキュリティ設定、Web最適化機能など、PDF活用のための機能を装備しています。
詳細はこちらをどうぞ。
■ニュースリリース 新製品「リッチテキストPDF2 for Windows」発売のお知らせ
■製品Webページ リッチテキストPDF2
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月08日
PDF セミナー 第二回終了しました。
PDFセミナーの第二回を行いました。セミナーの最初にもお話しましたが、アドビはPDFを、どんどん機能強化して難しいものにしていっています。
それに対して、私達は、PDFをもっと簡単に使えるものにしていきたいと考えています。PDFが紙に代わる電子媒体であるならば、PDFを紙と同じように身近に簡単に使えるようにしていくこと、それが私達の使命であると考えています。
ところで、セミナーでお話しする材料として、Webで配布されているPDFを幾つか集めて、しおり、Web最適化、タグ付きPDFの使用状況を調べて見ました。
次の表は、Webで検索してダウンロードしたPDF(中央官庁の報告書、マニュアル類とメーカのマニュアル類)におけるしおり、Web最適化、Tag付きPDFの設定率です。
全体で29件しか調べていなくて、数が少ないのであまり数字に統計的な意味がないですが、それでも何となく傾向は分かります。
| 利用率 | しおり(BookMark) | Web最適化(リニアライズ) | Tag付き |
|---|---|---|---|
| 全体 | 27.6% | 72.4% | 6.9% |
| 100P以上 | 66.7% | 33.3% | 16.7% |
| 100P未満 | 17.4% | 82.6% | 4.3% |
これで気がつきますのは、しおり(Bookmark)の使用率が意外に低いこと、およびWeb最適化の使用率は意外に高いことですね。
しおりはプリンタドライバからPDFを作成するだけでは設定できないことが理由と思います。PDFを閲覧する上で、しおりはとても便利な機能なのでもう少し使用率を高める工夫が必要ではないでしょうか。
タグ付きPDFの利用率が低いのは予想通りです。
次回セミナーは、9月4日(月曜日)開催の予定です。ぜひ、大勢の方にご参加くださいますようお願いします。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年08月07日
PDF/X-3 まとめ
これまで見てきましたように、PDF/X-3は、PDF/X-1aの上位拡張仕様です。具体的には、カラー空間の使用可能範囲を広げて、「カラー管理ワークフロー」を可能にしたものです。
2006年07月28日 PDF:RGBワークフローとデジタルカメラで述べましたように、最近ではデジタルカメラなどで撮影したカラーイメージ画像が印刷に使われることも増えていますので、PDF/X-1aよりもむしろPDF/X-3が重要になりそうです。
PDF/X-3についての今までのブログの記事を整理して下記にまとめてみました。
PDF/Xについて (2) PDF/X-3
参考にしていただければ幸いです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月06日
PDF/X-3 (5)
9.境界ボックス
PDF/X-3の境界ボックスに対する条件は、PDF/X-1aとまったく同じです。
PDF/Xについて (1) PDF/X-1a 7.境界ボックスを参照してください。
10. 拡張グラフィックス状態
PDF/X-3の拡張グラフィックス状態に関する制約もPDF/X-1aとまったく同じです。
PDF/Xについて (1) PDF/X-1a 8.拡張グラフィックス状態を参照してください。
11. PostScript XObject
PDF/X-3ではPostScript XObjectを使うことはできません。この制約もPDF/X-1aとまったく同じです。
12.暗号化辞書
PDF/X-3では、暗号化辞書を使うことはできません。PDF/X-1aと同じです。
13.代替イメージ
PDF/X-3の代替イメージに関する制約もPDF/X-1aとまったく同じです。
PDF/Xについて (1) PDF/X-1a 11.代替イメージを参照してください。
14.注釈
PDF/X-3のトラッピング以外の注釈は、完全にBleedBox(もし、BleedBoxが無い時は、TrimBoxまたはArtBox)の外側になければなりません。PDF/X-1aと同じです。
15.アクション、JAVAScript
PDF/X-3では、アクションやJAVAScriptを使うことができません。PDF/X-1aと同じです。
16.BX/EXオペレータの使用
BX/EXオペレータの使用に関する制約は、PDF/X-1aと同じです。
PDF/Xについて (1) PDF/X-1a 14.BX/EXオペレータの使用を参照してください。
17.デジタル署名
PDF/X-3は、デジタル署名を含むことができます。PDF/X-3のリーダはデジタル署名を無視してもかまいません。
18.透明
PDF 1.4から追加された透明は、PDF/X-3:2003で使用条件に制約が課されています。この制約は、PDF/X-1a:2003と同じです。PDF/Xについて (1) PDF/X-1a 15.透明を参照してください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月05日
PDF/X-3 (4)
4. フォント
PDF/X-3では、フォントのグリフ、メトリックス、符号化方法は、使用されているすべての文字について埋め込まれていなければなりません。
フォントは埋め込みを許可されたもののみを埋め込みできますので、埋め込みが許可されていないフォントをPDF/X-3で使うことはできません。
5.ファイル指定
PDFでは、ファイル指定機能によって、他のファイルの内容を参照することができます。PDF/X-3ではファイル指定機能を使うことは禁止事項です。
参考 PDF Reference Fifth Edition 3.1 File Specifications pp. 151 - 162
6.データ圧縮
PDF/X-3:2002では、LZW以外のPDF1.3で使える圧縮を使用できます。
PDF/X-3:2003では、LZWとJBIG2以外のPDF1.4で使える圧縮を使用できます。
7.トラッピング
PDF/X-3のトラッピングについての仕様は、PDF/X-1aとカラー空間を示すPCMの規定を除いてまったく同じです。
PDF/Xについて (1) PDF/X-1a 5.トラッピングを参照してください。
すなわち、PDF/X-1aでは、PCMキーの値は、DeviceCMYKのみが許されていましたが、PDF/X-3では、PCMキーの値は、PDF/Xの出力インテントで指定した印刷条件に一致していなければならないというように拡張されています。
8.PDFファイルの識別
PDF/X-3のファイルは、Info辞書のGTS_PDF/XVersionキーで識別します。
PDF/X-3:2002ではキーの値が、(PDF/X-3:2002)となります。
PDF/X-3:2003ではキーの値が、(PDF/X-3:2003)となります。
PDF/X-1a の文書情報辞書の一般項目の設定は、PDF/X-1aと同じです。
PDF/Xについて (1) PDF/X-1a 6.PDFファイルの識別を参照してください。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月04日
PDF/X-3 (3)
3.2 デバイス依存カラー
DeviceCMYKは、印刷条件がDeviceCMYKで指定されている時は、PDF/Xの出力インテントで識別される印刷条件で解釈しなければなりません。
これに対して、PDF/X-3のファイルにDeviceCMYKで定義されるカラーが含まれているにも関わらず、指定印刷条件がCMYKでないならば、Resource辞書のColorSpace下位辞書にDefaultCMYKカラー空間を含めなければなりません。そして、それは測色計によるカラー定義を提供しなければなりません。
DeviceGrayは、印刷条件がCMYKで指定されている場合、その黒色成分とみなします。印刷条件がグレーで指定されるときは、PDF/Xの出力インテントで識別される印刷条件で解釈しなければなりません。
DeviceGrayで定義されるカラーデータを含んでいるにも関わらず、指定印刷条件がCYMKでもグレーでもない場合は、Resource辞書のColorSpace下位辞書にDefaultGrayカラー空間を含めなければなりません。そして、それは測色計によるカラー定義を提供しなければなりません。
DeviceRGBも、DeviceCMYK、DeviceGrayと同様です。
3.3 ICCBasedカラー空間
ICCBasedカラー空間やその他の既定値のStream辞書では、Alternate(代替)カラー空間を含むことができません。
3.4 Separation, DeviceNカラー空間
CMYKカラー、スポットカラーにはSearationまたはDeviceNカラー空間を使うことができます。
PDF/X-3におけるSeparation, DeviceNカラー空間の仕様は、PDF/X-1aにおける同様の仕様を3.2項の記述に沿って拡張したものとなっています。
すなわち、送り手と受け手が、別の約束をしていない限り、名前をつけた色素は、意図した出力デバイスで使える独立した色素でなければなりません。
SeparationまたはDeviceNカラー空間で指定したスポットカラーをプロセスカラー色素を使って印刷するときは、SeparationまたはDeviceNカラー空間の代替カラー空間と色調変換式を使います。
代替カラー空間が、PDF/Xの出力インテントと同じデバイス依存カラーの場合、PDF/X-3準拠のリーダは、代替カラー空間をその印刷条件を参照するものとして扱います。また、代替カラー空間がDeviceGrayの場合は、PDF/X出力インテントで識別されるCMYKの黒と同等に処理します。代替カラー空間が、印刷条件と対応しないデバイス依存カラー空間を使っている場合は、3.2項を適用します。
3.5 Indexed、Patternカラー空間
Indexed、Patternカラー空間の基底となるカラー空間についても、上記の3.2項を適用します。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月03日
マイクロソフトXPSについて
今日は、マイクロソフトのWindows Color System(WCS) とXML Paper Specification(XPS)に関するセミナーがあり、出席してみました。
マイクロソフトのセミナーに出席するのも久しぶりです。
セミナーの内容については、NDAを提出してしまったため紹介できませんが、印象を一言だけ紹介します。私の印象は幾らなんでもNDAではないでしょうから。
時間中に、参加者から質問を集めて、セミナーの最後に質問に回答するという方式でQ&Aがありましたが、セミナーのQ&Aの方法としては、とても良い方法だと思いました。
かなり沢山の質問が集まっていましたが、その質問を聞いていて感じたことです。
1.PDF/Xに、WCS仕様のカラープロファイルを埋め込めるか、質問とか、PDF/Xでは、。。。だけど、XPSではどうか、というようなPDF/X関連の質問が多かったこと。
参加者は専門家が多かった(?)ようですが、それにしてもPDF/X関連の質問が多いことが予想以上でした。
2.PDFでは、。。。になっているが、XPSではどうか、という類の質問も多かったように思います。このことはセミナー参加者の中はXPSをPDFと競合するものと認識している人が多いということを示していると思います。
XPSは、10年以上PDFに遅れて登場したわけで、現時点では機能的にもPDFとは比較にならないほど低いのですが、10年後ははたしてどうなるのだろうと、質問を聞きながら考えてしまいました。
遅れてきたということは、逆にそれなりのメリットもあります。PDFでは既に使われなくなったPostScriptX オブジェクトのような過去の仕様が残っているなど技術的に過去を引きずっている部分があります。しかし、まったく新しく設計すれば過去のシガラミがない分だけ技術的には有利でしょう。
将来、XPSがPDFと同じ地位を占めるようになるのでしょうか?そして、その時、世の中はどのように変化しているのでしょうか?
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月02日
PDF/X-3 (2)
3. カラー空間
PDF/X-3:2002、PDF/X-3:2003では、出力デバイスのコード値でカラーを交換したり、測色計で定義したデータでカラーを交換できます。
いづれにせよ、印刷条件を事前に、名前付きの条件またはICC出力プロファイルの形で用意しておかねばなりません。
測色計で定義したデータを記述するには、PDFのICCBasedカラー空間のICCプロファイルを使うか、または、CalGray、CalRBG、Labカラー空間の同等の仕組みを使います。
出力デバイスのコード値は、PDFでは、DeviceRGB、DeviceCMYK、DeviceGray、Separation、DeviceN、Indexed、Patternカラー空間を、これから述べるような制約の元で使用できます。
3.1 出力インテント
出力インテントについては、PDF/X-1aと次の点を除いてまったく同じです。
印刷要素にデバイス独立のカラー空間を使用しているとき、DestOutputProfileキーが存在しなければならない。
PDF/X-1aについては、PDF/Xについて (1) PDF/X-1aの 2.1 OutputIntentによるカラー印刷特性の識別の記事を参照してください。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月01日
PDF セミナー 第一回終了しました。
今日は、PDFセミナーの第一回目を開催しました。第一回目とあって、関心も高かったのか、ほぼ満席のご参加をいただきました。
ご参加いただきました皆様、つたないお話を聞いていただき、本当にありがとうございました。
セミナーの準備にあたって、PDFのソフトを幾つか買い揃え、また、関係スタッフを動員して、PDFソフトの比較表も作ってみました。これは、セミナーのみの資料ですので、ぜひ、お時間の許す方は、次のセミナーにご参加ください。
お申し込みはこちらです。
アンテナハウス PDF セミナー
ところで、アンテナハウスでは、「リッチテキストPDF2」を開発してきまして、そろそろ、発表の時期も近くなっています。
セミナーの資料を作るにあたり、「リッチテキストPDF2」を他社のPDFからワープロへの変換ソフトと比較としてみましたが、今度のバージョンはだいぶ良くなったという印象があります。
現在、日本で販売されているPDFからワープロ変換ソフトは沢山ありますが、日本製のものは、「いきなりPDF to Data」を含め、みな、OCR技術を応用したものです。PDFを画像に変換し、画像をOCRで文字認識、認識結果をワープロ文書に変換するというものです。
これに対して、海外の会社が作って日本で販売しているものは、みな、PDFファイルの描画命令を直接解析するタイプです。日本製では、「リッチテキストPDF2」のみが、海外製と同じようにPDFファイルの描画命令を解析するタイプです。
「リッチテキストPDF2」は、これらの海外製品と比較してもトップクラスになったと思います。もう少し頑張れば、世界のトップの座も狙えそうなところにきました。
世界トップの製品を作って海外で戦う日が来るのが待ち遠しいです。ぜひ、皆様の応援をよろしくおねがいします。
投票をお願いいたします