« 2006年08月 | メイン | 2006年10月 »
2006年09月30日
Acrobat 8とPDFのファイル形式
アドビはAcrobat 8を11月下旬から発売するようですが、Acrobat 8のPDFファイル形式(PDF 1.7)について、Macduff Hughes(Acrobat StandardとProの技術ディレクタ)のブログに少し紹介されています。
Acrobat 8 and PDF format features
それによりますと、新しいPDFのバージョンは1.7ですが、従来のバージョンアップと比べて今回はフォーマットの変更はごく僅か。変更点は、3Dの領域、コメント機能、セキュリティ機能が主。
その他の注目の発言は:
(1) 今回は、ファイル形式の変更点が非常に少なかったので、Acrobat 8のファイル保存のデフォルトは、PDF1.6とした。ユーザが意図的に1.7を選択するか、1.7の機能を使用している時のみPDF1.7で保存される。
この結果、Adobe Reader 7で、Acrobat 8で作成したPDFを警告なしに開くことができるようになる。
(2) Adobat 8でPDFの過去のバージョンを指定しての保存がいままでより簡単になった。
ということです。製品としてはAcrobat については、PDFというファイル形式にかかわるツールから、もう少し、応用分野のツールに変わりつつあるように思います。PDFはファイル形式の機能強化を必要とする時期は終わったのかもしれません。

投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月29日
XSL-FOとCSSの未来 (2) CSS仕様の迷走
Webブラウザは、見方によっては、自動組版エンジンの一種と考えることもできるでしょう。HTML/XHTMLで記述されたコンテンツをパソコンの画面上に組版するエンジンです。
そのとき、CSS(Cascading Style Sheets)を使うことによって、HTMLやXMLのレイアウト指定をコンテンツから分離することができるという点で、CSSを使うことは大きなメリットがあります。CSSについて詳しい人にはいまさら、というほどの基本的なことですが。
そういう重要な仕様でありながら、2006年09月26日 XSL-FOとCSSの未来でも少しお話しましたが、CSSの仕様は混迷した状態にあります。そこで、CSSの仕様が、これまでどんな経緯を辿ってきたか、現在、どんな状態になっているか、これからどうしたら良いかを少し考えてみたいと思います。
1.CSSの歴史
2006年06月12日XSL-FOによるXMLのPDF化 (6) XMLのスタイル指定でも説明しましたが、CSSの最初の仕様(レベル1)は、1996年には策定されています。
その後、CSSレベル2が1998年2月に勧告仕様となっています。
ここまでは順調な歩みに見えます。
2.CSS2.1 仕様の策定の問題
その後、1999年にはレベル3の策定作業が始まっています。ところが、一方で、CSSレベル2.1(レベル2リビジョン1)の仕様がWorking Draftとして公開されています。
Cascading Style Sheets, level 2 revision 1
CSS 2.1 Specification
W3C Working Draft 11 April 2006
問題は、2.1の仕様案の2.0からの変更点の内容です。この変更点は、次の4つに分かれます。
Appendix C. Changes
C.1 Additional property values プロパティ値の追加
C.2 Changes 変更
C.3 Errors 誤り
C.4 Clarifications 明確化
この中で問題なのはC2の変更です。これを見ますと、特に、CSS2で定義されていたものが削除されたり変更になったものが多数あります。具体的なことは別途、例をあげて説明したいと思いますが、これは、仕様を実装する立場からは非常に困ったことになります。
なぜならば、(1)CSS2は、既に変更になるということが意図されているということになりますので、CSS2の完全な実装を意図することが無駄となってしまいます。
(2)ところが、CSS2.1は、いまだ、WorkingDraft(草稿)段階です。それどころか、一度、勧告候補まで進んだにもかかわらず、差し戻しで前に戻ってしまった状態になっています。いつ仕様として策定されるのかわからないという状況です。
そうしますと、CSS2.1の完全実装も目標として掲げ難くなります。なぜかと言いますと、果たして、標準仕様になるのかどうか分からないからです。このようにCSS2が既にCSS2.1によって否定されているにもかかわらず、CSS2.1が宙ぶらりんになっている、というのは、かなりまずい状況といえるとでしょう。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月28日
Plaggar
マッシュアップって最近のはやり言葉ですが、Webのマッシュアップ・サーバPlaggarってのが大人気だそうです。
インターネットからいろんなニュースなどを集めてきて、自在に加工して配信するサーバのようです。これ、元ライブドアの宮川達彦さんが中心になって開発しているようですが、Googleのメーリングリストは、英語なんですね。
スゴイ!なあ。
LLRingで発表されたプレゼンテーションを見ると、こんなのがあります。
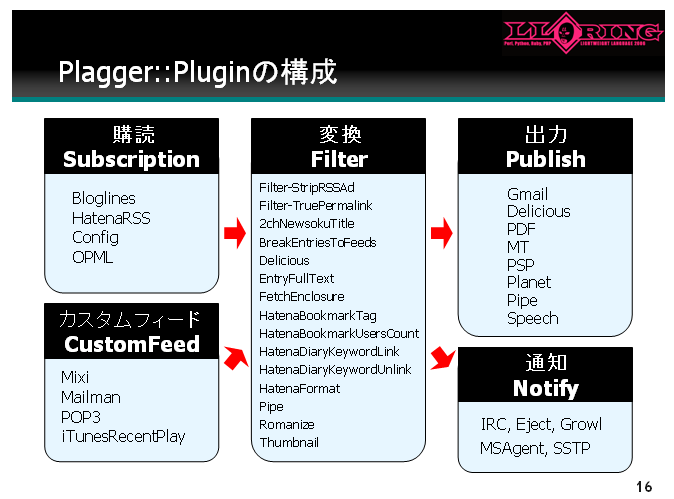
おおすごい!PDFも出せるんだ!
調べてみますと、PDF出力は、Perlで開発中の
PDF::FromHTML - Convert HTML documents to PDF
を使っているようです。でも、PDF::FromHTMLは、CPAN(Comprehensive Perl Archive Network)で公開されているのは、2006年9月12日時点でバージョン0.20で、安定してないようです。実用に使うのは難しそう。
オタク達は、こんなことやっているのか!って話ですが、実際の世界で使えるようになるには、誰かが投資をしないと無理かもしれません。
※CPAN というのは、Perlのライブラリーを集めたアーカイブ。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月27日
「リッチテキストPDF2店頭デモ」お知らせ他
1.店頭デモ
明日9月28日午後に「リッチテキストPDF2」の店頭デモを行います。
○時間: 9月28日14時~19時
○場所: ヨドバシカメラ マルチメディアAkiba 2F
○その他: 当日は会場にて「リッチテキストPDF2」のテスト変換をお受けいたします。
お客様がお持ちのPDFを使用して、実際に「リッチテキストPDF2」で変換 した結果をご確認いただくことができます。
ぜひ、ご活用ください。
2.PDF Tool V2.4 Solaris、Linux版
PDF Tool V2.4のSolaris、Linux版の発売が遅れていましたが、本日より、Solaris、Linux版をリリースします。
PDF Tool Windows版は、Antenna House PDF Driver、PDF Driver API、PDF Tool APIの3つのツールのセットです。これに対して、Solaris版とLinux版は、PDF Tool APIのみから構成しています。
主な機能としては、
・PDF をページ単位に分割・結合
* PDF をページ単位で分割・結合します。
* 分割: 指定したページ位置で PDF を分割して、新たな PDF にします。
* 結合: 複数の PDF を結合して、ひとつの PDF にします。
・PDF のセキュリティを設定・変更
* PDF を暗号化します。
* PDF に各種の制限(閲覧、印刷、文書の変更、コピー&ペースト等)を設定します。
* PDF に設定されているセキュリティ情報を取得します。
・PDF の文書情報を取得・設定
* PDF の文書情報(タイトル・サブタイトル・作成者・キーワード等)の取得・設定をします。
* PDF の開き方の取得・設定をします。
・PDF のしおり取得・作成
* 既存のしおりの取得・削除をします。
* 新規のしおりの作成をします。
・PDF の注釈の取得・作成
* リンク注釈、テキスト注釈、スタンプ注釈、ファイル添付注釈の取得・作成をします。
・リニアライズ機能
* PDF をリニアライズ(Web 表示用に最適化)します。
・PDF へ透かしを挿入
*PDF を透かしのイメージとして 他の PDF へ挿入することができます。透かしには次の指定等が可能です。
- 挿入するページの指定
- 配置する面(前面・背面)の指定
- 余白の指定
- 不透明度の指定
- 透かしに使用するイメージ(PDF)の倍率の指定
- タイリング(並べて表示)の指定
- PDF の表示時に透かしを表示する指定
Solaris版、Linux版は、サーバライセンスのみです。価格などの詳しいことにつきましては、弊社サーバ製品パートナー営業グループまでご連絡ください。
* 電話: 03-3234-9631
* FAX: 03-3221-9975
* Eメール: sis@antenna.co.jp
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月26日
XSL-FOとCSSの未来
XMLを印刷するための標準仕様としてXSL-FOとCSSがあるということは、既に、ブログで何回か取り上げました。
ブログの記事をまとめたもの
XSL-FOとCSSは兄弟のような関係ではありますが、標準化という点でもかなり異なる状況にありますし、また、互換性という点では、どうもだんだん離れていきそうな雰囲気になっています。
しかし、利用者側の視点ではそれでは困ります。なぜかと言いますと、まず、CSSとXSL-FOでは似たようなレイアウトモデルを採っていますし、レイアウトを指定するためのプロパティもかなり似通っています。
使用しているユーザの数、出回っている書籍の数、Webの情報という点から見ますとCSSの方が、XSL-FOよりはるかに多いのではないかと思います。つまり、XSL-FOに比べて、CSSの方が圧倒的に普及しているということは間違いないだろうと思います。
そうしますと、CSSを使った経験のある人、CSSについての知識を持つ人が、XSL-FOを使ってみようということになることが多いはずです。そういう人にとっては、CSSのプロパティが、そのまま、XSL-FOで使えると有難いでしょう。それができればXSL-FOの普及はもっと進むと思います。
ところが一方で、CSSとXSL-FOは標準化がかなり独立に行われ、さらに悪いことには、標準化に携わっている人の中に、無用なライバル意識があってお互いに譲歩して接近しようという気持ちがないように感じます。
標準化をすすめるワーキング・グループの運営でも、XSL-FOは強力なリーダ・シップで統制をとって、一応、順調に進んでいるのに対して、CSSのワーキング・グループは、どうも統制がなく、仕様策定もいきつ戻りつで、順調に進んでいません。
この状況をなんとか打開しなければならないでしょう。これは、私だけではなく、CSS仕様に関心を持つ人の多くが感じているだと思いますが、どうしたら良いでしょうかねえ。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月25日
フォントを埋め込まないPDFの表示(4)
10日程前、「フォントを埋め込まないPDFの表示」というテーマで、一般のWindowsアプリケーションからMS明朝、MSゴシックが使える状態になっているにも関わらず、PDFの中のMS明朝、MSゴシックを指定した文字がAdobe Readerで表示できないのは、常識的に判断して不具合である、と言いましたが、どうも気になります。Adobe Readerのフォント選択について、もう少し、調べてみましょう。
まず、PDF Reference ではどのように書いているでしょうか?探してみました。
5.4 Introduction to Font Data Structuresでは、「A font is represented in PDF as a dictionary specifying the type of font, its PostScript name, its encoding, and information that can be used to provide a substitute when the font program is not available.」(PDFにおいて、フォントは、PostScript名、符号化方式、フォント・プログラムが利用できないとき代わりを供給するために使われる情報を指定した辞書として表現される)となっています。
次に、
5.7 Font Descriptorsでは、「A font descriptor specifies metrics and other attributes of a simple font or aCIDFont as a whole, as distinct from the metrics of individual glyphs. These font metrics provide information that enables a consumer application to synthesize a substitute font or select a similar font when the font program is unavailable. (...略 これらのフォント・メトリクス情報は、コンシューマ・アプリケーションが、フォント・プログラムを入手できないとき、代わりのフォントを合成したり、類似のフォントを選択するための情報を提供する)とあります。
この2箇所から、コンシューマ・アプリケーションは、システムにフォントが存在するときにはシステムのフォントを使い、存在しないときに、フォント・メトリクス情報を使って代わりのフォントを選択するものと考えることができるように思います。
Adobe Reader(英語版)は、MS明朝を指定した日本語文字については、Windowsシステムにフォントがあっても表示できないことは、既に確認しています。では、日本語以外はどうなるか、を少し調べてみました。
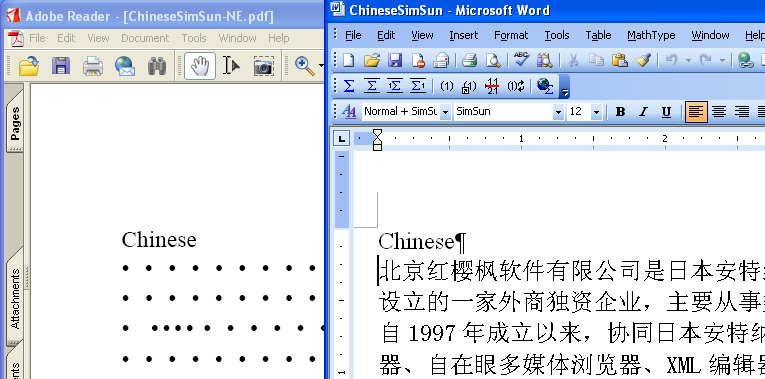
1.中国語
中国語簡体字にSimSunフォントを指定して、フォントを埋め込まずにPDFを作成してみました。右がWordのオリジナル画面、左が、フォントを埋め込まずに作成したPDFのAdobe Reader英語版で表示したもの。これを見ますと、中国語も同じように表示することができないことがわかります。
2.アラビア語
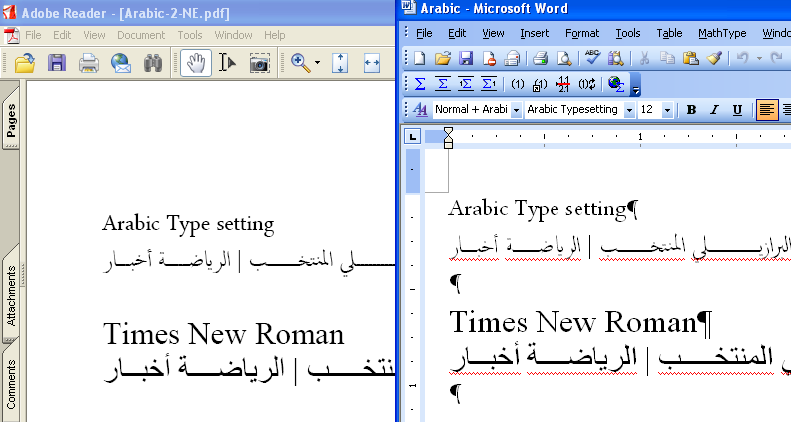
アラビア語(アラビア文字)の場合はどうなるでしょうか?試してみましたが、アラビア文字は、PDFを作成するときAcrobatにフォントを埋め込まないを指定してもフォントを強制的に埋め込んでしまいます。これは、アラビア文字は、フォントを埋め込まないPDFには意味がない(正確には、アラビア文字は、PDFのテキスト表示の仕様では、フォントを埋め込まない限り正しく表示できないため)と考えられますので、やむを得ないことだろうと思います。
■フォント・プロパティ
3.ラテン文字
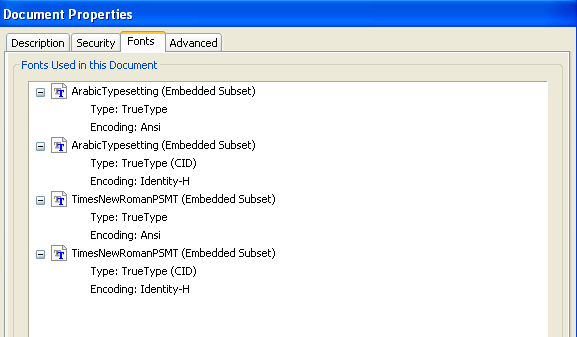
前の例では、フォントを埋め込まないと指定しても、アラビア文字が入っていると、ラテン文字についてもフォントが埋め込まれてしまっています。そこで、ラテン文字だけならどうなるかを調べてみました。
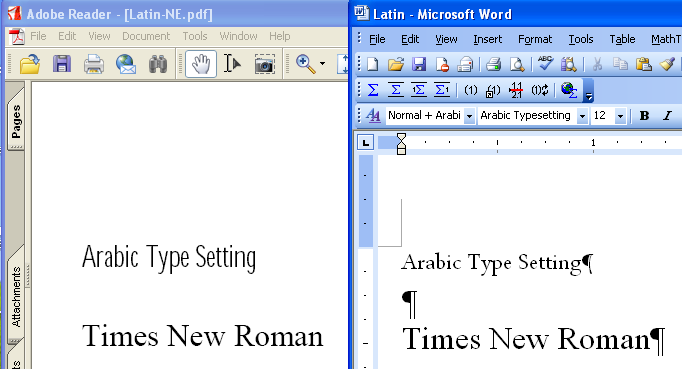
■フォント・プロパティ
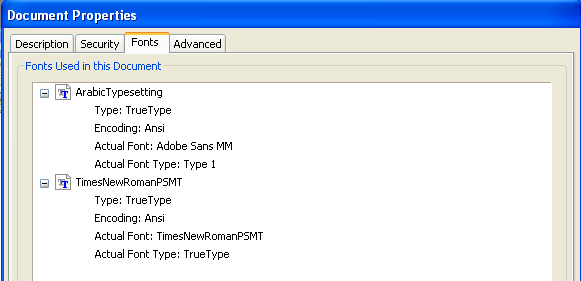
ラテン文字だけだと、フォントが埋め込まれない。Arabic Type Settingを指定した部分がAdobe Sans MM フォントに置換されて表示されていることがわかります。
このような結果を見ますと、Adobe Readerのフォントの選択では、Windows環境にどのようなフォントがあるかをチェックして適切なフォントを選択することを行っていないようです。
また、フォントを埋め込まずにPDFを作成すると、Arabic Type Settingのような特殊なメトリックスをもつフォントが、まったく異なるメトリックスのフォントに置き換えられています。
Adobe Readerのフォント選択の実装はPDF Referenceの仕様の指定するところから少しずれていると言えそうです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月24日
Office 2007 の新しい数式エディタについて まとめ
Microsoft Office (Word) 2007 の新しい数式エディタについて、2006年9月17日から21日にかけてお話しましたが、この記事には関心を持った方が多かったように思います。
そこで、早速、下記の通り整理しました。
XML資料室
Office2007の新しい数式エディタ
数式のマークアップ言語としては、MathML2.0が標準として多くの人に利用されています。MathMLは、直接、マークアップを編集することよりも、数式をWebで利用できるように、また、数式を共通に利用できるようにということを目標としているものです。
これに対して、Office2007のOMathは、数式の交換よりも、Word 2007の組版情報を忠実に保存することを目的としているようです。このようにOMathとMathMLでは目的とするところが少し異なっています。しかし、XSLスタイルシートをうまく作れば、相互に変換することが可能となりそうです。
現在、W3Cでは、MathML3.0の開発が始まっています。
Math Working Group Charter:Scope and Deliverables MathML 3.0 Recommendation
OMath とMathML3.0で、数式編集、組版が今までよりも簡単に、綺麗にできるようになることを期待します。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月23日
米国議会図書館のコレクション文書(XSL Formatter利用例)
米国の議会図書館(Library of Congress)では、色々な資料のPDF化にXSL Formatterを使っています。それで、なにか公開している利用例はない?と聞いてみましたところ、幾つかURLを紹介していただきましたので、次にご案内します。
次のページをご覧ください。
http://memory.loc.gov/cocoon/ihas/loc.natlib.ihas.200033529/full.html
http://lcweb2.loc.gov/cocoon/ihas/loc.natlib.ihas.200028017/full.html
右の方にView PDFというリンクがありますが、そこからPDFファイルをダウンロード・表示できます。PDFのプロフィールを見ますと、確かに「XSL Formatter」で作成したとあります。
最初のPDFは、Richard Rogers Collectionという表題です。ハマーシュタインとペアを組んで、「王様と私」、「オクラホマ」、「サウンド・オフ・ミュージック」などの様々なミュージカルの曲を作った人ですね。この人の業績を集めたものの説明書のようです。
PDFの本文

本文は上のように、見出し付き箇条書きの体裁になっています。
2番目のPDFは、Jazz on the screen - a jazz and blues filmographyという表題です。内容は、14000に上る、映画やテレビのフィルムで流れている1000曲に上るJAZZやブルースをデータベースに収録し、それを取り出してPDF化したもののようです。
PDFの表紙
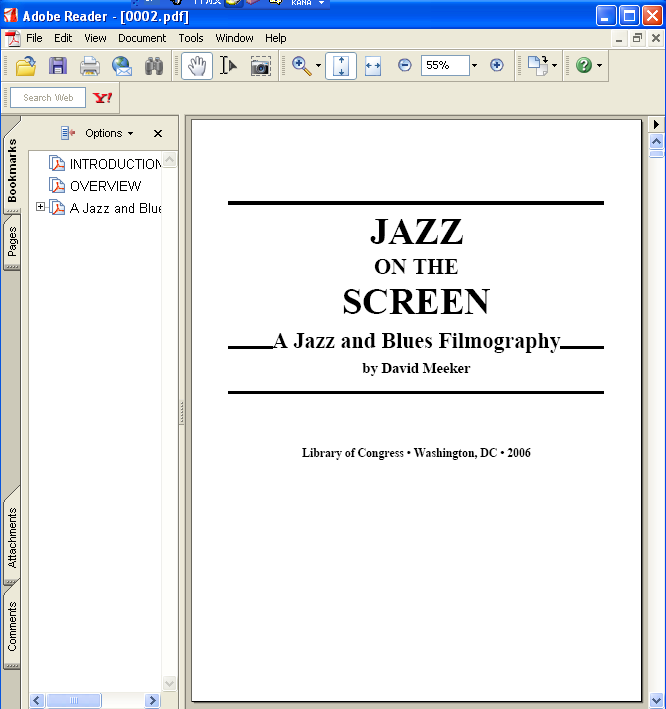
データベースからデータを取り出して、XSL スタイルシートでレイアウトを指定し、XSL FormatterでPDF化したものです。本文には2段組、3段組が使われています。トータル1082ページです。
XSL Formatterによる自動組版で可能なレイアウトの一つの例として参考にしていただきたいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月22日
ココログ出版 (XSL Formatter 利用例)
8月21日から22日にかけて、ブログのPDF化についてお話しました。
ブログをPDF化するサービス
ブログをPDF化するサービス 続き
この時、ニフティのココログ出版に、弊社の製品(XSL Formatter)が使われていると書きました。
そこで、早速、あさひ高速印刷様にケーススタディでの紹介をお願いしました。次のXSL Formatterケーススタディのページに紹介しましたので、参考にしていただければと思います。
ケーススタディのご紹介
ブログを本にする出版サービスは、これからも増えていくと思います。
ブログのコンテンツはXMLになっています。それを取り出して、XSL Formatterで自動組版してPDFにする、というのは大変親和性の高い応用領域の一つのように思います。こういうことを早くから考えられたあさひ高速印刷様に敬意を表したいと思います。
XSL Formatterは、こういう用途には一番適切なツールと思いますので、ぜひ、他のブログサービスでもご採用をいただきたいものです。
なにとぞ、よろしくお願いします。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月21日
Office2007の新しい数式エディタ (5) Office2007数式のXML形式
Office2007数式エディタで作成した数式を保存すると、WordProcessingMLの中の数式は、独自のXML形式で保存されます。この数式XML形式は、Office Open XMLの仕様書に定義されていますが、ここでは仮にOMathと呼びます。
数式をマークアップするための標準言語としては、W3CのMathML2.0がありますが、OMathはMathMLとはまったく別の仕様となっています。
・W3CのMathMLページ
・MathML2.0
Office2007をインストールすると、Office12フォルダの中にomml2mml.xslというスタイルシートがインストールされますが、このスタイルシートでOMathからMathML2.0に変換することができます。
逆にMathML2.0からOMathに変換するには、mm2omml.xslスタイルシートを使用します。
早速、簡単な数式でどの程度の互換性があるか、試してみました。
1.Word2007 ベータ版で作成した数式(PDF):Office2007Math.pdf
2.Word2007の本文XML文書:document.xml
各数式はoMathPara要素の内容となっています。
3.次のようにしてdocment.xmlをomml2mml.xslでMathMLに変換します。
>MSXSL document.xml omml2mml.xsl -o resMathML.xml
これで本文の中の数式だけ(oMathParaの内容のみ)を変換されます。このままでは表示できないので、少し修正してHTMLにしたものをブログにアップしました。数式の内容は変更していません。
4.resMathML.xmlをHTMLにしたもの:Download file この数式はInternet ExplorerとMathPlayer(プラグイン)を使うと表示できます。ご自分で表示できない人のためにIEの画面を下に示します。

これを見ますと、どうも、出来上がっているMathML数式に少しエラーがあるようです。(MathPlayerではMathMLにエラーがあると赤枠で囲って表示します。)
さらに、少し整形してXML化し、XSL FormatterのMathMLオプションでPDFにしてみました。
■Formatterで作成したPDF:Download file
MathPlayerと同じ表示になっています。Office2007の数式を完全に再現はできていませんね。多分、OMathからMathMLに変換するスタイルシートが未完成なのでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月20日
Office2007の新しい数式エディタ (4) 数学フォント
数式組版は、文字組版の中ではとても難しいもののひとつです。
昨日の話題にしましたように数学記号の種類が多いこともそのひとつですが、それ以外に、様々な難しさがあります。
1.数式の中でイタリック体や二重線文字の使い分け
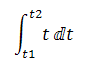
数式では、変数は多くの場合イタリック体で表します。微分記号は、上の図のⅆ (U+2146 DOUBLE-STRUCK ITALLIC SMALL-D)のように二重線のイタリック体で特別の意味を持たせた文字を使うことがあります。Unicode4.0には、U+2145~U+2149に二重線イタリックの数学記号が定義されています。
2.下付き、上付きを多用します。しかも、多重の上付き、下付きを使うこともあります。
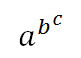
3.積分記号のような斜めの記号に対して、上限、下限をつける時は、単純に文字のベースラインを上、下に調整するのみでなく、左右の位置調整も行う必要があります。(1の例を参照)
4.括弧類などのフェンス類や積分記号などは内部の式の高さに応じて、高さを調整する必要があります。
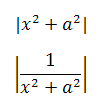
アウトライン・フォントでは、計算によって高さを調整するのは簡単にできます。しかし、ただ括弧を大きくしたり小さくしたりするだけではあまり綺麗になりません。やはりサイズ毎に専用のグリフが必要でしょう。
5.空白の幅に様々な種類があり、その使い分けが必要です。
例えば、次の図をご覧ください。
![]()
数式の左辺a-cと、右辺-cでは、マイナス記号と文字cの間の幅が異なっています。このように同じ文字の組合せでも文脈によってその間の空白の幅を変えることがあります。
6.行列の入った式を綺麗に組むには、行列の軸の位置と本文の文字の軸の位置を合わせる必要があります。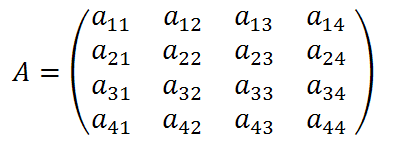
この場合、等号(=)は、行列の軸線と揃えることになります。
上のようなことを簡単に実現するためには数式組版専用フォントが必要でしょう。Office2007の数式エディタでは数式組版のための新しいフォントとしてCambria Mathフォントを開発したようです。Cambria Mathは、Cambria フォントのTrueTypeコレクション形式の一部ですが、数学の組版専用のOpenTypeフィーチャ・テーブルを持っているようです。残念ながら、この新しいOpenTypeフィーチャ・テーブルの仕様は文書化されていないとのことです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月19日
Office2007の新しい数式エディタ (3) 数学記号の入力
昨日は、Murray Sargent の直線形式は、TeXの数式表記をUnicodeで表したものと言いました。
Knuth先生が、TeXの概念を考え、最初のPlain TeXがリリースされたのは、1980年頃、Asciiコードしか考えられなかった時代です。このため、TeXでは、数式につかうギリシャ文字や、演算子、その他の記号類を「\」とラテンアルファベットの組合せでキーワードとして定めています。これで数学記号の代わりに使います。
ところが、現在、Unicode4.0には数式につかうための記号が2000種類も盛り込まれています。従って、TeXでキーワードとして決めている数学記号をUnicodeで表すのは、自然な進化といえるでしょう。
但し、何千もある文字を入力しようとすると、日本語の漢字を入力するのと同じようにIMEを使ってできるようにする工夫が必要になります。
Word2007の数式エディタでは、数学記号をキーワードで入力できるようになっています。キーワード、文字の字形とUnicodeコード番号の一覧表が「Unicode Nearly Plain-Text Encoding of Mathematics」の付録Bにあります。付録Bには264種類の記号が掲載されています。
これらのキーワードはユーザが定義して追加することもできます。
数式エディタで、キーワードを入力して空白をいれると自然にグリフに変わります。
例えば、平方根のキーワードは、sqrtです。平方根を入力するには、次のように、\(英語版ではバックスラッシュ)に続いて、キーワードを入力します。
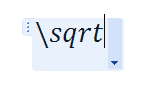
続いて空白を入力すると、記号に変わります。

このようにキーワードを使って入力するのが一つの方法です。しかし、264種類のキーワードでは、Unicodeで使える数学記号の種類と比べて少な過ぎて、足りないのではないかという心配があります。
そのためかどうか、数式エディタでは、Unicodeの16進コード番号を直接入力することもできます。先ほどのルート記号のUnicodeコード番号はU+221Aです。そこで、次のようにコード番号を入力して、

「Alt」キー+「x」キーを押しますと、記号に変わります。
この他に、主要な数式記号については、従来の数式エディタと同様にWYSIWYG入力もできます。これらの方法で、数式の入力は、従来と比べてかなり簡単になるのではないかと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月18日
Office2007の新しい数式エディタ (2)組み立て形式と直線形式
Office 2007の新しい数式エディタでは、数式の表記モードに、組み立て形式と直線形式の2種類があります。
簡単なところで、二項展開を表す等式の組み立て形式と直線形式は次のようになります。
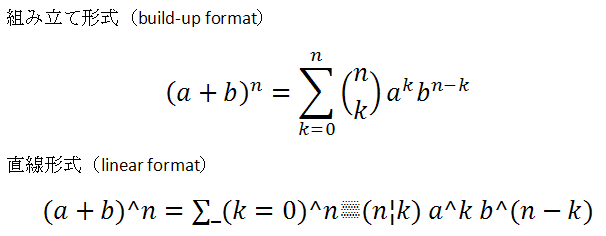
数式エディタで数式を入力していく時は、直線形式になりますが、数式を最後まで入力し終えて、スペースを入力しますと、自動的に組み立て形式に変わります。
TeXをご存知の方にとっては、直線形式というのは、TeXに似ていると思うに違いありません。TeXでは二項展開の等式を次のように表します。
(a+b)^n = \sum_{k=0}^n {n \choose k}a^k b^{n-k}
※私は、TeXを実際に使ったことが一度もありませんが、多分、こうじゃないかと思います。間違っていましたらご指摘ください。
TeXの式との違いは、次の4点です。
・\sumが、∑ (U+2211:N-ARY SUMMATION) となっている
・\chooseが、¦ (U+00A6:BROKEN BAR)となっている
・▒ (U+2592:MEDIUM SHADE)が結合子として使われている。
・画面に表示されない{ }の代わりに( )が使われている。
このように直線形式とはTeXの数式表記のUnicode版になっていると言っても過言ではないようです。
Murry Sargentによる「Unicode Nearly Plain-Text Encoding of Mathmatics」がUnicodeテクニカル・ノートとして公開されていますが、これは、Unicodeを活用したTeXの数式表記の提案と考えても良いと思います。
※参考資料
Unicode Technical Note #28:Unicode Nearly Plain-Text Encoding of Mathematics
本文:Unicode Nearly Plain-Text Encoding of Mathmatics (PDF)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月17日
Office2007の新しい数式エディタ (1)
マイクロソフトのMurray Sargentが新しいブログ「Math in Office」をはじめています。
Murray Sargent: Math in Office
この人がマイクロソフトに入社したのは1992年になっています。私の記憶では、入社の前、大学の先生時代、David Weiseと共同でSSTデバッガを開発し、その縁で、夏休みにマイクロソフトのコンサルタントとして働いていた時、ガーデン・パーティの最中に、Windowsのプロテクト・モードのきっかけとなるアイデアを出したそうです。その頃、MicrosoftはWindowsの開発で640KBのメモリの壁を破ることができずに、苦しんでいたのですが、この壁を破るきっかけが彼のアイデアだそうです。
これによって、Windows3.0のエンハンスト・モードが可能となり、さらには、Windows95へとつながって、Microsoft Windowsの大成功への道を開いたことになります。その時のエピソードが、確か、Andrew Schulmanの「Unauthorized Windows 95」に載っていました。(昔の本を置いてある書庫が遠隔地なので確認できないのですが)。
レーザの研究者(22年間大学でレーザを研究)でレーザについての本を出す傍ら、パソコンのH/Wなどのアーキテクチャについての本も執筆しています。
The Personal Computer from the Inside Out
The Programmer's Guide to Low-level
PC Hardware and Software
Murray Sargent III, Richard L.Shoemaker
Addison-Wesley Publishing Company
ISBN 0-201-62646-2
Copyright 1995
きっと、天才なんでしょうね。マイクロソフトにはこういう天才がごろごろしているそうです。(もっとも最近の天才はGoogleを目指すようですから、だんだん変わるかも。)
彼は、その後、Microsoftに入社して、RichEditの開発を担当。最近は、Officeで高品質な数式の編集と表示に関わる開発をしています。Unicodeコンソーシアムでプレーン・テキストによって数式を表現する方法について発表していたので、注目していましたが、いよいよ、その成果がOffice2007の新しい数式エディタとして登場するようです。
Word2007のβ版で、「Alt」キーと「+」キーを同時に押すと、新しい数式エディタが起動します。

ブログでは、この新しい数式エディタについての啓蒙活動をもくろんでいるようです。これから、Murray Sargentの提案する新しい数式編集についてもう少しレポートしてみたいと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月16日
PDFとOffice文書のサムネイル作成サービスを開始しました
今日から、サーバベース・コンバータ(SBC)のPRの一環として、SBCを使った無償サムネイル作成サービスを始めました。
無償サムネイル作成サービスサイト
http://conv.antenna.co.jp/tsbc/
サムネイルを作成する対象ファイル形式は、Microsoft Office (Word, Powerpoint, Excel) 97~2003のDoc/WordML形式文書、およびPDF、SVG、EMF他の画像形式です。
詳細は「MultiGeneratorサポートブログ」をご参照ください。
サムネイルですので、先頭のページだけになりますが、ファイルをWebブラウザからアップロードしますと、数秒で、サムネイル化した画像が次の図のように表示されます。
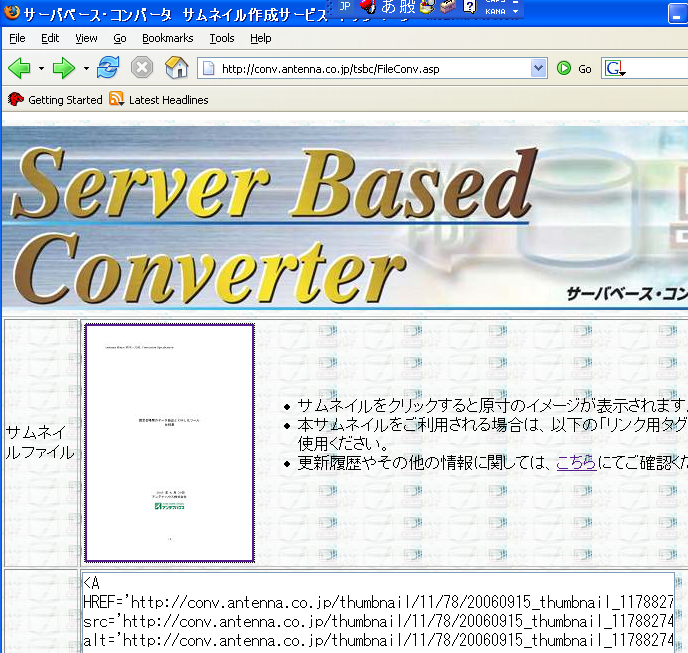
SBCは、独自にOfficeやPDF文書を解析してフォーマットするエンジンをもっていて、いわば、Officeコンパチブルなレンダラです。このサービスを通じて、SBCの高速性、精度などを体験していただく方が増えることを願っています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月15日
Wagby とXSL FormatterでWeb レポートPDFを作成
昨日(14日)は、ジャスミンソフトと共催で「Webレポート作成システム紹介セミナー」を開催しました。
今回は、なぜか、参加者があまり多くなかったのですが、ジャスミンソフトの「Wagby」は、皆さん、一度お試しになってみる価値があるソフトウェアと思います。ソフトウェアを辛口評価で切りまくるかみそりk16も、「プレゼンテーションが上手なせいか良さそうに見えた」とのご宣託でした。(素直に褒めてないですがね。それでも結構な褒め言葉です)。
私も、話を聞いていまして、このWagbyが普及したらWebレポートシステムを作るSI会社の初級プログラマは全員失職してしまうんじゃないかな、と心配になったぐらいです。
Wabyとは、Excelのシートをもとに、Webブラウザを使ってデータを登録・検索・更新・削除・表示をするデータ処理用JAVAプログラムを自動生成するソフトウェアです。
まず、Excelのシートに入力されているデータを解析して、データベースを自動設計し、データベースの接続用のサーバプログラムを生成します。
さらに、Webブラウザで表示・入力するための様々なフォームも自動生成します。このフォームは簡単なものだけではなく、必須チェック、文字形式チェック、禁止文字チェックなどの入力支援機能を設定したり、一度入力したデータをコンボボックスやテキストフィールドと連動させて再利用したり、コピー登録、入力不可制御などさらに高度な入力支援機能もいろいろ設定できます。
また、ログオン認証に加えて、ロールベースの権限管理も可能になっていることで、銀行業務のような、高度な業務アプリケーションを構築した実績もあるとのことです。
同時接続数10ユーザまでで、簡単なデータベースを内蔵した無償版も提供されていますので、関心をお持ちの方は、お試しになってみると良いと思います。
Wagbyが進化していくと、SEが客先で話を聞きながら、Wagbyを使って、さっさっとWebレポートシステムを作ってしまう時代が到来するのではないでしょうか。
さて、肝心の自社製品のPRが後になってしまいました。
Wagbyでは、データベースのデータをXML形式でエクスポートできます。あるお客様でWagbyで作成したデータから報告書のような体裁をもつレポートをPDFで出力するのにXSL Formatterを使っていただいています。
このケースでは、XML文書の内容によって出力レイアウトを変更してPDFを作成したいという顧客の要求がありました。なかなかそれに応えられるPDFツールが見当たらなかったところ、XSLTプロセサと組み合わせて柔軟にレイアウトを切り替えることのできるという点でFormatterを採用していただいたとのことです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月14日
フォントを埋め込まないPDFの表示(3)
さて、「フォントを埋め込まないPDFの表示」についていろいろ実験をしているあいだに、気が付いた問題点がありますので、次にまとめて見ます。
日本語のMS明朝、MSゴシックを使った文書をPDFにする時、フォントを埋め込む指定をしないと、Adobe Readerの英語版(初期状態)ではまったく表示できません。(WindowsにMS明朝、MSゴシックがインストールされていても、不可。)
これは、Adobe Acrobatで作成したPDFでも起きますし(下の図)、Antenna House PDF Driverでも同じようになりますので、PDF作成ソフトの側の問題ではなくAdobe Reader英語版の問題なのだろうと思います。
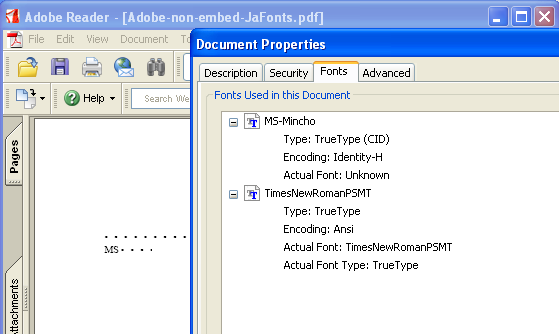
※WindowsXPを英語モードで起動中
この文書の元のWordファイルを、Wordで開きますと、次のようになります。
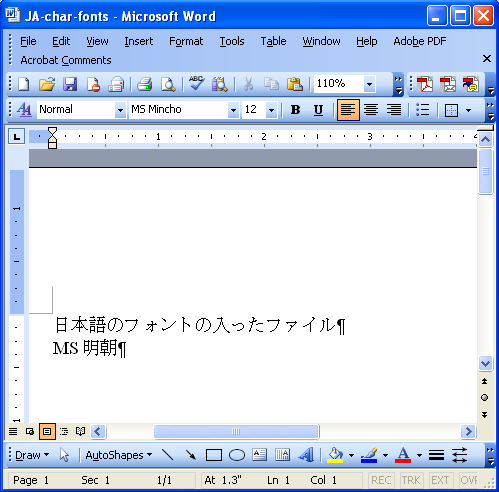
※WindowsXPを英語モードで起動中。Word2003英語版。
つまりWindowsアプリケーションでは正しく表示できるのに、Adobe Readerでは表示できないのです。
ちなみに、Antenna House PDF Viewerでもちゃんと表示できます。
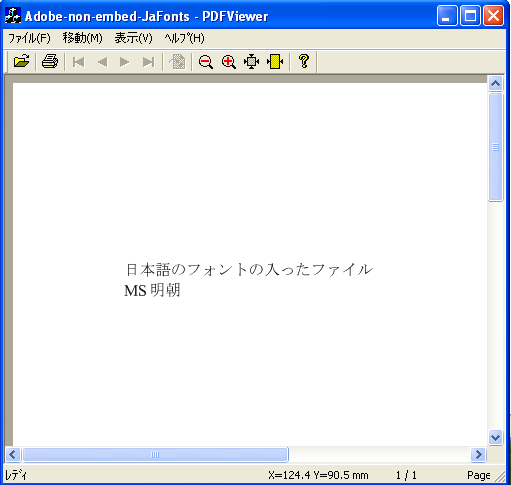
※WindowsXPを英語モードで起動中。
Antenna House PDF Viewer SDK V1.2 で、Adobe Readerと同じPDFを表示。
一方、Wordでラテンアルファベットだけ(TimesNewRomanフォントを指定)の文書を作成し、フォントを埋め込まないでPDF化したものは、Adobe Readerで問題なく表示できます。
以上のことをまとめて考えて見ますと、一般のWindowsアプリケーションからMS明朝、MSゴシックが使える状態になっているにも関わらず、PDFの中のMS明朝、MSゴシックを指定した文字がAdobe Readerで表示できないのは、常識的に判断して不具合である、と言っても良いだろうと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月13日
PDF Tool V2.4をリリースしました
アンテナハウスでは、9月11日から『PDF Tool V2.4』を出荷開始しました。本製品は、2006年6月発売の同製品V2に機能を追加・改善したものです。
■ PDF Tool V2.4 の機能
PDF Tool V2 は次の3つのコンポーネントを同梱したツールセットです。
○ Antenna House PDF Driver
各種デスクトップ・アプリケーションの印刷メニューから印刷操作で PDF を作成することができます。
○ PDF Driver API
企業内システムに、Office 文書を PDF 化する機能を組み込んだり、一括 PDF 作成機能を組み込むことができます。文書の種類に応じて、適切なデスクトップ・アプリケーションを自動的に動かして Antenna House PDF Driverにより PDF 作成をします。
○ PDF Tool API
企業内システムやインターネットシステムなどに、既存 PDF に対する様々な処理機能を組み込むためのものです。PDF をページ単位に分割・結合したり、しおり・注釈の設定・削除、透かしの付加などができます。
■ V2.0 から V2.4 での主な強化項目
V2.4 では下記の改訂をしました。
○ PDF Driver API
・ V2.0 では、Excel のシート内でマクロから PDF Driver API を呼び出すことができませんでしたが、V2.4 では、これを可能にしました。
○ PDF Tool API
・既存のPDFに別途作成したPDFを透かしとして付加する機能を追加しました。通常の透かしの他、表示されないが印刷される透かし、など様々な透かしを付加できます。
・ PDF ファイルの先頭に文字列を挿入する機能を追加しました。
・ユーザパスワード、オーナーパスワードにバイナリを扱えるようにしました。
・暗号化辞書へユーザ独自のエントリを作成する機能を追加しました。
○インターフェイス
・言語インターフェイスにJAVA インターフェイスを追加しました。(PDF Tool API のみ)
○ その他
・ V2.0では評価版は3ページしか扱えませんでしたが、V2.4ではページ数制限をなくしました。代わりに評価版であることを示す透かしが出力されるように変更しました。
・プログラムを見直し、高速化を行いました。
・ Windows版に評価版インストーラを用意して、初期設定をインストーラで行うようにしました。
・マニュアル類を見直して、より判りやすく改めました。
■販売方法と価格
PDF Tool V2 はアンテナハウスのリセラーを通じて、システム・インテグレータ、あるいは企業のシステム部門向けに販売します。
また、V2.4より価格をオープン価格に変更しました。販売価格につきましては、弊社の営業担当またはリセラーまでお問合せください。
なお、(ソフトウエア・メーカ)向けの複製再販権ライセンス契約(OEM契約)も承ります。OEM 営業窓口(oem@antenna.co.jp)までお問い合わせください。
■お問合せ先
〒102-0074 東京都千代田区九段南4-3-13 麹町秀永ビル4F
アンテナハウス株式会社(本社)
サーバ製品パートナー営業グループ
TEL.03-3234-9631
FAX.03-3221-9975 E-mail:sis@antenna.co.jp
■詳細情報
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月12日
フォントを埋め込まないPDFの表示について (2)
MS明朝とMSゴシックを指定し、フォントを埋め込まないPDFを表示しようとすると、Acrobat Readerをインストールしたフォルダの下のリソースに、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルがないと、日本語の文字が「・・・」になってしまうという問題に嵌っています。
昨日、英語版のAdobe Reader をアンインストールし、その後、日本語版のAdobe Readerをインストールしてみました。さらに、日本語版のAdobe Readerをアンインストールし、もう一度、最初に戻って英語版のAdobe Readerをイントールしました。
そうして、問題のJALのPDFを表示しようとしたところ、今度は、次の図のように真っ白になって文字がまったく見えない状態になってしまいました。
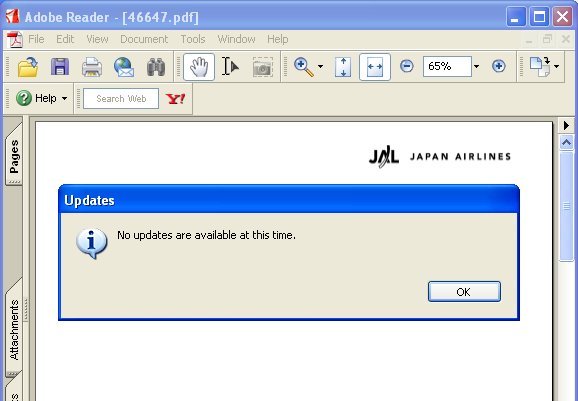
Adobe Reader をインストールしたフォルダの下のResourceフォルダの内容をチェックしてみますと、次の図のようになっています。KozMinProVI-Regular、KozGoPro-MediumはCIDfontというフォルダの中に保存されているのですが、CIDfontフォルダそのものがなくなっています。
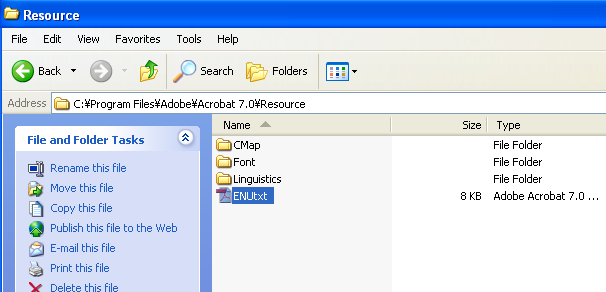
英語版のAdobe Readerをインストールした直後の状態では、フォントを埋め込んでない日本語文字の入ったPDFはまったく表示できません。(フォントを埋め込んだPDFは、日本語も問題なく表示できます)。
ここでひとつ気になりますのは、WindowsXPのロケールが英語の状態では、このままの状態から改善されないようだということです。
そこで、WindowsXPのロケールを日本語に切り替え、同じJALのPDFを表示しますと、今度は次のように、Adobe Readerをアップデートします。
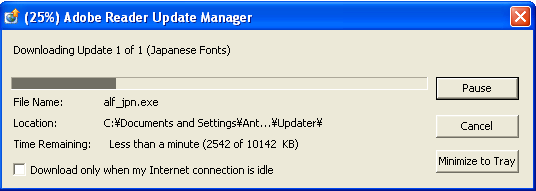
先ほどのResourceフォルダをチェックしますと、CIDfontというフォルダができていることが分かります。
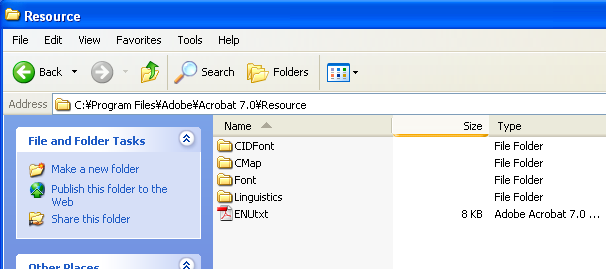
このCIDfontフォルダには、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルが収容されています。そうして今度は、フォントを埋め込んでないPDFも無事表示できます。
Adobe Reader がこの文書(日本語の文字)の表示に使用しているフォントはMSゴシックです。
つまり、Adobe ReaderのインストールフォルダのResourceの下のCIDfontフォルダとその内容がないと、フォントを埋め込んでない日本語が入ったPDFはまったく表示できないが、CIDfontフォルダができてKozMinProVI-Regular、KozGoPro-Mediumがあると日本語が入ったPDFが表示できるようになるということです。この時、表示用フォントはMSゴシックを使っているようです。MSゴシックとKozGoPro-Mediumとは一体どんな関係なのでしょう。不思議ですね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月11日
フォントを埋め込まないPDFの表示について
1昨日と昨日、MS明朝とMSゴシックを指定し、フォントを埋め込まないPDFを表示しようとすると、Acrobat Readerをインストールしたフォルダの下のリソースに、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルがないと、日本語の文字が「・・・」になってしまうということを説明しました。
この記事を読んで、次のような疑問をもたれた方もいると思います。
「PDFって、フォントを埋め込まなくても、表示するシステムに同じフォントがあれば、システムのフォントで表示するんじゃない?」
その通りですね。ここで紹介しました二つのファイルは、いずれも日本語はMS明朝またはMSゴシックを指定しています。そこで、表示したいWindowsにMS明朝とMSゴシックがあれば、KozMinProVI-Regular、KozGoPro-Mediumの有無に関わらず問題なく表示できるはずだろうと思います。
私が実験につかったPCには、無論、MS明朝とMSゴシックがインストールされていますので、PDFにフォントが埋め込まれていなくても、当該の二つのPDFは正しく表示できないとおかしいと思います。
なぜ、KozMinProVI-Regular、KozGoPro-Mediumがないと正しく表示できないのでしょう?
この原因として、考えられることは、次のようなことがあります。
(1) 英語版のAdobe Readerだから。
(2) 英語版のWindowsを日本語のロケールで使っているため?
(3) PDFファイルのフォント指定の方法が不正ではないのだろうか?
(1)を試してみるために、まず、英語版のAdobe Readerをアンインストールして、日本語版のAdobe Reader7.0.8をインストールし、JALのPDFファイルを表示してみました。それでも現象はかわりません。
ひとつだけ違い気が付きました。日本語版のAdobe Readerのままで、Windowsのロケールを英語に変更したときです。日本語版のAdobe Readerは、メニューが英語に切り替わり、英語版OS上でも使えます。この時、JALのPDFの場合、日本語をMSゴシックで表示しています。次の図を参照。

ちなみに、英語版のAdobe Readerは、同じPDFの日本語をKozGoPro-Mediumで表示するようです。

このふたつの画像は、文字の形は良く似ていますが、「こ」「は」という二つの文字に注目しますと、違いが分かります。
次に(2)について見るため、日本語WindowsXPに日本語版のAdobe Reader7.0.8をインストールし、JALのPDFファイルを表示してみました。それでも現象はかわりません。Adobe Reader のインストールフォルダの下のリソースのKozMinProVI-Regular、KozGoPro-Mediumを削除すると、フォントを埋め込んでないPDFは、システムにMSゴシックがあっても表示できません。
もしや、符号化方式の問題かと考えて、Unicode文書をPDF化してみても同じです。
次に(3)を確認するため、Microsoft Wordを使って、日本語にMS明朝、MSゴシックを指定した文書をつくり、AdobeのAcrobat、Antenna House PDF Driver で、フォント埋め込みをしないPDFを作成しました。それでも同じで、Adobe Reader のインストールフォルダの下のリソースのKozMinProVI-Regular、KozGoPro-Mediumを削除すると、フォントを埋め込んでないPDFは、システムにMSゴシックがあっても表示できません。
結局、この現象はAdobe Readerのバグじゃないかという判断に傾いているのですが。どうでしょうか。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月10日
PDFのフォント埋め込み
昨日、Webから購入した航空券のJALの「e-チケットお客様控え」(PDF)に、フォントが埋め込まれていないので、閲覧時にAdobeReaderが別のフォントに置き換えて表示しているというお話をしました。
そういえば、半年ほど前に、確定申告を下記のWebページから入力して作成しました。
確定申告書等作成コーナー
ここで、数字を入力し終えると、PDFにして返送してくれます。もう自分で電卓たたいて確定申告を作成する必要がありません。大変便利なのですが、このWebでサーバから返送してきたPDFにもフォントが埋め込まれていませんでした。
確定申告PDFをAdobe Reader(7英語版)で表示してPDFのプロパティ-フォントをチェックしますと、MS明朝とMSゴシックを使っているように見えています。しかし、Adobe Readerのインストール・フォルダの下のリソースにある、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルを削除すると、下の図のように文字が・・になってしまいます。
Adobe Readerの下にインストールされているKozMinProVI-Regular、KozGoPro-Mediumがないと、文字が正しく表示できません。Adobe Readerは、MS明朝とMSゴシックをKozMinProVI-Regular、KozGoPro-Mediumをつかって表示している?
これは、もしかすると英語のAdobe Readerだからかもしれません??
環境によってフォントが置換されて表示されてしまう可能性があるのは危険と思います。イントラネットならともかく、WebでPDFを配布するときはフォントを埋め込むべきではないでしょうか。
これに関連して、最近のQ&Aをご紹介しておきます。
<質問>
PDFへの出力におきまして「帳票の印字をMS明朝の太字で統一したい」という要求がありますが、私の認識では「対応するためには、市販のフォントを購入し、PDFの表示を行なうPC上にインストールする必要がある」と考えていますが、何か対応策は、あるのでしょうか?
<回答>
PDF作成時にフォントを埋め込むことで、PDFを表示する環境にフォントは不要となります。
但し、前提条件があります。
(1)PDF作成ソフトが、フォント埋め込み機能を実装していること。
(2)PDF表示ソフトが、埋め込んだフォントを使って表示する機能を実装していること。
<質問>
フォント埋め込みをおこなった場合は、対象フォント全体がPDFファイルに埋め込まれることになり、ファイルサイズがかなり大きくなりますか?そのPDFで使用しているフォントだけが埋め込まれるということでは無いですね?
<回答>
フォント埋め込みは、ソフトによって実装方法は違うと思いますが、アンテナハウス製品の場合は、欧文フォントは文書の中で使用しているフォントの全文字を埋め込みます。
和文フォントの場合は、文書中で使用しているフォントの中で、さらに使用している文字のグリフアウトラインデータのみをPDFに埋め込みます。(サブセット埋め込み)
従いまして、PDFファイルは、それほど大きくはなりません。なお、他社の製品でフォントをどのように埋め込んでいるかは、その会社にご確認いただく必要があります。
情報システムで作成したPDFが流通するようになるにつれ、IT技術者がPDFについて学習する必要が出てきたということなのでしょう。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月09日
Adobe Readerのフォント置換への疑問
最近、新しいPDFを見かけるたびに、プロパティをチェックするのが癖になってしまってます。
今日、JALで航空券を予約してクレジットで支払いましたところ、電子領収書がPDFで送られてきました。早速、開いてプロパティをチェックしたところ、PDFにフォントが埋め込まれていません。
○PDFファイルを表示したところ View image
○このPDFのフォント・プロパティ View image
このプロパティを見ますと、日本語はMSゴシックで表示している、とされています。
この状態は、WindowsXP英語版で地域と言語のオプション(ロケール)が日本語になっています。じゃあ、地域と言語のオプションを英語にしたらどうなるか、と思って試してみました。
WindowsXP英語版のロケールを英語にして同じPDFを表示すると次のようになります。
○PDFファイルを表示したところ View image
○このPDFのフォント・プロパティ View image
これでわかることは、Windowsのロケールを英語にするとKozGoPro-Mediumで表示しているということです。
そこで、今度は、Adobe Readerのインストール・フォルダの下のリソースにある、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルを削除しました。そうすると次のようになります。
まず、Windowsのロケールを日本語にしたとき:
○PDFファイルを表示したところ View image
○このPDFのフォント・プロパティ View image
なぜか、Adobe Readerは、このシステムではKozMinProVI-Regular、KozGoPro-Mediumフォントがないと日本語を表示できないようです。
次に、Windowsのロケールを英語にした状態で、Adobe Readerのインストール・フォルダの下のリソースにある、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルを削除しました。そうすると次のようになります。
○PDFファイルを表示したところ View image
○このPDFのフォント・プロパティ View image
結論として次のことが言えそうです。
日本語にMSゴシックを指定して、フォントを埋め込まずに作成したPDFを表示する際、Windowsのロケールが日本語の時は、MSゴシックで表示するが、Windowsのロケールが英語の時は、KozGoPro-Mediumフォントで表示する。
しかし、なぜかAdobe Readerは、Windowsのロケールが日本語にせよ、英語にせよ、自分のインストール・フォルダにKozGoPro-Mediumフォントがないと表示できない。
ここで使用したのは、Adobe Reader 7.0.8 英語版です。どうも奇妙な動作です。
いづれにせよ、WebでPDFを配布するときは、フォントを埋め込むべきではないでしょうか。そうしないと、PDFを表示する環境によって文字がどう表示されるか、予測が付かないケースが出てくると思います。
※9月9日の記事に、事実誤認がありましたので、9月11日に本文を修正しました。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年09月08日
PDFの画像化・サムネイル化
当社の営業窓口のメールを見ていますと、Office文書やPDFを画像化したいという要望は、時々寄せられます。その都度、「サーバベース・コンバータ」の評価版をお使いになってみてください、とご案内していましたが。。
よく考えてみましたら、既に、当社のWebページには、Office文書やPDFを1ページだけですが、画像化するシステムがあることに気が付きました。
いま、「デモサイト」と銘打っていますので、気が付かない方も多いのではないかと思いますが、ここから、Office文書やPDFの先頭ページを画像化していただけます。
Server Based Converter V1.2 MR4 テスト変換申し込み PC用
このWebサイトへ、画像化した結果を返送するメールアドレスをご指定の上、例えばPDFファイルをアップロードしていただきます。
そうしますと、ほとんど瞬時で、変換結果の画像がお手元に届きます。
例えば、このようなPDFをアップロードします。
サンプルPDF
変換先の画像形式として、JPEGを指定します。そうしますと、次のようなJPEGファイルが指定のメールアドレスに送られてきます。
もし、利用したい希望者が多いようなら、近いうちに、このシステムをもっと使いやすくして、無償のサムネイル作成サービスをはじめようかという議論をしています。
画像変換・サムネイル作成サービスを果たして大勢の方に利用していただけるでしょうか。また、無償サービスをする意義があるのでしょうか?
まずは、ブログの読者の皆さんの反応でそれを占ってみたいと思います。ということで、ブログの記事をお読みの皆さんの中で、無償サービスを実現して欲しいという方は、まず、現在のテスト変換を、ぜひお試しになって見てください!また、ご意見もお待ちしています。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月07日
Willcomのモバイルで大きなPDFを表示する
Willcomのモバイルが人気を集めているようです。今日、ある人が来社しまして、Willcomのモバイルのユーザ向けにPDFで情報を提供するサービスを計画しているのだが、Willcom搭載のPDFViewerでは、PDFを2ページ位しか表示できないのでどうしたら良いかという相談を受けました。
例えば、WillcomW-ZERO3には、Picsel PDF Viewerが載っています。このPDF Viewerでは、PDFを2ページ表示するともう目一杯になってしまうようです。
そこで、次のような仕組みはどうだろうかと考えました。
(1) サーバ側でPDFをページ単位に分割します。
(2) そして、各ページに、次のページに進む、前のページに戻る、というリンクを貼り付けます。(次の図を参照)。
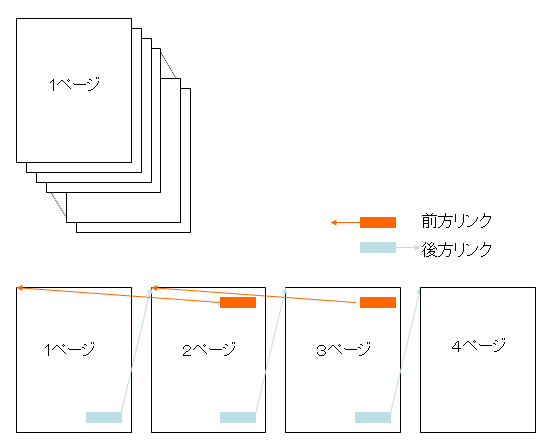
ユーザは1ページ目をWillcomモバイルにダウンロードし、見終わったら、次のページにすむをクリックしてナビゲートしていくことができます。こうすれば、いつも表示しているPDFは1ページだけですので、余裕があるはずです。
(1)、(2)をサーバ側で実現するには、アンテナハウスのPDF Tool を使えば簡単にできます。
PDF Tool V2では、PDF Tool APIがあり、これを使えばPDFのページ単位の分割はむろんできますし、さらに、任意の位置にリンクをつける機能もあります。
今度、開発者に時間の余裕があるときにでもデモシステムを作ってみようかと思っています。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月06日
PDFからHTMLに変換(3)
WebでPDFからHTML変換するソフトを調べていましたとこと、AdobeでPDFをHTMLに変換するサービスを行っているのに気が付きました。
Online conversion tools for Adobe PDF documents
1.PDFをe-Mailに添付して送信する方法
テキストに変換するメール受付窓口と、HTMLに変換するメール受付窓口があります。
2.簡単なフォームでURLを送る方法
Web上のPDFを指定して変換させることができます。
まず、2番についてためしてみました。Web上の英語のPDFを試しにアップしてみました。そうしますと、次のようなプログレス状態の表示になります。
しかし、数分かかったあと最後に、エラーになってしまってできません。4つのPDFファイルを変換してみましたがすべてエラーで、エラーの原因も通知してきません。
そこで、今度は、別のPDFをe-メールで送信してみましたところ、無事、HTML変換の結果が戻ってきました。
---ここから---
Thank you. Your document was successfully converted using the Adobe Acrobat Elements Server.
Document : WordML-Office.pdf
File Size : 367.9KB
Converted File : WordML-Office.zip
File Size : 49.8KB
---ここまで---
Acrobat Elements Server を使っているとあります。
変換精度を見てみますと、次のような状態です。
■オリジナルPDFファイルの1画面

■上のページの変換結果(HTML)
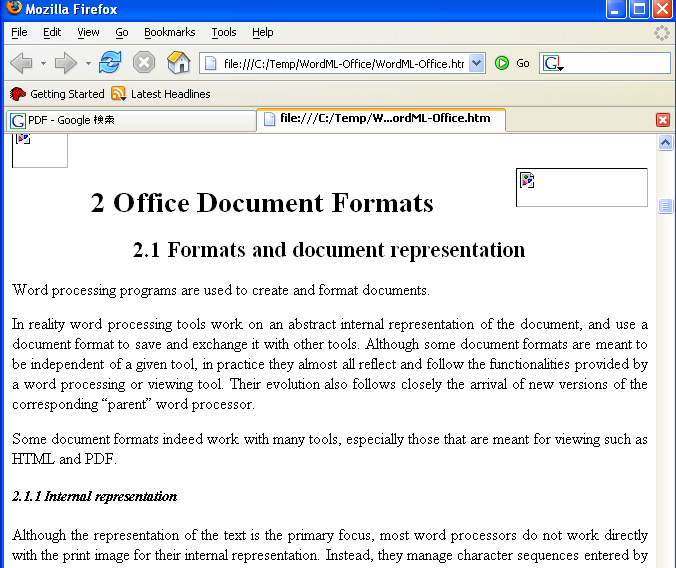
画像は脱落してしまいます。
上の結果から見ますと、あまり精度は良くないことが分かりますね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月05日
リッチテキストPDFの店頭デモのお知らせ
9月23日と24日の両日、午後13時から18時まで、秋葉原のラオックス ザ・コンピュータ館5Fで「リッチテキストPDF2」の店頭デモを実施します。
当日は会場にて「リッチテキストPDF2」のテスト変換をお受けいたします。お客様がお持ちのPDFを使用して、実際に「リッチテキストPDF2」で変換 した結果をご確認いただくことができます。是非ご利用ください。
また、具体的な金額についてはお知らせできませんが、当日は、「リッチテキストPDF2」は特価にて販売となります。お楽しみに。
店頭デモでは、「リッチテキストPDF2」の優れた変換精度をぜひお確かめいただきたいと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月04日
PDFからHTMLに変換(2)
昨日は、思わぬところで時間をとられてしまいましたが、今日は、他のPDFからHTMLへの変換ソフトとしてどのようなものがあるか、ピックアップしてみます。
BCL Technologies Magellan Desktop
Magellan Desktop Version 6.5
・Convert Documents to Web-Ready HTMLとあります。
・PDFを含む様々な文書をHTMLに変換できます。
・定価は129ドル(Webで99ドルで販売しています)
・日本語のサイトもあります。
30日間試用版がありますので、少し試してみます。
「リッチテキスト・コンバータ」の時と同じファイルを変換してみますと、日本語のPDFも問題なく変換できるようです。
変換結果をブラウザで表示した先頭の部分は、次の図のようになります。
このソフトの変換の特徴は、PDFのページをそのままHTMLでも1ページに変換することです。(既定値の場合。HTMLをひとつに結合するオプションも設定可能。)
HTMLをページ単位で分断し、1ページ毎をめくって行くようにナビゲーションします。このためjavascriptでフローティングするナビゲーションツールを作っています。このツールからサムネイルを表示することもできます。
できあがったHTMLは、次の図のようにPDFの1行毎に分断されていて、SPANタグで囲まれています。このためHTMLを再編集することはできません。

このHTML(本文の1ページ目のみ)をAnother HTML Lintで採点しますと、-369点になりました。うーーん。標準仕様などぜんぜん頭にないのでしょうね。
この製品の基本的な考え方は、PDFをブラウザでナビゲーションできる形式にするということにあり、HTMLにして再利用するという考え方ではないようですが、こういうやり方もあるということ。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月03日
PDFからHTMLに変換(1)
PDFを表示するには専用のビューアが必要ですし、WebでPDFを見かけると、「煩わしい!」と思ってしまいます。そういう印象をもつひとは私以外にも大勢いると思います。
PDFをHTMLにしてからWebで公開するのも良いのではないか?と考える人も多いことでしょう。そこでPDFからHTMLに変換するソフトについて現状を調べてみたいと思います。
リッチテキスト・コンバータ
ちなみにアンテナハウスの「リッチテキスト・コンバータ」でもPDFからHTML変換ができます。リッチはPDF専用というわけではないので、ワープロ文書ファイルからHTMLへの変換もできます。営業担当者にWeb掲載のニュースを作ってもらうとこれでやっているようです。この「Webレポート作成システム紹介セミナー」ご案内ページはリッチで作ったもの。
PDFはどうかと言いますと、PDFについても文字や表のレベルであれば大体正しくHTMLに変換できます。
次の変換例をご覧ください。
■オリジナルのPDFファイル 契約書の雛形例(PDF)
■変換後のHTML 契約書の雛形例(HTML)
※「リッチテキスト・コンバータ2005R3」(未発売)で変換。変換先設定は既定値です。
ところで、このHTMLのリンクをブラウザでたどると、IE6、FireFoxともAgreement.htmファイルをUTF-8と判定してしまいます (正しい文字コードはシフトJISです)。
《※9月4日追記 上の文章は、サーバ側の設定が原因でした。9月4日に設定を変更しましたので、現在、文字符号化方式が正しく判定されるようになっています。詳しくはコメントをご覧ください。》
・Agreement.htmファイルはxhtml形式です。
・Agreement.htmファイルをローカルでFireFoxで見ると、文字符号化方式自動判定でシフトJISになります。
・XML妥当性検証パーサでは妥当なXMLと判定されます。
・Another HTMLLintでは99点です。(title 要素の内容がないのが減点1)。
・XML宣言でもencoding="Shift_JIS"と宣言していますし、<meta http-equiv="Content-Type" content="text/html; charset=Shift_JIS" />も出力しています。
なぜ文字符号化方式を正しく判定できないのでしょうか。ブログサーバの方になにか問題がありそうに思います。
同じファイルを他のWebサーバにアップすると、リンク先ファイルの文字符号化方式が正しく判定できます。
契約書の雛形例 (HTML をWebサーバにアップしたもの)
投稿者 koba : 08:00 | コメント (4) | トラックバック
2006年09月02日
ソフトウェアの国際化について 続き
昨日は、現在では、ソフトウェア製品はワンソース、ワンバイナリで全世界の市場をカバーできるようになっているという話をしました。
これとインターネットが組み合わせれば、技術的には、全世界で同一のソフトウェアを販売することも可能になります。
そうするとソフトウェアの市場は飛躍的に大きくなりますので、今の10倍は売れるようになるのだろうと思います。
で、実際にやってみると、なかなかそうはうまくいかないものなんですね。
当社の場合、XSL Formatterだけは、海外でかなり売れています。今年は、有名どころの会社だけでも、米国のB航空機製造会社、ドイツのD自動車会社、米国のIコンピュータ・メーカなど、錚々たる会社が大口ユーザになっていることもあり、最近は、海外売上げ比率70%以上になっています。
ところが、他の製品はなかなか売れないんですよ。市場がグローバル化されて広がったからと言って、売上げが増えるわけではないということを身をもって実感してます。
PDF関連ツールに限っていえば、残念ながら、念願の欧米市場参入すらできていません。欧米市場のPDF関連ソフトウェア・メーカ、PDF関係製品の種類も日本の市場とは比較にならないほど多く、競争も厳しいですから、この競争相手と同じ土俵で戦って頭角を現すだけのモノがなければ、製品を出しても、それこそ一顧だにされない、という状態になってしまうのは明らか。
自動車メーカ、OA機器メーカでもできたことなので、ソフトウェア・メーカだってできると思うのですが。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月01日
ソフトウエアの国際化について
昨日、英語版のWindowsXPの地域と言語のオプションを日本語としたOSで、英文のMicrosoft Word2003で作成した日本語フォントを含む文書をPDFにするとフォントのハンドリングがうまくできていないソフトウエアがあるということを報告しました。
私は、日本で開発したソフトウェア製品を欧米で売りたいと思っていますので、いつもWindowsは英語版を使うようにしています。日常PCを使って仕事する上では、それでほとんど支障を感じることはありません。
ところが、時々、昨日報告しましたように、日本語のWindowsで日本語のアプリケーションを動かしているのであれば問題ないのに、英語版を日本語用に使ったとき問題が出ることがあります。
それで思い出しますのは、20年前、MS-DOSの時代。昔は英語用に開発したOSやアプリケーションで日本語処理をするということは考えられませんでした。そして、Windows3.1、Windows95の時代では、英語版と日本語版は別のアプリケーションとするのが普通で、欧米のソフトウエア製品を日本語化して、初めて日本語で使うことができました。日本のソフトハウスの仕事のジャンルの一つに欧米のソフトのローカライズという仕事がありました。
ところが、WindowsNT、Windows2000、WindowsXPでは、最初から、全世界で使えるように作ることで、ソフトのローカライズの必要性はなくなっているはずです。
アプリケーションに表示するメニューでさえも、Windowsが英語版として動いているときには英語のメニューを表示し、Windowsが日本語で動いているときには日本語のメニューを表示するように作っておくことで、英語環境では英語版として、日本語環境では日本語版として使えるように作ることができます。
ワンソース、ワンバイナリでソフトウエアの多言語化ができるのです。
例えば、アンテナハウスのXSL Formatterはそのように作って、日本語版と英語版を常に同時リリースしています。(同じものなので当たり前ですが)。
XSL Formatter日本語版のWebページ
XSL Formatter英語版のWebページ

上の図を比べていただくと日本語版と英語版が同時進行になっていることをご確認いただけると思います。現在は、最初から国際化を考えて設計することで、プログラムに関する限り、ローカライズ作業は必要なくすことができます。
従って、きちんと国際化を考えて作れば、昨日起きたような問題は本来起きないはずなのです。しかし、現実には起きるのですね、それが。で、この問題が起きるのはやはりフォント周りの話が多く、時々、まれにですが、弊社の社内でも私のPCでしか起きないという問題もなくはありません。
投票をお願いいたします