« 2007年02月 | メイン | 2007年04月 »
2007年03月31日
Open XML と ODFの比較レポート
少し古い情報ですが、Microsoft Office 2007のXML文書形式である「Open XML」と、OpenOffice.orgの文書形式である「ODF(Open Document Format)」についての、IDCの調査レポートの日本語版が公開されています。
IDC report on Open Document Standards (Japanese version)
ODF陣営を中心に、既に、ODFがISOの標準になっているのに、二つ目の国際標準は要らない、という意見も見られるようです。それに対して、このIDCのレポートでは、オープンな標準が二つあっても別に問題はないという結論を出しているように読み取れます。多分、それが、このレポートが、Open XML のWebサイトで公開されている理由なのでしょう。
IDCのレポートは、ざっと一読してみる価値はあります。
ところで、私は、「Office 2007」の文書形式が、標準になることについては、IDCの言うオープンな標準とは別の観点から、大きな意味があると思っています。
このことは、以前に、XML開発者の日にも、コメントさせていただきましたけれども繰り返しますと、— Microsoftは、Word2003で、WordprocessingMLを出したとき、「これが標準だ」、と言っていたはずなのですが、4年経過してWord2007になった時点で、新しいWordprocessingML(2007)は、Word2003のWordprocessingMLとはかなり変わってしまいました。
弊社では、Word2003のWordprocessingMLをいろいろ調べて、Word2003によるXMLオーサリング・システムを開発したりしたのですが、Word2007でファイル形式が変わってしまったことで、また、(全部ではありませんが)やり直しが必要でしょう。
オーサリングだけではなく、サーバべース・コンバータは、Word2003のWordprocessingMLを組み版することはできるのですが、Word2007のWordprocessingMLは組版できません。また作り直しです。そんなわけで、早いところ、ISOの標準になって、Microsoftの独断でファイル形式を変更できないようになると、ありがたいと思っています。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月30日
PDFからWord、Excel変換ソフトの評価 (6) — 「リッチテキストPDF3D&D」と「いきなりPDF to Data2」 によるExcel変換採点
次に、「リッチテキストPDF3D&D」と「いきなりPDF to Data2」 によるPDFからExcelへの変換結果について、それぞれの変換がどの程度のレベルかを採点してみたいと思います。
PDFからExcel変換は、テスト用PDFファイルを3つ用意しました。
2007年03月27日 PDFからWord、Excel変換ソフトの評価 (4) — 「リッチテキストPDF3D&D」と「いきなりPDF to Data2」 による変換結果
3件のファイルの変換時間合計は、下の表に示す通りで、「リッチテキストPDF3D&D」が15秒、「いきなりPDF to Data2」 は30秒です。「いきなりPDF to Data2」 の方が2倍の処理時間が掛かっています。
採点結果を次に示します。採点の基準は、昨日のPDFからWord変換の採点と同じです。
| テスト項目 | 「リッチテキストPDF3 D&D」 | 「いきなりPDF to Data2」 | |
|---|---|---|---|
| PDFからExcelへの変換 | 3ファイルの処理時間 | 15秒 | 30秒 |
| (1)簡単な表とグラフの例 | グラフの折れ線が不正な変換(-10)、測定結果を囲む囲み罫線が第一列に集まっている(-10) (採点80点) |
計測条件の説明部分がセルに適切に配置されていない(-5)、測定結果を囲む囲み罫線の上辺が崩れている(-5)、測定結果の表の左側が完全に脱落(-10)、同右側の背景色が消える(-5)、グラフの黄色折れ線が脱落・メモリなど文字化け(-10) (採点65点) |
|
| (2)簡単な財務諸表の例 | 勘定科目が不必要にセルに分かれている(-5) (採点95点) |
数値が勘定科目毎にセルに入らず、複数の勘定科目の数値がひとつのセルに入っているためExcelで再計算ができない(-10)、構成比の数値の位置が行ずれを起こしている(-10) (採点80点) | |
| (3)簡単な経費清算書の例 | 上部の境界線が再現されていない(-10)、図形の位置がずれている(-5) (採点85点) |
上部の境界線と文字列がイメージ図形になっている(-10)、表部分数値がひとつのセルに入らずまとめて一つのセルに入っているためExcelで再計算できない(-10)、図形が脱落している(-10)(採点70点) | |
3つの文書の採点結果を平均しますと、 「リッチテキストPDF3D&D」は87点。「いきなりPDF to Data2」は72点となります。
こうしてみますと、両者のExcelへの変換結果は比較的高得点のように見えます。しかし、「いきなりPDF to Data2」のExcelへの変換結果は、多分、Excelデータとして再活用できないだろうと思います。
その理由は次の通りです。Excelのような表計算では数値を一つずつセルに入力することで、セルに定義した計算式を使うことができます。しかし、「いきなりPDF to Data2」は、ひとつのセルに多数の数値を入れてExcelのセルを作ってしまうため、上述の計算機能が使えないからです。なぜ、このような仕様になっているのでしょうか?理解に苦しむところです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月29日
PDFからWord、Excel変換ソフトの評価 (5) — 「リッチテキストPDF3D&D」と「いきなりPDF to Data2」 によるWord変換採点
今日は、先日ご紹介しました、 「リッチテキストPDF3D&D」と「いきなりPDF to Data2」 によるPDFからWordへの変換結果について、それぞれの変換がどの程度のレベルかを採点してみたいと思います。
採点基準は目に付く問題のない変換結果を100点とし、目に付く問題点が1件ある毎に致命的問題点-10点、致命的でないと考えられる問題点-5点として採点します。ここで指摘する以外にも、Word文書を編集する過程で発見される小さな問題があると思います。しかし、そういう小さな問題は取り上げていません。これらの問題点は、ソフトウエアの改良すべき点でもあります。もちろん、採点結果はどうしても恣意的なもので、絶対というものではありませんが、一応の目安にはなるのではないかと思います。
最初に6つのファイルを変換するのに要する時間ですが、 「リッチテキストPDF3D&D」が30秒弱に対して、「いきなりPDF to Data2」は160秒程度と5倍以上の処理時間がかかっていることを報告します。個別の採点結果は表をご覧ください。
| テスト項目 | 「リッチテキストPDF3 D&D」 | 「いきなりPDF to Data2」 | |
|---|---|---|---|
| PDFからWordへの変換 | 6ファイル処理時間 | 25秒~30秒 | 160秒程度 |
| (1)簡単な契約書の例 | 上余白・下余白が狭い(-5)、
左余白・右余白が狭い(-5) (採点:90点) |
上余白・下余白がゼロ(-10)、
左余白・右余白がゼロ(-10)、
契約条文毎にテキストボックスに入っているので文章の修正ができない(-10)、
一行毎に改行が入っていて文章が繋がっていない(-5)、
文字化け(9条見出し、14条二項、15条など)(-10) (採点:55点) |
|
| (2)簡単な表の例 | 目に付く問題なし (採点:100点) |
文字の大きさが不揃い(-5)、極端な文字化け(賃貸借室の所在する建物、賃料等の支払方法、㎡他)(-20)、セル内の文字配置が狂っている箇所多数(-10) (採点:65点) |
|
| (3)単純な縦書き文書の例 | 一行毎に改行が入っている(-5)、ページ番号がテキストボックス(-5)、第2条四項の読点がテキストボックス(-5) (採点:85点) |
上余白・下余白がゼロ(-10)、
左余白・右余白がゼロ(-10)、
ほとんど一行毎にテキストボックスに入っていて文章の修正ができない(-10)、記号類(()類、句点)が認識できていない(-10)、ページ番号が本文と同じテキストボックス(4、5ページ)(-10)、ページ番号がテキストボックス(1~3ページ)(-5)、読点が文字の左上(-10) (採点:55点) |
|
| (4)簡単な仕様書の例 | 上余白・下余白が狭い(-5)、ページ番号がテキストボックス内(-5)、3pの図形の線が2本欠落(-5)、4pの図形が再現できてない(-10)、5Pの図形と文字の位置関係不正(-5)、アンダーラインがシェイプでも出ている(-5) (採点65点) |
上余白・下余白がゼロ(-10)、
左余白・右余白がゼロ(-10)、
ページ番号がテキストボックス内(-5)、見出しゴシックと本文明朝の使い分けができてない(-5)、1p表の網掛け欠落(-5)、表の文字誤認識(-10)、文章が不規則にテキストボックスに入っていて編集できない(-10)、2Pの図不正(-10)、5P図不正(-10)、番号箇条の番号と文章が別のテキストボックス(1.1項、1.4.2(2)項)(-10)、アンダーライン付きテキストがイメージ図形(-10) (採点5点) |
|
| (5)文字の大きさや地の色の例 | 背景色が異なる色になっている(-5)、背景色と文字の相対位置関係がずれている(-5)、飾り文字がイメージ図形になっている(-5) (採点85点) |
背景色がなくなっている(-10)、飾り文字が文字化けしている(-10) (採点80点) |
|
| (6)簡単な申請書の例 | 文字間隔が不揃い(-5)、行間隔が不揃い(-5) (採点90点) |
文字の大きさがばらばら(-5)、文字化け(九段→九浸、明路→関路)(-10) (採点85点) |
|
6つの文書の採点結果を平均しますと、 「リッチテキストPDF3D&D」は86点。「いきなりPDF to Data2」は58点となります。
なお、ここで紹介しました6つのPDF文書は比較的単純なものです。採点については「いきなりPDF to Data2」については、少し甘く採点しているつもりです。実務での使用に耐えるかどうかを判定するには、もう少し厳しいデータで、厳しい採点をしなければならないだろうと考えていることを申し添えておきます。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月28日
PDF Tool V2.5MR2 と PDF Driver V3.1MR2 をリリース
アンテナハウス株式会社は、Antenna House PDF Tool V2.5MR2 と Antenna House PDF Driver V3.1MR2 の公開・販売を開始しました。
今回のバージョンは、主として前バージョンの公開以降に報告された障害の修正を反映したものになります。PDF Driver や PDF Tool をまだお試しでない方は、ぜひこの機会に評価版をお試しください。
※ PDF Tool に同梱されている PDF Driver は、単体販売しているものと同一製品です。
◆ 詳しい情報は下記ページをご覧ください。
◇ ウェブページ
Antenna House PDF Tool
Antenna House PDF Driver
◇ アンテナハウス直販ページ
Antenna House PDF Tool
Antenna House PDF Driver
投稿者 numata : 08:00 | コメント (0) | トラックバック
2007年03月27日
PDFからWord、Excel変換ソフトの評価 (4) — 「リッチテキストPDF3D&D」と「いきなりPDF to Data2」 による変換結果
先日発売した、「リッチテキストPDF3 D&D」の変換精度がどの程度のものかを確認していただくために、次に、簡単なPDFのサンプルを用意して、WordとExcelに変換してみました。比較対象として、現在、PDFからWord、Excelに変換するソフトの中では圧倒的な売行きを誇っていると思われる「いきなりPDF to Data2」で同じPDFを変換したものと比較してご紹介したいと思います。
ここにご紹介するサンプルは、どれも比較的シンプルなものですので、ソフトの本当の実力を調べるには少し物足りないかもしれません。しかし、複雑なデータを用意するのは時間と手間が相当に掛かりますので、とりあえずは、初歩的なデータでご勘弁いただきたいと思います。
最初に、用意したPDFと、二つの製品による変換結果を一覧として紹介しておきます。なお、ここにご紹介する変換結果は、いづれも自動変換直後のデータであり、一切手を加えていないことを申し上げておきます。
■PDFからWordへの変換
(1)簡単な契約書の例

○オリジナルデータ
○「リッチテキストPDF3 D&D」によるWordへの変換結果
○「いきなりPDF to Data2」によるWordへの変換結果
(2)簡単な表の例
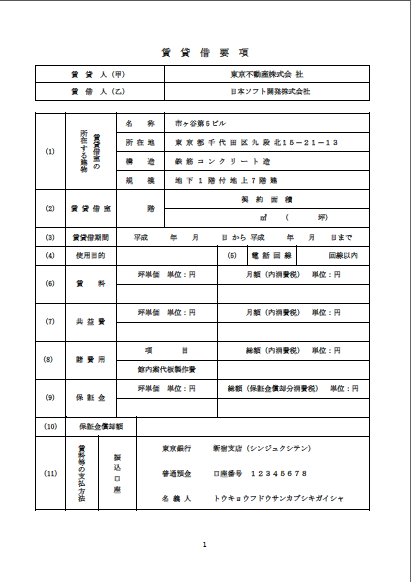
○オリジナルデータ
○「リッチテキストPDF3 D&D」によるWordへの変換結果
○「いきなりPDF to Data2」によるWordへの変換結果
(3)単純な縦書き文書の例

○オリジナルデータ
○「リッチテキストPDF3 D&D」によるWordへの変換結果
○「いきなりPDF to Data2」によるWordへの変換結果
(4)簡単な仕様書の例

○オリジナルデータ
○「リッチテキストPDF3 D&D」によるWordへの変換結果
○「いきなりPDF to Data2」によるWordへの変換結果
(5)文字の大きさや地の色の例

○オリジナルデータ
○「リッチテキストPDF3 D&D」によるWordへの変換結果
○「いきなりPDF to Data2」によるWordへの変換結果
(6)簡単な申請書の例

○オリジナルデータ
○「リッチテキストPDF3 D&D」によるWordへの変換結果
○「いきなりPDF to Data2」によるWordへの変換結果
■PDFからExcelへの変換
(1)簡単な表とグラフの例
○オリジナルデータ
○「リッチテキストPDF3 D&D」によるExcelへの変換結果
○「いきなりPDF to Data2」によるExcelへの変換結果
(2)簡単な財務諸表の例
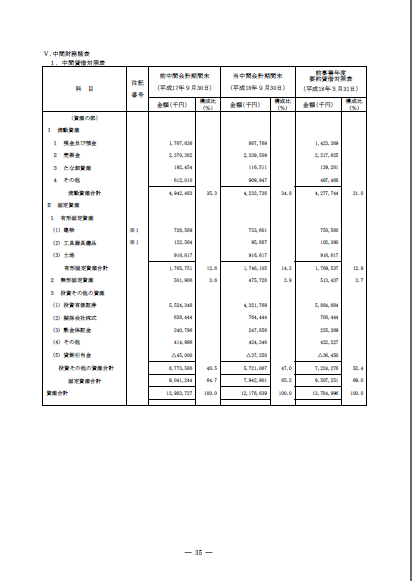
○オリジナルデータ
○「リッチテキストPDF3 D&D」によるExcelへの変換結果
○「いきなりPDF to Data2」によるExcelへの変換結果
(3)簡単な経費清算書の例
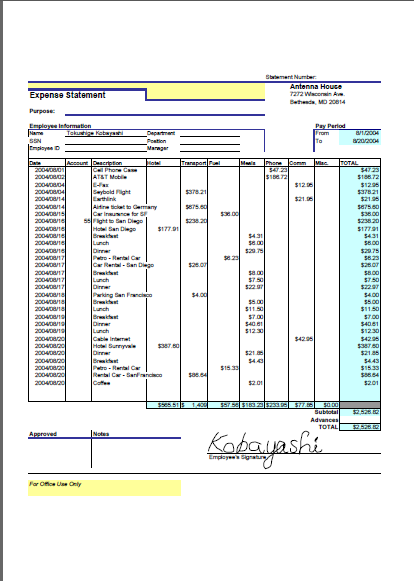
○オリジナルデータ
○「リッチテキストPDF3 D&D」によるExcelへの変換結果
○「いきなりPDF to Data2」によるExcelへの変換結果
【ご参考】
変換に用いたのは、「リッチテキストPDF3D&D」初版(日付2007/3/19)、「いきなりPDF to Data2」(日付2006/8/29)です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月26日
日本語組版はグリッドベースで行うと言って良いのか?(8)
CSSのページに、W3Cのリチャードイシダ氏が書いた、「Tutorial: CSS3 and International Text」という記事があるのを見つけました。
Tutorial: CSS3 and International Text
この文書は、前書きに「CSSの非ラテン・テキストのサポートに関し、将来どうなるかについて概略を知りたいと考えているXHTML/HTMLとCSSによるコンテンツ作者向け」とされています。このチュートリアルは、CSS3のドラフトを元にした解説を意図していると思われるのですが、この中に、ドキュメント・グリッドという項があります。簡単に紹介してみましょう。
東アジアの言語で書かれる文書では、グリフをページの上に配置するときグリッドのパターンにレイアウトするのが一般的である。これは、漢字、かな、ハングル文字が同じ幅をもつという事実によっても支援される。
CSS3では、グリッドを適用し、グリッドの中でラテンのテキストなどの全角でない文字を管理する方法について幾つかの属性を定義している。これらの属性によって、表意文字以外の文字に対してもCJK文字と同じようにグリッドを当てはめるかどうかを指定する。
次のスライドは、グリッドを当てはめないときの日本語の縦書きを示す。
http://www.w3.org/International/tutorials/css3-text/en/slides/Slide0170.html
l
さらに次のスライドは、前のスライドに対してあるグリッドの属性を当てはめたものを示す。
http://www.w3.org/International/tutorials/css3-text/en/slides/Slide0180.html
このスライドは、2007年02月27日 日本語組版はグリッドベースで行うと言って良いのか?(5)の10.2 line-grid-mode、10.3 line-grid-progressionの説明です。
以前として、この10.2 line-grid-mode、10.3 line-grid-progressionの意味が分かりません。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月25日
PDFからWord、Excel変換ソフトの評価 (3)
PDFからWord、Excel変換ソフトの評価の3回目の今日は、ちょうど、弊社の「リッチテキストPDF3 D&D」の販売を開始しましたので、「リッチテキストPDF3 D&D」での変換結果をご紹介してみたいと思います。
まず、「リッチテキストPDF3 D&D」の変換動作は簡単で、まず、変換先のファイル形式を設定します。
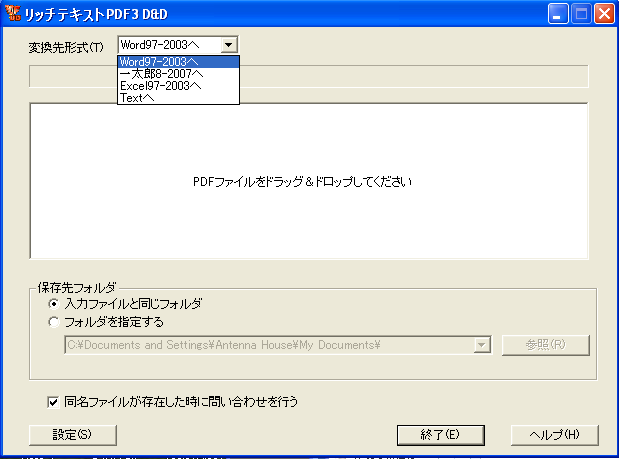
次に変換したいPDFをマウスでドラッグ&ドロップすれば変換が始まります。
ちなみに変換のオプション設定も簡単なオプション設定があります。上位版の「リッチテキストPDF3」ではさらに高度な変換設定ができますが、本製品では主要なものだけに限定しています。次の図のように、段組、表、線画、テキストボックスを使用してレイアウト優先で変換するかどうか、を設定できます。
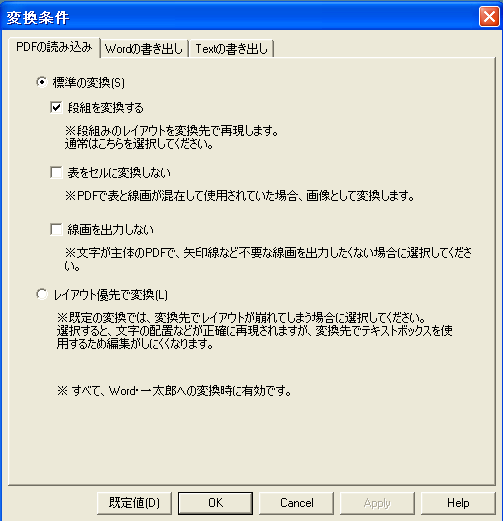
とりあえず、上の設定で変換してみました。
■PDFからWordへの変換
(1)簡単なWord文書
簡単な契約書の場合ですが、次の図のようにテキストボックスを使わずに段落を配置しています。こうすることで、Word文書として再編集がし易くなります。

さらに、先日の2007年03月22日PDFからWord、Excel変換ソフトの評価 (2)で取り上げました、PixelPlanet GmbHのPdfGrabber3.0と比較してみます。
●リッチテキストPDF3D&D

●PdfGrabber3.0
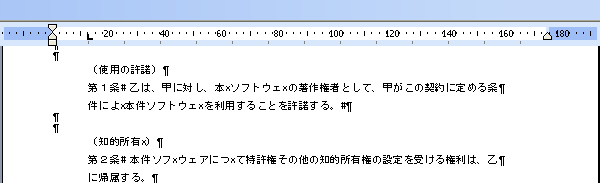
上の二つを比べてみて頂きますと、「リッチテキストPDF3D&D」の方は、左右インデントで段落配置を設定しており、段落内の文章は繋がっていることが分かります。これに対して、「PdfGrabber3.0」の方は、段落内を一行毎に改行で区切っていてしかも、タブで文字の位置を設定しています。従って、「PdfGrabber3.0」で作成したWord文章は再編集しにくいと思います。これに対して、「リッチテキストPDF3D&D」の方が文章の再編集はし易いはずです。
(2)EU文書の表
次に、EUの文書を変換して表の部分がどうなっているかを見てみましょう。

この図を見ていただきますとお分かりになると思いますが、「リッチテキストPDF3D&D」ではPDFの表を解析して、Wordのセルを使った表にしています。ですので、Wordで作成した表と同じように編集ができるようになります。これは、過去2回取り上げました、「Able2Extract 4.0」、「PdfGrabber3.0」よりは格段に優れていると言えるでしょう。
■PDFからExcel表への変換
最後に、ExcelからAcrobatでPDF化した帳票を元のExcelに変換してみました。
●元のExcelファイル(印刷プレビュー)

●変換結果のExcelファイル
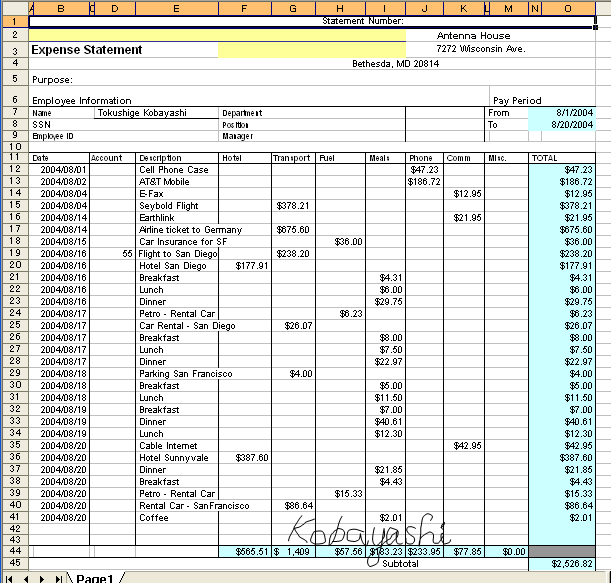
このようにほぼもとのExcelの表に近くなっています。「PdfGrabber3.0」でも大体できていましたが、「リッチテキストPDF3D&D」の方は、図形も変換できています(位置がずれているのが残念ですが)。このあたりは弊社製品の方が優れていると思います。
こうしてざっと比較した範囲内では、「リッチテキストPDF3D&D」は、海外の主要な製品と比較しても見劣りはしていないと言っても良いように思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月24日
リッチテキストPDF3 D&Dの販売開始
ベクターより、「リッチテキストPDF3 D&D」の販売を開始しました。本製品は、「リッチテキストPDF3」の中で、PDFからWord、Excel、一太郎、テキストへの変換エンジンを取り出して、ドラッグ&ドロップで変換を行うGUIから変換処理を行うようにしたものです。
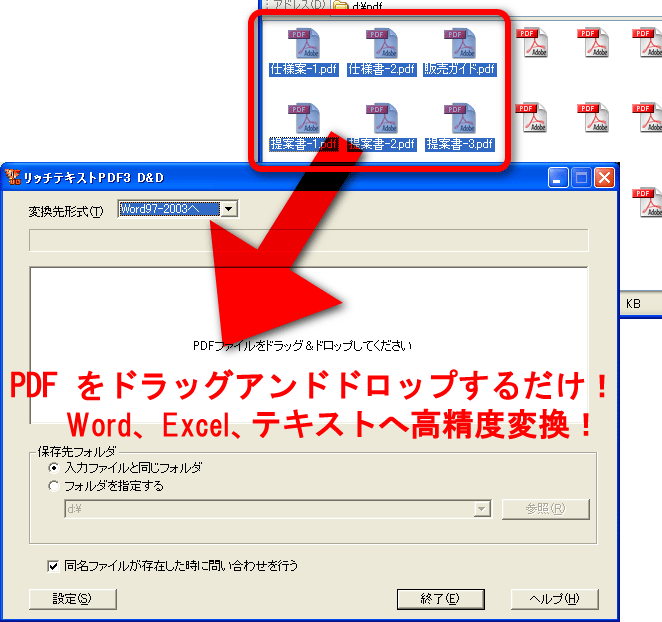
今回の目玉機能は、PDFからExcelへの変換の追加です。
また、Windows Vistaにも対応しました。
「リッチテキストPDF3」(フルセット版)との機能の違いは次の表の通りです。
| 機能 | リッチテキストPDF3 D&D 本製品 |
リッチテキストPDF3 Webページ |
|---|---|---|
| PDFからWord | ○ | ○ |
| PDFから一太郎 | ○ | ○ |
| PDF からExcel | ○ | ○ |
| PDF からText | ○ | ○ |
| PDF から画像 | × | ○ |
| 変換の詳細設定(余白、表領域、画像領域を対話的に指定) | × | ○ |
| PDFを作成する | × | ○ |
| PDFのページ編成(分割・結合) | × | ○ |
| PDFリニアライズ(Web最適化) | × | ○ |
| PDFのセキュリティ設定 | × | ○ |
旧製品「リッチテキストPDF2 D&D」からのバージョンアップは、差額の3,270円(税込み)となります。また、「リッチテキストPDF3」へのレベルアップは、弊社の登録ユーザの方々向けの優待販売価格(税込み5,000円)となります。
詳しくはこちらをどうぞ。
「リッチテキストPDF3 D&D」 Webページ
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月23日
テキスト抽出ソフト「TextPorterV4.2サーバ版」の出荷を各OS毎に順次開始
2007年3月19日より、テキスト抽出ソフト「TextPorterV4.2サーバ版」の出荷を各OS毎に順次開始いたしました。
**********************************
今回のバージョンアップのハイライト
Office2007, Acrobat8, 一太郎2007に対応いたしました。
**********************************
【「TextPorterV4.2サーバ版」の特長】
・主要なアプリケーション・ファイルからテキスト抽出します。
文書を作成したアプリケーションが無くても、指定したファイル、または埋め込まれたOLEオブジェクトからテキスト文字列を取り出せます。
指定したファイルの持つプロパティ情報の抽出、ページ指定の抽出ができ、ストリーム出力指定も可能です。
・主要なアプリケーション・ファイルの識別
ファイルを作成したアプリケーション名称とそのバージョンを識別します。
・さまざまな文字コードに対応しています。
抽出するテキストの文字符号化方式を切り替えることができます。また、テキストファイルの文字符号化方式や改行コードの種別を変換することができます。
・スレッド・セーフ版ですので、マルチ・スレッド・アプリケーションから呼び出して使用することができます。
・APIの互換を保っておりますので、新しいモジュールを差し替えればそのまま使用できます。
・全文検索、文書管理、データマイニング、セキュリティ管理等のアプリケーションへの組み込んでのご利用に最適です。
【V4.2で新たに抽出対象とした対応ファイルフォーマット】
・Office2007(Word2007, Excel2007, PowerPoint2007)
Office2007で、対応致します拡張子は次のとおりです。
・DOCX/DOCM/DOTX/DOTM
・XLSX/XLSM/XLTX/XLTM
・PPTX/PPTM/POTX/POTM/PPSX/PPSM
・Acrobat8(PDF1.7)
・一太郎2007
【商品概要】
・商品名
「TextPorterV4.2 サーバ版」
・動作環境
出荷中:
Microsoft Windows2000 Professional/2000Server/XP/2003Server(32bit)/Vista(32bit)
対応予定:
Microsoft Windows 2000Professional/2000Server/XP/2003Server(64bit)/Vista(64bit)
Sun SPARC 版Solaris 8/9/10(32bit/64bit)
x86版 Solaris10(64bit)
Linux gcc version 3.2.3 以上(32bit)(動作環境にlibstdc++.so.5が必要)
Linux gcc version 3.4.2 以上(64bit)(動作環境にlibstdc++.so.6が必要)
IBM AIX 5L version5.2 (32bit)(動作環境に VAC++6.0ランタイムライブラリが必要)
・対応インターフェイス
C インターフェイス
COM インターフェイス
Java インターフェイス
Perl インターフェイス
・メディア
CD-ROM(出荷中のものが含まれます。)
・ライセンス形態
通常ライセンス 標準価格:500,000円/1CPU より(税別)
デベロッパライセンス 標準価格:200,000円/1CPU より(税別)
*デベロッパライセンスは、開発用のシステムのみで使用することができます。実運用のシステムでは使うことができません。
*開発した製品を本製品と一緒に再配布する場合は通常ライセンスの購入が必要です。エンドユーザの方は開発したシステムを運用する場合、通常ライセンスを購入して頂く必要が有ります。
・出荷開始日
2007年3月19日
Windows32bitサーバ版から出荷を開始致しました。その他のサーバ版は随時、出荷を予定しております。
・バージョンアップ:
保守期間中のお客様には無料でV4.2をご提供致します。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月22日
PDFからWord、Excel変換ソフトの評価 (2)
次に、2007年03月17日PDFからExcel変換ソフトの3つ目に紹介しました、PixelPlanet GmbHのPdfGrabber3.0を試してみたいと思います。
この会社のWebページはメインがドイツ語ですが英語のページもあり、評価版をダウンロードすることができます。Web ページを見ますと、1996年からやっているようです。この道10年ですか。でも、アンテナハウスは、この道23年ですからキャリアじゃ負けません。
■PDFからWord変換
PDFからWord変換では、レイアウトを維持するモード、高い変換性、テキストフロー、多段のレイアウトという4種類のモードがあります。さらに、各モードでオプション設定が多々あります。このオプションのダイヤログは英語なのにドイツ語が混在していたりして意味が良く分かりません。
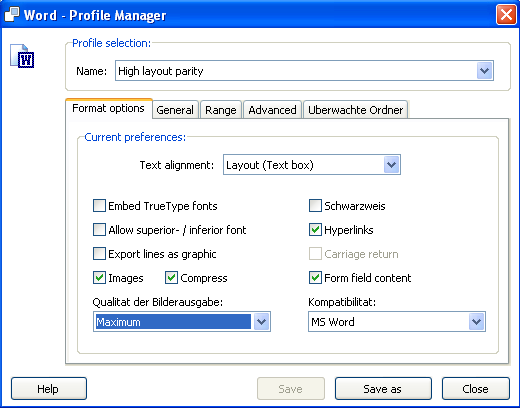
○レイアウトを維持するモードは、原則としてテキストボックス使いまくり変換です。このソフトの場合、酷いことに単語単位でテキストボックスを作ってしまうようです。但し、ページによってはテキストボックスを作っていないページもあり、ページのレイアウトを見てテキストボックスをどの程度作るかを決めているのかもしれません。
○次にテキストフローを選んで変換します。すると、次の図のように1ページ毎にテキストを完全につなげてしまいます。これは、一種のテキスト抽出に相当する機能と言えます。

○次の変換性はどうでしょうか。変換結果を見ますとテキストボックスは使わずに一応それなりのレイアウトになっています。

詳細にみますと、どうも1行単位でタブを使ってレイアウトを調整しているようです。次の図をご覧ください。Wordのルーラを見ますと、余白が取られていますが、本文開始位置にタブ位置が設定されていて、各行の先頭がタブ設定位置から開始されています。
このような文書の作り方はやはりあまり編集しやすいものではないと思います。
さて、この同じ変換性のオプションを選択して、昨日のEUの文書を変換して、表の部分を見てみますと、このコンバータで作成した表も、一見、レイアウトが完全に再現されているように見えますが、表のボーダー部分が全部図形(オートシェイプ)になっています。しかも、グループ化されていません。
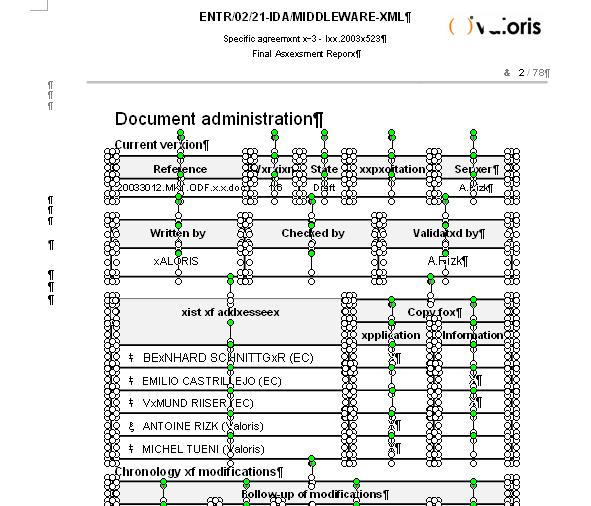
■PDFからExcel変換
次に、簡単なPDFの表をExcelに変換してみました。
使用したPDFは昨日の例と同じです。
変換結果をご覧ください。
○レイアウトを維持するモード
次のように、Excelのセル幅とセル結合を使って、かなり高いレイアウト再現性ができています
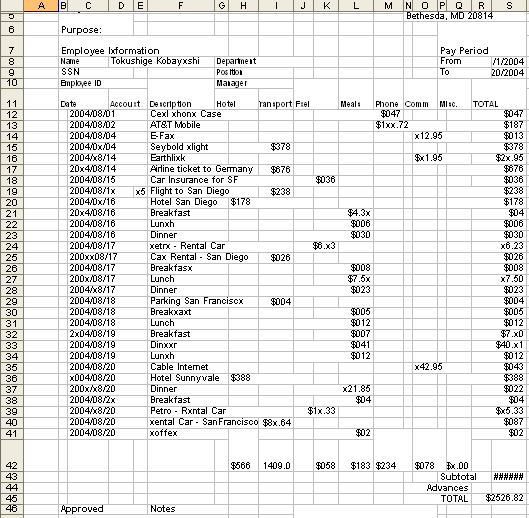
○変換性モード
このモードでは、次の図のように行方向のセル結合を使っていないので、さらにExcel的な表になっています。ざっくり言ってかなり良い出来のように思います。

このソフトのPDFからWord変換はあまりお勧めできません。しかし、PDFからExcel変換はそこそこ使えそうに思います。(但し、メニューがドイツ語なので日本で使うのはあまりお勧めできません。)
【ご注意】PdfGrabber3.0の評価版では、変換後の文字列にXをランダムに挿入してしまいます。このため、評価版だけでは日本語の文字列が正しく変換できるかどうかは判断できません。上のキャプチャは、どのような変換をしているかを判断するためのみにご活用ください。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月21日
PDFからWord、Excel変換ソフトの評価 (1)
先日、3月17日にPDFからExcelに変換するソフトとして、幾つかリストアップしてみました。
折角ですので、海外のこうしたソフトが、どの程度の実力か、すこし試してみましょう。まず、最初に、INVESTINTECHのAble2Extract 4.0です。これは7日間の試用版があります。これをダウンロードして試してみました。このソフトは、PDFを読み込んでビューアで表示し、変換する範囲を対話的に指定できるようになっています。最初に例によって、いつも使用している、「敦賀市物品等競争入札参加資格審査申請書提出要領(建設工事を除く。)」を読み込んでみました。しかし、次の図のように正しく表示されません。どうやら、日本語のPDFはうまく表示できないようです。
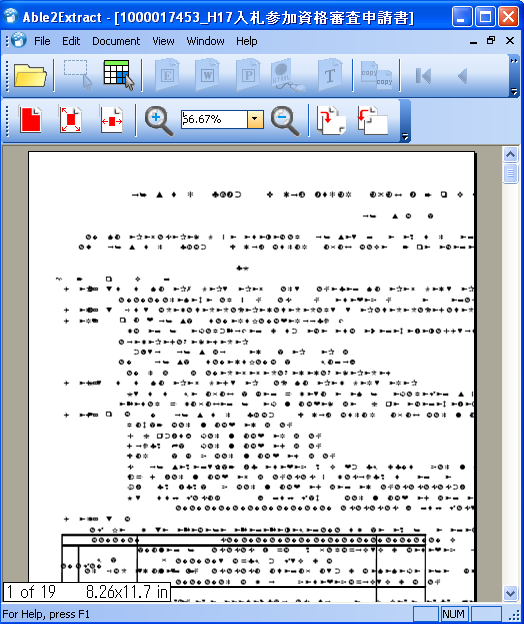
そこで、英語のPDFで試してみました。
■PDFからWordへの変換
EUの「Comparative assessment of Open Documents Formats Market Overview」という文書ファイル形式についてのレビュー文書(PDF形式)をWordに変換してみました。試用版では、変換できるページは1文書について3ページのみです。
PDFをWordに変換しますと、次の図のように表もかなり綺麗にWord文書になっているように見えます。
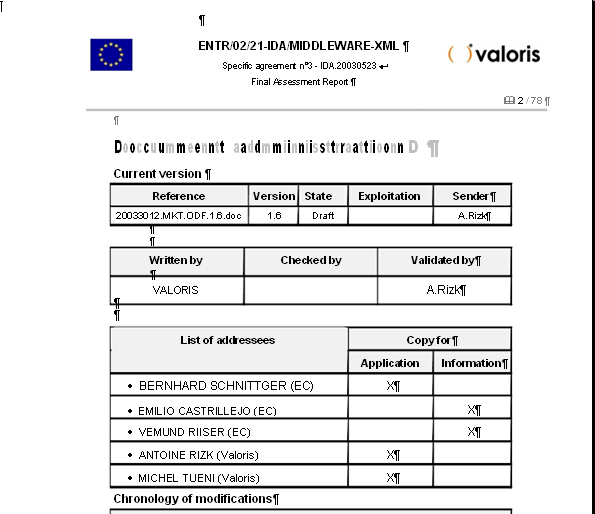
しかし、罫線を選択して移動しますと、あれれ!!表の中と罫線がずれてしまいます。このコンバータもPDFの表の罫線をセルにしないで、画像にしてしまっているんですね。

■PDFからExcelへの変換
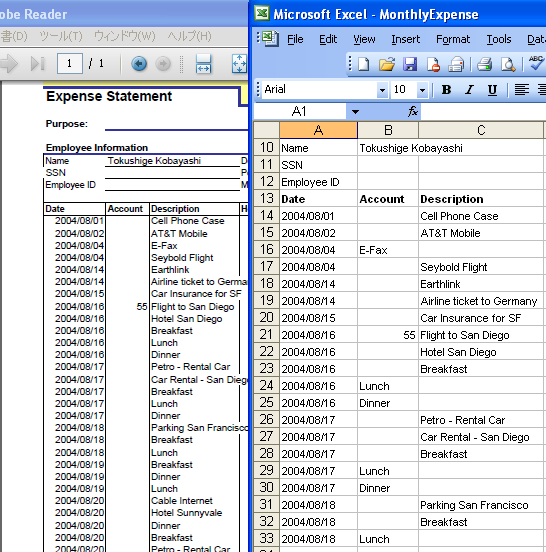
次に簡単な表のPDFをExcelに変換してみます。
○オリジナルのPDF: ファイルをダウンロード
○変換結果:一部の画像をみますと次のようになります。この表は縦線でカラムが区切られているにも関わらず、このコンバータで変換したExcelは、正しい欄に文字が入らず、欄ずれをおこしていることが分かります。
結局、このAble2Extract 4.0もあまりお勧めできるものではないように思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月20日
PDF Viewer SDK の利用例 — PDFを画像のように取り扱う
PDF Viewer をアプリケーションに組み込んだ例として、XSL Formatterを紹介してみたいと思います。
アンテナハウスのXSL Formatterでは、PDFを画像ファイルの一つの形式として、次のような利用ができます。
1.PDFを画像ファイルの一種として、EPSなどと同じように扱う。
2.PDFのページの全画面の背景画像として利用する。
3.既存のPDFと新たに組版したページを結合して新しいPDFを作る。
1.3.の機能につきましては、2006年12月10日XSL Formatter V4.1 の新機能ご紹介でお話しました。従来であればEPS(Encapsulated Postscript)形式で埋め込んでいたイラスト図形などをPDFで埋め込むことができます。そして、この埋め込まれたPDFをXSL FormatterのGUIで表示して確認することができます。
2.の機能につきましては、2007年02月21日 雛形PDFにデータを差し込みして、新しいPDFを作成でお話しました。
今日は、こうして組み込みしたPDFをXSL FormatterのGUIで表示できることをご説明したいと思います。
例として予め次のようなPDFを作成し、それをページの一部に埋め込んでみます。
○埋め込みしたい画像としてのPDF:ファイルをダウンロード
○XSL-FOで画像を埋め込む部分のFO
<fo:flow flow-name="xsl-region-body" font-family="sans-serif" font-size="20pt">
<fo:block >
PDFをページの一部に取り込み。
</fo:block>
<fo:block>
content-height="50%"</fo:block>
<fo:block border-style="solid" border-color="rgb(255,0,0)">
<fo:block>
<fo:external-graphic src="Comparison.pdf" content-height="50%"/>
</fo:block>
</fo:block>
<fo:block space-before="2em">
content-height="30%"</fo:block>
<fo:block border-style="solid" border-color="rgb(255,0,0)">
<fo:block>
<fo:external-graphic src="Comparison.pdf" content-height="30%"/>
</fo:block>
</fo:block>
</fo:flow>
○上のFOを組版して、XSL FormatterのGUIで表示したところ
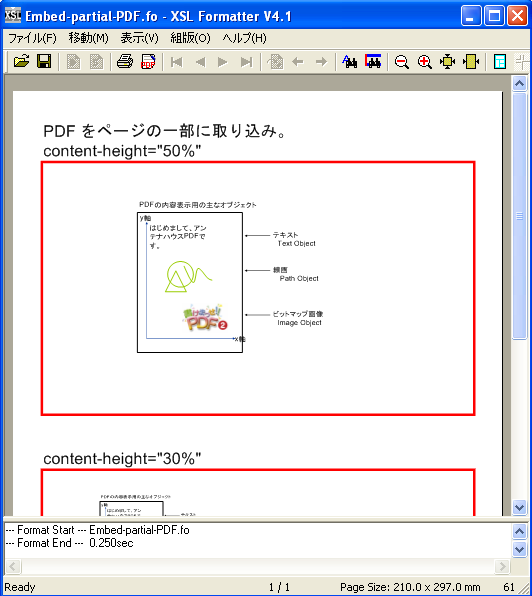
このように、PDFをEPSなどの画像ファイルの代わりに使うことができ、そして、それを画面に表示して確認することができます。この画面表示には、PDF Viewer SDKを使用しています。
○上の組版結果から出力したPDF
念のために、上の組版結果をPDFに出力してみますと、次のようになります。
ファイルをダウンロード
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月19日
PDF Viewer SDK 1.4をリリース
PDF表示機能をアプリケーションに組み込むための開発キット「PDF Viewer SDK」がV1.4になりました。
ご承知のようにPDFには次のようなハイパーリンク機能を埋め込むことができます。
・PDFの内部へのリンク
・外部のファイルへのリンク
・外部のuriへのリンク
V1.4 では、これらのPDFのリンクをたどるための関数を追加しました。
なお、これらのハイパーリンクはPDFの仕様ではリンク注釈として定義されており、PDFの仕様におけるリンク注釈は、ハイパーリンクを含む様々なアクションを定義することができます。この中で、PDF Viewer SDKに追加したのは、上のようなハイパーリンクを行うための機能のみですので、リンク注釈の機能全体から見ますと、2割くらいにあたると思います。
まだ先が長いといいますか、実際のところ、なぜ、PDFの仕様では、こんなに沢山の機能を定義しているのか、本当に必要なのか理解に苦しみます。
PDF Viewer SDKを開発する理由については、以前に説明しました。
なにか、PDFに関係する製品を作ろうとしますと、PDFを表示する機能が必要になります。そうしますと、PDFを表示する機能を、自力で開発するか、Adobeまたは他の会社から調達するかのどちらかが必要になるでしょう。
日本の多くの会社はPDFを画像に変換してしまって、画像としてPDFを表示しています。しかし、それでは処理速度も限界がありますし、その後、表示したデータを使って再びPDFを作るとき困ることになるでしょう。
そんなわけで、PDF Viewerの必要性はますます高まっています。既に、弊社の製品では次の製品にPDF Viewer SDKを使ってPDFを表示する機能を組み込んでいます。
・リッチテキスト・コンバータ
・自在眼
・リッチテキストPDF
・書けまっせ!!PDF
・アウトライナー
・XSL Formatter
・自在眼SDK
ご覧いただくとお分かりの通り、弊社のほとんど全ての製品でPDF表示を行っており、現在、PDF Viewer SDKが最重要コンポーネントの一つになっています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月18日
「書けまっせPDF2Vista対応版」のご紹介
「書けまっせ!!PDF2Vista対応版」の紹介記事が、MYCOMお助けソフト物語に紹介されています。
めんどうな紙の書類の書き直しにお別れ!デジタル書類に直接書けるPDF活用ツール (1)
いちば~ん最後の方に小さく(MYCOMジャーナル 広告企画)とクレジットが入っていますが、これは広告企画による記事ですが、分かりやすく製品の紹介がなされていると思います。
インターネットを通じての広告モデルとして、グーグルのようなクリック課金と比べて、こういう製品紹介を行うモデルも地味ではありますが、広告主にとってはありがたいものです。
以前にも書きましたが、昔はグーグルにかなり広告を出していましたが、2005年ですっぱり足を洗って以来、弊社は、グーグルには一切広告を出していません。
※なぜグーグルの広告を止めたかは、「PDF千夜一夜」の73話~77話をご参照ください。
ところで、WikipediaのPDFの項の履歴(下記)を見てましたら、
http://ja.wikipedia.org/w/index.php?title=Portable_Document_Format&action=history
このところ、http://www.freepdf.8m.com/を関連リンクに追加、削除、追加、削除が繰り返されてます。http://www.freepdf.8m.com/には無償のPDF'ソフトの一覧が乗っていますが、このリストの作者の意図は、グーグルからのクリック収入と思います。で、きっとWikipediaのPDFに自分のリンクを登録しようとしてシステム(管理人?)に拒絶されてるのではないでしょうか。ご苦労なことです。
インタネットにはグーグルのアドセンス・クリック収入を狙った、こういうページが一杯あります。しかし、私達広告主にとっては、無償ソフトを探す人を相手に商売するのは無理でしょう。つまり、無償ソフトを探している人は、対価を払いたくないのが動機ですから、有償ソフトを買う行動には繋がり難いのではないでしょうか。ですので、http://www.freepdf.8m.com/ページの広告から来たクリックは、広告主にとっては恐らく売上げには繋がらないだろうと思います。広告を出すときはそういう心理・仕組みをよく考えて注意しないと、広告費はまるで砂漠に水をまくように消えてしまいます。
こういう事情も弊社がグーグルのアドワーズ広告を出したくない理由の一つです。Linux=オープン・ソース関連の雑誌になかなか広告が入らないのも同じような事情があるのではないでしょうか。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月17日
PDFからExcel変換ソフト
以前に、米国製のPDFを解析してOfficeに変換するソフトにはPDFからExcel変換を行うものがない、とお話しました。
2007年03月08日PDFからWordとExcelに変換するソフトで一覧にしましたが、日本で売られている米国製変換ソフトはAdrobatを初めとして、PDFをWordに変換するものばかりです。しかし、本当にPDFからExcelに変換するソフトはないと言って良いのでしょうか?少し気になっています。ということで、もう少し調べてみました。Googleで検索しますと、全然無いわけではないようです。
まずは、リストアップしてみましょう。
○INVESTINTECH
Able2Extract 4.0 — 説明のイラストをみますと、PDFからWord, Excel, Powerpoint, HTML,テキストへの変換ができます。ダウンロード版はUS$89.98です。
Able2Extract 4.0Professional — スキャナで作成したPDFを変換できます。ダウンロード版がUS$119.95です。
この会社は結構PDFに力を入れているようです。要調査です。あとで評価版をダウンロードしてみましょう。
○Cogniviewニューヨークが本社らしく見えますが、イスラエルの会社?
PDF2XL — ダウンロード版はUS$95.00
PDF2XL — OCR(スキャナで作成したPDF)ダウンロード版はUS$129.00
PDF2XL Enterprise — ダウンロード版はUS$169.00
この会社はPDFからExcel変換に注力です。
○PixelPlanet GmbH (ドイツの会社?)
PdfGrabber Standard — PDFからWord, Excel, PPT など 66.39ユーロ
PdfGrabber Professional — PDFからWord, Excel, PPT, AutoCAD など 105.04ユーロ
ざっとみたところ、この3社が結構充実しているように見えます。
アンテナハウスもそろそろ「リッチテキストPDF」の英語版を作って、海外市場に殴りこみ!と思っていますが、結構沢山ライバルがありそうです。もう少し、敵の研究が必要なようです。でも、救いは、価格が1万円前後になっていて日本のようにダンピング価格になっていないことです。税込み1,980円はやはり国際的に見ても異常に安いのではないでしょうか?
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月16日
XSL Formatter用のWeb Service Interface V2.0を発売
アンテナハウスは、3月15日より、XSL Formatter V4.1用のWeb Service Interface V2.0を発売しました。
本製品は日本語版と英語版を同時に発売しています。
Web Service Interface V2.0日本語版のWebページ
Web Service Interface V2.0英語版のWebページ
XSL Formatterは、XML+XSLをPDFにするためのソフトウエアです。多くの場合、サーバ上で自動組版を行うために使われます。但し、XSL Formatterのサーバライセンスのみですと、サーバ側の自動組版システムのプログラム開発が必要となります。
Web Service Interface を使うことで、サーバ側のプログラム開発が必要なくなり、次のように簡単に、1台のサーバ上のXSL Formatterの組版機能を多数のクライアントから使うことができるようになります。
(1)サーバ用のコンピュータにXSL Formatterサーバ版をインストール
(2)同じコンピュータに、Web Service Interface のサーバサイド・モジュールをインストール
(3)(複数の)クライアント用のコンピュータにWeb Service Interface のクライアントサイド・モジュールをインストール
これで、複数のクライアントからサーバ側のXSL Formatterの組版機能を共有できるようになります。
さらに、今回のWeb Service Interface V2.0から、フォルダ監視サービス機能が新規追加になりました。
フォルダ監視機能は、変換元フォルダを設定(複数も可)しておくと、該当フォルダを定期的に監視し、新しい変換対象ファイルがフォルダに放り込まれたことを検出します。そして、検出したファイルをサーバに送って、PDFに変換します。変換が終了したら、指定した変換先フォルダにPDFを移します。
V1.0では、監視フォルダ機能がありませんでしたので、クライアント側からサーバ側にマニュアルでデータを送る必要がありました。V2.0からは、変換元フォルダにXML+XSLを放り込むだけで、変換先のフォルダにPDFが出来あがることになり、システムを作って使うことがさらに簡単になります。
このような、フォルダ監視の仕組みは、多くの自動組版システムに用意されており、特に目新しいものではありません。これに対して、本Web Service Interface V2.0の特徴は、クライアントとサーバ間の通信をSOAP/HTTPという標準のWeb Serviceプロトコルを使っていることです。これにより、インターネットに接続されたサーバ上のXSL Formatterの機能をファイアー・ウオールを超えて、遠隔地から利用するようなシステムを簡単に構築できるようになります。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月15日
XMLによる法制システム — ニュージーランドPALのケース
先日のOpen Publishで、XMLによる法制システムのとても興味深い報告がありました。このことは、
2007年03月10日Open Publish Conference — XML オーサリングで少し触れたのですが、Webで調べてみましたところ、ニュージーランドでは、法律を公衆に公開するシステム(Public Access to Legistlation)の大掛かりなプロジェクトが進んでいるようです。
ところがこのプロジェクトが、途中で大幅に遅延し、開発費が大幅増になって、問題になったのですね。このプロジェクトは、2003年2月から運用を開始する予定だったようですが、いろいろ問題があり、2003年~2004年は停止、結局、2005年に復活、しかし2006年の秋現在ではまだ完成していません。Web上では2007年央から稼動の予定となっています。
プロジェクトを行っているのは、議会書記局です。システム開発はUnisys。議会書記局のWebページにプロジェクトの経費がどうなったのか、ということまで様々な情報が公開されています。この情報公開の姿勢は日本政府もぜひ見習って欲しいものです。
Parliamentary Counsel OfficeのWebページ
Public Access to Legislation Project
まだ、全ての情報を詳しく読んでいないのですが、このシステムは立法のための草稿から完成までをXMLで行うもののようです。
政府レベルの話なのでかなり大掛かりなものですが、ケーススタディとしてもなかなか興味があります。
XML編集システムは、PTC/ArborTextのEpicEditorを使い、組版はFOSIを採用、ArborTextのPrintComposerを使おうとしたようです。
ところが、システムのパフォーマンスに大きな問題がありました。大勢の人が懸念をもち、外部のコンサルタントに依頼してシステムについて技術レビューを行っています。
Final Report—New Zealand PCO Technical Assurance Review(技術レビュー)
特にFOSIの複雑さ、メンテナンスの悪さ、パフォーマンスの悪さが問題のようです。
6.2.2 Epic Print Composer—the Print Rendering Tool
には、PrintComposerのパーフォーマンスの悪さが書かれています。
誰か他の人が大きなBillを作っていると、20分も待たされると。
結局、組版エンジンがかなり大きな問題になったようで、組版エンジンだけで次のレポートがあります。
Rendering Engine Review—Final Report(組版エンジンの評価レポート)
ここで評価の対象になっているのは、
3.1 ArborText E3 (ADG)
3.2 XyVision XPP (XyVision or ADG)
3.3 Advent Publishing 3B2 (Allette Systems)
3.4 Elkera XML Print (Elkera)
でXSL-FOは残念ながらまだ代替候補になっていません。将来は、XSL-FOに変わるかもしれない、というような書き方です。2004年にしては感度が鈍すぎると思いますが。アンテナハウスのXSL Formatterを選んでいれば、プロジェクトがこんなに難航しなかったのではないか、と言ったらいい過ぎでしょうか。
2000年に、実装協力者を募集していますので、XSL-FOには少々早すぎたのかもしれません。しかし、2004年の再評価には立候補するべきでした。知っていれば!!ニュージーランドまで行ったのですが、残念です。
XSL Formatterは国レベルの立法システムでは、カナダ政府で2000年代前半から使われています。カナダでは、英語とフランス語で翻訳ではなく、平行して法律を作るようです。やはりニュージーランドよりはカナダの方が進んでいる?
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月14日
「リッチテキスト・コンバータ19」と「リッチテキストPDF3」の機能比較
アンテナハウス製品の中で、「リッチテキスト・コンバータ19」と「リッチテキストPDF」は、いづれも、機能の中核が文書変換となります。そのため、名称も似ていて、また、機能の違いもやや分かりにくくなってしまっているかもしれません。
そこで、次の図に主にPDF関連機能の面での、両者の違いを簡単に示してみました。
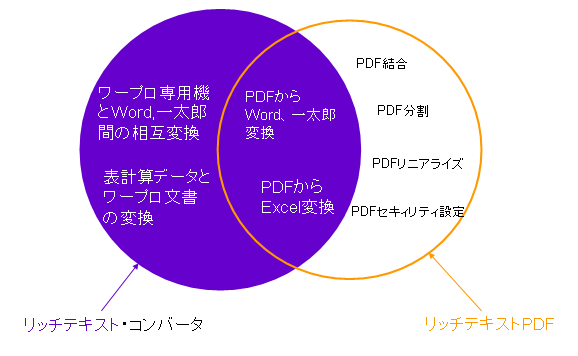
両方に共通する機能は、(1)PDFからMicrosoft Wordと一太郎への変換機能、(2)PDFから画像とテキストの取り出し機能、(3)PDFからMicrosoft Excelへの変換、(4)Antenna House PDF Driverのドライバを利用してアプリケーションからPDF出力機能の4項目となります。
「リッチテキスト・コンバータ19」の方は、上の(1)~(4)に加えて、ワープロ文書(専用機、ソフトトウェア)同士の変換、ワープロ文書から表計算への変換を行う機能があります。また、文書ビューアなどの文書変換用のツールが幾つかついています。
「リッチテキストPDF3」の方は、上の(1)~(4)に加えて、既存のPDFの分割・結合、既存のPDFのWeb最適化、同セキュリティ設定などのPDF処理専用のツールが付いています。
二つの製品で共通の機能が多いので、どちらにしようか迷われる方が多いかもしれません。
この二つの製品では、「リッチテキストPDF3」の方が、割安な価格設定になっていますので、もし、今後はPDFとMicrosoft Office(Word,Excel)間の変換のみをご利用になる見込みの場合は、「リッチテキストPDF3」をお使いいただければと思います。なにとぞ、よろしくお願いします。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月13日
リッチテキスト・コンバータ19を近く発売
アンテナハウスでは、ワープロ文書ファイル変換ソフト「リッチテキスト・コンバータ」シリーズの最新版として、「リッチテキスト・コンバータ19」を3月末から4月初旬に発売する予定です。
「リッチテキスト・コンバータ19」は、ワープロ専用機、パソコンのワープロソフト、PDF・HTMLなどの標準ファイルの相互間の文書変換を行うことができます。旧バージョンは、「リッチテキスト・コンバータ2005R3」という名称でしたが、次から、初心に帰って、製品名称につけるバージョン番号を初版からの通算バージョン番号である「19」に戻すことにしました。
新しいバージョンは、Windows Vistaで動作するようになります。また、一太郎2007のファイル形式、PDF1.6などの新しい形式の変換サポートを追加しました。
「リッチテキスト・コンバータ」の最初のバージョンの発売は1990年です。初版はNECのPC9801のMS-DOSの上で動くものでした。その後、DOS/V、Windows3.1、Windows95、WindowsNT/Windows2000、WindowsXP、WindowsVistaとMicrosoft社の歴代のOSをサポートした製品を順次出してくることができました。これはひとえに多くのお客様に使っていただくことができたからです。
改めて、「リッチテキスト・コンバータ」をお使いいただいた多くのお客様に、心から感謝したいと思います。日本では、既に、ワープロ専用機のメーカが全て撤退してしまい、あと数年でワープロ専用機のユーザはいなくなるものと思います。弊社では、ワープロ専用機の最後の一人のお客様まで継続してサポートを続けていきたいと考えています。
また、今後は、PDF変換などのサポートをさらに強化していきたいと考えていますので、ご支援のほど、よろしくお願いします。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月12日
Softinterface "ConvertDoc"
先日、PDFからWord、Excelへの変換ソフトのことをお話しました。
2007年03月08日PDFからWordとExcelに変換するソフト
そこで、Softinterfaceの"ConvertDoc"について評価してみて欲しいというコメントをいただきました。Softinterfaceは1999年から変換ソフトやファイル比較ソフト製品を作って販売しているようです。以前にも何回か社内的に変換ソフトの評価対象としてチェックしたような記憶があります。最近では、Microsoft OfficeからPDFに変換する「サーバベース・コンバータ」の英語版を出す際に競合製品として調べたと思います。Microsoft Officeを使わずに、Office文書をPDFに変換するソフトは、世界的にみても比較的種類が少ないのですが、その競争相手の一つとして評価しました。その時の記憶では、はっきり申し上げて、スカタンなソフトと思いましたけれども。
PDFからOfficeへの変換ソフトとしては、評価したことはありません。これは要チェックです。早速、調べてみましょう。
まず、ConvertDocの特徴は、かなりいろいろな方向へのファイル形式変換ができるということです。そういう意味では、弊社の製品で言いますと、「リッチテキスト・コンバータ」に近いと思います。
ConvertDocでは、PDFからWord文書、HTML、テキストに変換できます。なお、Excelに変換する機能はないようです。先日のコメントでも、価格が高いとありましたが、価格は次のようになっています。
デスクトップ基本ライセンス料金が、$499ドルです。但し、これでは、PDFからWord変換できません。PDFからWordへの変換(厳密にはPDFからRTFへの変換)をプラスしますと$549.95です。これだけですと、将来のアップデートはなしです。さらに将来1年間のアップデートを追加しますと、$679.90となります。念のために申し添えますと、アップデートとはバグ・フィックス版の提供です。バージョンアップは、アップグレードと言います。で、バージョン・ヒストリを見ますと、”COM interface was broken since v3.83”なんてのがあります。6ヶ月もCOMインターフェイスが動かなかったようです。アップデートなしだと修正版をもらえないとしたら、結構悲惨ではないでしょうか?
さて、ダウンロードして試してみました。まず、良い点は、最初にメニューとしてかなりいろいろな言語を選択できることです。日本語のメニューも選ぶことができます。これは素晴らしいですね。変換テストですが、以前に、「2006年10月01日PDFからWordへ 3つの変換ソフトを無慈悲に比較する(1)」で使いました、「敦賀市物品等競争入札参加資格審査申請書提出要領(建設工事を除く。)」を試してみました。
ConvertDocでは、詳細設定ダイヤログで、Word文書の作成方法を次の3つから選ぶことができます。
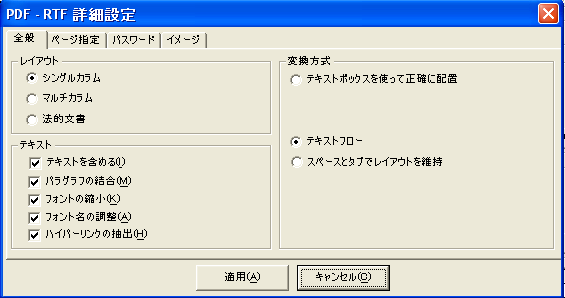
1.テキストボックスを使って正確に配置する
2.テキストフロー
3.スペースとタブでレイアウトを維持
この中で、1の方式は、テキストボックスを使いまくってPDFのレイアウトをWordで再現する方式です。「いきなりPDF to Data」や「速攻!PDF to Data」などのOCR生まれのソフトが行っている方式です。「PDFからWordへ 3つの変換ソフトを無慈悲に比較する」の時にも批判しましたが、私にはWord文書を作るのにテキストボックスを使いまくる理由がまったく理解できません。こんな変換に価値はないと思います。
2のテキストフローは、テキストを取り出す機能のようです。但し、RTFになりますので、Word文書としてのページ書式は付加されます。表の罫線などは消えてしまいます。良い点は、結構、変換速度が速いということしょうか。
3.スペースとタブでレイアウトを維持が一番評価に値するように思います。変換してみますと結構高速です。但し、出来上がったファイルサイズが異常に大きいですね。
オリジナルPDF: 153KB
ConvertDoc(RTF): 8950KB(約60倍)
(ご参考:「リッチテキストPDF2」では、470KBのDOCファイルになります。)
さて、変換結果をチェックしてみます。
用紙サイズは、A4、上下左右余白はそれぞれ、18.6mm、21.2mm、13.5mm、23.6mmに設定されています。また、ヘッダ・フッタ領域を12.7mmに設定。余白をきちんと取っていますし、ヘッダ・フッタ領域を取っているところは良いと思います。
また、1~2ページにテキストボックスが一つもなく、インデントとタブで文字の桁位置をセットしています。このあたりはやるな、という感じですが、但し、細かく見ますと文字の位置が正しくセットされずに、余分な改行が入ったりしてずれてしまっています。この結果、次図のようにPDFの1ページ目がWordでは2ページになってしまっています。

それからConvertDocの最大の問題点は表でしょう。全ての表の罫線が画像として変換されています。表のテキストが表のセル内の文字として認識されずに、本文テキストとなっていて、画像に変換した罫線を上に貼り付けています。結局、このソフトではPDFの表を表として扱うことができていないということになります。表を扱いたい方にはまったくお勧めできません。
そんなことで、結局、このソフトはテキストだけのPDFをWordに変換するなら使えますが、それ以外の用途ではあまり使えないと思います。
変換結果のWord文書をアップしようと思いましたが、ZIPで圧縮してもファイルが大きすぎでエラーになってしまいました。
※評価したConvertDocはVersion4.04です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月11日
米国連邦政府系のE-Form(電子フォーム)サイト
米国では、政府系のフォーム(様式)を一箇所に集めたWebサイトがあります。これは随分昔からやっているようですので、既に、ご存知の方も多いかもしれませんが。
Foms.gov
「副題に米国政府の連邦フォームのための公式ハブ」とあります。
Q&Aを見ますと、全ての政府機関を網羅してはいないとのことですが、2007年3月10日現在で5400種類以上の企業向け・市民向けのフォームを収録している、とあります。
アンテナハウスでは、先日、「書けまっせ!!フォーム」を公開しました。この「書けまっせ!!フォーム」のアイデアを検討しているとき、日本の官庁のWebページのフォームをいろいろ調べてみました。日本では、電子政府のWebページはありますが、各官庁のWebページへのリンク集です。政府機関を横断してフォームを集めたサイトはないようです。ですので、米国には、こういう横断的なサイトがあるというだけでも、日本の縦割り行政との違いを感じます。
Foms.govでよく使われるフォーム順のところでは、税金関係がトップに上がっています。日本でも恐らく税金関係が多いのではないかと思いますが。
ところで、このフォームのPDFを見てみますと、データを入力するところに、「フォームフィールド」が設定されています。
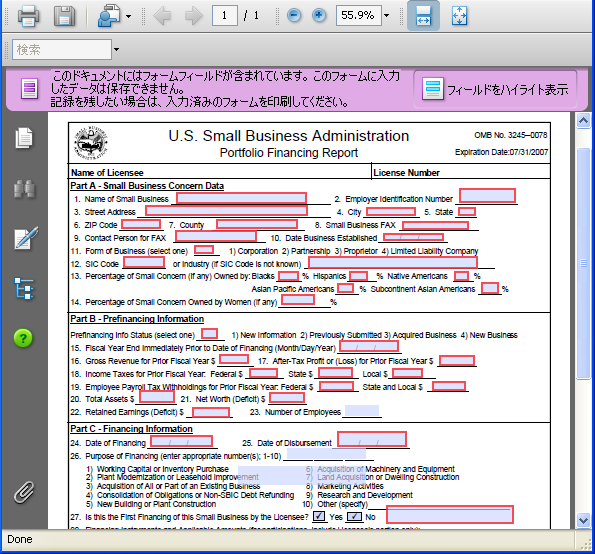
日本で官公庁が配布しているPDFにフォームフィールドが設定されているのは見たことがありません。さすが、PDFの利用が進んでいる、というべきでしょうか。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月10日
Open Publish Conference — XML オーサリング
Open Publishは、オーサリングのトラック、コンテンツ・マネジメントのトラックの二つのトラックで開かれていました。この会議は出版業界を対象にしているようです。出版においてどのようにコンテンツを作成・管理して、コンテンツを多重利用するか、という日本でもおなじみのテーマです。
プレゼンテーションを行っている人の大半は、どうもXML関係のコンサルタントのようです。
私は、オーサリング・トラックをずっと聞いていたのですが、人気があるテーマのときは、聴衆が集まりますし、あまり関心がないテーマでは、聴衆が少なくなります。聴衆の数の変化からは、オーサリング・トラックでは、ODF(Open Document Format)とMicrosoft Office 2007のXML形式についての話題に関心がもたれたようです。多分、これは、日本と同じでしょう。
アンテナハウスでも、ある会社のためのMicrosoft WordでXML(マニュアル)を編集・組版するシステムを作っています。そんなこともあり、Mark Jacobsonの「Microsoft WordでXMLをオーサリングする実際の話」には関心がありました。このプレゼンは今日のプレゼンの中では参加者が一番大勢集まりましたので、参加者の間でも関心を集めたようです。
この話の内容は、次のようなものです。
(1)Word97/2000時代には、RTFをXMLに変換するシステムを作った。
(2)Word2003でWordMLで保存できるようになり、RTFの代わりにWordMLを使うことで、XMLからXML変換で済むようになり楽になった。
(3)Word2007では、WordMLが標準のフォーマットとなった。
(4)しかし、Word2003もWord2007もカスタムXMLのサポートは中途半端、ユーザ・インターフェイス(GUI)は、XML編集には向いていないなど、XMLエディタとして使うには向いていない。
(5)Wordのスタイルは平坦なので、ネストした構造をWordのスタイルで表すことができないし、属性の入力、混合内容(Mixed Content)を編集するのは非常に難しい、など。
ざっくり言って、私達も経験で知っているのと同じような内容で、あまり目新しさは感じませんでした。
あとは、立法(legislative)に関するオーサリングと出版についてのプレゼンが二つありましたが、こちらは、両方とも実際の地方自治体でのシステムのデモもあり、なかなか面白いものでした。XSL Formatterは、米国の州政府・カナダ政府の法律出版システムなど、法律の出版物の作成に使われている例がいくつもあります。今日のプレゼンテーションを聞いて、なぜ、法律のシステムにXMLが向いているかが理解できました。
今日は、6つ(6人)のセッションを聞いただけなのですが、その講演者でXSL Formatterのユーザが2人いました。XSL Formatter=XSL-FOの代名詞とまでは行きませんが、これは、なかなかの数字ではないでしょうか。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月09日
Open Publish Conference, PDF Conference
今日は、Baltimore(米国Maryland州)に来ています。Washinton DCの子会社に用事がありましたが、そのついでに、第一回目のOpen Publish Conferenceの様子を見てみたいと思い、立ち寄ることにしました。このConferenceは、今回が初回ですが、印刷技術に関する管理と実装についてを主題とするとされています。
米国の専門家会議の主催者も新しいテーマを探して、新しい会議をいろいろと企画しているのでしょう。
アンテナハウスは、米国法人がこの会議に出展していますので、営業責任者にいろいろ聞いてみて、なにか、日本の方々に役立ちそうな話がありましたら、明日にでも紹介したいと思っています。
Open Publish 出展者リスト
ところで、米国のPDF Conferenceは、3月21日と22日に開催されますが、今回(今年?)はインターネット会議に変身するようです。
アドビのAcrobat8で、オンライン会議を始めるからではないかと思いますが、2日間もパソコンの前に座って、オンライン会議して楽しいのでしょうかねえ。出張旅費や時間の節約にはなりそうですが。
投票をお願いいたします
投稿者 koba : 09:12 | コメント (0) | トラックバック
CSS3 Text Level3 モジュールの新草稿が公開
W3CのCSS3仕様案の中で、文字組版に関係する部分である「CSS3 Text」の新しい草稿が3月6日に公開されました。
CSS Text Level 3
W3C Working Draft 6 March 2007
新しい草稿では、日本語の約物の詰めの仕様(7.3. Fullwidth Punctuation Kerning: the 'punctuation-trim' property)に関する部分がだいぶ変わっています。
また、ぶら下げ禁則なども盛り込もうとしているようですが、まだ、定義が不十分という状態のようです。
9.2 Hanging Punctuation: the 'hanging-punctuation' property
Textモジュールは、文字組版に関する規定ですが、日本語の組版からしますと、重要な和欧文間の空き量などは入っていません。
狙いとしては、Typographyを実現しようということと理解していますが、多言語のTypographyを一元的に扱うというためには、もっと、世界中の専門家の英知の結集が必要なように思います。
なお、CSS3の仕様進捗状況について、次のページの情報をついでに更新しておきました。
XML資料室:W3CにおけるCSS仕様策定の動向
ご活用ください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月08日
PDFからWordとExcelに変換するソフト
アンテナハウスが開発・販売している「リッチテキストPDF」は、PDFとOffice文書を相互に変換することができるのがその特徴です。最近は、PDFによるドキュメントの配布が増えてきたため、受け取ったPDFを再活用したいという需要もそれに応じて増えています。それで、そのジャンルのソフトウェア製品も徐々に増えているようです。
そこで、いま、日本で売られている同種の製品にどのようなものがあるかを調べ、表にまとめてみました。次の表がそれなのですが、眺めていて、面白いことに気が付きました。
PDFからWordやExcelに変換するソフトは、技術的に2つに分かれます。第一は、PDFファイルの中のオブジェクトを解析してデータを取り出し、取り出したデータからWordやExcelのファイルを生成するもの。第二は、PDFを画像にしてしまい、OCRの認識技術を使って文字や文書構造を認識してそのデータを使ってWordやExcelファイルを生成するものです。
次の表の場合、第一のグループに属するのは、リッチテキストPDF2、Acrobat Standard 8、PDF TOOLS All PDF、PDF2Office Personal Version3.0、PDF2Office Standard Version3.0、Solid Converterの6種類です。
第二のグループに属するのは、読んde!!ココ Ver.13、速攻! PDFtoData、いきなりPDFtoData2の3種類です。
で面白いこと、と言いますのは、第一のグループのソフトは、リッチテキストPDF2を除いて、他の5種類の製品は、米国製なのですが、Excelへの変換をサポートしていないということです。
それに対して、第二のグループは全部日本製で、Wordへの変換と、Excelへの変換の両方をサポートしているということです。
私は、これは、日米の文化の違いによるものではないかと思いますが、如何でしょうか?つまり米国では、PDFからExcelに変換ということを考える人が少なく、日本ではPDFをExcelに変換しようと考える人が多い、ということです。
ちなみに、この表には、私としては、全部で9種類のPDFからの変換ソフトを掲載していますが、リッチテキストPDF2がもっとも優れている、と自信をもってお勧めします。
| 名称 | 開発元 | 販売元 | 税込標準価格 | PDFからWord | PDFからExcel | コメント |
|---|---|---|---|---|---|---|
| リッチテキストPDF2/3 | アンテナハウス | アンテナハウス | 10,290円 | ○ | ○ | PDFの作成など多機能統合ソフト |
| Acrobat Standard 8 | アドビ | アドビ | OPEN | ○ | ×(注1) | PDFからの変換はStandard以上のみ |
| PDF TOOLS All PDF | BCL Tech(米) | マグレックス | 5,600円 | ○(RTF可) | × | PDFの作成、結合など統合ソフト |
| PDF2Office Personal Version3.0 | Recosoft(米) | アイフォー | 5,980円 | ○ | × | |
| PDF2Office Standard Version3.0 | Recosoft(米) | アイフォー | 7,980円 | ○ | × | Powerpointへの変換が可能 |
| Solid Converter | Solid Documents | 日本には代理店がないようだ | US$49.95 | ○ | × | Pro版もあり |
| 読んde!!ココ Ver.13 | エプソン | エプソン | 13,440円 | ○ | ○ | OCRソフト |
| 速攻! PDFtoData | スカイコム | クロスランゲージ | 2,079円 | ○ | ○ | OCR+抽出 |
| いきなりPDFtoData2 | パナソニック ソリューションテクノロジー | ソースネクスト | 1,980円 | ○ | ○ | OCRソフト |
投稿者 koba : 08:00 | コメント (3) | トラックバック
2007年03月07日
日本人一人あたりの紙消費量
日経BPのニュース配信の中で、宋文洲の傍目八目という記事は楽しみに読んでいます。先日(2月22日)、「日本は本当に「環境先進国」なのでしょうか 」という話があり、これは結構いろいろ反発があるのでは?と思っていましたが、3月1日は、「中国人を理由に僕を非難する方々へ 」という話でした。
やはり。。と思いましたが、その中で、日本人の紙の消費量について、「日本製紙連合会の資料では、日本人1人あたりの紙及び板紙の消費量は2004年時点で247キログラムです。世界の平均は56キログラムで、参考までに中国は42キログラム、インドは7キログラムです。」という一節があります。
これを見ての感想なのですが、昔、30数年前には、紙の消費量は国の文化度のバロメータというような説があり、紙の消費量が多い国の文化度が高い、という風に思っていたものです。いまや、時代が変わり、環境保護、CO2排出量を減らすために、紙の消費量を減らさなければならない時代になっています。
私も、実際のところ、頭の中では、紙の消費を減らしていかないといけないんだな、ということは気にしているのですが、なかなか、気が付かないところで無駄に紙を使っています。
最近は、電子メールで連絡することが多くなり、紙を郵送する代わりにPDF添付のメールをやりとりして済ませることが増えています。しかし、つい、紙を郵送してしまうこともあります。先日も、アンテナハウスの株主総会の開催通知を送りましたが、その際、PDFで作成した営業報告書などの資料をわざわざ紙に印刷して株主全員に郵送してしまいました。後で、そういえば半分くらいの人は、メールアドレスが分かっているのだからPDFで送れば良かった、と反省しています。
毎年習慣的にやっていることなのですが、どうも習慣を換えるのは難しいものです。しかし、やはりこれからは、紙の無駄な消費を減らすことにもっと留意していかないといけないのでしょう。ひとり一人が少しでも減らせば、全体ではかなりの量になるでしょう、経済活動とはそういうもの。
と言うわけで、最後に、我田引水ですが、PDFをもっと簡単に活用できるようにするソフトを多くの人に提供することは、社会全体のためにもなることだ、と重要な使命を再認識しました。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月06日
3月末より『自在眼10』を発売
アンテナハウスは、2007年3月26日より、『マルチ・ファイルビューア 自在眼10』を出荷開始いたします。
『自在眼10』は、日本語ワープロ文書や表計算ワークシート、パワーポイント、PDFなど200種類以上のファイル形式に対応し、簡単操作でファイル内容を表示・印刷するソフトです。文書・画像フォーマットの変換や圧縮・解凍、マルチメディアファイル再生までもできます。
『自在眼10』は、動作環境にWindows Vistaを追加、Windows95以降の全てのWindowsオペレーティング・システムで動作します。
今回のバージョンアップの目玉は、新しく開発した高性能文書ビューアです。
PDF、Microsoft Word、PowerPoint、一太郎の表示には新しい高性能ビューアを使用します。それぞれ次のような特徴があります。
(1) PDF表示の高精度化
自在眼9で追加した新PDFビューアを改良し、埋め込みフォントの表示やスムージング表示などに対応しました。
(2) 新Wordビューアを追加
新ビューアでは縦書き文書で文字が正立した表示となりワードアートや図の表示精度も向上しています。スムージング表示にも対応。 新WordビューアはMS Word 97から2003に対応しています。
(3) 新PowerPointビューアを追加
新PowerPointビューアを追加しました。新ビューアでは、文字列検索、ハイパーリンクやボタンのクリックによるジャンプに対応しました。またクリップボードへのコピーで文字もコピーされます。スムージング表示にも対応。新PowerPointビューアはMS PowerPoint 97から2003に対応しています。
(3) 新一太郎ビューア追加
新一太郎ビューアを追加しました。新ビューアでは縦書き文書で文字が 正立した表示となり枠飾りなどへの対応も強化しています。スムージング表示にも対応。 新一太郎ビューアは一太郎8から最新の一太郎2007に対応しています。
新しいワープロビューアでは、縦書きの文字を正立した状態で表示できるようになりました。論より証拠『自在眼9』と『自在眼10』でMicrosoft Wordで縦書した文章を表示してみました。
■『自在眼9』で縦書き文書を表示
■『自在眼10』で縦書き文書を表示
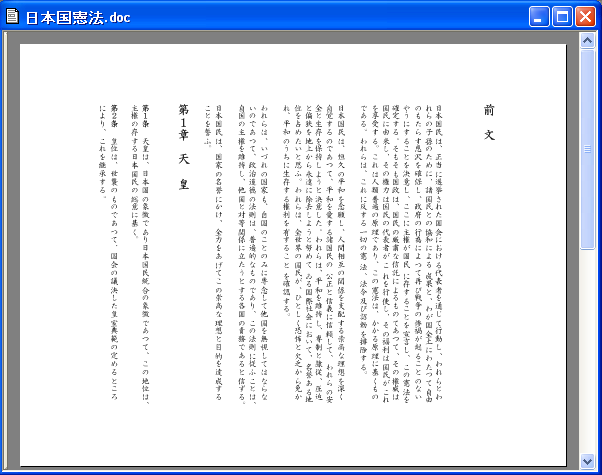
日本語向けのビューアとしては、縦書き表示ができるようになって漸く1人前ということ。『自在眼』の初版発売は1997年秋ですので、10年かかって漸く縦書き表示ができるようになったわけです。
■オリジナル(Microsoft Word 2003英語版で作成)

投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月05日
「書けまっせ!!2Vista対応版」を出荷開始
アンテナハウスでは、3月5日より、「書けまっせ!!PDF2Vista対応版」を出荷開始します。本バージョンは、動作保証OSとして、新たにMicrosoftのWindows Vistaオペレーティング・システム(32ビット版OS)を追加しました。

従来の「書けまっせ!!PDF2」と機能は全て同等です。但し、Vistaで動作させるために内部的な処理を一部変更し、インストーラの改訂を行いました。
「書けまっせ!!PDF2Vista対応版」は、パッケージ製品(CD-ROM)とダウンロード版を販売します。
1.パッケージ製品につきましては、本日より、新パッケージ(JANコード変更)を出荷開始します。また、販売店の店頭在庫はお取替えします。
2.ダウンロード版は、Vector他より発売致します。Vectorの販売ページは、こちらです。

3.既に、「書けまっせ!!PDF2」(Vista非対応版)をお求めいただいた方で、ご希望の方は、Vista対応版を次のような方法でご提供します。
(1)Vista対応版提供のための申し込み書(PDF)をWebサイトからダウンロードして、PDFにお申し込み要項をご記入の上、アンテナハウスの顧客サービス宛にe-mailまたはFAXでお送りください。折り返し、e-mailにてVista対応版のダウンロード方法をご連絡いたします。
(2)ダウンロード版のご提供は無償です。
(3)CD-ROMメディアにつきましては、1,050円(税込み)にてご提供いたします。
なお、「書けまっせ!!PDF2」を正式にご使用いただくには、1台のPCあたり1つのエンドユーザ・ライセンス(シリアル番号一つに相当します)が必要です。既に「書けまっせ!!PDF2」をWindowsXP/2000にインストールしてお使いの方が、Windows Vistaが動作する別のPCに、「書けまっせ!!PDF2Vista対応版」をインストールされるときは、もう1本のライセンスを追加でお求めいただく必要があります。追加ライセンスにつきましては、優待販売で格安にご提供していますので、ぜひ、ご利用ください。
【ブログだけのお得情報】
ところで、今回のVista対応版で機能は変更していないのですが、内部的に若干の改良を行っています。まず、PDF出力のための「書けまっせ専用PDF Driver」の呼び出し方を変更しました。そうしましたら、PDF出力に従来10秒近く掛かっていたのが、2秒程度に短縮されました。後は、PDF Viewer SDK、PDF Toolといったコンポーネントを最新版に入れ替えています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月04日
日本語組版はグリッドベースで行うと言って良いのか?(7)
昨日は、Microsoft Wordのページ設定で、「文字数と行数を指定する」、「原稿用紙の設定にする」、という二通りの設定をして、文字を入力した結果を検討してみました。
その結果を見ながら、2007年02月27日日本語組版はグリッドベースで行うと言って良いのか?(5)を振り返って、CSS3の10.2 line-grid-modeの仕様に出ているサンプルの図と照らし合わせてみます。
そうしますと、Microsoft Wordの「文字数と行数を指定する」(標準の字送りOFF)は、すなわち、CSS3のallグリッド・モードと同じであり、「原稿用紙の設定にする」は、ideographグリッド・モードと同じになっていることが分かります。
このことからも、CSS3 Text Module W3C Candidate Recommendation 14 May 2003の10. Document gridの仕様は、Microsoft Wordのページ設定の仕様をベースに作られていると言って間違いない、つまり、CSS3(案)に規定されているグリッドの仕様は、ワードプロセッサの原稿清書用の機能をCSSに持ち込んだものである、といえます。
このMicrosoft Wordの機能は、従来であれば手書きで行っていた、論文集・作文集の原稿執筆などを、原稿用紙と鉛筆の世界からワードプロセッサを使って行うための機能と考えられます。つまり、ワードプロセッサを紙と鉛筆の代わりに使って原稿書きをするためのものです。そのための目的としては重宝されるものと思います。しかし、そこで出来上がった結果は、あくまで、清書されてプリントされた原稿であって、そのまま印刷物にするものではありません。
これに対して、JIS X4051「日本語文書の組版方法」は、表題の組版から自明なように印刷のためのものであり、適用範囲では、主に書籍に適用する、とあります。
XSL-FOの用途は、XMLドキュメントの組版をすることにありますので、適用範囲は、書籍あるいは操作説明書などの書籍に近い印刷物となります。従って、XSL-FOには、原稿清書用の機能は不必要と考えられます。
では、CSSには、原稿清書用の機能が必要なのでしょうか?これは、CSS3の適用される用途にも依存しますので、なんとも言えません。
ただ、CSS3 Text Module W3C Candidate Recommendation 14 May 2003を見ますと、"Giving a fixed advance width to ideograph grapheme clusters only. Other grapheme clusters are spaced normally. This is called "genko" in Japanese typography."(漢字かな類のみを固定ピッチとし、他の文字には通常のスペースを与える、これは、日本のtypographyでは"原稿"と呼ばれる)という文章があります。
ここでTypographyとはなんでしょうか?Wikipediaの説明は以下のようになっています。
Typography英語版
Typography is the art and techniques of type design, modifying type glyphs, and arranging type. Type glyphs (characters) are created and modified using a variety of illustration techniques. The arrangement of type is the selection of typefaces, point size, line length, leading (line spacing) and letter spacing.
Typography is performed by typesetters, compositors, typographers, graphic artists, art directors, and clerical workers. Until the Digital Age typography was a specialized occupation. Digitization opened up typography to new generations of visual designers and lay users.
日本語版
タイポグラフィ (英: Typography) とは、活字(あるいは一定の文字の形状を複製し反復使用して印刷するための媒体)を用い、それを適切に配列することで、印刷物における文字の体裁を整える技芸である。タイポグラフィの領域はその周縁においては、木版を用いて文字を印刷する整版、見出し用途のための木活字の使用、やはり木活字を使用する古活字版、さらにはレタリングやカリグラフィー、東アジアの書芸術と、技術的内容においても審美的様式においても、深く連関する。
この説明を見て、直ぐに分かることは、原稿執筆はTypographyにはあてはまらないということです。もし、CSS3が、原稿とはTypographyの一種であると理解して書かれているならば、まず、この理解の誤りを正す必要があります。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月03日
日本語組版はグリッドベースで行うと言って良いのか?(6)
さて、CSS3のグリッドの仕様はだれが考えたのかは、私には分かりません。しかし、CSS3 Text Module
W3C Candidate Recommendation 14 May 2003を担当したのがMichel Suignard (Microsoft)となっていますので、恐らく、Microsoft関係者ではないかと思われます。
それで、ベースになっているのは多分Microsoft Wordでしょう。実際、Microsoft Word2003(英文)のページ設定のダイヤログには、次のような機能があります。
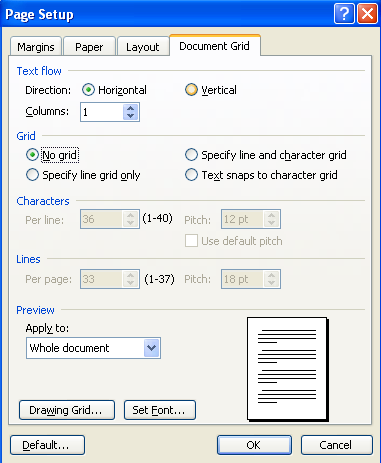
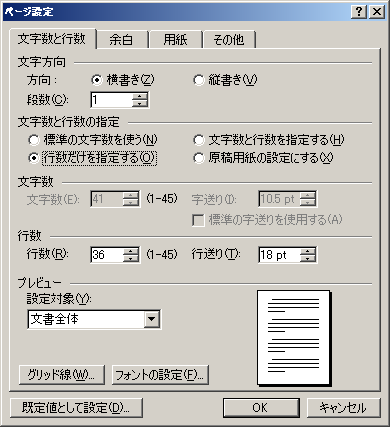
Word2003の日本語版で、このダイヤログに相当するのは次の図です。
1.文字数と行数の設定
Microsoft Word 2003では、「文字数と行数を指定する」にチェックすると一行の文字数とページ内行数を設定できます。「標準の字送りを使用する」にチェックをいれない状態では、字送り(文字ピッチ)は用紙の幅から左右の余白を引いた残りの本文領域の幅を文字数で割った値になります。行ピッチも同様に、用紙の高さから上下の余白を引いた数字になります。この設定で文字を入力すると次の図のようになります。

このとき、「標準の字送りを使用する」にチェックを入れますと、文字ピッチが文字の大きさになります。この設定で文字を入力すると次の図のようになります。

2.原稿用紙の設定
次に、「原稿用紙の設定にする」(英語版では「Text snaps to character grid」)にします。すると、文字が各グリッドの中央に配置されます。さらに、ラテンアルファベットの文字配置が、単語ベースになります。すなわち、最初の図では、ラテンアルファベットを1バイト=半角で入力したときは、2文字ずつが一つのグリッドに入っていたのですが、「原稿用紙の設定」では、ラテンアルファベットは文字単位ではなく、単語単位で配置されて、次の図のようになります。

投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月02日
「リッチテキストPDF3」を3月20日発売
アンテナハウスは、2007年3月20日より、「リッチテキストPDF3」を出荷開始いたします。 本製品は、PDFファイルの内容をMicrosoft Word、同Excel、ジャストシステムのワープロ一太郎の文書に変換するソフトウェアの新バージョンです。
今回のバージョンアップでは、主に、次の点が新しくなりました。
1. Windows Vista™オペレーティング・システム(OS)上でも動作するようになりました。
2. PDFから各種文書への変換精度を向上するため、特に次の機能を追加しました。
(1)PDFからExcelへ変換する前に、PDFファイルを画面に表示して、その中でイメージ画像に変換したい領域を指定できます。これによりグラフの横線などが表のセルに誤変換されてしまうことを防止できます。
(2)PDFからWordへの変換時に、縦書きのPDFをWord文書の縦書き書式を設定して出力するオプションを追加して、変換結果の編集を容易にしました。
3. 本製品にはPDFを作成する機能もあります。
PDF作成機能では、最新のAntenna House PDF Driverを搭載し、新たにPDF1.6形式の作成を可能としました。
また、Microsoft Office 2007のメニューにPDF作成機能を組み込んだり、Microsoft Office 2007の文書を自動でPDFに変換できるようになりました。
■PDF変換機能の特徴
本製品の主な機能は、PDFファイルをワープロ文書や表形式に変換する機能です。特に、本製品では、PDFファイル内容を読み込み・解析するエンジンを独自開発し、PDF内のデータから文書書式、段落書式、表書式、文字書式などを抽出します。PDF内の文字データを直接取り出す方式により、文字化けがなく、また、フォントや段落も可能な限りもとのデータを忠実に再現します。
また、ワープロ文書の生成、表形式の生成で、日本の文書変換ソフトのトップ・メーカとして20年以上蓄積したノウハウをもとに、できるだけ再編集しやすいワープロ文書・表形式ファイルを生成しますので、変換後ワープロなどでの編集が容易です。
さらに、PDFプレビュー機能を標準搭載することで、文書ごとに余白の大きさや、表、線画の変換領域などを詳細に設定できます。
■本製品の詳細
下記の弊社Webサイトをご参照ください。
http://www.antenna.co.jp/rpd/
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月01日
ドキュメント配布フォーマットとしてのPDF
1昨日、お客さんとのミーティングの席上、次のようなご質問をいただきました。
「以前は、PDFは再編集できない形式・完成した文書を配布する形式として適切と理解していたのですが、最近は、リッチテキストPDFを初めとして、PDFをワープロに変換するソフトが増えているようです。そうなりますと、PDFは送り先で再利用されない形式であるという特徴がなくなってしまいます。それなら、Wordなどの形式で送っても良いのではないでしょうか。文書をPDFで送ることに、どのようなメリットがあるのでしょうか?」
実は、これとまったく同じご質問を時々いただくことがあります。実際、Microsoft Officeなどが、非常に普及して、ビジネスユーザなら大半のPCにMicrosoft Officeがインストールされている状態になった現在、ドキュメントを配布する形式としてのPDFに一体どんなメリットがあるのだろうか?という疑問を持たれる方も多いことと思います。
その疑問に対する直接的な回答には、全然、あてはまらないかもしれませんが。
Microsoftは、技術文書の配布にXPS(XML Paper Specification)を使い始めています。たとえば、最近、Microsoft はMSDNで「Print Schema Specification Version 0.95」というのを配布し始めました。
この文書は、もう、XPS形式しか配布されていないようです。それで、私は、やむを得ず、昨年、一度アンインストールしたXPSビューアをもう一度、ダウンロードしてインストールしました。
今度は、.NETFramework3.0をインストールしましたが、そうしますと、IEのプラグインとして、XPSビューアが動いて、IEの画面でXPSを表示します。
○Print Schema Specification(XPS形式)の表紙

これをみて、思いましたが、結局、ドキュメント配布形式としてのPDFのメリットを議論するということも大切ですが、見たい文書が、XPSで配布されてしまえば、有無を言わさず、XPSをインストールしなければならないので、あまり議論をしてもしょうがないかな、ということです。なんだか、結論がお粗末?
投票をお願いいたします