« 2006年09月 | メイン | 2006年11月 »
2006年10月31日
XSL Formatter、決算報告書組版で1/4のシェアを取る!
LiveDoorファイナンスの企業開示情報(PDF)で、10月30日16時から19時の間に開示されたPDFによる企業情報の中で、10ページ以上のものについて、PDF作成エンジン、アプリケーション、および、しおりの有無について調べてみました。
PDFによる企業開示情報は膨大な数に達していますが、10ページ以上のものは、大雑把に言って20%位です。
16時から19時の間に開示されたものを130件ほどチェックしてみましたが、その中で10ページ以上のPDFが23件ありました。
23件のPDFの中で、PDF作成アプリケーションがXSL Formatterになっているものが6件ありました(下の表を参照)。シェアにしますと1/4がXSL Formatterで作成されているということ。これらは、ほとんど財務諸表です。いまや、かなり多くの財務諸表がXMLで作られて、Formatterで組版されていると言っても良いと思います。
中には、Microsoft ExcelやWordで作っている会社もあるようです。
もうひとつは、しおりの使用率が低いことです。10ページを超えるようなPDF文書ですと、やはりしおりをつける方が閲覧しやすいと思いますが、しおりをつけているのは23件中わずか3件しかありません。
Formatterを使えば、しおりを自動的につけることができるのですが、使われていないのは、少し残念です。
■企業情報開示情報PDFの作成アプリケーションなど(2006年10月30日夕方調べ)
| コード | 会社名 | 表題 | ページ数 | しおり有無 | PDF生成エンジン | アプリケーション |
|---|---|---|---|---|---|---|
| 8720 | ベンチャービジネス証券投資法人 | 平成19年1月期 中間決算短信(非連結) | 20 | N | Acrobat Distiller 5.0.5 Windows | NA |
| 2125 | ディー・ブレイン証券 | 平成 19 年 3 月期 個別中間財務諸表の概要 | 11 | N | Acrobat Distiller 7.0.5 Windows | PScript5.dll Version 5.2 |
| 6917 | デンセイ・ラムダ | 2007年3月期中間決算説明会資料 | 27 | N | Acrobat Distiller 6.0 Windows | NA |
| 9008 | 京王電鉄 | 2006年度 中間決算説明資料 | 39 | N | HyperGEAR PDFOCRLib rev1.11 Date 2002/07/18 | NA |
| 9022 | 東海旅客鉄道 | 平成19年3月期中間決算補足資料 | 15 | N | Acrobat PDFWriter 5.0 Windows NT | Powerpoint |
| 8768 | ミナミ保険 | 平成 18 年 8 月期 決算短信(非連結) | 13 | N | Acrobat Distiller 7.0.5 Windows | PScript5.dll Version 5.2 |
| 3754 | エキサイト | 平成19年3月期 中間決算短信(連結) | 44 | N | Hyf PDF Output Library 2.3.0 (Windows) | XSL Formatter 3.4 MR2 |
| 3754 | エキサイト | 平成19年3月期 個別中間財務諸表の | 30 | N | Hyf PDF Output Library 2.3.0 (Windows) | XSL Formatter 3.4 MR2 |
| 5970 | 菊池プレス工業 | 平成19年3月期 個別中間財務諸表の概要 | 14 | N | Hyf PDF Output Library 2.3.0 (Windows) | XSL Formatter 3.4 MR2 |
| 5970 | 菊池プレス工業 | 平成19年3月期 中間決算短信(連結) | 29 | N | Hyf PDF Output Library 2.3.0 (Windows) | XSL Formatter 3.4 MR2 |
| 4674 | クレスコ | 平成19年3月期 個別中間財務諸表の概要 | 12 | N | Acrobat Distiller 6.0.1 (Windows) | Word 用Acrobat PDFMaker6.0 |
| 6660 | フォトニクスソリューション | 平成19年6月期 第1四半期決算短信(非連結) | 10 | N | Acrobat Distiller 7.0.5 Windows | PScript5.dll Version 5.2 |
| 9532 | 大阪瓦斯 | 2007年3月期中間決算プレゼンテーション資料 | 24 | N | Acrobat Distiller 5.0.5 Windows | NA |
| 9532 | 大阪瓦斯 | 平成19年3月期 中間決算短信(連結) | 24 | Y | Acrobat Distiller 7.0Windows | PScript5.dll Version 5.2 |
| 9532 | 大阪瓦斯 | 平成19年3月期 個別中間財務諸表の概要 | 11 | Y | Acrobat Distiller 7.0Windows | PScript5.dll Version 5.2 |
| 4329 | ワークスアプリケーションズ | 平成19年6月期 第1四半期財務・業績の概況(連結) | 15 | N | Acrobat Distiller 6.0.1 (Windows) | NA |
| 8699 | エイチ・エス証券(株) | 平成19年3月期 個別中間財務諸表の概要 | 14 | N | Hyf PDF Output Library 2.3.0 (Windows) | XSL Formatter 3.4 R1 |
| 8699 | エイチ・エス証券(株) | 平成19年3月期 中間決算短信(連結) | 38 | N | Hyf PDF Output Library 2.3.0 (Windows) | XSL Formatter 3.4 R1 |
| 6911 | 新日本無線 | 平成19年3月期 個別中間財務諸表の概要 | 14 | N | Acrobat Distiller 7.0.5 Windows | PScript5.dll Version 5.2 |
| 6911 | 新日本無線 | 平成19年3月期 中間決算短信(連結) | 32 | N | Acrobat Distiller 7.0.5 Windows | PScript5.dll Version 5.2 |
| 6756 | 日立国際電気 | 平成19年3月期個別中間財務諸表の概要 | 15 | Y | Acrobat Distiller 6.0.1 (Windows) | Adobe Acrobat 6.0 |
| 9694 | 日立ソフトウェアエンジニアリング | 平成19年3月期 中間決算短信(連結) | 18 | N | Acrobat PDFWriter5.0 Windows NT | Microsoft Excel |

投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月30日
リッチテキストPDF2 D&Dが、ベクターのダウンロード製品ランク入り
10月20日発売のリッチテキストPDF2 D&Dが、ベクターのダウンロードソフトでランク入りしました。
10月22日から28日の期間で9位です。
この順位は毎日変わりますので、証拠PDFをここに用意しました。
ベクターのダウンロードソフトランキング2006/10/28(PDF)
多分、10月23日から29日(30日)ですと、ランクはもう少し上がると思います。

参考:ランキング ダウンロードソフト(Windowsソフト)
※ちなみに、上の証拠PDFは、IE7で、プリントプレビューで縮小してPDF化したものです。このレベルの縮小フィットは、FireFoxでも大体同じことができます。IE7だから特に良いということはありません。ただし、IEの方がページのサイズ(レターサイズからA4への切り替えや、スライダによるマージン幅の変更などの操作性が良いと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月29日
Unicode Line Breaking Properties (2)その動向
Uncode Line Breaking Properties (UAX #14)は、Unicodeの付録として分類されていますが、Unicode仕様の一部であり重要な仕様です。
1999年8月に第5版の段階でUnicodeのテクニカルレポートとして、初めて正式な仕様になっています。
・1999年8月 第5版 http://www.unicode.org/unicode/reports/tr14-5(Unicode 3.0)
その後、次の時期に改訂版が出ています。正式仕様版の間に、提案書としての版があります。
・1999年11月 第6版 http://www.unicode.org/unicode/reports/tr14/tr14-6.html(Unicode 3.0)
・2000年8月 第7版 http://www.unicode.org/reports/tr14/tr14-7.html(Unicode 3.0.1)
・2000年2月 第10版 http://www.unicode.org/reports/tr14/tr14-10.html(Unicode 3.1.0)
・2002年3月 第12版 http://www.unicode.org/reports/tr14/tr14-12.html(Unicode 3.2.0)
・2003年4月 第14版 http://www.unicode.org/reports/tr14/tr14-14.html(Unicode 4.0.0)
・2004年3月 第15版 http://www.unicode.org/reports/tr14/tr14-15.html(Unicode 4.0.1)
・2005年8月 第17版 http://www.unicode.org/reports/tr14/tr14-17.html(Unicode 4.1.0)
そして昨日お話しました通り今年の8月に最新版として第19版(Unicode5.0.0)が出ています。
日本語では、一つ一つの文字を書く(表示、印刷する)毎に、横書きなら文字の幅、縦書きなら文字の高さ分だけ一文字づつ書き進めていき、一行の最後にきたら改行するのが、原理的な改行規則です。漢字やかななどの間ではどこでも改行できますが、例外として、行の先頭に来てはいけない、または、行の最後に来てはいけない禁則文字があります。
これに対して、英語は、単語の区切り、空白の位置で改行します。ドイツ語やフランス語なども基本は同じです。ただし、昨日述べましたようないくつかの例外があります。
実際に各言語を書いたり、表示したりする処理の際には、アルファベットやかな・漢字だけではなく、記号類、数字、さまざまな空白が混在しますので、ある文字の前後で改行することができるかどうか判断するのはかなり難しい場合があります。
UAX #14は、これを文字の改行特性と、いくつかの規則で統一的に判断しようということですので、多言語組版を行うためには、非常に重要な仕様のひとつです。
一方において、言語に関する知識なしに、UAX #14のような文字に関する規則だけから、その文字の位置で改行できるのかどうか、本当に正しい判断が可能なのだろうか?という疑問もわきますね。
ちなみに、XSL Formatterは、各言語の組版で(原則として)UAX #14に基づいて改行位置を決定しています。古いバージョン(V2の時)のことなのですが、米国の有力パートナーから、「お前のところのソフトは、米国人が絶対受け入れないような位置で改行している。それを直さないなら商談ストップする!」といって、えらく叱られました。
そこで、UAX#14の著者のAsmus Freytag氏に、「UAX#14がおかしいから、お客さんに叱られたので仕様を直して欲しい」とメールでクレームを投稿したことがあります。
他にも文句を言う人がいるためなのでしょうか、UAX#14は比較的頻繁に細かい点が変更になっているようです。UAX#14のような仕様を完璧につくるのは恐ろしく難しいと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月28日
Unicode Line Breaking Properties と禁則文字
日本語組版に精通している人ならば、日本語の行頭禁則文字や行末禁則文字についての知識はお持ちのことと思います。
行頭禁則文字や行末禁則文字という概念をもう少し広い概念でとらえたものに、「Unicode Line Breaking Properties」という規則があります。
最新版:Line Breaking Properties 19版
最新版は、2006年8月22日に出たもので、Unicode 5.0の一部となっています。
Unicode Line Breaking Propertiesという仕様は、文字の前後で改行できるかどうかという観点から文字をいくつかのグループに分けて改行についての挙動を示しているものです。
たとえば、英語の組版では、原則は、(1)単語間の空白で改行し、(2)必要に応じて単語をハイフネーションすることができるということです。しかし、この単純な原則だけでは必ずしも十分ではありません。たとえば、The Chicago Manual of Styleの15版には、単語の区切りという節があり次のような区切りは良くないとあります。
・7-40 名前の中の番号や、Jr.、Sr.の前できってはいけない。
例) Elizabeth II は改行するなら、Eliz- /abeth II とする。
・7-42 単位の数字と単位の略語の間では区切らない。
例) 345 m のような場合、数字と単位は行末で別れないように。
・7-43 行の中のリスト
行の中に(3)、(c)のような文中の箇条書き番号が出現したら、箇条書き番号と続く文字は同じ行にはいるようにする。
これは、空白があっても空白で改行してはならないケースですが、逆に空白でなくても記号類で改行できることもあります。Unicode Line Breaking Propertiesを見ますと、次のような分類があります。
B2 前後で改行できる 例:emダッシュ
BA 後ろで改行できる 例:空白、ハイフン
BB 前で改行できる 例:辞書の中の句読点
HY ハイフン 数字の中を除き、後ろで改行できる
CB 他の情報次第で改行できる
そして、逆に、改行を禁止する文字の種類として
CL 閉じ括弧 文字の前で改行することを禁止
EX 感嘆符(!) 同上
IN リーダのように対の間で改行できない
NS 非開始文字 例:小さな「かな」文字
OP 開き括弧 文字の後ろで改行することを禁止
QU 曖昧な引用符 開き括弧と閉じ括弧の両方の役割
などがあります。
さて、上の文字の属性のみで単純に判断すると、例えばUTF-16というような単語がUTF-と16で切れてしまったり、example(s)の開き括弧の前で改行が起きてしまいます。
Unicode Line Breaking Propertiesでは、このあたりをもう少し詳しくルールを決めているのですが、それはまた明日。
The Chicago Manual of Styleとは
シカゴ大学の出版部が出している米国の代表的な編集マニュアル。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月27日
Internet Explorer 7 の印刷機能
IE7の機能強化ポイントのひとつに印刷機能があります。以前から、ブラウザの弱点として印刷がなかなか思うようにならないということがありましたが、IE7では、この点がどのように改良されたのでしょうか?
IEブログにIE7 Printingというページがありますが、簡単に紹介してみましょう。
(1)デフォルト印刷
余分な空白をなくして、ぴったりとページにおさまるように。
・Webページの多くはそのままでは用紙をはみ出すことがあるので、用紙からページがはみ出さないように縮小してフィットさせる機能。
・オーファンの制御:Webページを印刷しようとしたとき、それが2ページにまたがり、2ページ目が最小の行しかないとき、自動的に縮小して1ページにおさめる機能。
この二つの機能は確かに、いつも、ブラウザの印刷で不便に感じたことで、大歓迎です。
(2)印刷プレビューのインターフェイスの変更
・印刷アクションのための制御をウインドウの右下に集め、ページ送りの制御キーを左下に、ページの調整のためのキーをウインドウの上に集めた。
・プレビューの最初の画面がフルページ表示になるようにして、スクロールを不要にした。これは、全幅表示(詳しく表示)モードに切り替えて、元に戻すことができる。
(3)印刷の制御
・用紙の横使い(ランドスケープ)と縦使い(ポートレート)の切り替えを簡単に
・ヘッダ/フッタのオンオフ
・最大12ページまでの多ページ表示
・印刷のスケール(縮小率)変更
・ページに縮小率を指定可能に
・マージンスライダ(マージンを対話的に変更)
(4)選択指定した内容をプレビュー
ブラウザの上で、範囲を指定して、右クリック・メニューを表示。そこで、印刷メニューを選択すると、印刷ダイヤログが表示される。その段階で、既に、選択領域を印刷が有効になり、選択した部分だけ印刷される。
(この機能、なぜか、私が使っても、そのようにならないのですが??)
(4)項はともかく、(1)から(3)までを見る範囲では、いままでのブラウザ印刷への不満が大幅に解消されそうです。
これもFireFoxが刺激を与えたおかげ。やはり競争は必要なようです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月26日
PDFを画像や音声のコンテナとして使う!?
今日の日経産業新聞にアドビのCEOブルース・チゼン(Bruce Chizen)氏のインタビューが掲載されています。この後ろの方に、次のような発言があります。
記者「文書画像関連ソフトだけでは成長に限界があるのでは。」
BC「...画像や音声など、様々な情報を包み込むコンテナのような役割を未来のPDFとフラッシュは果たすだろう」
アドビは、マクロメディアを買収して以来、フラッシュとPDFの統合を図っています。このことは、何回かこのブログでも触れています。
・Macromedia吸収後のアドビ、次のステップ
・PDFとFlashの統合?
この統合がどういう形になるか、最終的な形は見ていませんが、もし、PDFのフレームの中に音声や動画を埋め込むということであれば、それはかなり無理があるように感じます。
もう少し補足しますと;
PDFはページの概念をもつ紙を電子化したものです。もともと紙であった情報、または紙への印刷を目的としたものをPDF化するというのは適切なように思いますが、紙を前提としない情報をPDFに入れるのは不自然だと思います。
Acrobat Readerを使ってPDFをPCのWindowに表示して画面上で読む行為、Windowに入りきらない部分をスクロールしたり、ズームアップ・ズームダウンしながら読む行為は、どうも不自然ではないか、無理なところがあるのではないかと感じます。
それはなぜかと考えますと、PCのディスプレイは横長の大きさをもつのが普通ですが、紙は通常は縦長の大きさをもちます、紙に比例する領域の大きさをもつPDFを横長のディスプレイに表示する行為には無理、無駄があります。
最近のPDFにはタグ付きPDF、リフロー機能などの機能が追加されていて、Windowのサイズに合わせて表示することもできるようですが、しかし、PDFはもともと紙への印刷を前提として開発された技術の延長上にできたものです。従って、コンピュータのディスプレイや、その上のWindowにフィットさせることを目的とするとき、PDFファイルの内の情報の持ち方は不向きです。
一足飛びに結論を言いますと、まず、PDFとブラウザを融合した新しい情報の表示手段の必要性があるということ。そして、音声や動画などは、基本的にコンピュータ技術を前提としますので、紙よりもコンピュータのディスプレイに親和性が高いはずです。親和性の低い紙=PDFに音声や動画を統合する、というのは技術として筋が悪いのではないか、と思うのです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月25日
サーバベース・コンバータ V1.3をリリース
サーバベース・コンバータ(SBC)が、このほど、V1.3となりました。V1.3では次の機能を強化しています。
(1) .NET Framework2.0 に対応するインターフェイスを追加
(2) MS Word, MS PowerPoint から PDF への変換でハイパーリンクの埋め込みに対応
(3) MS Word から PDF への変換で見出しマップをしおりに出力するようにした
(4) MS Word の変換精度を改善
(5) 変換元に テキストファイル を追加
(6) Excelからの変換で末尾の空白ページを変換しないようにした
(7) (Pro版のみ)変換元にジャストシステムの一太郎文書を追加しました
SBCは、Windows, Linux, Solaris のサーバOS上で、様々な文書フォーマットをPDF、SVG、ラスタ画像(Windowsのみ)に変換することができます。Microsoft Officeや一太郎と互換のページ組版エンジンを持っていますので、サーバ上ではMicrosoft Officeやその他のSBC以外のアプリケーションは必要とせずに、Microsoft Officeや一太郎の文書をページアップしてPDFを作成することができます。
SBCには、Standard版とPro版があります。この2種類の違いは、入力できるファイル形式の違いです。
入力できるファイル形式は、次のようなものです。
(1) Adobe PDF 1.0 - 1.6
(2) MS Word 97 - 2003のDoc文書
(3) MS Word 2003 WordProcessingML文書
(4) MS Excel 97 - 2003
(5) MS PowerPoint 97 - 2003
(6) テキストファイル
以下の入力ファイル形式はPro版のみサポートです。
(7) ジャストシステム 一太郎8 - 2006
(8) SVG 1.1 / Basic / Tiny
(9) Enhanced Meta File
(10) Windows Meta File
(11) Windows Bit Map
(12) Portable Network Graphics (PNG)
(13) Graphics Interchange Format (GIF)
(14) Tagged Image File Format (TIFF)
(15) JPEG File Interchange Format (JFIF)
(16) Joint Photographic Experts Group 2000 (JPEG 2000)
現在のバージョンでも、まだ、Microsoft Officeや一太郎の文書とは完全互換とは言えませんが、Officeのページ再現性はだいぶ向上しています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月24日
Internet Explorer 7 (英語版)正式リリース
10月18日にInternet Explorer 7 が正式リリースしました。正式リリースは英語版のみで、日本語を含むその他の言語は、まだ、リリース候補(RC)版のままです。
Internet Explorer 7 for Windows XP Available Now
早速、インストールして使ってみました。まず、ブログを書いてみたのですが、いつもと違ってなれないのでやりにくいですね。
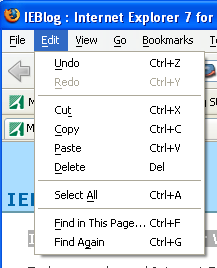
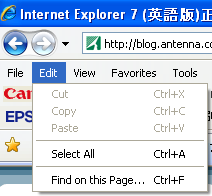
なぜやりにくいのかな、と見て気が付いたのですが、編集メニューがちょっと違います。
FireFox(左)の編集メニューはUndoがありますが、IE7(右)の編集メニューはUndoがありません。
Ctrl+Zを覚えれば良いとは言え、いつものメニューがないと、まごつきます。
| 
|
IE7は、ビルゲーツが、IE7を出す、と約束してから20ヶ月(2年弱)を費やし、5回のβ版と1回のリリース候補版を出したそうです。
XHTMLだけと比べて、HTMLで書いたWebには文法的にいろんなページがありますから、大変なんでしょうね。お疲れ様です。
IE7での改良点については、いままでもニュースにいろいろ取り上げられているようですが、次のようなことがあります。
・フィッシング・フィルターの強化
・Quickタブをもつタブブラウザ機能
・印刷機能の強化:縮小してフィットさせる。一行だけのページができないようにする。
・カスタマイズしやすい検索機能
・CSSサポートの強化
など。
私としては、いろいろ試してみたいのは印刷機能の強化の点です。FireFoxの印刷機能はかなりひどい状態なので。印刷が綺麗にできるなら、この際、再びIE7に移行しようかな。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月23日
アドビSVG Viewer、2008年1月でサポート終了
アドビがSVG Viewer のサポート終了をアナウンスしたという噂は聞いていたのですが、先日、公式にアナウンスしているという話を聞きました。
そこで、アドビのWebページを調べてみましたら、SVGホームページの日本語版では掲載されていませんが、英語版では、2008年1月でサポート終了とアナウンスしています。専門家の間では周知のことらしいですので、いまさらといわれるかも知れませんが、知らない人もいると思いますし、紹介してみます。
日本語版SVGViewerページ
英語版SVGViewerページ
Adobe to Discontinue Adobe SVG Viewer(アドビは、Adobe SVG Viewerを終了する)
SVG Viewerのサポートをやめる理由は、SVGが既に幅広く普及して、WebブラウザなどがSVGをサポートしているからだそうです。これはちょっと信じられませんけどねー。
計画では、2008年1月1日をもってサポートを終了し、2009年1月1日をもってダウンロード・サイトからAdobe SVG Viewerを除去するとのことです。今後、セキュリティ・パッチの提供はありません。また、Adobe SVG ViewerはWindows Vistaでの動作は保障されません。
この他詳しいことは、FAQページ(PDF)をご覧ください。
※この話題はもう1ヶ月以上古いようです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月22日
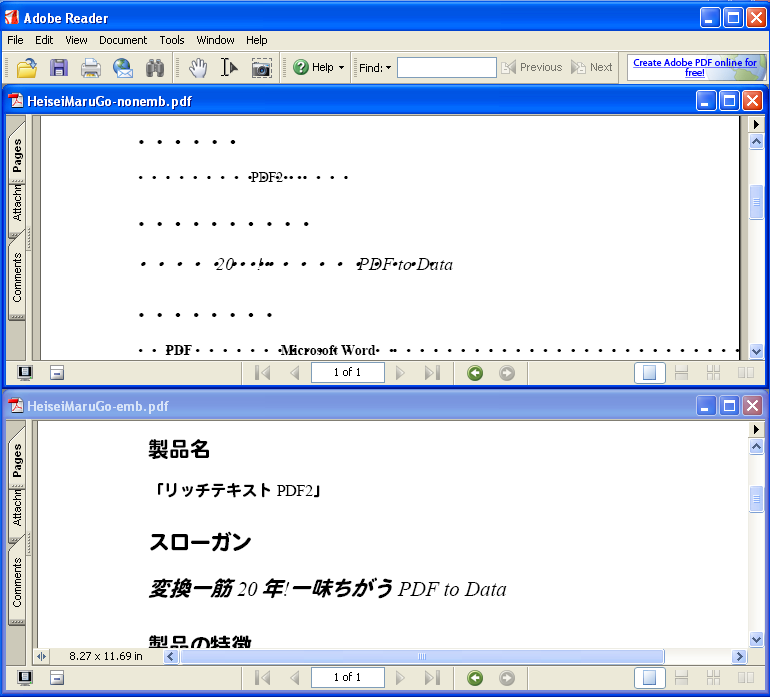
『リッチテキストPDF2 D&D』を発売
アンテナハウスは、10月20日より 『リッチテキストPDF2 D&D』を株式会社ベクターより販売開始しました。
この製品は、 PDFからMicrosoft Word、一太郎、テキストファイルへの変換を行うものです。弊社の『リッチテキストPDF2』の変換機能の一部を取り出して、ドラッグ&ドロップのみの簡単操作で使用できる変換ツールとして独立化し、1,980円(税込み)で販売するものです。
ソフトウェアのオンライン販売サイトである、ベクターのサイトからダウンロードにより販売を開始しました。今後、他のダウンロード・サイト、あるいはパッケージの形態などで、販売を強化していく予定です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月21日
W3C Print Symposium 2006 (4) XSL-WG
19日は終日、XSL-FOのサブ・ワーキングの会議がありました。この会議の内容は機密事項になっていますので、詳しいことを紹介できないのが、残念です。
日本からかなりのボリュームの提案資料を持参したのですが、18日の会議(XSL-FO 2.0へのリクエスト聴取)では配布を禁止されてしまい、その上、勝手に発言しては困ると口も封じられ、何度もシャロン女史と折衝して、漸くのことで「CSSとXSL-FOの互換性を達成すべき」という要求項目を一行だけ入れてよいと言われたのです。その代わり(??)19日は会議の時間のほとんどを割いて、われわれが用意した提案を聞いてもらえました。そんなわけで一緒に行ったM氏(私は前座で、技術的なところは、ほとんどM氏が説明)は18日は発言する機会を与えられず、しょげかえっていました。しかし、19日は丸1日ほとんど独り舞台で、5ページのサマリと21ページのレポートを全部説明せよ、という時間をもらいました。M氏は終わってから大満足の様子。ビールをおいしそうに飲んでいました。

どうも、私達の提案を18日の会議で取り上げると会議の予定が全部ぶち壊しになりかねないことを恐れたようです。
しかし、現在、XSL FormatterはXSL-FOの実装ではもっとも重要な存在です。私達が、今後は協力しないといえば、XSL-FOの仕様拡張も成り立たないことになりかねない、ということになります。標準仕様を実装するベンダがいなければ、標準仕様を作成する意味がなくなってしまいますから、両者の相互依存関係は非常に大きい訳です。
XSL-FOのワーキングの人達が口を揃えて言っているのは、第一に、最初のころCSSがルーズであったためにXSL-FOとして厳密な方法を取り入れなければならなかったこと、第二に、CSSはブラウザ向けで、テクニカル・ドキュメンテーションのために必要な機能をもっていなかったことです。
このために、XSL-FOはDSSSLに由来するエリアモデルを導入していて、CSSのボックスモデルとXSL-FOのエリアモデルは異なるものであり、CSSとXSL-FOを完全に互換にすることはできないということです。
また、XSL-FOとしてCSSと互換性を保とうとしても、CSS(2.1、3)はまだ勧告になっていないので、動くターゲットになってしまう。このため現時点ではXSL-FO側からCSSを採用することができない。一方において、CSS側がCSS3でXSL-FOの仕様と類似の機能を互換でないが、しかし、類似の方法で追加しているため混乱のもとになっています。
Webの議論では、Hakon Wium Lee氏がXSL-FOを攻撃しているのですが、実際に話してみますと、LeeさんはXSL-FOについてあまり知らないようで、CSSとXSL-FOの互換性については協力しても良いとおっしゃっていました。これに対して、シャロンさんが強硬反対ということでWebやメーリングリストを読んで予想した筋書きとはだいぶちがっていました。
さて、これをどういう方向にもっていくべきか?今後、考えねばならない課題です。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月20日
W3C Print Symposium 2006 (3) XSL-FOとCSSの互換性
アンテナハウスは、XSL Formatterを海外でかなり販売しています。その経験だけで一般論を引き出すのは危険かもしれません。しかし、経験的に、W3C の勧告は、日本ではそれほど大きな影響力がないように思いますが、海外ではかなり大きな影響力があることを感じます。そんなこともあり、 XSL-FOとCSSの互換性についてもう少し考えたいと思います。
Webの印刷に関する標準仕様で、CSSとXSL-FOという二つの仕様があると言いました。もともとCSSは、印刷よりもWebページのコンテンツとレイアウト指定を分離することで、メンテナンスし易くしたり、アクセスし易くする、という趣旨で作られたと思います。XSL-FOはページ概念のあるメディアへの組版・印刷用と言う点で、当初は重複するという印象はありませんでした。
ところが、近年、CSSでページ概念をもつメディア(紙やPDF)に印刷し、CSSで本を作るなどを狙ってきたためにCSSとXSL-FOの境界が分かりにくく、両者が重複する部分が多くなりつつあります。
XSL-FOは、非常に高度な組版機能を持っていますので、組版機能の強力さで見れば、XSL-FOとCSSは比べものにならない、まあ、高級乗用車と軽乗用車以上の差があると思います。
ところが、実際のユーザの多くは、実はXSL-FOのそんなに高度な機能を使っている訳ではない様です。XSL-FOはドキュメントの自動組版という用途ですが、その分野で、高度な機能を必要とするXMLコンテンツを扱うユーザ層は限られます。実際のところ、Webページ的な内容を組版する用途でXSL-FOを使っている人が多いということになりますと、CSSで印刷機能が強化されれば、XSL-FOの市場と重複してきます。
その結果、CSSとXSL-FOのツールの競合が増え、競争は厳しくなるかもしれませんが、それはベンダにとっては、競争に勝つために努力するということですから、大きな問題ではありません。むしろ切磋琢磨することで、市場が大きくなり、ツールも良いものになるだろうと思います。
その結果、ユーザにとってはCSSとXSL-FOのツールを両方を使ったり、あるいは、一方から他方へ移行したいということになるケースが増えるでしょう。そういうとき、両方のツールに類似の機能があるが互換ではない、というケースがあるとユーザが不利益をこうむるということになります。まったく別の標準機関が提唱する仕様ならいざしらず、同じW3Cの提唱する仕様でそのような混乱が起きるのは好ましくない、ということになります。
結果的に、W3Cの仕様のステータスも下がってしまいます。ところが、CSSとXSL-FOの互換性は、総論ではともかく、各論になるとなかなか実現できないのですね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月19日
W3C Print Symposium 2006 (2)
ドイツのハイデルベルグで行われているW3C Printシンポジウム2006の会場は、Print Media Academyという建物ですが、印刷機械メーカのHidelBerg社のセミナー施設のようです。ハイデルベルグ市って、HidelBerg社の城下町なんですね。
さて、参加登録者の人数は70名強で私の予想より少ない人数です。日本からもジャストシステム2名、アンテナハウス2名、印刷技術協会、キヤノン、W3Cから各1名とだいぶ大勢の参加者がありました。日本からの参加者は、18日のワークショップで、W3Cの印刷仕様を国際標準としてしっかり作ってもらおうということが目的です。また、米国勢ではHPやIBMの参加者も多く見られますが、マイクロソフトの参加者が一人もいないというところにマイクロソフトの冷淡な姿勢が感じられます。
マイクロソフトは標準仕様には冷淡で、自分達の独自仕様を推進するのに熱心なようです。シャロン・アドラーさんは、一社だけの仕様とオープンな標準仕様とでは、意味が違うとおっしゃっていましたが、ユーザの人たちは、マイクロソフトの仕様と、W3Cの標準仕様にどの程度の意味の違いをおいているのでしょうか?
結局は、プログラムをどの程度優れた実装をするかが決め手になるように思います。
ドイツでの会議ですので、ドイツの参加者が多いのは当然ですが、XSL Formatterのリセラーである、Doctronics社がスポンサーであり、他にも当社リセラーの関係者が参加していたことで、日頃めったに会うことのできない海外取引先の方と挨拶を交わすことができたのも良い機会です。
セミナーの合間に話して見ました人の中では、CSSのHakon Wium Leeさんが熱心という印象を受けました。
また、XSL-FO V1.1の概要説明も良くまとまっていたように思います。
会場の参加者からW3Cに印刷関係の仕様が沢山あって、分かりにくいという声も聞こえました。これに対しては、それぞれ、特徴があって、異なる市場・用途を狙っているという説明がありましたが、確かに、HTMLPrintは家庭向けの普及型プリンタでデジタルカメラ、携帯電話、PDAなどを含む様々な端末から写真などを印刷する用途を想定していますので、CSSやXSL-FOとはだいぶ違います。
一方、CSSとXSL-FOのように、一部の客層に対してオーバラップする仕様もあります。W3Cでは、重複する部分は互換性の維持、重複する仕様はグループ化して互換性を保つような管理をしていくべきだろうと思います。
アンテナハウスでは、そのようなことを考えてXSL-FOとCSSの互換性を高めて欲しいということを提案しようと考えていたのですが、Chairのシャロンさんが、XSL-FOとCSSの互換性を実現するのは絶対無理と強硬な意見をもっているために今日のところは、話をする時間があまり与えられませんでした。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月18日
W3C Print Symposium 2006 (1)
10月17日にドイツのハイデルベルグにおいて、W3C Print Symposium 2006が開かれました。
17日は、W3Cにおいて進められている次の4つの印刷関係の仕様についての概要の説明がありました。
・CSS Paged Media
・XHTML Print
・SVG Print
・XSL 1.1
また、今日、18日は、XSL-FO 2.0についての検討を行うワークショップが開かれる予定です。
ハイデルベルグから、このシンポジウムの状況について簡単に報告してみたいと思います。
まず、4種類の印刷関連の仕様の最新版は次のような状況です。
■CSS Paged Media
CSS3 Module: Paged Media
W3C Working Draft 10 October 2006
CSSレベル3の一部で、ページ分割、マージン、用紙サイズ・方向、ヘッダ、フッタ、ウィドウ・オーファン、イメージの方向、ページ番号などを定義する仕様です。2006年10月10日に最終ドラフトになりました。
■XHTML Print
XHTML-Print
W3C Recommendation 20 September 2006
モバイル機器や低価格機器用でプリンタ専用のドライバが無くても、HTML-Printに準拠したページ記述をすれば、印刷したり、表示したりできることが狙いです。9月26日に勧告になりました。
CSS Print Profile
W3C Working Draft 13 October 2006
CSSのサブセット。HTML-Printと一緒に使用して、ページレイアウトをより強化するための仕様です。2006年10月13日に最終ドラフトになりました。
■SVG Print
SVG Print
W3C Working Draft 15 July 2003
これは仕様書ではなく、Web用のグラフィックスの標準仕様SVG1.2を印刷に使うためのガイドラインです。
■XSL-FO
Extensible Stylesheet Language (XSL) Version 1.1
W3C Proposed Recommendation 06 October 2006
これは既に詳しくお伝えしていますが、つい10日ほど前に、勧告提案になったばかりです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月17日
Google Docs/Spreadsheetsを初体験(4) — Kochi-Mincho
2006年10月14日 Google Docs/Spreadsheetsを初体験(1)で、Google Docsで作成したPDFで使われているフォントが「Kochi-Mincho」になっていることに気がつきました。Googleのサーバで作成したPDFの日本語フォントには、Kochi-Minchoが埋め込まれています。
私の記憶では、Kochi-Minchoは日本語フォント名「東風フォント」と言い、確か権利侵害の問題で公開停止になっていたものではなかったかな?
その後、この問題はどうなったのでしょうか。少し気になりましたので、Webでざっと調べて、状況を整理しておきます。
■この経緯についての情報リストはここにあります。
StolenBitmap
緊急作成 --- 32 ドットビットマップフォントの無断複製について
これに基づいて、私なりに整理しますと。。
■渡邊フォント(ビットマップ)
まず、32 ドットビットマップフォントの無断複製についてによると、「渡邊フォント」と呼ばれる様々なサイズのビットマップフォントがあった。これは、1990年代初頭に、広く流通していたフリーのビットマップ・フォントを元にJaWaTeX の開発者である(当時)東北大学の渡邊雅俊さんが作成したフォント集。
ところが、2003 年 6 月 15 日に、当該ビットマップ・フォントは、日立とタイプバンクが制作してROMとして販売したフォントが無断で複製配布されていたものであることが判明。
■東風明朝フォント(TrueType版) Kochi-Mincho
慶応大学の古川泰之さんが、渡邊フォント(ビットマップ)を元にアウトライン化したもの。
元になった、ビットマップフォントの問題が発覚したため、2003年10月21日に古川泰之さんは制作活動終了宣言をしています。
東風フォント制作活動終了のおしらせ (2003年10月21日)
■その後
東風フォントその後
東風フォントその後 7~9
東風フォントその後 10~11
東風フォント問題が解決の方向へ無償利用も可能に
などを読みますと、話合いの結果、日立やタイプバンクとライセンス契約を結べば「東風フォント」などの派生フォントを(一定の条件で)開発、配布、利用できることになったようです。しかし、この過程で古川さんは「東風フォント」の開発・配布をやめ、内田明さんという方は、契約を結んで「XANO明朝フォント」を開発することにしたのだそうです。
XANO明朝フォントについて
つまり、開発者である古川さんは「東風フォント」の開発契約を結ばず、終結宣言をしたことから考えて、他の人が東風フォントを配布したり、利用するのは、正当な契約に基づかない行為になるのではないかと思います。契約に基づかない行為、すなわち無断使用が、直ちに不正であるとか、あるいは、損害賠償等の問題に発展するかは私にはわかりません。そういうことを判断する立場でもないですが。
しかし、Googleほどの企業であれば、有償フォントを購入して使えば良いのにね、と思うのは私だけでしょうか?
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月16日
Google Docs/Spreadsheetsを初体験(3)
Google Docs、まだ、生まれたての子供といったところですが、従来のワープロと違っているのは、やはりWeb上で使うという点。具体的には、Publish機能、Collaborate機能の二つでしょう。
Publish機能というのは、名前どおり作成した文書をそのままWebで公開する機能です。従来のワープロでも作成した文書をHTMLに変換して、Webに公開することはできましたが、Google Docsは、ボタンひとつで文書の公開ができるということで、従来とは、比べものにならない手軽さで文書の公開ができそうです。
試しにGoogle Docsで作成して、Publishした文書をおきます。
http://docs.google.com/View?docid=dxspw42_39r7cw8s
この文書はMicrosoft Wordで作成したものです。
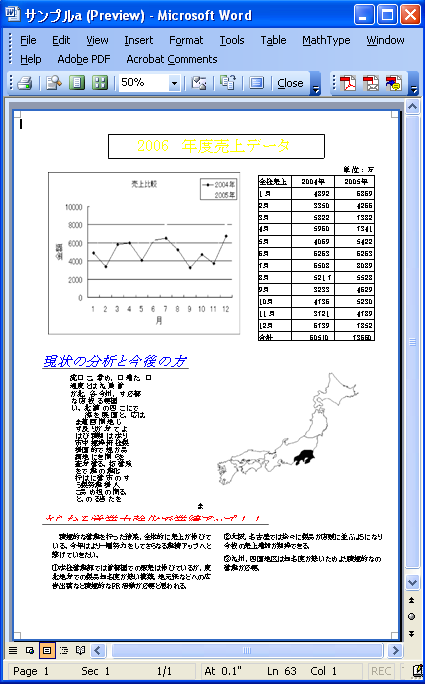
■元の文書の印刷イメージ

■この文書をGoogle Docsにアップロードしたところ
■Publish
Publishと言いますと、大層な機能と思うかもしれませんが、要するにHTMLに変換してWebサーバの上に置くということです。ただ、こういう機能は、インターネット上で一般に公開するのよりも、社内用のグループウエアの掲示板などの方が用途が多いのではないでしょうか。インターネットにHTMLをパブリッシュできたとしても、それだけではたいして役に立たないように思います。
ちなみに同じ文書をPDFで保存変換しますと次のようになります。
■PDFに変換した結果
HTML変換に比べて、PDF変換では、レイアウトがかなり崩れてしまいます。PDFで保存はもう少し気合を入れて改良しないと使い物になりませんね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月15日
Google Docs/Spreadsheetsを初体験(2)
さて、次にGoogle Docs/Spreadsheetsのもうひとつの核、表計算を体験してみましょう。
新しい表計算のメニューを選択しますと、ブラウザが新たに起動して、空白のシートができます。
メニューはワープロと似ていますが、やはり表計算独自の機能として行や列を挿入したり、削除するメニューがあります。
簡単な表を作ってみました。
■Google Spreadsheetsで作成した表
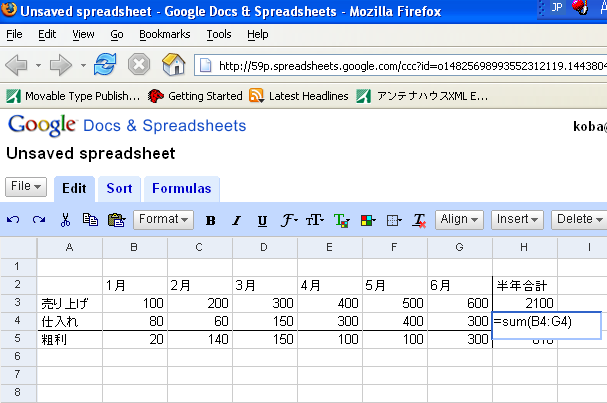
データの入力は、やはり、通常のデスクトップの表計算よりはレスポンスが悪いようです。また、入力したデータ(記号類)によって、インターネットの接続が切れたようになりデータが消えたりします。まだ、不安定な状態のようです。
ファイルメニューを見てみます。Google Docsとは違って、Exportの先にPDF形式があります。昨日のDocsでは、SaveAsの形式のひとつとしてPDFがありました。DocsとSpreadsheetsでメニューの整合性が取れていません。
■ファイルメニュー
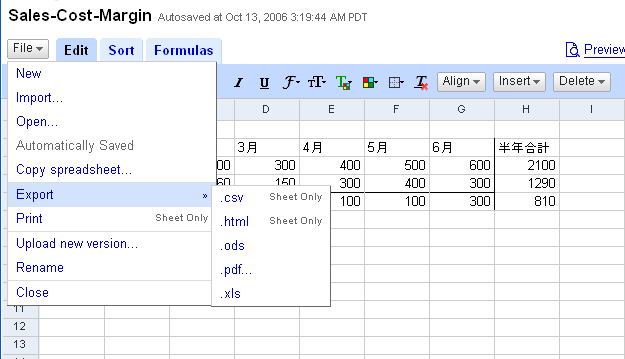
■PDFへのエクスポート・ダイヤログ
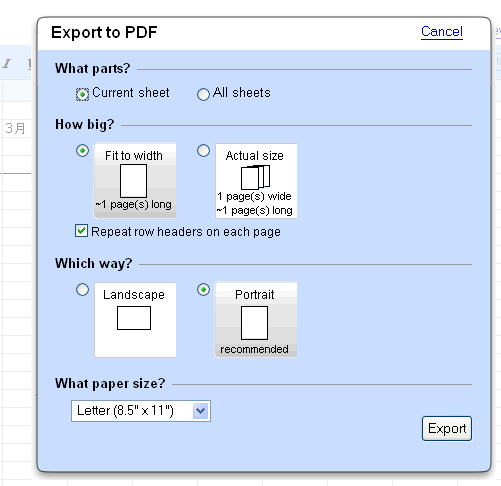
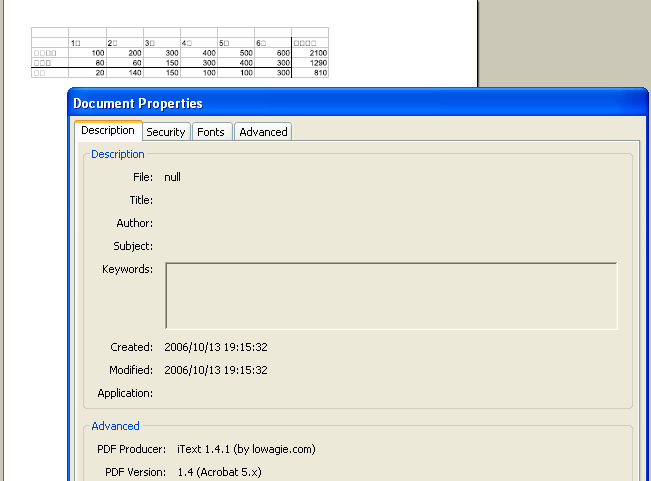
PDFで保存してみました。このPDF作成のプロパティを見ますと、今度は、iTextになってますね。
■PDFの作成者プロパティ
OpenOffice.orgには、表計算もありますが、使っていないのはなぜなんでしょうか?
ワープロ文書はOpenOffice.orgでPDFを作成、表計算はiTextで独自にPDF作成機能を作った、というところは、やや荒削りな感じを受けます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月14日
Google Docs/Spreadsheetsを初体験(1)
Googleが、11日にWebで使えるワープロと表計算GoogleDocs&Spreadsheetsを発表しました。そこで、早速、体験してみました。
GoogleDocs&Spreadsheetsのホームページ
■画面
この画面からワープロ文書の作成(New Document)、表計算の作成(New Spreadsheet)ができます。また、自分のローカルのハードディスクから文書を読み込む(Upload)することもできます。
■ローカルの文書を読み込む画面
これを見ますと、HTML、Word文書(Doc)など基本的な文書を読み込めるようです。ただし、500KBが読み込みできる大きさの限界になっていますので、あまり大きな文書は無理なようです。そこで、簡単な文書を読み込んで見ました。そうしますと、日本語の文書も比較的すなおに表示します。しかし、通常のワープロと違って、紙のようなページの概念はないように見えます。次のふたつの画面を比較しますと、そのことが分かります。
■編集用のウインドウ幅を広げた状態
■編集用のウインドウ幅を狭めた状態
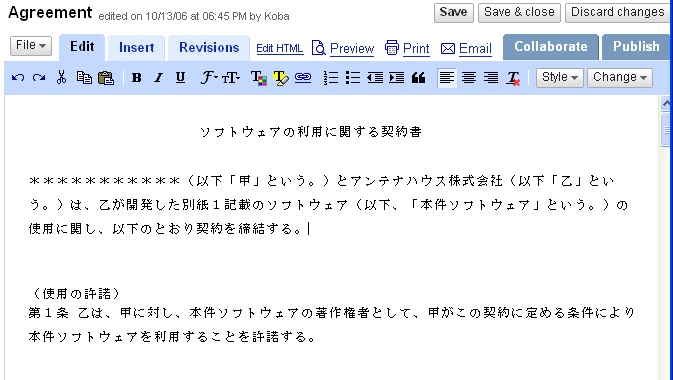
ウインドウの幅の広さが変わると文章の改行位置が変わりますね。これはブラウザと同じように可変幅のディスプレイで使いやすくするためではないかと思います。ページレイアウトをWYSIWYGで表現することは意図していないということになります。
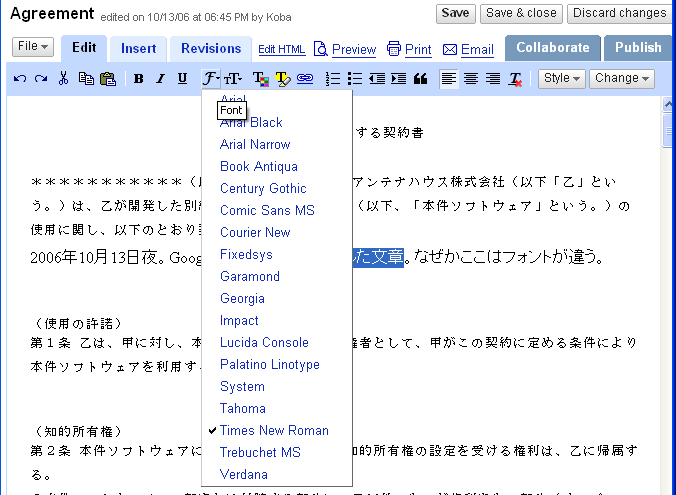
日本語の文字も編集ウインドウで直接入力できますが、フォントはどうやって指定するのでしょうか?試しに、日本語の文字列を選んで、フォントのメニューを開いても、次のようにTimesNewRomanという欧文フォントにチェックマークがついています。どうやら日本語フォントを指定するのは無理なのかな?
■日本語文字列を選んでフォントメニューを開く
普通のワープロと同じように、ファイルメニューもあります。
■ファイルメニュー
おお!PDF形式で保存なんてメニューがありますよ!そこで早速、PDFで保存してみました。
■出来上がったPDFのページ

改行位置が画面の表示と少し違います。将来、こういうワープロが普及してくると、改行位置なんてあまり気にしなくなるのでしょうか?そうなると「日本語行組版規則」なんてJISは化石な存在になるのかな?
このPDFのプロパティを見ますと、PDFの作成者は、OpenOffice.orgになってます。PDF出力はサーバサイドでOpenOffice.orgを使っているんでしょうね。
■PDFのプロパティ
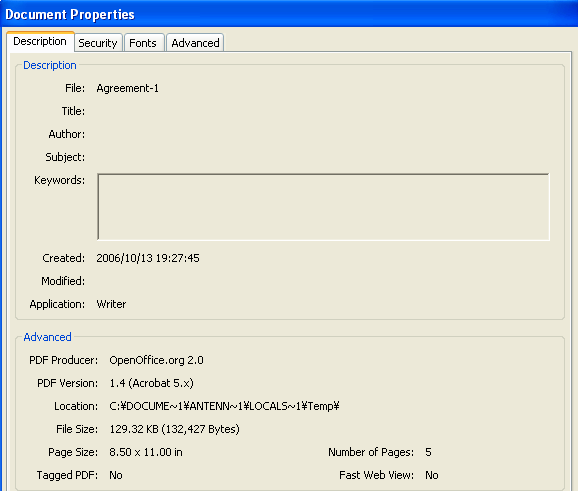
■PDFのプロパティ(フォント)
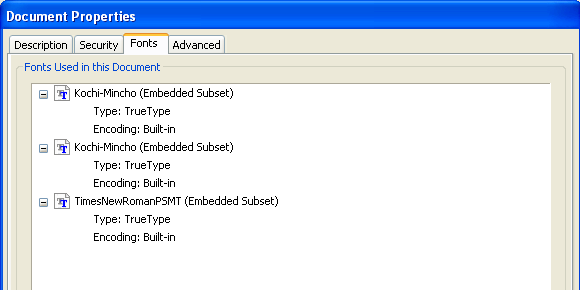
普段使ったことのないフォントをいろいろ使ってますね。
ちなみに、このKochiMinchoという名前のフォントは、私のローカルのPC上のWindowsのFontsフォルダにはありません。従って、このフォントはGoogleのサーバ上にあるフォントということになります。
ワープロ編集画面上では、恐らくローカルのフォントで表示していると思います。そうしますと、必然的にWYSIWYGにはできないことになります。
ともあれ、Google Docsは、言ってみれば生まれたばかりの幼児ですが、将来どうなるか?夢が膨らみますね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月13日
PDFからWordへ 3つの変換ソフトを無慈悲に比較する (4)
さて、PDFからワープロ文書への変換について、実際にどの程度変換できるのか、もう少し違ったサンプルを取り上げて、そのもう少し比較検討してみたいと思います。
最初に、少し入り組んだPDFを取り上げて変換結果がどうなるかを見てみましょう。
○オリジナルは、画像、表、縦書き、横書きの文章が入り組んだPDFです。
オリジナルPDFをダウンロード (PDF)
○これを「リッチテキストPDF2」でWord文書に変換しました。
変換結果をWordで開いて、印刷プレビューしました。
変換後のWord文書をダウンロード
図、表、見出し、縦書き、横書き(2段組)ともほぼ完全に変換できていることがお分かりいただけると思います。
ひとつ、問題を挙げるとしますと、次の図のように縦書きの段落で一行毎にテキストボックスを作ってしまっているということでしょう。

これは早期に改善して欲しい点です。
ちなみに、この同じPDFを他社の製品でWordに変換しますと次のようになります。
○「いきなりPDF to Data 2」で変換
変換結果をWordで開いて、印刷プレビューした画面
変換後のWord文書をダウンロード
○「速攻!PDF to Data」で変換
変換結果をWordで開いて、印刷プレビューした画面
変換後のWord文書をダウンロード
どうもOCRを使う方式は、変換設定の仕方にもよるのかも知れませんが、カラーがあるとなんとなく認識精度が落ちるような印象を受けますが如何でしょうか。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月12日
Office Open XML File Format(OOX)最終ドラフト公開
Microsoft Office2007のXML形式である、Office Open XML File Formatの最終ドラフトが公開されました。
Ecma Office Open XML File Formats Standard
仕様は5部から構成されています。
第一部:基礎 173ページ
第二部:パッケージ化の約束事 129ページ
第三部:最初に 472ページ
第四部:マークアップ言語のリファレンス 5129ページ
第五部:マークアップの互換性と拡張性 43ページ
下記のEcmaのPRページによれば、
Ecma Office Open XML File Formats Standard - Status Report - 28 September 2006 - Trondheim, Norway
この最終ドラフトは、Ecmaの作業委員会TC45のメンバの間で9月下旬に開催された会議で全員一致の賛成で決定されました。
そして、12月に開かれるEcmaの全体の会議で正式な仕様として採用するかどうかの投票が行われるようです。
それにしても、この仕様書PDF形式で5900ページ超えて、自動車の整備マニュアル並みの厚さです。読むだけで大変。実装することを考えたら冷や汗がでます。
XSL-FOの仕様書なんて500ページ程度。それでもXSL Formatterの開発には7年もかかったのに。
当社としては、サーバベース・コンバータ(SBC)でOOXを組版しなけりゃならないんです。6000ページの仕様書なんて。SBCは完成するまで一体何年かかることやら。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月11日
フォントを埋め込まないPDFの表示(6)
さて、昨日は、CJKコンポーネント(「alf_jpn.exe」)をインストールすることで日本語フォントを埋め込まないPDFも、表示できるようになることを説明しました。
では、どのような仕組みでこれが可能になっているのでしょうか?
そこで、CJKコンポーネントをインストールすると、追加されるものと調べてみますと、次の3つのようです。
・Program Files\Adobe\Acrobat 7.0\Readerフォルダの
agldt28l_cjk.dllファイル (約1MB)
・Program Files\Adobe\Acrobat 7.0\ResourceフォルダにCIDFontというフォルダができ、中に次のフォントがインストールされます。
KozGoPro-Medium.otf (約3MB)
KozMinProVI-Regular.otf (約6MB)
・Program Files\Adobe\Acrobat 7.0\Resource\CMapフォルダは、インストール前は、Identity-HとIdentity-Vだけでしたが、CJKフォントをインストールしますと、Adobe-Japan1-H-CID以下、94個のCMapテーブルが追加になります。
この中で、agldt28l_cjk.dllファイルの役割は分かりません(このファイルを削除しても、日本語フォントは表示できます)。
また、日本語フォントファイルとして、MS明朝や、平成丸ゴシックが追加されるわけではありませんので、CJKコンポーネントをインストールすることによって表示されるフォントはWindowsのシステムに、あらかじめ存在していたものなのでしょう。
恐らく、日本語フォントを指定した文字がフォントを埋め込まないと表示できない理由のひとつは、CMapテーブルがなかったためだろうと思います。ですがそれだけではありません。CMapテーブルを残しておいて、KozGoPro-Medium.otf、KozMinProVI-Regular.otfを削除してしまうと、再び、フォントを埋め込んでない日本語の文字が表示できなくなってしまいます。
なぜ、KozGoPro-Medium.otf、KozMinProVI-Regular.otfを削除してしまうと、MS明朝や平成丸ゴシックが表示できなくなるのでしょうか?関係なさそうに思えるのですが、これは謎ですね。
それから、英語について、フォントを埋め込まないとArabicTypesettingが正しく表示できないというのは、CJKコンポーネントをインストールしても変化ありません。次の図をご覧ください。上はWordでArabicTypesettingを指定したラテンアルファベット文字、下はフォントを埋め込まずに作成したPDFをAdobe Readerで表示したもの。
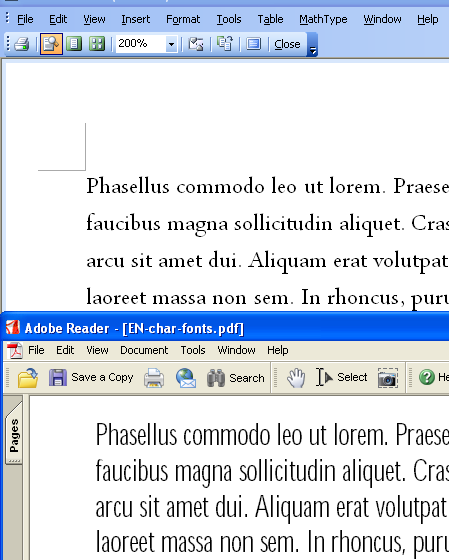
フォントを埋め込まないで作成したPDFについて、Adobe Readerの表示方法にはいろいろと謎がありますが、少なくともWindowsのシステムにあるフォントを素直に使っていないのは確かなようです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月10日
フォントを埋め込まないPDFの表示(5)
Adobe Reader英語版では、フォントを埋め込んでいない日本語・中国語の文字を正しく表示できないことについては、2006年09月14日
フォントを埋め込まないPDFの表示(3)、2006年09月25日フォントを埋め込まないPDFの表示(4)で説明しました。
これについて、もう少し続けて検討してみたいと思います。
まず、日本語について、いままでMS明朝とMSゴシックだけで検討してきましたので、他のフォントでも同じことが起きるかを確認してみます。そのひとつの例として、「平成丸ゴシック」で試してみました。
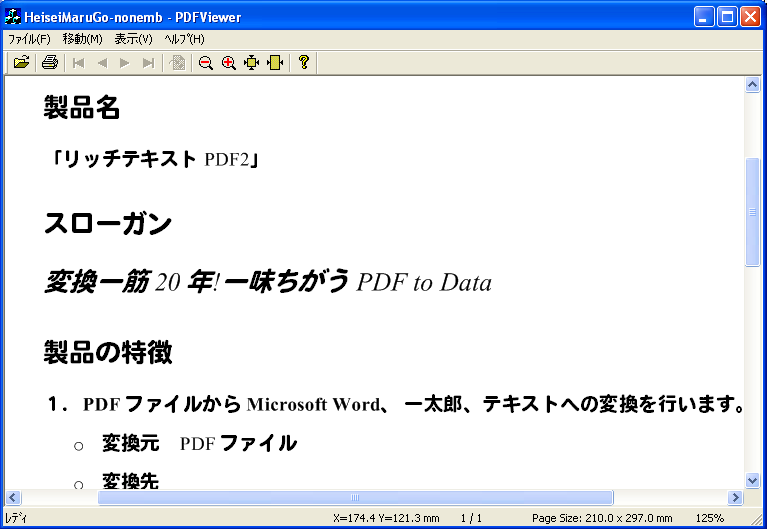
上の図は、「平成丸ゴシック」を指定した日本語文字を含む文書をPDFにして、Adobe Reader英語版で表示したものです。上がフォントを埋め込まない場合、下がフォントを埋め込んだ場合です。「平成丸ゴシック」も「MS明朝」「MSゴシック」と同じ結果になっていることが分かります。
Windowsにはこのフォント(平成丸ゴシック)がインストールされていますので、Windowsのシステムフォントを使うと、フォントが埋め込まれていなくても文字を表示できます。ちなみに、アンテナハウスのPDF Viewer SDKではフォントが埋め込まれていなくても「平成丸ゴシック」を指定した文字が表示されます。
さて、アドビのホームページのサポートデータベースには、日中韓フォントが埋め込まれていない PDF の表示方法(文書番号223007)という文書があり、Adobe Reader 6.0/7.0 で、日中韓フォントが埋め込まれていない PDF ファイルを正常に表示するには必要なコンポーネントをダウンロードするようにという説明があります。
このコンポーネントは、「alf_jpn.exe」というプログラムです。これをダウンロードしてインストールしますと、確かに、「平成丸ゴシック」フォントを埋め込んでいないPDFも正しく表示できます。次の図のように確かに、平成丸ゴシックStd-W8フォントで表示しています。
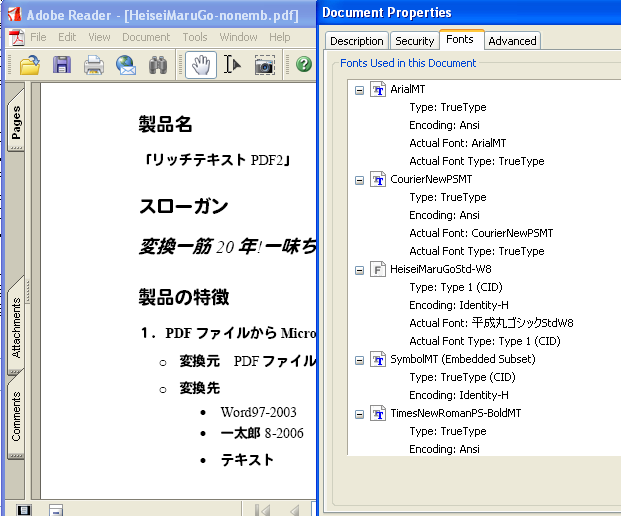
これで、一件落着か?と言いますと、実はそうじゃなく、ますます疑問が深まってしまうのです。次のような疑問です。
・今まで、「平成丸ゴシック」フォントを指定した文字が表示できなかったのに、alf_jpn.exeをインストールすると、なぜ、表示できるようになったのか?
・AdobeReaderが表示に使っている「平成丸ゴシック」フォントは、Windowsのシステムのフォントなのか?それとも、追加でインストールしたalf_jpn.exeに入っていたのだろうか?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月09日
XSL-FOの勧告提案までの経過
ここで、XSL-FOがV1.0からV1.1までの経過について、振り返ってまとめてみたいと思います。
・2001年10月 XSL-FO V1.0の勧告
・2002年4月頃からXSL-FO V1.0のErrataの作成作業開始。
ユーザ等からのコメントへの対処作業
テストケースの改訂
・2002年10月25日 XSL-FO V1.0についてErrataの発行
Extensible Stylesheet Language (XSL) Version 1.0 Errata
(その後、随時更新)
・2002年秋までに作業グループ内で時期バージョンでは2.0を狙わずに、各社の拡張の標準化を図ることで合意したようだ。
・2002年12月新しい作業委員募集 新しいメンバ数人が参加。
・2003年前半まで XSL-FO拡張についての提案の収集
・2003年秋に電話投票でXSL-FO V1.1での標準化アイテムを決定
この意思決定過程で、私の記憶ではXSL Formatterでかなり沢山のクレームがあった脚注の配置の問題が拡張候補にリストアップされなかった。このため脚注の配置については、V1.1でもベンダ独自仕様のままになっているのは残念。
ちなみに、XSL Formatterは、脚注について次のような拡張をしています。
○axf:footnote-align 脚注の配置を指定します。
○axf:footnote-position 脚注を段ごとに配置するかどうかを指定します。
○axf:footnote-stacking 脚注の配置の方法を指定します。
XSLFormatter V4.0 のXSL独自拡張仕様
アンテナハウスから提案したはずなんだけど、アピールできなかったのは失敗。
・2003年12月最初の作業草稿(Working Draft)を公開
Extensible Stylesheet Language (XSL) Version 1.1 Requirements
W3C Working Draft 17 December 2003 (要求)
Extensible Stylesheet Language (XSL) Version 1.1
W3C Working Draft 17 December 2003 (作業草稿)
・2004年春。作業草稿を出してから様々な意見が出た。次の段階に進むため、再度、仕様に盛り込む項目について作業グループで投票が行われる。
※欧米人は投票が好きなんだ。主張を通すには、投票で点を稼がないとだめってことだね。
・2004年11月 XSL 勧告へのコメントの処理について公開資料更新
Disposition of Comments on XSL Recommendation
・2004年12月第二回目の作業草稿(Working Draft)を公開
Extensible Stylesheet Language (XSL) Version 1.1
W3C Working Draft 16 December 2004 (作業草稿)
・2005年7月ラスト・コール(最終草稿)を公開
Extensible Stylesheet Language (XSL) Version 1.1
W3C Working Draft 28 July 2005
その後は、2006年2月に勧告候補、2006年10月に勧告提案となっています。いや、しかし、振り返ってみますと長い道のりでした。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月08日
XSL-FO V1.1 がProposed Recommendationに
Extensible Stylesheet Language (XS-FO) V1.1が、10月6日にProposed Recommendationとして公開されました。
Extensible Stylesheet Language (XSL) Version 1.1
W3C Proposed Recommendation 06 October 2006
これからW3Cの会員代表者による投票が行われ、投票の結果によりますが、問題なければXSL-FO V1.1 勧告仕様として認められることになります。投票の期限は11月3日です。
V1.1は、2月に勧告候補になった後、半年以上かけて実装報告を集め、その報告に基づいて議論と微調整が行われてきました。9月にはほぼ全ての問題について検討修了してProposed Recommendationになりました。
関係されたワーキング・グループの皆様の真摯な努力に対して、心からお礼を申し上げたいと思います。
V1.1では、V1.0のマイナーなバージョン・アップであり、延べ22項目が追加されています。この仕様が勧告になるための条件は、各項目に対して、2つのベンダのサポートがあることです。
ベンダからの実装報告は、まだ公開されていませんが、アンテナハウスを含め4社からの実装報告が集まっています。(実装報告のサマリは、ベンダ各社の反対がなければ公開される予定になっています)。
4社中で22項目全てを実装済みと報告しているのはアンテナハウスのみ。2番手は13項目フル実装+6項目部分実装+3項目未実装となっています。4社合わせますと20項目が2社以上の実装、2項目がアンテナハウスのみの実装となっています。
問題があるとしますと、アンテナハウスのみ実装の2項目が基準に達していないということですが、この2項目はオプションで、特にそのうちひとつは、日本語と中国語用の縦書きのために追加したものである、とされています。
XSL-FOの概要と、今回のV1.1で追加された機能につきましては、次のページに紹介していますので、ご参照ください。
1ヶ月あまりで結論がでることになります。差し戻しということはないと思いますので、年内には勧告になるものと期待しています。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月07日
DITA からFOに変換するスタイルシートを公開
DITAのOpenTool Kit 1.2.2のスタイルシートをXSL Formatter用に使えるようにするためのスタイルシートを作成して公開しました。
DITA OpenTool Kit についてはこちらをご覧ください。
DITA Open Toolkit Project Home
DITA OpenTool Kit Project は、DITAの内容をPDF、HTMLなどの配布可能な形式に変換するプログラムを実装しようというオープンソース・プロジェクトです。もともとIBM社内で利用されてきたDITAのコンテンツをFOやXHTMLに変換するためのAntベースのプログラムを元に、機能を強化して実用化しようとしているものです。
※Antは、JAVAベースのプログラム・ビルドシステム。Makeの一種。
DITAからPDFに変換するスタイルシートとしては、IBMが開発したもの(XSL FO プロセサには、FOPを使用する)がベースです。使用するXSL FOプロセサのレベルが低いためもありますが、スタイルシートの出来もあまり良くないようです。
さらに、Idiomが開発したプラグインがあります。Idiomが開発したプラグインは、XSL FOプロセサとして、RenderX のXEPを使用しています。
アンテナハウスでは、昨年9月(2005年9月)に、これらとは独立に、DITAからFOに変換するスタイルシートを開発して公開してきました。現時点で日本語のWebページに公開しているものがこれに相当します。(組版サンプルのページのDITAからFOに変換するスタイルシートにアップしているもの。)
しかし、DITA OpenTool Kitと組み合わせて使えるスタイルシートを開発して欲しい、という要望を、多くの方々からいただきましたので、今回、従来とは別のものとして、IBM版とIdiom版をそれぞれXSL Formatterコンパチブルにするためのスタイルシート差分を開発して公開したものです。
日本の皆様には申し訳ありませんが、DITA OpenTool Kit自体が英語のため、英語版のみの公開となっています。
新しいスタイルシートは、こちらから入手していただけます。
Stylesheet for DITA to XSL-FO transformation
このスタイルシートをお使いいただくには、まず、DITA OpenTool Kitをダウンロードしてインストールし、部分的にファイルを入れ替えていただくことになります。
ご活用くださいますようお願いします。
DITAについては、2006年08月24日DITA への関心が急激に高まっていますでも少し触れました。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月06日
商標登録における顕著性について 続き
昨日、最後に「特許庁の審査基準が首尾一貫してないんじゃないでしょうか?疑問を感じます。」とお話しましたが、ひとつだけ具体例で説明してみたいと思います。
以前、アンテナハウスでは「XMLツールボックス」という製品を出していました。現在は、バージョンが新しくなり、バージョンアップの機会に、名前も「XML Editor」と変えてしまいました。
そんなわけで、過去の話になってしまいましたが、この「XMLツールボックス」の商標登録申請は、顕著性がないとして、拒絶されたひとつの例です。
「XML Tool Box(エックスエムエル・ツールボックス)」と「セキュアPDF」の構成要素を比較すると、
・XMLとPDFでは、どうみてもPDFの方が一般に知られていると思います。
・ツールボックスとセキュアでは、どうかといいますと、やはりセキュアの方が多くの人に使われているのじゃないかと思います。
そうしますと、「セキュアPDF」が商標登録できて、「XMLツールボックス」が商標登録できないというのはやはり納得できません。
「XMLツールボックス」を商標として認めない理由は、次の通りです。
---ここから---
この出願に係わる商標は、コンピュータプログラム言語の1種であるXML言語をタグで生成する補助機能が、頻繁に利用する機能をボタン化して画面に並べたものであるツールボックスに格納されていることの意を認識させる「XML Tool Box」「エックスエムエル・ツールボックス」を2段に並べたものに過ぎず。。中略。。単に商品の品質、機能を表示するにすぎないものと認めます。
---ここまで---
これ、そっくりそのまま、いや、もっと適切に「セキュアPDF」にあてはまると思うのですが。
しかも、「頻繁に利用する機能をボタン化して画面に並べたもの」って、Windowsアプリケーションの標準用語では、「ツールボックス」ではなく、「ツールバー」って言うんですよ。この審査官、「ツールバー」を知らないらしい。
そんなことを主張して反論したところ、「ジャストシステムのソフト(一太郎)では、『ツールボックス』の名称が用いられていますので、認定を覆すことはできません」という返事が来ました。審査官は、どうやら「一太郎」ファンだったようです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月05日
PDF製品の商標 「セキュアPDF」
PDF製品の商標登録を調べていましたところ、次のような商標にぶつかりました。
【登録番号】 第4927478号
【登録日】 平成18年(2006)2月10日
【商標(検索用)】 セキュアPDF
【標準文字商標】 セキュアPDF
【称呼】 セキュアピイデイエフ,ピイデイエフ,セキュア
【権利者】 株式会社リコー
【商品及び役務の区分並びに指定商品又は指定役務】
9 。。。電子出版物
電子出版物に、「セキュアPDF」という名前をつけるとリコーの商標違反になるのでしょうか?
そもそも、「セキュア」、「PDF」というようなポピュラーな(顕著性のない)名称を組み合わせて、商標に登録できるというのはちょっとおかしいのではないでしょうか。
かなり昔ならいざしらず、登録日が平成18年なのに!
特許庁のホームページには
「どのような商標が登録にならないのか」
というページがあり、そこには、
「商標登録を受けることのできる商標は、次のような商標でなければなりません。」として、「自他商品の識別力又は自他役務の識別力を有する商標であること。」が条件になっています。
そして、次のような説明があります。
---引用ここから---
したがって、次のような商標は、自他商品の識別力又は自他役務の識別力を有しないものとして登録を受けることができません(商標法第3条第1項)。
・商品又は役務の普通名称を普通に用いられる方法で表示する標章のみからなる商標(第1号)
・商品又は役務の普通名称とは、取引業界において、その商品又は役務の一般的名称であると認識されるに至っているものをいいます。例えば、「時計」について「時計」、「靴の修理」について「靴修理」などがこれに該当します。
---引用ここまで---
私の経験でも、申請した商標が、顕著性のない言葉を組み合わせたものとして特許庁に拒絶されたことが、いままで何回かあります。私見では、「セキュア」と「PDF」よりもはるかに特殊な言葉を組み合わせたものでも拒絶されたこともあります。(まあ、これはあくまで私見ですが)。
「セキュア」と「PDF」は、これに該当しないのでしょうか。
特許庁の審査基準が首尾一貫してないんじゃないでしょうか?疑問を感じます。皆さんはどう思いますか?
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年10月04日
「いまさら聞けないPDF」セミナー 終了しました
PDFセミナーいまさら聞けないPDF 「PDF活用のいろは」編を、7月末から4回開催しました。
この間、大勢の方にご参加いただきありがとうございました。
いろいろな業種からご参加いただいたのですが、全体として感じましたのは、PDFはかなり普及しているように思えますが、実際にはPDFのメリットを生かした使い方がなされていないようだ、ということです。
一般の人たちは、PDFをドキュメントを紙に出す代わりに印刷して配布する形式として使っているだけで、PDFのもつポテンシャルはほとんど理解されていないといっても過言ではないようです。
いままで、また、今でも、PDFというと印刷関連業界の人が、恐らく業務上でしょうが、一番関心をもっているようです。
しかし、2004年に1980円のPDF作成ソフトが日本に登場して以来、恐らく、廉価なPDF作成ソフトはあわせて200万本程度は市場に出回っているのではないかと思います。200万人というのは、パソコンユーザ全体から考えますと、まだ小さな数字です。
しかし、無償のPDF作成ソフトもありますし、さらに高価なAcrobat Professionalのユーザまで含めますとPDF作成ソフトのユーザは、その数倍はいるでしょう。
ユーザ数の増加に加えて、層の広がりも非常に幅広くなっています。
さらに、来年は、Office2007のPDF作成機能も登場して、PDF作成ソフトのユーザはさらに爆発的に増えていくものと予想されます。そうしますと、来年には爆発的な数の、また、様々な種類のPDFファイルが流通するようになると思います。
そういう中で、PDFツールのベンダとして、社会のお役にたつためにどういうことを行っていくべきか、もう一度良く考えねばならないと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月03日
PDFからWordへ 3つの変換ソフトを無慈悲に比較する (3)
昨日に続き、3製品の変換結果について、さらに詳しく検討してみたいと思います。
2.1-2ページ目の変換結果について
まず、先頭から2ページ分の変換結果をWord2003で読み込んでオリジナルPDFと比べて変換結果が良くないところ、改善すべきところを見てみます。
(1)「リッチPDF」
次の図がリッチPDFの変換結果でオリジナルと比較して問題がありそうなところを示したものです。

・PDFを解析していますので、当然ですが、文字の誤りはひとつもありません。
表のただし、解析プログラムを改良すべき点として、次のようなことがあります。
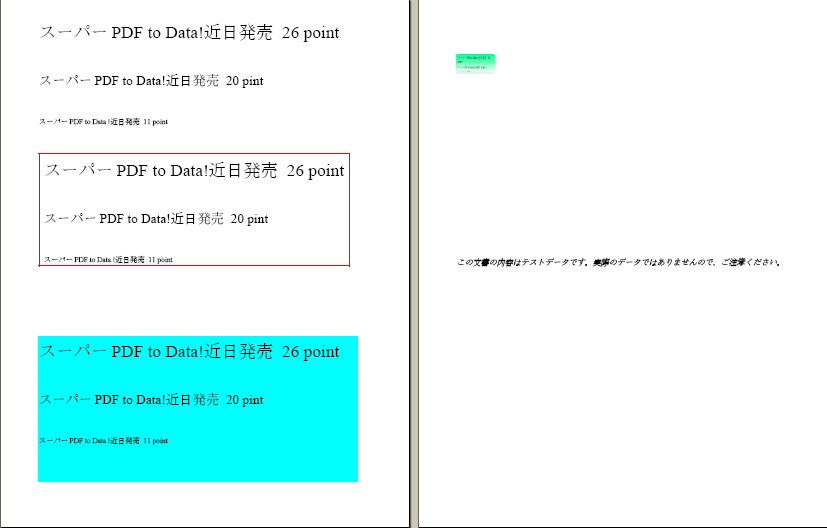
・最初の見出しの番号と見出し文字がずれている
・先頭ページで表の前のテキストに不要な枠線がついている
・文字間に不要な空白が入っている
・次の行の行頭文字(括弧など)が前の行の後ろにつく箇所が多数あるのが目につきます。これは早急に直して欲しいものです。
(2)「いきなり」

・文字認識が誤っている箇所を赤マーカで塗りましたが、1ページ目に12箇所、2ページ目に3箇所あります。文字種では9種類です。
・表のセルごとの文字サイズが、8、9、10、11ポイントが混在していて醜くなっています。表のセル内の文字サイズの認識精度が良くないようです。
・表の中の文字列の改行位置がオリジナルと違います。
・フォントカラーがなぜかグレーになる箇所があります。
・黄色がなくなっています。
・テキストボックス中の改行幅がオリジナルと比べて小さすぎるようです。行間隔はもう少し広くすべきではないでしょうか。
解決が難しい問題が多いという印象を受けます。
(3)「速攻」

・OCR方式でありながら、文字の誤りが少ないのは優れていると思います。ただし、広告のうたい文句に文字認識100%とありますが、1ページ目に文字化けが3箇所あります(~が、<”に化けている)。100%は嘘じゃないの?
・表の中の文字列の改行位置がオリジナルと違う。
・テキストボックス中の行間隔がオリジナルよりも広めになっているためか、テキストボックスから行、文字があふれている箇所が3箇所あります。このまま印刷すると行と文字が脱落した状態になってしまいます。
行間隔をもう少し小さめにするべきではないでしょうか。
※読者の皆様へ
この画像は、あくまで各製品の2006年9月末現行販売品による変換結果です。各社ともこの結果を見て製品を改善するでしょうから、将来、この結果は該当しなくなると思われますのでご注意ください。問題点については、各社とも早急に改善する努力がなされることを期待します。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月02日
PDFからWordへ 3つの変換ソフトを無慈悲に比較する (2)
昨日は、3製品でサンプルのPDFをWordに変換してみましたが、次に、各製品の変換結果を詳細に検討してみます。
1.全体として
(1)余白の認識
PDFには余白の概念がありません。これに対して、ワープロ文書には余白があります。普通は、上余白にヘッダ、下余白にフッタを配置することが多いので、PDFをワープロ文書に変換するとき余白をどう設定するか、はかなり大きな課題と思います。理想的にいえば余白を自動推定するのが望ましいと思いますが、これを実現している製品はありません。
・「リッチテキストPDF2」(リッチPDF)は、余白を既定値で設定しますが、ユーザがビューアで余白を設定することもできるようになっています。
・「いきなり PDF to Data2」(いきなり)は、上下左右余白をゼロにしています。
・「速攻! PDF to Data2」(速攻)は、上下左右余白を全て3.5mmにしています。
Microsoft Wordのページ内領域配置モデルではヘッダ・フッタは上余白・下余白内に挿入することが前提です。ヘッダを挿入するとヘッダの上端位置+ヘッダの高さがヘッダの下端位置になります。そして、ヘッダの下端位置が上余白をはみ出すと、本文領域がヘッダに侵食され、本文の開始位置が、侵食された分だけ下方にずれます。このことから、「いきなり」も「速攻」も変換後の文書にヘッダを挿入すると全てのページの本文領域が移動し、本文レイアウトを再編集することが必要になることが分かります。フッタについても同様です。
■変換後文書にヘッダやフッタを挿入することを考えると余白を設定する方が良いのではないでしょうか。
(2)テキストボックスの使用
PDFをWord文書に変換する大きな目的は、文書の再利用だろうと思います。再利用するためには、Word文書の段落に変換していくのが一番使い勝手が良くなります。ところが、段落に変換して段落内の行間隔と段落間の空き量を制御してテキストをレイアウトする方法だとPDFのレイアウトを再現するのが困難です。
これに対して、Wordのテキストボックスを使えば、ページの中での絶対位置指定ができますので、PDFのレイアウトを再現するのが比較的簡単です。再利用などなにも考えず、レイアウトさえ再現できれば良いというなら、テキストボックス使いまくりで変換後の文書を作る方法をとれば開発者は楽です。しかし、恐らくユーザは不満をもつでしょう。
さて、このサンプル文書の1~2ページにテキストボックスをいくつ使っているかを見ますと、次のようになります。
・「リッチPDF」 4個
・「いきなり」 16個
・「速攻」 15個
具体的にそれぞれがどのようなテキストボックスを作っているかを図で示します。
○「リッチPDF」のテキストボックスの位置をグリーン枠で示したもの

これを見ますと、「リッチ」のテキストボックス4個はいずれも使わなくても良い箇所です。テキストボックスを無駄に使っている感があります。この程度のレイアウトであれば、テキストボックスをひとつも使わずにレイアウトすべきだろうと思います。
○「いきなり」のテキストボックスの位置をグリーン枠で示したもの

○「速攻」のテキストボックスの位置をグリーン枠で示したもの

「いきなり」「速攻」はテキストボックス使いまくりでレイアウトを再現しているのは明らかです。ただし、「いきなり」は1ページ目にたくさんのテキストボックスを使っていますが、「速攻」は2ページ目にたくさんのテキストボックスを使っているという点が少し異なります。
■PDFからWordへの変換では、変換後のPDFのレイアウトを崩さず、かつ、再利用しやすくするためにテキストボックスをどう使うか、そのバランスをもっと工夫すべきです。
(3)フォント
このPDFの本文は日本語ではMS明朝とMSP明朝が使われています。また、本文は9.6ポイント、場合によってはより大きなフォント・サイズ、大きなフォント・サイズが使われているようです。
「リッチテキストPDF2」では、変換後のフォントサイズを0.5ポイント単位で指定していますが、「いきなり」、「速攻」では、フォントサイズを1ポイント単位で認識しているようです。PDF内のテキストに設定されている、フォントとフォントサイズを詳細に認識できないというのは、OCRソフトの限界かもしれません。
ただし、今回のサンプルでの変換結果を見る限りでは、変換後のフォントサイズを0.5ポイント単位で設定するか、1ポイント単位で設定するかであまり大きな違いはないようです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月01日
PDFからWordへ 3つの変換ソフトを無慈悲に比較する (1)
ソースネクストが、9月29日に「いきなりPDF To Data2」を発売しました。このソフトは最初のバージョンが2005年4月に発売されましたが、それ以来、PDFをワープロ文書に変換するソフトの分野では売行き(本数)トップをずっと維持してきました。
この製品は、PDFを画像に変換した上で、パナソニックの文字認識エンジンを使ってOCR処理してWord文書に変換する方式です。アンテナハウスが開発した「いきなりPDF Professional2」とセットで販売されているため、弊社製品と誤解しやすいためか、時々、「リッチテキストPDF2」宛てに、OCRの精度をもっと上げてほしいという要望をいただくことがあります。
そんなこともあり、できるだけ誤解を解くべく、下記に両製品の違いについて、まとめておきました。
PDF からOffice文書への変換ソフト
今回新バージョンになって、文字認識の精度アップをアピールしています。どの程度よくなったのか興味深いところです。
また、先日、同種のソフトとして、クロスランゲージから「速攻!PDF to Data」が発売されました。これは、ハイブリッド方式といって、テキストが埋め込まれたPDFでは、文字認識ではなく、PDFから符号化されたテキストを抽出する方式を採用し、文字認識ゼロを売りものにしています。名前もパッケージもまさしく「いきなり PDF to Data」への挑戦という印象を受けます。
アンテナハウスでも、「リッチテキストPDF2」を8月に出しています。そこで、今日は、この3つの製品を比較してみたいと思います。一般にWebで他社製品を比較するときは、A社、B社、C社というような曖昧な表現をとっているようですが、ここでは、そういう表現を使わず、情け容赦のない比較をしてみたいと思います。もちろん、自社製品に対しても例外ではありません。
その動機は、世界のナンバーワンを目指し、正々堂々と切磋琢磨しようということであって、他社の誹謗中傷をすることではないのでお間違えのないようにお願いします。まあ、実際は、変換したいPDFによって、それぞれの方法の利害得失が出てくる可能性がありますので、完全に公平無私な比較は難しいものですが。
まず、Webにあがっている実際のPDFを使ってどの程度の変換ができるのかを試してみました。
試してみたPDFはWebで配布されている「敦賀市物品等競争入札参加資格審査申請書提出要領(建設工事を除く。)」です。この文書はテキストと表を混在したもので比較的一般的なものだろうと思います。
このオリジナルテキストと、「リッチテキストPDF2」、「いきなりPDF to Data2」「速攻!PDF to Data」を使ってMicorsoft Wordに変換した結果をこちらにアップしてあります。
Download file
○使用したソフト
(1)「リッチテキストPDF2」:アンテナハウスのWebで配布されているパッチを宛てたもの。
リッチテキストPDF2 for Windows 改訂プログラムのご案内
(2)「いきなりPDF to Data 2」(9/30に購入したもの。プログラムのタイムスタンプは、P2D.EXEが8月29日になっています。)
(3)「速攻!PDF to Data」(9/30に購入したもの。プログラムのタイムスタンプは、PDF2Data.exeが8月3日になっています。)
○変換条件
なお、「リッチテキストPDF2」は、余白を対話式に設定し、先頭ページの部分を表変換設定しました。(図)
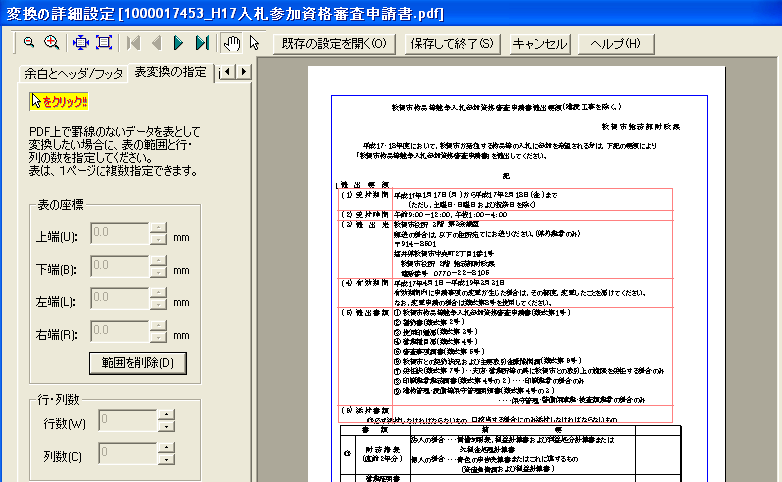
他の製品は、インストールした時のデフォルトのままです。
※10/1追記 「いきなりPDF to Data2」については、フォントを「MS明朝」に指定して変換するように設定して変換したものに差し替えました。
変換の様子を見ていますと、「いきなりPDF to Data2」も「速攻!PDF to Data」もともに、PDFを画像化して、その後、領域(レイアウト認識)、文字を認識(抽出)して、最後にWord文書を作成しています。全部または一部にOCRを使っていることは間違いありません。
投票をお願いいたします