« 2006年01月 | メイン | 2006年03月 »
2006年02月28日
マーケティング手法としての無償ソフトを批判する
日経コンピュータの2月20日号のニュース&トレンドで、「オープンソース対抗で苦肉の策 IBM、マイクロソフト、オラクルが無償DBを投入」という記事を読んで、内心ぞっとしました。
記事は、IBM、マイクロソフト、オラクルがそれぞれ、有償製品の最新版と同じDBエンジンを備える無償のDBの配布を開始したということを紹介して、これがオープンソースの「PostgreSQL」、「MySQL」を初めとするオープンソース・ソフトウェアへの対抗上やむなく行った、という日本IBMのコメントを紹介しています。
1.Microsoftは、以前からSQLServerのExpress版を無償で配布しています。
SQL Server 2005 Express Edition 概要
2.IBMのDB2 Universal Databaseは、次のサイトから入手できます。
DB2 Express-C for Linux and Windows
ここを見ますと、完全にフリー(無償)と書いてあります。
3.Oracleのデータベース「Oracle Database 10g Express Edition」も無償で入手可能になっています。
Oracle Database 10g Express Edition, Free to develop, deploy, and distribute
これらのデータベースは、フル機能版と比べて機能の制限がついたものですが、オープン・ソース対抗と言いながら、Oracle、Microsoft、IBMという3社のシェア争いという面も見逃せません。
こういう状況が進めば、DBマーケット自体が侵食されていくことは間違いありません。そうなるとOracle、Microsoft、IBMの3社がどこまで赤字を我慢できるかという我慢比べになり、いずれは、この中のいづれかからDB事業を放棄する会社が出てくるでしょう。
これに類する、過去に起きた最悪の例は、ブラウザのシェア争いです。Webブラウザの分野では、Netscape NavigatorとMicrosoftのInternet Explorerです。この争いは、Netscapeが敗れて終わりました。しかし、Internet ExplorerがWebブラウザの標準になって、競争相手がいなくなったためにWebの進歩が、相当に遅れてしまったと思います。また、Internet Explorer独自仕様になっていて、Internet Explorerでしか使えないWebサイトがあることも事実です。これは、無償ソフトの配布によって、公正な競争がなくなったための負の側面が現れてしまったものです。
PDFでも同じように、無償ソフトを販促手段として配布している会社があります。販促手段として無償版を配布するのは、自己の利益を追求するために他社の利益を犠牲にするという恥ずべき行為です。
こういうことを行う会社が増えれば、ソフトウェアの市場は侵食されて縮小していきます。新しい製品を作るために投資をしても市場が縮小してしまえば投資を回収できないわけですので、無償ソフトのユーザが多い分野では、新しい製品を作るために投資をする人はいなくなってしまうでしょう。そうなったとき、誰が一番損をするか、といえば、それはユーザだろうと思います。
無償ソフトの配布というのは、企業活動において、公正な競争手段なのかどうか、きちんと考えてみなければならないと思います。「利を求むるに道あり」という言葉がありますが、手段を問わずに利益を追求するということをしてはならない、と考えます。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月27日
プリフライト・チェッカとRIPシミュレータ
PDFを印刷工程にまわす前にチェックすることを、PDFプリフライト・チェックと言います。Acrobatにはプリフライト・チェックの機能はありますし、有名なプリフライト・チェック・ツールには、enFocus(ベルギー)社のPitStopというソフトもあります。
しかし、AcrobatやPitStopはあくまでPDFとしての内容チェックとなります。AcrobatやPitStopでチェックしてOKだから、実際の印刷工程で問題が出ないかというとそうでもないようです。
例えば、PitStopは、PDFの修正をすることもできますが、PitStopでPDFを修正すると、ファイルを壊してしまうことがあるという話も聞きます。
実際に、XSL Formtterのお客様から、Formatterで作成したPDFをPitStopでPDF/X-1a用に修正したところ、ファイルが壊れてしまう、ということで、FormatterのユーザサポートにPDFファイルが送られてきたこともあります。壊れたPDFファイルの内容を調査しましたところ、PitStopで書き直した箇所のPDF命令が不正になっている、という現象が見つかっています。この理由は、PitStopのPDF描画命令の出し方が良くないために不正なPDFになってしまうのですが、プリフライト・チェックを行うソフト自体がPDFを壊すような出力をするのは笑えません。PitStopでプリフライトがOKであっても実際にRIPで処理しようとするとエラーになってしまう可能性は十分考えられます。
そうしますと結局のところ、印刷会社でPDFを処理するRIPと同じRIPを使ってチェックをしたら万全になるのではないかということになります。RIPシミュレータの意味はそんなところにあるように思います。
さて、前置きが長くなりましたが、Facilisというのは、三菱製紙が販売している自動面付けソフトのブランド名です。
Facilis Guardianは、Facilisという名前を冠している通り、Facilis RIP Ver.2.0の300dpi制限版を内蔵し、PDFをRIPを使ってチェックするRIPシミュレータです。
Facilis RIP はHarlequin RIP Genesis 版のOEMですので、実体はHarlequin RIPということになります。Facilis Guardianを開発した朝日システム開発の梶間社長に伺ったところでは、Harlequin のRIPは、高速で、しかも出力結果のログで様々な情報を得ることができ、他のアプリケーションに組み込みしやすい、などのAdobeの純正RIPにない様々な特徴があるそうです。
ところで、話を伺っていて、このHarlequin RIPを開発した人の方に関心をもってしまいました。なにしろ、PostScriptを処理するプログラムを作るのは、恐ろしく大変、と以前からいろんな開発者に聞いています。私の知っている限りでは、PostScriptインタープリタの開発はソフトウェア開発者が誰もやりたがらない仕事の一つです。Harlequin RIPというのは、PostScriptを読み込むこともできますし、PDFを読み込んで処理することもできます。で、PostScriptインタープリタのコア部分の開発は大勢でやるものではなく、やはり天才が一人で作るものなんだそうです。Harlequin RIPのコアを作った人は、英国のケンブリッジで、一人で部屋にこもって作ったのだそうです。こんなすごいものを一人で作るとは、一体、どんな天才なんでしょうか。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月26日
PDFと印刷
アンテナハウスの設立は1984年ですが、その頃は、ちょうど、ワープロ専用機が世の中に普及し始めた時代でした。そうして、ちょうどその頃に普及していたのが電算写植機です。同時に、パーソナルコンピュータが普及を始めた頃です。
この3点セットが普及をする前は、印刷用の版下を作成する作業は、(1)手書きの原稿をお客さんから受け取って、(2)オペレータが写植機にデータを入力して組版して、(3)版下を切り張りで作成する、という流れで行われていました。
電算写植機の登場により、版下切り張りの必要がなくなりましたが、相変わらずデータの方は手入力だったわけです。
一方で、印刷の発注先であるユーザ企業の間にワープロ専用機が普及したことから、ワープロで入力したデータをなんとかして電算写植機にそのまま入力できないかというニーズが生まれました。
これを可能にしたのが、1980年代後半、当社が商品化したMS-DOSテキストファイル・コンバータです。このMS-DOSテキストファイル・コンバータは、主に富士通のOASYS、シャープの書院、NECの文豪、東芝のToswordやRUPOなどのワープロ専用機で作成した原稿を、印刷会社が電算写植機に入力するためのデータとするための用途に使われたのですが、1980年代後半には、それこそ飛ぶように売れたものです。
いまは、登場する役者が全部変わってしまいましたが、電算写植機をRIP(Raster Image Processor)にワープロ専用機のデータをPDFに置き換えて見ますと、同じような状況が起きているのかも知れません。
吉田印刷のDTPサポートブログには、PDFを印刷入稿に使う7つのメリットという記事があります。
[1062][PDF]PDF形式の7つのメリット~なぜPDFなのでしょうか?
ユーザ企業にはPDFがどんどん普及しています。ユーザがPDFにしたデータをそのまま印刷用の完全データとして使って、印刷機にセットし、印刷ができるのならば、こんな便利なことはありません。
しかし、話に聞きますと、印刷会社ではPDF入稿をあまり歓迎しない向きもあるとか。
どうしてこんなことになってしまうかと言いますと、PDFがあまりにもなんでも取り込みすぎたからでしょう。
極端な例が、低価格のスキャナで紙をスキャンしてPDFを作るケースもかなり多く、多分、スキャナで作ったPDFはPDF全体の10%~20%は占めているのではないかと思います。スキャナ派はAdobe Readerで表示できるものがPDFであると考えているのではないかとも思います。
そこまで行かなくても、印刷の原稿としてのPDFにはいろいろ問題があるようです。
Page2006などの展示会で印刷機材のメーカのカタログを見ますと、Acrobatで作成したPDFしか保証しない、ということをうたっているケースもしばしば見かけます。というよりもAdobe以外のサードパーティのPDF作成ソフトで作ったPDFを保証している印刷機材は殆どないのが現状のように思います。
しかし、これはやはり困ります。なんとかしなければなりません。
そんな問題意識があって、PDFを評価するソフトに関心がありましたが、たまたまFacilis GuardianというRIPシミュレータをお借りして試してみることができました。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月25日
iTextのPDF直接出力機能
いままで、iTextの高級オブジェクトをかい摘んで紹介しました。こういう高級オブジェクトを使うと、PDFについての知識を持っていなくても、PDF出力が簡単にできるというメリットがあります。
これに加えて、iTextの特長は、PDFの中に記述する命令を直接出力する機能があります。PDFの低レベルの命令を直接扱うだけに、この機能を使うには、PDF Referenceの第4章グラフィックス、第5章テキストあたりを最初に読む必要があります。
具体的には次のような命令です。
Part IV: Direct Content
5.iTextで直接扱えるPDF描画命令
・Graphics state オペレータ
・座標変換行列
・カラー
・クリッピング・パス
・形状の定義をするパス設定オペレータ
・パスの塗り潰しなどのオペレータ
・PDFのオブジェクトであるImageXObject、FormXObjectなど
※PostScriptXObjectの例もありますが、これは廃止予定があるとされているもので使うべきではありません。
・テキスト・オペレータでフォントのグリフ記述
・オプション・コンテンツ
XSL-FO組版エンジンは、これらのPDFの描画命令をユーザには通常開放していません。アンテナハウスのXSL Formatterの場合、これらのPDF描画命令は、PDF生成ライブラリーを使ってPDFに出力しています。
iTextでは、内部的に各ページを4つのレイヤに分けています。その内2つのレイヤは高級オブジェクト用でiTextのプログラム内部専用です。残りの2つにはgetDirectContent()、getDirectContentUnder()を使って直接出力できます。例えばウオーター・マークなどを出すのに使えます。
(このレイヤは、iTextのプログラム内部のレイヤで、PDF Referenceの「オプション内容グループ」(後述)とは別のものです。)
JAVAプログラマが直接PDFの描画命令を使うのは、あまり生産性が高いとは思えません。しかし、汎用ソフトのオブジェクト経由では実現できないことを行うために、プログラマに開放したレイヤがあるというのは便利な場合もあるように思います。
6.PDFのオプション内容グループ(Optional Content Group)
PDF 1.5(Acrobatのバージョンでは6)で、オプション内容グループ(Optional Content Groupという機能が追加になりました。この機能は、PDFの内容を多層化して作成しておき、各層を表示するかしないかを選択できます。
iTextでは、PdfLayerオブジェクトを使って、この機能を使ったPDF出力もできるようになっています。チュートリアルで幾つかサンプルが紹介されていますが、その中で一つだけ次に紹介します。
PdfLayerで出力する層を指定して、各レイヤに別の文字列を出力します。すると、このような3層のPDFが出来ます。
3層のPDFの例
Adobe ReaderのLayersタブで各レイヤを表示するかどうかを選択できます。
さて、このようにiTextの機能のあらましを紹介し、iTextのオブジェクトについては、XSL-FOと簡単に比較してみました。実際のところiTextはPDF出力専用の低レベルなJAVAライブラリーと言えます。その範囲で、PDF専用の機能についてはかなり強力な部分を持つ優れたライブラリーのようです。
しかし、XSL-FOのような高度な組版機能を提供するものではありません。サーバ上で作成しようとするレイアウトにもよりますが、Webページをさらに精密にするような高度なレイアウトであれば、XSL-FOの方が生産性が高くなると思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月24日
iTextとXSL-FOでのテキスト出力比較
一昨日に続いて、iTextとXSL-FOのオブジェクトの比較をしてみます。
4.テキストの出力
(1)iTextでテキストを出力するオブジェクト
・iTextでPDFにテキストを書き出すには、主にChunkオブジェクトまたはParagraphオブジェクトを使います。Chunkオブジェクトとは、すべてのテキスト・オブジェクトの原子であって、その内容はフォント名、フォントのサイズ、スタイル、色が同じ文字列です。
Chunk単位で、アンダーラインを付けたり、文字の位置を上下に移動したり、バックグラウンド・カラーを付けたりの様々な処理ができます。
Paragraphオブジェクトは段落に相当しますので、行間の空きや、段落単位でのフォントの指定ができます。
(2)XSL-FOでは、テキストを出力する時は、fo:inlineやfo:blockなどのオブジェクトを使います。fo:inlineが、iTextのChunkオブジェクトに、fo:blockがiTextのParagraphオブジェクトに相当します。
XSL-FOではフォント名、フォントのサイズ、スタイルなどはfo:inlineやfo:blockの属性として指定します。例えば次のようになります。
<fo:block text-align="center" font-size="15pt" font-weight="bold" background-color="black" color="white">Extension for Line Numbering</fo:block>
さて、iTextでできて、現在のXSL-FOの組版エンジンでできないのは、PageEventでしょう。
iTextのチュートリアルには次のような例が載っています。
public void onGenericTag(PdfWriter writer, Document document, Rectangle rect, String text) {
if ("ellipse".equals(text)) {
.... }
else if ("box".equals(text)) {
... }
}
これは、渡される文字列の内容を見て処理を変更する例です。
また、w = c.getWidthPoint();という関数で文字列の幅を取得して、プログラムの中で計算する例も出ています。
このような組版対象オブジェクトのコンテンツの内容をみてダイナミックに処理を変更するプログラミングは現在のXSL-FOではできません。iTextの良いところは、XSL-FOでも積極的に取り入れて、将来の拡張を検討しなければならないと思います。
5.表の出力
次に表の出力を見てみます。
(1) iTextでの表は、PdfTabke、PdfCellオブジェクトを使って出力します。
チュートリアルの一番簡単な例を見ましょう。
PdfPTable table = new PdfPTable(3);
PdfPCell cell =
new PdfPCell(new Paragraph("header with colspan 3"));
cell.setColspan(3);
table.addCell(cell);
table.addCell("1.1");
table.addCell("2.1");
table.addCell("3.1");
table.addCell("1.2");
table.addCell("2.2");
table.addCell("3.2");
document.add(table);
としますと、次のような簡単な表ができます。

この方法はシンプルですが、例えば、複数のセルを行方向で結合するのは困難になります。行方向のセル結合は、テーブルの入れ子機能を使うようです。
(2)XSL-FOでの表は次のようになります。
<fo:table-and-caption>
<fo:table>
<fo:table-body>
<fo:table-row>
<fo:table-cell number-columns-spanned="3" border-style="solid" border-width="0.5mm" ><fo:block>header with colspan 3</fo:block></fo:table-cell>
</fo:table-row>
<fo:table-row>
<fo:table-cell border-style="solid" border-width="0.5mm" ><fo:block>1.1</fo:block></fo:table-cell>
<fo:table-cell border-style="solid" border-width="0.5mm" ><fo:block>2.1</fo:block></fo:table-cell>
<fo:table-cell border-style="solid" border-width="0.5mm" ><fo:block>3.1</fo:block></fo:table-cell>
</fo:table-row>
<fo:table-row>
<fo:table-cell border-style="solid" border-width="0.5mm" ><fo:block>1.2</fo:block></fo:table-cell>
<fo:table-cell border-style="solid" border-width="0.5mm" ><fo:block>2.2</fo:block></fo:table-cell><fo:table-cell border-style="solid" border-width="0.5mm" ><fo:block>3.2</fo:block></fo:table-cell>
</fo:table-row>
</fo:table-body>
</fo:table></fo:table-and-caption>
XSL-FOの方はHTMLと同じように表全部を予め作っておくことになります。この作り方から見ますと、複雑なレイアウトの表をiTextで作るのは相当に難しいのではないかと予想します。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年02月23日
XSL-FO仕様が勧告仕様になりました
W3Cが、現在、仕様の改訂作業を行っているExtensible Stylesheet Language V1.1 が2月21日(日本時間)に勧告候補(CR)になりました。
CR仕様書は、下記に公開されています。
Extensible Stylesheet Language (XSL) Version 1.1
W3C Candidate Recommendation 20 February 2006
http://www.w3.org/TR/xsl11/
今回の改訂では、次のような項目が新しく仕様として盛り込まれました。
* Change marks
チェンジ・バーとも言います。改訂箇所を示すために使われるもので、アメリカの軍のドキュメントの規格がベースになっているようです。日本の法律文書などは、新旧対照表を作って管理するようですが、米国では新旧対照表を作るという習慣はないと聞いています。
* "Back of the book" index.
書籍等の巻末索引を作成するための仕様です。この巻末索引の仕様は非常に重要なもので、XSL-FO組版エンジンの主要ベンダは巻末索引を独自に拡張していましたが、V1.1で標準化されることになります。(但し、縦書の上、中、下段なんてのはないですね。これは提案しないといけないでしょう。)
* Bookmarks.
PDFのしおりを作成するための機能です。実際のところ、XSL-FO組版エンジンの出力は殆どPDFです。XSL-FO V1.0ではしおりを定義する機能がなかったため、PDFのしおり作成機能をXSL-FO組版主要エンジンが独自拡張していたのですが、V1.1で標準化されます。
* "Markers"
マーカー機能が拡張されます。
XSL-FOにはfo:marker/fo:retrieve-markerという機能があり、ページ単位でのランニング・ヘッダやランニング・フッタ作成、等のために使うことができました。表が次のページ/段に続く、前のページ/段から続くとか、あるいは、小計の表示をする機能などが欲しい、という要望が多く寄せられています。V1.1でマーカーの機能が強化されて、表の継続を示す用途などに使えるようになります。
* Multiple flows.
これまで、内容オブジェクトのフローは単一で、流し込む領域はfo:region-bodyという本文領域のみでした。V1.1から複数のフローを定義可能になりました。
図 マルチフローの例
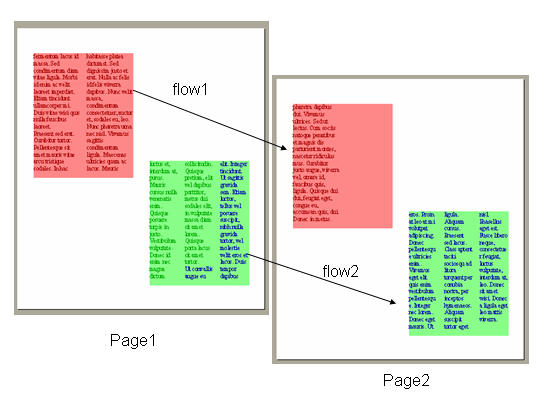
上の図のように、用紙マスターに複数の領域を定義しておき、内容オブジェクトのフローを複数用意し、各々流し込みする領域を対応つけることができます。この機能は、FrameMakerから持ってきたものと思いますが、かなり複雑なレイアウトが可能になるでしょう。
この他、次のオブジェクトが追加になっています。
* fo:page-sequence-wrapper.
* fo:page-number-citation-last.
また、プロパティの拡張も幾つかあります。
* graphic の拡大縮小の条件付け.
* page-position の属性に新しく "only" という値を追加
* clear、floatの属性に "inside" と "outside" を追加
* ページ番号に、接頭辞、接尾辞を指定可能に
ページ番号は、folio-numberに変更になりました。
CRは仕様として安定した状態で、ベンダーに対して実装を呼びかけるステップです。
W3Cの仕様策定ステップ
CRの予定期間は5月31日までとなっています。W3Cは、この間に、ベンダーの実装レポートの提出を求めています。
現時点での予備的な実装レポート
追加された仕様の項目毎に最低2つのベンダが実装することが必要です。
アンテナハウスは世界で唯一、すでにXSL-FO V1.1 追加仕様の実装をすべて完了しています。
本日、XSL Formatter V4.0 Alpha2 版を公開しました。α版としていますのは、リリースまでにいろいろと改良予定があるためです。XSL-FOの実装については問題なく評価していただくことができますので、ぜひお試しになってみてください。
また、アンテナハウスでは、2月27日(月曜日)16:00より多言語組版研究会を開催します。ここで、XSL-FO V1.1 で追加された仕様についての勉強会を行なう予定です。まだ、席の余裕がありますので、ぜひご参加くださいますよう。
お申し込みはこちらからどうぞ。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月22日
iTextとXSL-FOのページ生成方法を比較する
iTextとXSL-FOの比較を続けてみます。
2.ドキュメントの用紙サイズとマージン設定
(1)iTextでは、次のようにドキュメント・コンストラクタで文書のページを指定します。
public Document(Rectangle pageSize,
int marginLeft,
int marginRight,
int marginTop,
int marginBottom);
ページサイズは、標準形式(A0-A10)など、あるいは寸法で指定します。標準はポートレイトですが、回転してランドスケープにすることができます。
マージンは省略すると36ポイントになります。
document.setMargins(180, 108, 72, 36);
のように直接指定もできます。
document.setMarginMirroring(true);
で左右対称マージンの指定ができます。
(2)XSL-FOではページは、fo:simple-page-masterで指定します。
fo:simple-page-masterはページの中に本文領域fo:region-bodyをもち、ここに文章が配置されます。マージンは、fo:simple-page-masterとfo:region-bodyの両方に属性として指定します。
図 fo:simple-page-master
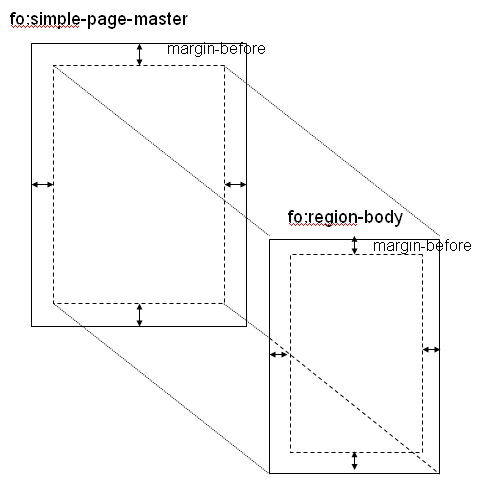
マージンを変更するにはfo:simple-page-masterを別のものに切り替えます。左右ページのマージンを対称にするには、右ページ用のマージンを定義したfo:simple-page-masterと左ページ用のマージンを定義したfo:simple-page-masterを用意し、その出現順序を指定したfo:page-sequence-masterというものを定義して用紙マスターとして使います。
3.ページの生成
(1)iTextでは、ページに章、節、段落、表などのコンテンツをプログラムで出力していきます。内容がページの中で一杯になるとiTextが自動的に新しいページを生成します。
document.setPageSize();
でページの大きさを変えたり、
document.setMargins();
でページに対して、明示的にマージンを指定すると自動的に改ページされ新しいページができます。
また、document.newPage().
で強制的に新しいページを作り出すことができます。
この他、新しい章や節を作るときに改ページすることもできるようです。いずれにしても、プログラムの中で比較的直接的にページを作成したり改ページする制御を行います。
(2)XSL-FOでは、用紙マスターを定義するfo:layout-master-setのツリーとページの中に配置する内容オブジェクトfo:page-sequenceのツリーを用意して、各内容の枝に対して、それを流し込む用紙マスターを関連付けておきます。
XSL-FO組版エンジンは、fo:page-sequenceの内容オブジェクトをページの中に流し込むことでレイアウト済みのページを作り出します。
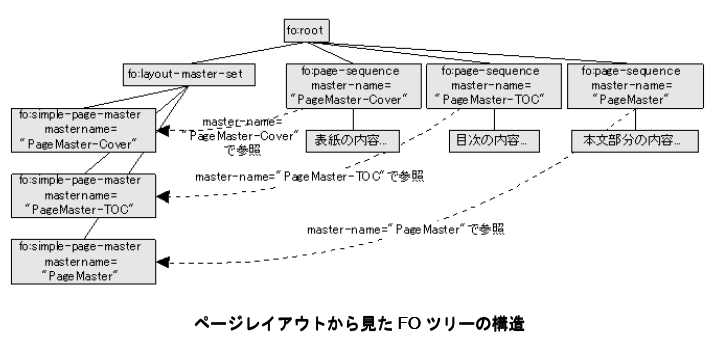
例えば、左右ページのマージンを対称にするには、左右ページ用のfo:simple-page-masterをもつfo:page-sequence-masterを用紙マスターとして使います。この用紙マスターに、内容オブジェクトを流し込んでいくと、生成されるページが奇数ページ、偶数ページかで用紙が切り替わります。これによって、左右マージンが対称になる、という仕組みです。
こうしてみますと、ページを作り出す仕組みは2つのソフトでまったく違っていることが分かります。iTextの方法は直感的・直接的ですが、複雑なページ・レイアウトやページ・シーケンスを内容オブジェクトと独立に定義していくのが難しいように思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月21日
iText的なPDF生成
TheServerSideというJAVA専門のコミュニティ・サイト(英文)があります。ニュース、ブログ、討論、ホワイト・ペーパー、レビューなどからなるサイトですが、ここで、PDFを検索すると774件がヒットします。
・iTextは45件
・FOPは55件
FOPというのは、XSL-FOを使ってPDFを生成するJAVAのライブラリーで、Apacheのプロジェクトなので非常に有名な存在です。
※FOPはあまり出来の良いものではありませんのでお勧めしません。有名なだけです。
それにしても、JAVAの世界で、iTextがFOPに近いくらいポピュラーな存在だと初めて知りました。
ここを見ていましたら、FOは複雑なので、iTextを薦めるというような話、あるいは、XSL-FOはあまり普及していないというような意見がちらほらとあります。
XSL FO
例えば、struts とenterprise java beansで作ったWebアプリケーションからXSL-FOを使ってPDFをダイレクトに生成したいんだけど、誰か教えてくれる?
↓
これに対して、FOPは複雑。スタイルシートを作るのに苦労するよ、というコメント。
↓
iTextでやってうまくいったと報告。
というようなものです。これを見ると、iTextとXSL-FOというのはサーバサイドでPDFを生成する手段として競合しているようにも思えます。
私の見たところ、iTextのオブジェクトは原始的過ぎて、もし、iTextで高度なレイアウトを実現しようとすると生産性が低いのではないかと思います。簡単な帳票のようなものを出すだけでも、きちんとレイアウトすると結構大変じゃないかなと思うのですが。
でも、JAVAプログラマの人達には、XSL-FOというのは、却って複雑なんでしょうかねえ。某航空機メーカのように両方を組み合わせて使っているケースもあります。この場合は、XSL-FOでできないことをiTextで補足しているわけです。
いづれにしても両方を理解しないと、適材適所の判断は難しいでしょう。そこで、少し詳しく、iTextによるPDF生成とXSL-FOとを比較して見ようと思います。
1.PDFの生成手続き
(1) iTextでは、次のようになります。
ステップ1.ドキュメント・オブジェクトを生成
ステップ2.Writerオブジェクトを生成
ステップ3.ドキュメントをオープンする。
ステップ4.出力する内容を追加する。
ステップ5.ドキュメントをクローズする。メモリの内容がフラッシュされて出力ストリームにデータが書かれる。
(2) XSL-FOを使う場合の仕組みは、iTextとはかなり違っています。入力と出力を指定してXSL-FO組版エンジンを呼び出す形になります。入力はXMLとXSLスタイルシート、またはXSL-FOになります。
XMLとXSLスタイルシートが入力になった場合は、第一ステップでXSL-FO組版エンジンの中でXMLとXSLスタイルシートからXSL-FOが生成され、第二ステップでXSL-FOからPDFへの変換が行われることになります。
JAVAプログラマから見た時、iTextでは、PDFの内容をプログラマがiTextのオブジェクトとして手続き的に追加していきます。これに対して、XSL-FOの場合は、全てをXSL-FOのオブジェクトとして作成した上で入力しなければなりません。このためには、XSL-FOのオブジェクトの種類とそれがどのようにレイアウトされるかについての知識が必要です。XSL-FOのオブジェクトについて十分な知識が必要になる、と言う点がプログラマにとってはかなり高い障壁になっているように思います。この点、iTextは、今すぐにでもできそうで、プログラマにとっては参入障壁が低そうです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年02月20日
iTextの機能概要
次に、iTextでできることを調べてみます。
iTextは、オンラインのチュートリアルが充実していることが特徴です。機能説明のみでなく、簡単なJavaのサンプル・プログラムでできあがったPDFのサンプルが多数提供されています:
Tutorial: iText by Example
これは良い点で、チュートリアルを見てますと直ぐにできそうに思えてきますし、大いに学ぶべきところです。
(1) iTextの基本機能はPdfWriterです。
Documentオブジェクトにテキストやイメージをセットして、PDFを生成します。この時、ページの大きさをセットしたり、ランドスケープとポートレートの切り替えができます。ページの背景色、マージンの設定、マージンの左右対称指定、PDFのメタデータ設定、セキュリティ設定ができます。但し、これらの機能は基本的なもので、あまり見るべきものはありません。
ちょっと面白いのは、PDF、RTF、HTMLのWriterをもっていてひとつのソースから同時に3種類の出力ができることでしょう。
(2) 既存PDFを読み込んでコピーしたり、ページ番号やウオーターマークを付加する。
・PdfWriterには、既存PDFのページを取り込む(Importする)機能があります。但し、Importされたページの注釈、しおりなどの対話機能は失われます。
・PdfStamperで、既存PDFにページ番号やウオーターマークを付加したり、フォーム・フィールドに記入したり、フォームフィールドを平坦化して書き込めなくしたり、PDFに署名を追加、暗号化などができます。
・PdfCopyでは、既存のPDFの結合ができます。異なるAcroFormをもつPDFを結合するにはPdfCopyFileldを使います。
iTextのオブジェクト
iTextのPDF出力はチャンク(文字の塊)、パラグラフ、フレーズ、リスト、フォント、アンカー、しおり、イメージ、表、カラムなどのオブジェクト単位で設定します。
・チャンク—同じフォント、フォントサイズ、色などの属性をもつ文字列。チャンク単位で、アンダーラインを指定したり、上付・下付指定したり、背景色を指定などができる。
・パラグラフ—段落の文字列。異なる属性をもつチャンクをつなげて作ることもできる。
・リスト—HTMLの箇条書き同様なオブジェクトです。
・アンカー—PDFでのリモート/ローカルのジャンプ先、ジャンプ先でのアクションなどを指定する。
・表—表の行やセルをPDFに出力するオブジェクト。
こういうオブジェクトを使って、JAVAのプログラムを記述すると、iTextがオブジェクトをページの上に適切に配置してPDFを生成します。
ざっと見たところ、XSL-FOにも同じようなオブジェクトがありますが、XSL-FOのオブジェクトは組版という観点から設計されているのに対して、iTextのオブジェクトはPDFから、つまり出力するデータから設計されているように思います。つまり両者のオブジェクトの設計思想には根本的な違いがあり、iTextの方が低レベル(インテリジェンスが低い、あるいは組版エンジンが初歩的という表現が良いかもしれません)のオブジェクトのようです。このあたりは、別途検討してみたいところです。
ただし、PDFに近いだけに、アンカー・オブジェクトなどはXSL-FOよりは機能が多くなっているようです。(XSL Formatter の場合は、XSL-FO仕様を独自拡張して、同様の機能を追加しています)。
直接的なコンテント
iTextは、PdfContentByteクラスを使って、PDFのページの中の指定した位置に、グラフィックス、テキストをに直接データを書き込むことができます。但し、この機能を扱うにはPDF Referenceを理解している必要があるようです。
RTFとHTMLの出力
ページの内容をPDFに出力するだけではなく、RTFとHTMLにも出力できます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月19日
Java用PDF生成ライブラリー iTextの調査
WebサイトでPDFをダイレクトに生成するライブラリーはいろいろあります。2005年11月12日 PDFの作成方法(9) – PDF出力ライブラリーで取り上げたPDFLibは有名なものですが、Java用のライブラリーとしてiTextも時々名前を聞きます。オープンソースなので使っている人が多いかもしれません。
XSL Formatterも50%以上のユーザがWebサイトでXMLからPDF生成に使っています。
ある航空機メーカでは、現在、ASPサービスにXSL Formatterを使っています。そこではFormatterで作成したPDFに対してiTextでさらに加工を加えてからPDFを配信しているようです。しかし、パーフォーマンを上げるために、iTextでやっていることをFormatterに吸収できないかという話がありました。
一般論として、メンテナンスやパーフォーマンスを問わなければ、Formatterの出力をiTextに入力するという2段階で良いことになるのでしょうが、やはりパーフォーマンスを上げていこうとすると一つのツールに統合したくなります。
こう考えるとミドルウェアも高機能が求められるということになります。そうするとツール・メーカとしては、どんどん投資して他のツールの機能を吸収していかないとだめってことになります。
そんなわけで、iTextについてチェックしてみました。iTextの機能の中で、吸収するべき部分があるのでしょうか。
iTextとはなに?
iTextは、JavaでPDFを生成するためのライブラリーです。オリジナル開発者は、Bruno Lowagie(35歳、オランダ人らしい)、現在、もっとも積極的に活動している開発者はPaulo Soaresです。他に2人の開発者がいます。
SourceForgeにホームページがあります。2000年11月から始まっていますので、既に5年を経過しています。
・現在のバージョンは、iText 1.3.6 (2005/12/12リリース)
・その前のバージョンは、iText 1.3.5 (2005/10/20リリース)
・もう一つ前が、iText 1.3.4 (2005/09/22リリース)
・2005/07/29には、iText 1.3.2 をリリース、Bruno LowagieはManning Publications社と契約して、'iText in Action'という本を書き始めたというニュースが出ています。
※最後の0.0.1のアップグレードはメンテナンス・リリース(主としてバグ修正)のようです。
こういうリリース経過、内容、バグフィックス、CVSへのコミットの記録をみると結構積極的に活動しているようです。オープン・ソース・プロジェクトは、最初は活動が活発でもだんだんしぼんでしまうものが多いですが、5年経過して積極的にやっているのは立派なものです。但し、2000年に始まって、2003年6月にV1.0が出ていますので、商業ソフトと比べると足が遅いと思います。商業ソフトならば、このスピードでは生きていけないでしょう。
iTextで興味深いのは、.NET版であるiTextSharpがあるということです。これは、J#を使ってJAVAから移植したものです。
iTextのホームページのPeopleでは、日本の氏原 一哉さんが、iText.NETの著者として紹介されています。iTextSharpとiText.NETの関係は良くわかりません。
バックグラウンドについての紹介はこの位にして、次に機能を見てみましょう。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月18日
線の太さについてのPDFの仕様
昨日までは、PDFを作成する際の解像度設定、特に線の太さ、について検討してきました。これをまとめてみます。
PDFの仕様 (PDF Reference)では、線の太さはLine Widthというパラメータで指定することになっています。
Line Width に設定する値は0以上の数値です。このときの座標の単位はPDFを書くプログラムが自由に設定できます。なお、Line Width 0はデバイスで表示できる最小の幅という特別な意味があり、表示するときは常に1ドットの幅となります。
※PDF Reference Ver. 1.6 p.185 Line Widthを参照
1.PDFを作成する際のLine Width値の設定
(1) WindowsのGDIを経由する場合は、線の幅はGDIで設定するデバイス(ディスプレイ、プリンタ)の解像度から計算されるドット幅の倍数になります。WindowsのGDIもPDFと同様に幅が0の線は1ピクセル幅になります。従って、PDFでLine Widthが0になることはないはずです。
(2)直接PDFの命令を出力する、あるいは、PostScriptを経由する場合は、論理的な寸法を指定できます。この時、次のような場合に、PDFで線のLine Widthが0に設定されることが起こり得ます。
a. 幅をもたない線を引くことができるアプリケーションが、意図的にPDFにLine Widthを0に設定したとき。
b. 外部から入力された線の幅が、PDFを作成するアプリケーションが扱える最小の論理幅より小さいため丸めた結果0になってしまう事態などが起きる、など。これらの場合には、意図しない結果としてPDFの中の線のLine Widthが0になります。
2.PDFを表示・印刷する際のLine Widthの取り扱い
(1) PDFの中の線にLine Widthに0が設定されている場合は、デバイスで表示できる最小の幅、すなわち1ドット幅の線になります。この線は、例えばAdobe ReaderでPDFを表示してズーミングしていっても太さは変わらず、常にディスプレイ上では1ドット幅になります。解像度の小さいプリンタでは太い線になり、解像度の大きいプリンタでは極細い線になります。
このように線幅0の線の太さはデバイス依存となりますのであまり良くないとされています。
(2) 次に、PDFに0以外のLine Width が設定されている場合、PDFに設定されているLine Width は表示、印刷されるときどのように処理されるかを調べてみます。
PDFを作成したツールと表示・印刷するツールは別のものになることが多いと思います。そうなりますと、PDF作成時の解像度と、PDFを表示・印刷する時の解像度は異なることが多いでしょうし、完全に一致したとしても線の位置がデバイスのドットの並びと一致しないこともあるでしょう。
次の図に、このような例を幾つか挙げてみました。
図1 Line Widthはドットの幅の整数倍で位置がずれている例 (左)
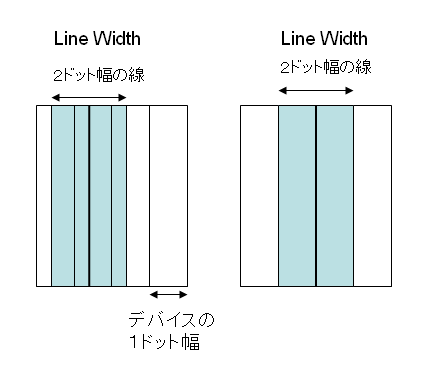
図2 Line Widthがドットの幅よりも狭い例
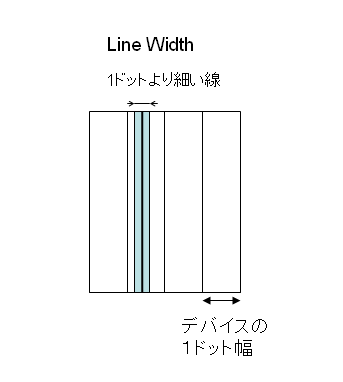
スキャン・コンバージョン
図のような論理的な太さ(幅)を持つ線を、表示・印刷デバイスはドット単位の塗り潰しに変換します。この処理をスキャン・コンバージョン(Scan Conversion)と言います。スキャン・コンバージョンのアルゴリズムは、PDFの仕様の一部として定義されているのではなく、各製品あるいはデバイス毎に最適な実装をすることになっています。
※PDF Reference Ver. 1.6 6.5 Scan Conversion Details (pp. 478~482)を参照
PDF ReferenceにはAcrobat製品のスキャン・コンバージョンについて記述されています。これはPostScript製品にも共通です。以下の説明は、PDFの仕様ではなく、Acrobatの実装のついての説明となります。
スキャン・コンバージョンの方法は、線、イメージ図形、フォントでは異なります。今回のような線の場合は、まず、PDFの中の論理的な座標系を、デバイスのドット単位の座標形にマップします。次に、論理的な座標系における線と少しでも重なるところがあるドットを塗り潰すという方法をとっています。こうすると、スキャン・コンバージョンの結果、線が消えてしまうことがなくなります。
つまり、上の図で示したような線は、デバイスの上では次のようなドット幅の倍数の太さの線になります。
図3 Line Widthはドットの幅の整数倍で位置がずれている例 (左)
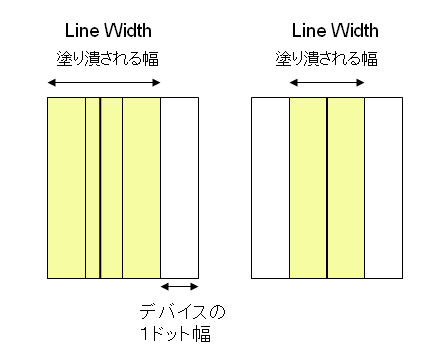
図4 Line Widthがドットの幅よりも狭い例
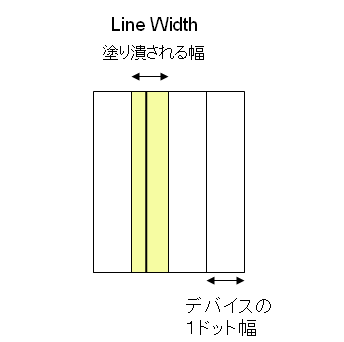
この方法では、図3のように、PDFでは同じ太さの線が、画面やプリンタに出力すると太さが変わってしまうことがあります。特に、解像度が低いデバイスに出力する時は、線の太さのばらつきが目立ってしまう可能性があります。そこで、PDF 1.2以降で、自動ストローク調整機能を用意しています。これがONの時は、線の太さを可能な限り均一になるように調整します。
※Acrobat6.0は、自動ストローク調整機能がPDFの中でON/OFFのどちらに設定されていても、常にONとして処理します。(PDF Reference V1.6 実装ノート 70 (p.1018))
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月17日
GDIをバイパスして高精細なPDFを作成 – PDFの作成方法(23)
PDFの中で線の幅は、論理的な寸法指定で表現します。従って、極論すればコンピュータで扱うことのできる数値であればどんな細い線でも表現することができます。
しかし、一方、Windowsのアプリケーションでは表示・印刷デバイスはGDIを経由して取り扱う必要があり、GDIでは解像度によって表現できる精度に限界があることを説明しました。
では、2月13日に示しましたような、線幅0.01ポイント(0.0035mm)というような細い線をPDFに正しく設定するにはどうしたら良いでしょうか?
方法は、二通りあります。
(1) PostScriptプリンタ・ドライバを使ってPostScriptを出力し、PostScriptからPDFを生成する。但し、アプリケーションはGDIをバイパスしてPostScript命令を直接出力できること。
(2) アプリケーションからGDIに関係なく、直接PDFの命令を出力してPDFを作成する。
前提条件として、(1)、(2)ともアプリケーションが、GDIをバイパスして出力する機能を実装している必要があります。従って、任意のアプリケーションでできるという訳ではありません。
アンテナハウスのXSL Formatterは、上の(1)、(2)の両方の方法を実装しています。
図1 GDIと関係なくPDF生成ライブラリーの関数(API)を使ってPDFを出力
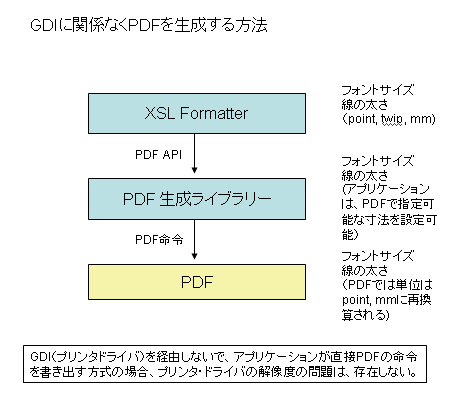
※アンテナハウスのPDF生成ライブラリーはOEMで提供しています。関心をお持ちの方は、oem@antenna.co.jp までどうぞ。
図1の方法で出力したPDFファイル:Download
図2 PostScriptプリンタ・ドライバに対して直接PostScriptを出力
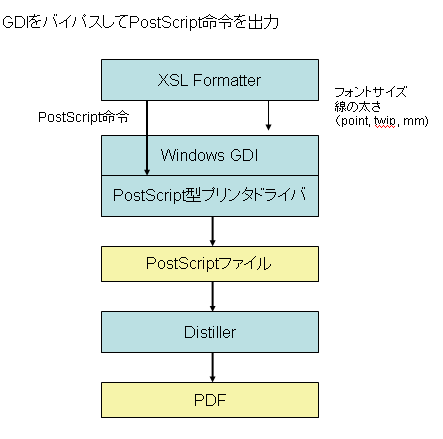
図2の方法で出力したPDFファイル:Download
※このPDFはAcrobatのプリンタ設定を72dpiにしてみましたが、それにも関わらず、細い線も精確に出力されます。拡大することで確認できます。
PostScriptプリンタというのは、Windowsでは別格の扱いになっていますので、このようなこともできるのですね。また、アプリケーションからAcrobatをPostScriptプリンタ・ドライバとして認識できますので、GDIをバイパスして、Acrobatにどんな細い線幅でも出力することができます。昨日の出力試験では、Microsoft Wordはそれをやってないようなのですが。これは謎です。
いずれにしても、上のいずれかの方法を使えば、WidnwosでGDIの機能的制約を受けることなく、PDFで設定可能な機能を自由に使いこなしたPDFを作成できることになります。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月16日
Acrobatの解像度設定 – PDFの作成方法(22)
話は、2006年02月14日の – PDFドライバの解像度に戻りますが、Acrobatの解像度設定についてチェックしてみます。
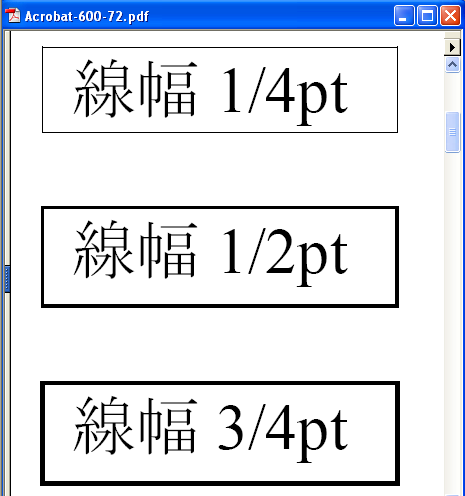
まず、Microsoft Word2003で作成した細い線幅(1/4ポイント、1/2ポイント、3/4ポイント)の3種類の線種が、解像度設定でどう変わるかをチェックしてみましょう。
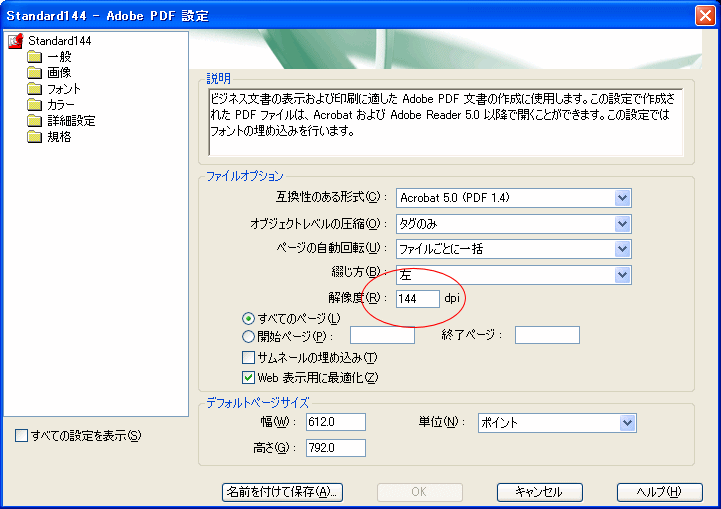
ややこしいことに、Acrobatで解像度を設定するダイヤログは、ジョブ設定のダイヤログとプリンタの設定のダイヤログの2箇所にあります。
・Acrobat 7の ジョブ設定のダイアログ
図1
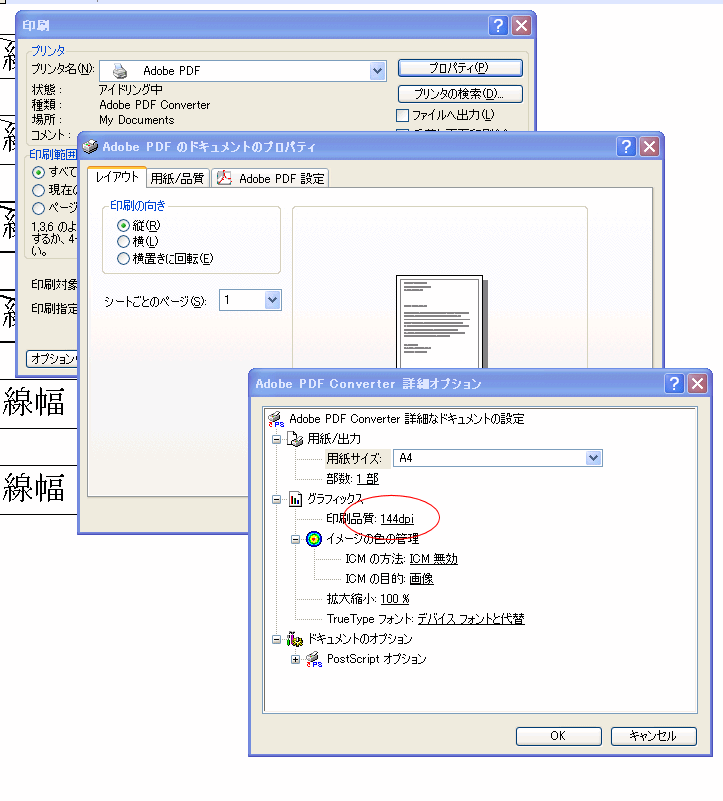
・Acrobat のプリンタの設定
図2 プリンタのプロパティダイアログからレイアウトタブの詳細設定ボタンで表示されるダイアログです。
まず、ジョブ設定の解像度を600dpiに固定して、プリンタの設定の解像度を72dpi、144dpi、300dpiに変更してPDFを作成してみました。これをAdobe Readerで300%拡大表示したのが次の3つの図です。
図 プリンタ設定72dpi ジョブ設定 600dpi

図 プリンタ設定144dpi ジョブ設定 600dpi

図 プリンタ設定300pi ジョブ設定 600dpi

この3つの図を見ますと、プリンタ設定を72dpi、144dpi、300dpiに変更すると各線の太さが少しずつ変わり、300dpiではもっとも精確にPDFに出力されていることがわかります。つまり、プリンタ設定72dpi、144dpiでPDFを作成すると線種が指定した太さで出力されていません。このことから、Microsoft WordはAcrobatでPDFを出力するとき、AcrobatをPostScriptプリンタとして看做して、線種を精密に出力する処理を行っていないという推定が成り立ちます。言い換えると、Microsoft WordはAcrobatをGDI型プリンタ・ドライバとして認識しているということになります。そうなんだろうか?
なお、プリンタ設定600dpiでジョブ設定を72dpiしてPDFを出力したものを、Adobe Readerで300%拡大表示すると次のようになります。
図 プリンタ設定600pi ジョブ設定 72dpi
ジョブ設定の解像度を最小値72dpiにしても線の太さへの影響はありません。どうも、ジョブ設定の解像度は線種には影響がないようです。Acrobat のヘルプの記載では、ジョブ設定はPostScriptからPDFにする時点で機能するようで、WindowsのGDIには影響を与えていないことがわかります。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年02月15日
Foxit ReaderでもPDFの細い線は表示できない
2月13日のブログで、WindowsのGDIで細い線が表示できないと間違ったことを書いてしまいました。
※2月14日に訂正済。
これは、XSL Formatterの画面で、下のようにディスプレイの1ドットの幅よりも細い線が正しく表示できなかったので、WindowsのGDIの仕様(制限事項)なのかなと思ったわけです。実は、WindowsGDIの制限事項だと思ったのは、Formatterのみではなく、Foxit Readerという別のソフトでも確認してみたのですが、同じように細い線が正しく表示できていなかったからなのです。
PDFを表示するソフトといえば、AdobeReaderがもちろんダントツにポピュラーですが、それ以外にもPDFビューアはあります。その中で、コンパクトで高速なことで人気があるのが、このFoxit Readerです。
2月13日に紹介しました表示できない細い線のデータのファイルをPDF化し、他のソフトで表示できるかどうかを試してみたのですが。そうしますと、Adobe Readerは正しく表示できましたが、Foxit Readerでは細い線を正しく表示できていませんでした。
次の3つの画像をご覧ください。
図1 XSL Formatter V3.4 の画面
※ 2月13日に細い線を表示できないバグを修正する前の画面表示です。このバグは既に修正され、全ての線が表示できるようになっています。
図2 Foxit Reader の画面
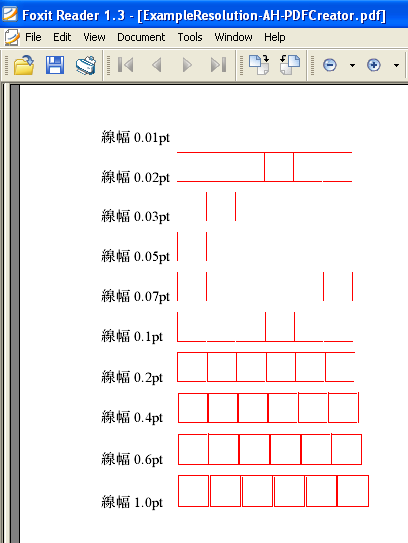
※Foxit Reader V1.3 Build 0930。細い線が正しく表示できていない!
図3 Adobe Acrobat6 の画面
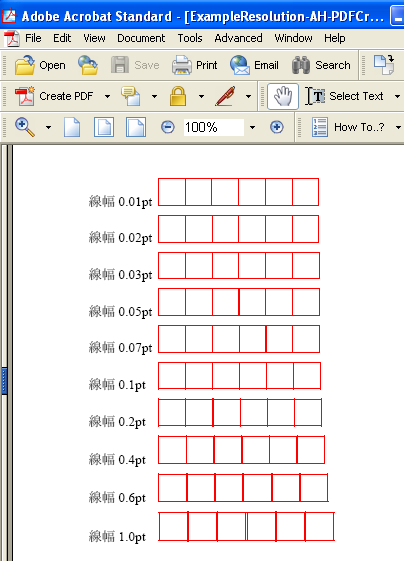
この3つを並べてみて、2つのソフトで表示できないのだから、このような細い線は正しく表示できないのがWindowsの仕様(制限事項)で、Acrobatは自分で線を太くして表示しているんだろうと思ってしまった訳です。
しかし、1ドットより細い線は1ドットに太らせて表示するのがGDIの仕様ということがわかりました。となりますと、Foxit Readerも細い線を正しく表示できないというバグがあるということになってしまいますね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (3) | トラックバック
2006年02月14日
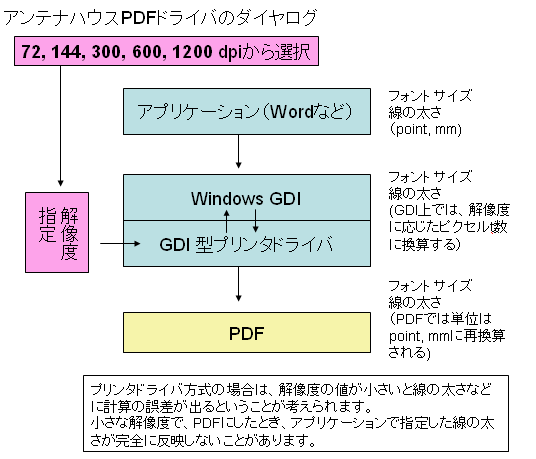
PDFの作成方法(21) – PDFドライバの解像度(続き)
昨日は、Windowsのプリンタ・ドライバとしてPDFを出力するソフト(アンテナハウスPDFドライバなど)の場合、解像度設定値によっては、出来あがるPDFの中で、線の太さが正しく表現されるかどうかに影響がでることを示しました。例えば、Microsoft Wordで設定できる最小の太さの線は、1/4ポイント(約0.09mm)です。この線を表示するのには、最低でも300dpi以上の設定が必要です。
このようなことは、アプリケーションはWindowsのGDIの機能を使って描画し、PDFドライバは、描画のデータをGDIから受け取ってPDFを作成するので、その過程で生まれるものです。
昨日の例で言いますと、Microsoft Wordを使って、1/4ポイント、1/2ポイントの線を、72dpiの設定でPDF化したとき、線の太さが正しく表現できていないとがわかりました。Microsoft Wordは、これらの線を72dpiでは印刷できないことを知っていて、ドライバの設定が72dpiの時は線を太くして出力しているものと思います。
図 GDI型のPDFドライバの解像度設定の仕組み
ちなみに、AcrobatのようなPostScriptプリンタ・ドライバ型のPDF作成ソフトを使ってPDF化する時、(アプリケーションによっては)解像度設定の影響を回避することが可能です。
この理由は、PostScriptプリンタはWindowsで特別扱いされているので、アプリケーションはGDIを経由しない(バイパスして)で、PostScriptの命令をプリンタに直接出力することができるからです。このことは、2005年11月18日 PostScriptプリンタドライバとGDI型PDFプリンタドライバの相違で少し触れました。PostScript命令では、線の太さなどはドット単位ではなく論理的な寸法になりますので、精度の高い出力が可能です。
なお、PostScriptプリンタ・ドライバを認識し、GDI型のプリンタ・ドライバへの出力との切り替えを行うのはアプリケーションの役割です。つまり、技術的には可能ということであって、実際に、全てのアプリケーションが、PostScriptプリンタドライバを認識して、特別な処理をしているとは限りません。PostScriptプリンタ・ドライバを使ったからといって、常に精度が出るわけではなく、あくまで使用しているアプリケーションがPostScriptをうまく出力しているかどうかに依存するということです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月13日
PDFの作成方法(20) – PDFドライバの解像度
2005年11月18日にPostScriptプリンタドライバとGDI型PDFプリンタドライバの相違について、WindowsのGDIの影響を受けるかどうか、という違いがあることを説明し、具体的な例として、カラーの処理を挙げました。
今日は、もうひとつの例として、解像度の問題を取り上げてみます。
Microsoft Windows、及びそのアプリケーションはディスプレイやプリンタを統一のGDI (graphics device interface)という機能を使って扱っています。アプリケーションが、直接、プリンタやディスプレイなどの物理デバイスに出力することはできません。原則としてGDI経由の出力になります。
プリンタでの印刷やディスプレイなどの表示デバイスには解像度という表示能力を表す尺度があり、dpiという単位で表します。dpiとはインチあたりのドット数の略です。デバイス上の1ドットは物理的なものです。これに対して、WindowsGDIの上では画像は1ピクセル単位で処理します。ピクセルというのは論理的なものですので、実際の出力ではGDI上のピクセルがデバイスのドットに割り付けられます。この割付はWindowsやデバイス・ドライバの役割となります。(以下、ここではとりあえず、ドットとピクセルを区別しないで考えます。)
GDI上で線を引くときは、ピクセル単位の塗りつぶしで表現します。ですので、次の図のように、GDIの上で表示できる線の最小の太さは1ピクセル幅ということになります。これは、デバイスの上では1ドット幅の線に相当します。
図 表示できる最小の線幅
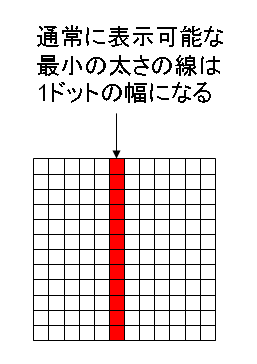
ここから予想されることは、アプリケーション・ソフトが細い直線を引いたとしても、GDIを経由する限り、それを実際にディスプレイの画面に表示したり、物理的なプリンタに出せるとは限らないということです。
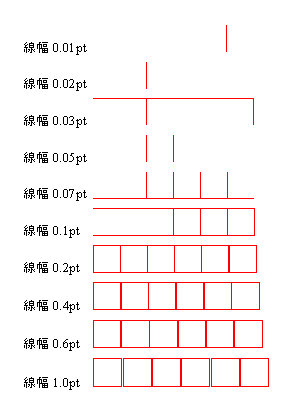
実例で試してみましょう。まず、直線の太さを0.01ポイントから少しずつ太くしていくようなデータを作ります。
表示に使用するWindowsのディスプレイは、96dpi(1インチに96ドット)の解像度に設定してありますので、このディスプレイの上の1ドットの大きさは、(72ポイント/1インチ)÷(96ドット/1インチ)=0.75ポイントとなっています。
∵1インチは72ポイント。96dpiは1インチに96ドット。
1ポイントは約0.35mmですので、100分の1ポイントは、0.0035mmに相当します。このような細い線を指定できるWindowsアプリケーションは少ないと思いますので、普段はあまり眼にしたことがないかもしれません。XSL Formatterを使って、この線を表示してみます。
図 Windowsの画面にどの位の太さの線を表示できるか

この表示結果を見ますと、Windowsはディスプレイ上の1ドット相当よりも細い線も画面に表示しているようです。但し、細い線は正しく表示できていないことが理解できます。これは、ディスプレイの物理的な表示能力を超えているのですから、まあ、やむを得ないともいえます。(2006/2/14削除)
この表示結果を見ますと、Windowsは、ディスプレイ上で1ドット相当よりも細線も表示しています。これは、WindowsのGDIは1ドット相当よりも細い線については1ドットにして表示するためだそうです。(2006/2/14挿入)
解像度に応じて、ドットの大きさがどの位になるかを次の表に示しました。ディスプレイと比較しますとプリンタの解像度はもっと大きいのが普通です。通常のプリンタですと300dpiから600dpiでしょうか。例えば、600dpiのプリンタでは1ドットの大きさは0.12ポイントとなります。
| DPI | 1ドットの幅(単位:ポイント) |
|---|---|
| 72 | 1.00 |
| 96 | 0.75 |
| 144 | 0.50 |
| 300 | 0.24 |
| 600 | 0.12 |
| 1200 | 0.06 |
| 2400 | 0.03 |
さて、例えば、Microsoft Word2003の罫線は、細いほうから1/4ポイント、1/2ポイント、3/4ポイントが設定できます。そうしますと、上の表から、この太さの線を正しく表示するのには、最低限600dpi、144dpi、72dpiの解像度が必要ということになります。
次に、実際に試して見ましょう。
Microsoft Word2003で、1/4ポイント、1/2ポイント、3/4ポイントの太さの罫線を引きます。
Wordの画面(200%に拡大)は次のようになります。
図 Wordの画面(200%拡大)

・200%拡大しても1/4ポイント、1/2ポイントの線の太さは画面上で識別できません。
これをWordからアンテナハウスPDFドライバを使って、解像度設定を72dpi、300dpi、600dpiに設定してPDFを作成します。これを、Adobe Readerで300%に拡大して画面に表示します。
図 GDI型PDFドライバの解像度72dpiの時のPDFの線の太さ

・72dpiでは3種類の線の太さを識別できていないことがわかります。
図 GDI型PDFドライバの解像度300dpiの時のPDFの線の太さ

・300dpiではPDFの上でも3種類の線の太さが判別できます。
図 GDI型PDFドライバの解像度600dpiの時のPDFの線の太さ

・600dpiは、画面上で拡大してみる限り、300dpiとあまり変わりません。
この3つの例から、GDI型PDFドライバでPDFを作成するとき、正しく表示できる線の太さは解像度設定によって変わることがわかります。これはGDI型PDFドライバは、WindowsのGDIの仕組みに依存しており、GDIがドット単位での処理を行っているためです。大雑把に言えば、どのGDI型PDFドライバでも似たような結果になるはずです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年02月12日
もっともsuckでないソフト
YahooのXSL-FOグループのメーリング・リストにShameless Self Promotionという風変わりなメッセージが投稿されました。投稿者を見ますと、Eliot KimberさんというTexasのXMLドキュメントの仕事をしているコンサルタントです。
こんど、XMLとそれに関連する技術的な話題についての個人ブログをはじめたので、見てくれという投稿です。ブログはこちらです:
http://drmacros-xml-rants.blogspot.com/
タイトルが面白い。
DR. MACRO'S XML RANTS
Rantという単語は知りませんでしたが、辞書を引くと「どなること・大言壮語」ってあります。なるほど。納得です。数年前、シカゴの同業のコンサルタントの事務所を訪問したのですが、その人に、Kimberさんってどんな人?と聞きましたら、曰く「丘の上にのぼって叫ぶ人だよ」とのこと。
このブログはまさしくその形容が当てはまります。
Kimberさんのプロフィールによりますと、大学を卒業後、IBMのリサーチ・トライアングルでテクニカル・ライターの仕事を始めてから、25年間マークアップ言語をベースとする執筆と出版 — この日本語は、あまり適切ではないかもしれません。テクニカルライティングというとマニュアル類の制作が多いのだろうと思います。— に携わった。SGMLやXML関係の仕様の制定にも数多く関与し、現在は、XSL-FOのV1.1仕様のサブ・ワーキンググループのメンバーとしても積極的に参加している人です。
このsuckって単語は、私の使っている35年前の三省堂の辞書には載っていませんが、Webで調べると、むかつくほどひどいという意味です。
彼によると、標準をサポートするソフトウェアで、標準が要求することを完全にサポートしているものはなく、また、大抵のソフトウェアにはバグがあり、パフォーマンスが悪いなどの問題があるので、必然的に、すべてのソフトウェア製品はむかつくほどひどいってことになるとのこと。
その中で、suckでない(ひどくない)製品の基準は、
(1) 標準をどれだけサポートしているか。特にユーザにとって必要な要求をサポートしている程度が高ければ高いほどsuckじゃない。
(2) ソフトウエアの工学的にみて優れていて、パーフォーマンスが高く、バグが少なく、コストパーフォーマンスが良く、サポートが良く、ドキュメンテーションが良く、インテグレーションがし易いほどsuckじゃない。
で、その次の記事は:
比較的suckじゃない、幾つかのツール
ここで、トップに彼が出会ったツールの中で最もsuckじゃないツールとしてAntenna House XSL Formatterを紹介してくれました。
言い換えますと、Antenna House XSL Formatterが最も良いツールだと言ってくれたわけです。
XSL-FOは標準仕様になってから、満4年半が経過して、20種類近くの実装が出てきています(2006年02月08日 XSL V1.1 仕様についての多言語組版研究会開催を参照)。
その中で世界NO.1というのは、自分で言うのもなんですが、オリンピックの金メダルに相当すると言っても良いと思います。ちょうど、今、トリノ・オリンピックですが。
オリンピックの金メダルと違って、ビジネスの金メダルは、毎日が戦いです。チャンピオン・シップを過去のものにしないように、今後も、さらに精進したいものです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月11日
PDFと文字 (43) – ラテンアルファベットのリガチャ
さて、2006年01月26日 PDFと文字 (33) – ラテンアルファベットで、Unicodeのラテンアルファベット・ブロックを取り上げてから、結合ダイアクリティカルマークの検討に随分とお話の回数をかけてしまいました。
次にラテンアルファベットのリガチャについて検討してみましょう。リガチャについては、アラビア文字の時にも紹介しましたが、2つ以上の文字の組み合わせが出現するとき、文字のデザイン上の配慮から、二つ以上の文字を合成した別の形状のグリフに置き換えるものです。
2006年01月23日 PDFと文字 (31) – リガチャを参照。
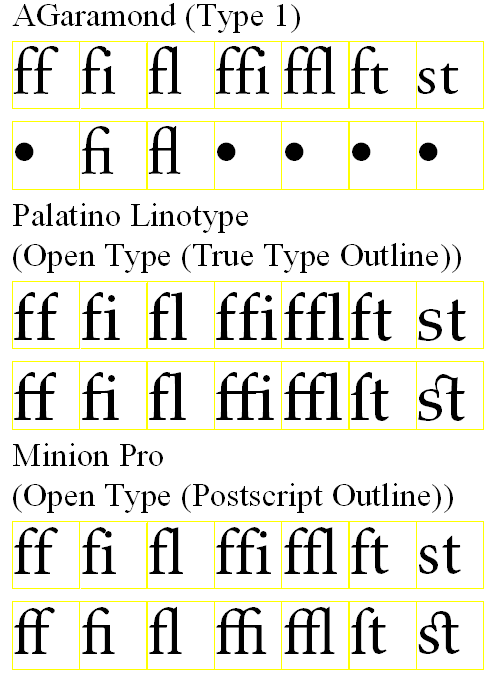
ラテンアルファベットのリガチャはUnicodeでは次にコードポイントが与えられています。
・ラテンリガチャ:U+FB00-U+FB06 コードチャート
このブロックではラテンアルファベットのリガチャは次の7文字になっています。
U+FB00:ff
U+FB01:fi
U+FB02:fl
U+FB03:ffi
U+FB04:ffl
U+FB05:ft
U+FB06:st
次の図は、AGaramond、Paratino Linotype, Minion Proの3つのフォント・ファミリーについて、リガチャなしの文字の組とU+FB00~U+FB06を対比させたものです。AGaramondのようなType1のフォントは、U+FB01、U+FB02しかグリフがないことが分かります。他のフォントでもU+FB02については、fとlの2文字の配置とわずかな相違しかありません。
Wikipedia(英文)のリガチャの説明を見ますと、もっと他にも挙げています。例えば、次の文字は、Wikipediaではリガチャとされていますし、Unicodeでも文字の名前にリガチャという文字を含んでいます。
U+00C6:Æ Latin capital ligature AE
U+00E6:æ Latin small ligature ae
U+0132:IJ Latin capital ligature IJ
U+0133:ij Latin small ligature ij
U+0152:ΠLatin capital ligature OE
U+0153:œ Latin small ligature oe
次の文字は、文字の起源はリガチャとされていますが、Unicodeの文字名ではリガチャという名前は付いていません。
U+0028:& Ampersand (文字の起源はEtのリガチャ)
U+00DF:ß Latin small letter sharp s (文字の起源は、ſ Latin small letter long s とsのリガチャ)
この他、ラテン拡張Bには、クロアチア文字としてラテンアルファベット2文字を組み合わせて1文字にした文字があります。
U+01C4~U+01CC
この他に、2文字を組み合わせて1文字にしたものが幾つかあります。これらの2文字のセットにコードポイントを与えた文字とリガチャはどのような関係なのでしょうか?両者の境界が曖昧なようにも思います。
リガチャについては、2つの文字が1行に入りきらない時は、必ずしも合成形に置き換えないこともありますので、本質的には文字コードというよりは、特別な表示形と言うべきでしょう。
また、これらのリガチャの形状の中には、Unicodeで互換分解マップが与えられているものがあります。(2006年01月30日 PDFと文字 (37) – 結合文字列の正規合成の分解可能な文字の説明を参照。)
これらの互換分解マップが与えられる文字は、例えば検索では、互換分解した文字列でヒットさせることが望まれるのだろうと思います。この点から見ても、ひとつの文字として扱うものではないということになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月10日
英語版ブログ Tokyo PDF Story を開始
日本語のブログ開始から既に3ヶ月、1000回連続の目標からしますと、1割まで書きましたが、ブログはかなり好評で大勢のアクセスを頂いています。ありがとうございました。
これに気をよくして、というわけはなくて、かねてからの構想で、このブログの英語版を開始しました。
英語版は、題名を「Tokyo PDF Story」としました。
既に、お気づきかもしれませんが、右下の方に、[English version]というリンクがあります。
ここをクリックしていただきますと、英語版のブログページにジャンプします。
アンテナハウスでは、現在、一部の製品、主としてXML関係の製品を英語版で販売しています。これから、PDF関係の製品も海外で販売して行きたいと考えていまして、まず、ブログから英語版を始めてみました。まず、「ブログから始めよ」というわけです。
それに、せっかく、Unicodeなどの批判をしても、日本語でやっていたのでは、肝心のところに声が届かないでしょうしね。
ただ、英語でブログを毎日書くだけの英語力はちょっとありませんので、さるところで翻訳してもらっています。
簡単な英語で書いてありますので、たまには、ぜひ、英語版の方もご覧ください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月09日
PDFと文字 (42) – ハングル音節文字の合成
次に、2006年02月03日PDFと文字 (40) – Unicode標準形式NFCの問題点で挙げましたが、ハングルの字母(Jamo)で表されたテキストをNFCにすることでハングル合成文字(Johab)にすることが可能、という点について調べてみます。
以前に、2006年01月18日PDFと文字(26) – ハングルの扱いで、ハングル音節文字(Johab)は字母からプログラムで合成できると書きましたが、これは具体的には、字母で表された文字列をNFCにするということを指します。
こんどは、実際に試して見ましょう。
(1) まず、ハングルの「こんにちは」は、「アンニョンハセヨ」と言うらしいですが、このハングル表記を調べます。そして、各音節文字を初声、中声、終声に分解します。
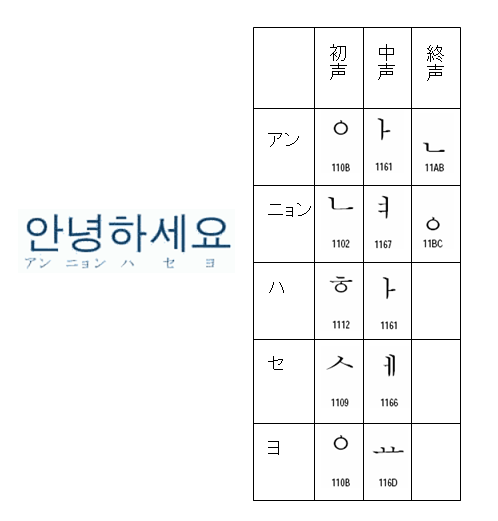
(2) これをUnicodeのJamoの文字列として表します。次のようになります。

(3) この文字列をXSL FormatterV4.0(Alpha)で標準形NFCにして表示します。
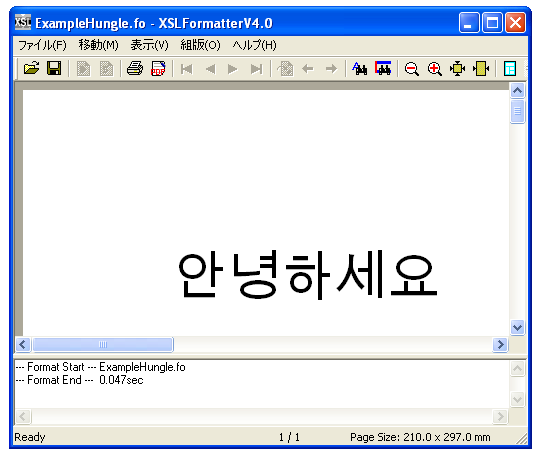
このように、ハングルの字母で表した文字列をNFCにすることで、合成文字Johabにして表示することができることを確かめることができます。
試しに、同じ文字列をMicrosoft Word2003で表示しますと次のようになってしまいます。
![]()
どうやらMicrosoft Word2003は、まだ、ハングルの字母を合成することはできないようですね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月08日
XSL V1.1 仕様についての多言語組版研究会開催
現在、W3C(World Wide Webコンソーシアム)でExtensible Stylesheet Language (XSL-FO) 仕様の改訂作業が進んでいます。
昨年(2005年)7月にXSL-FO V1.1 仕様の最終ドラフトが公開され、一般からの意見公募がありました。その後、W3CのXSLワーキング・グループは一般の意見を反映して、ドラフトの最終検討を行っていました。この作業はまもなく終わり、2月下旬には、勧告候補(CR)版として公開される見込みです。
勧告候補版になりますと、仕様として安定し、実装を進める段階となります。
XSL-FOのV1.0仕様は、2001年10月15日にW3Cの勧告となりました。XMLを印刷仕様の高品位なレイアウトを指定することができます。仕様が公開されていて誰でも実装できますので、世界にはオープンソースのプロジェクトを初め、商用ソフトまで約20種類近い処理系があります。
これらは、殆どが、XMLをPDFにする用途で使用されていると思われます。
アンテナハウスのXSL Formatterは、その中の一つであり、唯一の日本製です。XSL-FO仕様を忠実に実装している点、多言語組版、高速性、大きなページ数の組版が可能などの点で、世界最高水準と認められています。
次期バージョンXSL Formatter V4.0で、XSL-FO V1.1の仕様を実装すべく、開発を進めています。情勢が整い次第、公開して、お試しいただく予定です。
そこで、この機会に、XSL-FO V1.1 仕様で強化された点についての解説をしていただくための研究会を、次の通り、開催します。多くの方々のご参集を賜りますようご案内致します。
参考資料
1. Extensible Stylesheet Language (XSL) Version 1.1
(W3C Working Draft 28 July 2005)
2. Extensible Stylesheet Language (XSL) Version 1.0
(W3C Recommendation 15 October 2001)
報告者
藤島 雅宏氏 (有限会社イー・エイド 代表取締役)
(財)日本規格協会(JIS)の標準化調査委員会のユビキタス委員会、技術分科会の分科会1-WG1 委員(XSLのJIS原案策定などに参加)
参加費用
3,150円(消費税込み)
参加資格
どなたでもご参加頂けます。
開催日・時間
2006年2月27日(月曜日)16:00-18:00
開催場所
アンテナハウス株式会社 セミナー・ルーム(定員20名)
JR市ヶ谷駅徒歩7~8分、地下鉄都営線市ヶ谷駅徒歩3~4分
お申し込みは、こちらでどうぞ。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月07日
PDFと文字 (41) – Unicode標準形式NFCの問題点(続き)
2006年02月03日にPDFと文字 (40) – Unicode標準形式NFCの問題点で、合成除外文字の中の1種類Singletonについて説明しました。
合成除外文字のリストには、Singletonの他に、次の種類があります。
(a) スクリプト依存
デバナガリ文字、ヘブライ文字の合成文字など67文字。
(b) Unicode3.0以降に追加された合成文字
数学記号1文字、音楽記号13文字
(c) 正規分解が結合文字から始まる合成文字
4文字
これらの文字は、標準形NFCにすると分解されたままになってしまい合成されません。
Singletonの問題を合わせて考えますと、組版ソフトのように文字の形が重要な意味をもつソフトでは、Unicode文字列を安易に標準形NFCにする処理を既定値にするのは危険なので避ける方が良い、という結論になりそうに思います。
次に、2006年02月03日に挙げた2つ目の
(2) Unicodeにコードポイントを持たない文字を指定したときの問題
について検討します。これは、UAX#15の表5にも載っていますが次の図のような例です。
これは、Latin capital letter D with dot aboveとCombining letter dot belowという結合文字列を標準形NFCにすると、Latin capital letter D with dot belowとCombining letter dot aboveに化けてしまうという類の問題です。
NFCにする処理では、最初に、合成済の文字を分解し、そして正規並び替えを行います。(2006年01月30日PDFと文字 (37) – 結合文字列の正規合成を参照してください。)
並び替えで、Combining letter dot belowとCombining letter dot aboveの順序が入れ替わります。この結合文字列を正規合成すると基底文字DにCombining letter dot belowが先に結合してしまいます。上と下の両方にドットの付いたDはUnicodeにはありません。従って、Combining letter dot aboveが独立した文字として残ってしまいます。
正規並び替えでは結合クラスが小さい文字を、結合クラスが大きい文字より先になるよう並び替えるため、この例のような問題が起きるケースは、少なくないと考えられます。
元はといえば、Unicodeの正規分解や正規合成の概念は、分解可能な文字、合成済みの文字を想定して組み立てられています。従って、標準形NFCの適用範囲は、分解可能な文字、合成済みの文字、及びそれらを分解した文字だけからなる文字列に限定されるのではないかと思いますが、どうなのでしょうか?
実際のところ、上の例で、最初の結合文字列と最後の結合文字列が正規等価である、といわれても認めがたいように思います。少なくとも、結合文字列の表示が等価になるかどうかは、フォントとレンダリングするアプリケーション依存となってしまいます。
ちなみに、上の2つの結合文字列をWord2003で表示しますと次のようになります。

正規等価な結合文字列の表示が同じになっていないということがお分かり頂けると思います。
結合文字列をレンダリングするアプリケーションが、結合文字の位置を自在に制御して、基底文字に対して正しい位置に配置できるのであれば、標準形NFCなど考慮しなくても、結合文字列をダイナミックに合成できるわけです。この場合、標準形NFCは無用の概念となります。
このように、文字をレンダリングするという観点から考えますと、標準形NFCというのはやや中途半端な仕様ということになりそうです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月06日
三井物産株式会社の業務処理マニュアルPDF化
Page2006でエクスイズムが発表した事例紹介の最後に、三井物産の業務処理マニュアルのPDF化で活躍したXSL Formatterについて取り上げたいと思います。
このシステムについては、既にいろいろなところで取り上げられています。例えば:
(2) 日経システム構築 事例研究 問題解決の軌跡 2005年6月号 pp.41~45
「サーバ増設17台」に絶句 アプリ再開発で4台増に抑える
これは、三井物産が2004年に、「SAP R/3」で業務を電子化するのに伴い、その一部の業務マニュアルの管理システムを構築する際に、NeoCoreを使って成功したという事例です。この事例は、NeoCoreの応用例として幅広くPRされていますので、ご存知の方も多いと思います。
業務マニュアル・システムでは、業務マニュアルをPDF化するのが大きな特徴とされています。このPDF生成には、XSL Formatterが採用されているのですが、残念ながらいままで、このことはあまり大きくPRされていませんでした。まあ、三井物産はNeoCoreを販売していて、そのPRだから当然と言えば当然なのですが。
今回、エクスイズムの徳江社長のプレゼンテーションで、ようやくこのことがPRされましたので、もうかなり古い事例ですが、取り上げてみました。
次の2枚の図は、Page2006でのプレゼンのスライドです。

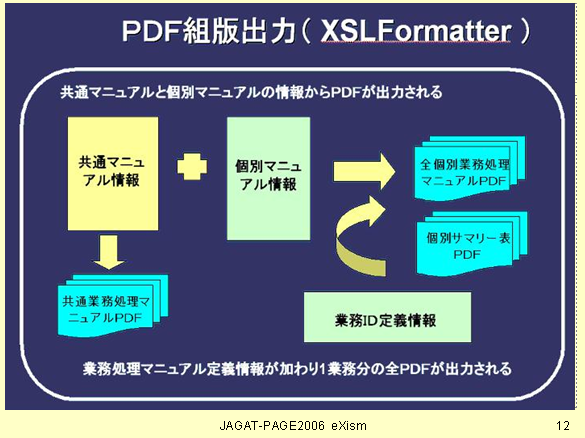
ということで、業務マニュアルのPDF化にXSL Formatterを使っていることがお分かりいただけると思います。このこと自体は、それ程目新しい話ではないのですが。
上記の日経システム構築の記事によりますと、このシステムの検討では、最初は、AdobeのFormServerを使おうとしたが、パーフォーマンスが悪くて採用できなかった。そこで、.NETフレームワークで再構築、短期間で成功したとあります。ということは、Adobe Form ServerよりXSL Formatterの方が、ずっとパーフォーマンスが良い、ということが証明されたと考えても良いかな?と、私としては密かに喜んでいた次第です。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年02月05日
Webで加盟店情報をPDF化
エクスイズムが発表した、次の事例は、あるクレジットカード会社の会員向けオンデマンドDM制作システムの一部として開発された、加盟店情報をWebから加盟店自らが制作するシステムです。
大抵どこのカードでも、会員に定期的にDMを送っていますが、そのDMの中には数多くの加盟店情報がカラフルに印刷されています。DMには沢山の加盟店情報が盛り込まれますので、加盟店情報の種類が多く制作が大変です。一方で、カード会員に送るDMではできるだけ旬の情報を提供しなければなりません。このためDMを印刷する直前までひきつけて、フレッシュな情報を入力したい、というリアルタイム性が要求されます。
このような、二律背反するニーズにどのように応えるか?それが、クレジットカード会社や印刷会社の知恵の絞りどころでしょう。
このシステムでは、加盟店自らが随時Webブラウザから情報を入力できます。Webブラウザから情報を入力するというのは、別に目新しくはないことですが、さらにこのシステムでは入力した情報を即時にレイアウトしてPDF化し、加盟店が自らPDFを見て校了できることが特徴です。
仕組みは次のようになります。
加盟店がWebブラウザから入力した情報は、インターネットを経由してデータ・センターのデータベースに内部情報として、次のようなXML形式で蓄積されます。
<?xml version="1.0" encoding="UTF-8" ?>
<restaurant>
<kana>インショクジョウホウサンプルデータ</kana>
<name>飲食情報サンプルデータ</name>
<type>メキシコ料理</type>
<address>武蔵野市吉祥寺南町2-20-8 NISHIKAWAビル2階</address>
<information>JR吉祥寺駅より徒歩約7分</information>
<tel>
<number>0422-72-0410</number>
<comment />
</tel>
<business_hours type="営">5:30PM~翌5:00AM</business_hours>
<holiday>年中無休</holiday>
<contents>カラフルでエキゾチックなインテリアの店内は陽気でロマンチックなメキシコそのもの。夜はメキシカンバンドの奏でるメロディを聴きながら料理に舌鼓みをうってみては?</contents>
<budget>5,000円~10,000円</budget>
<url>http://www.exism.co.jp</url>
<discount type="1">
<discount_image>image/pricedown.pdf</discount_image>
<discount_type>注文時</discount_type>
<discount_plan>優待ポイント</discount_plan>
<discount_detail> お好みのケーキを1皿サービス <期間> 2/25~3/31 *2名以上のグループに限る*PAGE2006の入場者にはグラスワイン1杯サービス</discount_detail>
</discount>
<icon>
<new_shop>image/new.pdf</new_shop>
<pay1>image/pay01.pdf</pay1>
</icon>
<image type="1">
<image1 >image/A051231034.jpg</image1>
<image2 >image/A051231034.jpg</image2>
<caption>写真のケーキは一例です</caption>
</image>
<edition_code>12345678</edition_code>
</restaurant>
加盟店がデータを入力し終わって、Webブラウザからボタンを押しますと、このXMLは、サーバ側で動くXSL Formatterによって瞬時にレイアウト・PDF化されて、ブラウザに送信されます。
図 加盟店情報レイアウトのサンプル

加盟店側では、ブラウザ上でPDFを表示して内容を確認して、OKであれば校了となります。校了となったPDFはサーバ上のコンテントマネジメントシステムに順次登録されます。あとは、カード会社ではPDFを随時確認したり、DM制作時に必要に応じてそれを取り出して、DMを組み立てて印刷に回ります。
自動組版とレイアウトの自由度について
このシステムでは、PDF作成はサーバ側での完全な自動組版となりますので、加盟店側にはWebブラウザ以外にはなにも必要ありません。また、カード会社・印刷会社でも加盟店情報のレイアウト変更には手間をかけることはありません。従って、従来の加盟店情報をレイアウトするオペレータの作業コストは大幅な削減になります。
一方、レイアウトは予めパターン化しなければなりませんので、人間のデザイナーが自由自在にレイアウトする場合のようなフレキシビリティは、残念ながらありません。しかし、例えば、上のレイアウトパターンでは、画像をひとつにすれば文字の配置は自動的に変更になります。
図 加盟店情報レイアウトのサンプル(画像1個の例)

印刷業界向けの自動組版システムの多くは、自動組版と言いながら、実際はオペレータが後で修正することを前提とする、いわば半自動組版を自動組版と呼ぶケースが多いようです。ここで紹介しましたような完全自動組版というのは意外に少ないと思います。
完全自動組版においてはオペレータの人手をゼロにすることになります。オペレータの作業量をゼロにしながら、その中で、どの程度のレイアウトの自由度を実現していくかは、レイアウトを指定するスタイルシートの作成者の腕前とも言えるでしょう。
組版ソフト側も、ソフトウェアに内蔵するインテリジェンスを高めることが求められるのはいうまでもありません。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月04日
自動組版によるPDF生成で六法全書を出版
今日は、2月1日から3日に東京・池袋で開催されたPage2006で、(株)エクスイズムの徳江社長がプレゼンテーション発表した自動組版とPDF利用事例を紹介してみたいと思います。
エクスイズムは、2003年3月にアンテナハウス、株式会社ニシカワ、セザックス株式会社の合弁でドキュメントXML化、XMLWebアプリ開発、自動組版、印刷媒体制作の連携を実現する会社として設立した会社です。設立後3期になって、XML関連で優れた実績をあげることができるようになってきました。
特に、アンテナハウスにとっては、XSL Formatterの市場を広げていくために貴重な存在となっています。
エクスイズムの事例の中で、なんと言っても一番に紹介したいのは、東京法経学院出版向けに開発した「六法編集システム」です。東京法経学院出版は、有力資格試験取得のための受験指導などを中心とする学校ですが、同時に「登記六法」、「不動産六法」などの六法全書を編集・出版しています。

これらの六法全書は、また、電脳六法としてWebでも提供されています。
法律については、私はあまり詳しくなくて、天下の秀才の人たちが、次々に新しい法律を作り出している位の知識しかありません。しかし、これが結構身近なところにも影響があり、常識と思っていたことが、いつの間にか変更になって困ったこともあります。
そういう時に頼りになるのが、もろもろの法律を集めた六法全書というわけです。六法全書は、それだけに小さな文字でページ数が多く膨大な情報量になります。また、法律の改正情報を迅速に集めて書籍にしなければなりません。そのような理由で、XMLデータベースと自動組版という技術に最も向いた分野と思います。
エクスイズムが、今回開発した六法編集システムは、データの蓄積にXMLデータベースNeoCoreを使います。データの入力にはWebブラウザを使い、Webブラウザから法律の改訂情報を入力して、データベースに蓄積します。
こうした情報の入力は随時行っていき、出版の時期になりましたらデータベースから取り出して自動組版してPDFにします。この自動組版の部分を担当するのが、当社のXSL Formatterです。XMLで作成しデータベースに蓄積されている原稿を、データベースから取り出す際にスタイルシートでXSL-FOに変換し、XSLFormatter瞬時にPDFを生成することができます。
この六法全書の特徴はページの本文のレイアウトが縦書でしかも多段組になっていることにあります。

特にややこしいのが、膨大な量の索引も自動的に作り出すわけですが、索引にはページ番号だけではなく、「上・中・下」という段の位置まで指定できなければなりません。これも実現したのがひとつの技といったところです。
アンテナハウスでは、今回、これを実現するためXSL-FOの仕様を独自拡張しました。(現時点で、Webでは公開されていませんが、オンライン・ヘルプには載っています。)索引を作るには、通常は、索引語の後ろに、fo:page-number-citationを指定します。組版を完了すると、これは、ページ番号に置き換わります。今回の拡張で、fo:page-number-citationが置き換わるページ番号に段まで指定できるようにしました。具体的には、axf:number-type=”page-and-column”とするとfo:page-number-citationがページ番号と段に置き換わります。さらに、数字の形式を拡張して、この段の数字として「上、中、下」という形式を指定できます。そうすることで、
XXX --- 398上
というような索引まで作成できます。
XSL-FOを使う自動組版は、こういう六法全書のようなものを作るのには最適ではないかと思います。ぜひ、このようなシステムを多くの出版社で採用していただきたいものです。
Pageの会場でプレゼンテーションをご覧になった方もいらっしゃると思いますが、XMLの自動組版でこんなことができるのか!という点で参考にしていただきたいと思います。
詳しいお問い合わせは、エクスイズム(電話番号:0422-40-2571)までどうぞ。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年02月03日
PDFと文字 (40) – Unicode標準形式NFCの問題点
昨日までで、Unicodeの標準形式NFCを使えば結合文字列を合成できそうなことは分かりました。しかし、便利なものには落とし穴もあるもの。NFCにもなにか問題があるに違いありません。
そこで、仕様書を少し詳しく検討してみましたところ、気になる点が出てきました。
(1) 合成除外文字の問題、特に、CJK互換漢字が別の文字に置換されてしまう件。
(2) Unicodeにコードポイントを持たない文字を指定したときの問題。
の二つです。
一方、ハングルの字母(Jamo)で表されたテキストをUnicode標準形NFCにすることで、ハングル合成文字(Johab)に変換できるというメリットもあるようです。
2006年01月18日PDFと文字(26) – ハングルの扱いで、ハングル音節文字(Johab)は字母からプログラムで合成できると書きましたが、Jamoの列を標準形式NFCにすることで、これが実現できてしまうんですね。
順番に検討してみます。
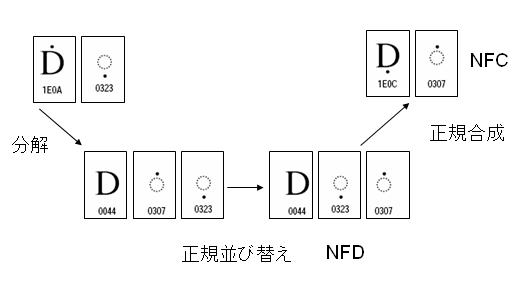
(1) 合成除外文字の問題について
Unicode文字列の標準形NFCの作成では、文字列をまず正規分解し、次に正規合成します。ところが、この処理は完全なラウンドトリップ変換ではありません。つまり出発点に戻らない文字があります。
UAX#15に合成除外文字のリスト(Composition Exclusion Table)が用意されています。これを見ますと、合成除外文字には幾つかの種類がありますが、一番問題になりそうなのが、正規分解でそれ自身とは異なる一文字になってしまう文字です。これはSingletonと言います。
Singletonの例としてUAX#15にはオングストローム記号が出てきます。オングストローム記号は、上リング記号付きラテン大文字Aへの分解マッピングを持っています。さらに、NFDでは<U+0041, U+030A>になります。ところがSingletonは合成除外文字に指定されているため、オングストローム記号のNFCをとっても元に戻りません(次の図を参照)。
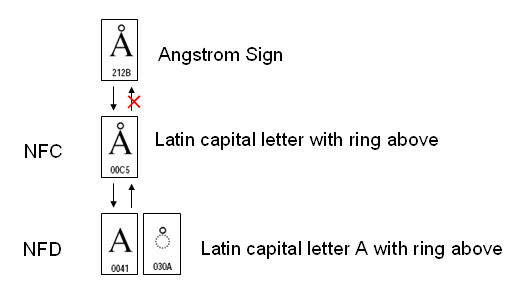
もし、万一、指定したフォントでオングストローム記号と、上リング記号付きラテン大文字Aのグリフが違っていると、NFCを取る場合とNFCを取らない場合で表示される字形が異なってしまうという問題が生じます。オングストローム記号をわざわざU+212Bで表す数奇者はいないと思いますが。それなら、Unicodeは、なぜ、オングストローム記号にコードポイントを与えたのでしょうか?
オングストローム記号程度なら良いのですが、Singletonのリストの中に漢字が997文字もあります。
※Composition Exclusion Tableには、Singletonの合計コードポイントは924となっていますが、漢字だけで997文字もありますから、924は誤りでしょう。
997文字は全部CJK互換漢字のブロックの文字です。
※CJK互換漢字については、2006年01月04日 PDFと文字(15) – CJK統合漢字拡張を参照してください。
CJK互換漢字(U+F900~U+FAFF)のブロックは、12文字(U+FA0E, U+FA0F, U+FA11, U+FA13, U+FA14, U+FA1F,U+FA21, U+FA23, U+FA24, U+FA27, U+FA28, U+FA29)を除く残りがSingletonになっています。また、CJK互換補助漢字(U+2F800~U+2FA1D)はすべてがSingletonになっています。これらの文字は標準形式NFCにするとCJK統合漢字に置き換わってしまいます。
ちなみに、JIS X0213 とのラウンドトリップ用にコードポイントをもつU+FA30~U+FA6Aの59文字もCJK統合漢字への正規分解マッピングを持っていますのでNFCで文字が置換されてしまいます。
実際にどうなるか見てみましょう。
こんどは、Normalization Conformance Testのデータに、フォント・ファミリーをMS明朝を指定してPDF化してみます。最初が標準形NFCにしない場合、次が標準形NFCにした場合です。
図 標準形NFCにしない場合

図 標準形NFCにした場合

これを見ますと、現在の時点では、MS明朝では、U+FA30~U+FA6Aの文字にはグリフがないことがわかります。これをNFCにしますと文字が表示されるようになります。
Windows Vistaでは、MS明朝にJIS X 0213の文字のグリフが追加されるようですので、そうなると、Unicode標準形NFCにすると字形の置換が現実に起きてしまうのではないかと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月02日
PDFと文字 (39) – Windowsへ表示とPDF作成の相違
昨日、XSL FormaterV3.4ではWindowsの画面には正規分解を正しく表示できても、PDFでは正規分解を正しく表示できない、ということを示しました。
実は、このあたりがWindowsの大変ややこしいところなのです。
Latin capital letter A with ring above and acute (![]() )という文字をWindowsの画面に表示することを考えて見ます。この合成文字のコードポイントはU+01FAです。もし、入力されたデータの中の文字コードが正規分解
)という文字をWindowsの画面に表示することを考えて見ます。この合成文字のコードポイントはU+01FAです。もし、入力されたデータの中の文字コードが正規分解
そうしますと、Windowsが文字の形を作り出して ![]() という形を画面に表示します。
という形を画面に表示します。
一方、PDFを作成するときは、正規分解
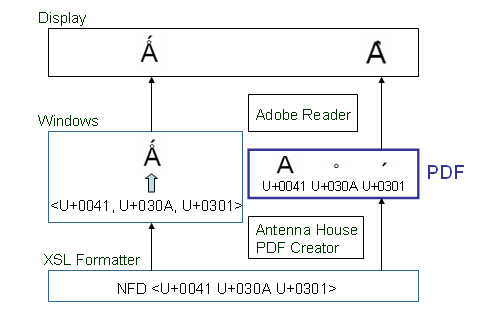
これに対して、V4.0でLatin capital letter A with ring above and acute (![]() )を画面でもPDFでも正しく表示できるのは、Formatterの方で、正規分解
)を画面でもPDFでも正しく表示できるのは、Formatterの方で、正規分解
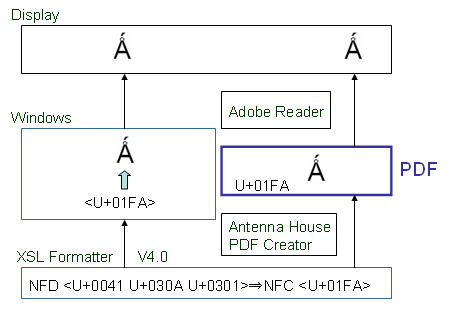
以上により、Unicodeの結合文字列から合成文字にするのは有効なように思います。では、この問題点はないのでしょうか?引き続き検討してみましょう。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月01日
PDFと文字 (38) – Unicode標準形NFCの実装
さて、先日までに、Unicode文字列をUnicode標準形NFCに変換する処理を実装することで、結合文字列を合成文字で表示できるようになるはず、ということを考えて、実際にXSL Formatterの次期バージョンV4.0のα版に試しに実装してもらいました。
そこで、まずその成果をざっと見てみましょう。Unicodeの標準形を決めているUAX#15には、Normalization Conformance Testというテストケースが付随しています。
これを、従来のバージョンと新機能を実装したバージョンで組版して比較してみました。そうしましたところ次のことに気がつきました。
(1) XSL FormatterV3.4のGUIでは、Unicodeの結合文字列をNFCを使わないで表示しているにも関わらず、結合文字列がかなりの割合で正しく表示できます。
次の図は、XSL FormatterV3.4のGUIに表示される組版結果中、ラテン拡張-Bブロックの後ろの方の画面のスクリーン・ショットです。
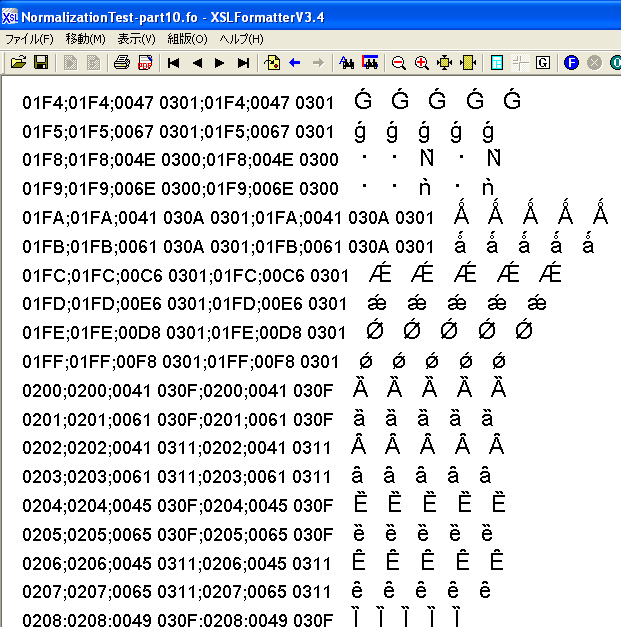
図の中で、左から3列目が左端の文字の正規分解(NFD)です。例えば、U+01FAは、<U+0041, U+030A, U+0301>と正規分解されます。WindowsのGUI経由では正規分解が正しく表示できています。
主なブロックの文字の正規分解が正しく表示できるかどうかを、表に整理しましたが、ラテン文字はほとんど正しく表示できていることが分かります。
| ブロック | コードポイント | Windows XP SP2の表示 | |
|---|---|---|---|
| ラテン文字 | Latin-1追補 | U+00C0~U+00FF | 結合文字列を正しく表示している |
| Latin Extended-A | U+0100~U+017F | 結合文字列を正しく表示している | |
| Latin Extended-B | U+0180~U+024F | U+0218以降の結合文字列が正しくない | |
| Latin Extended Additional | U+1E00~U+1EFF | 結合文字列を正しく表示している | |
| ギリシャ文字 | Greek | U+0370~U+03FF | U+0344, U+0374が不正。一部グリフがない。 |
| Greek Extended | U+1F00~U+1FFF | U+1FBE, U+1FC1, U+1FCD~U+1FCF, U+1FDD~U+1FDF, U+1FED~U+1FEF, U+1FFDが不正。 | |
| キリル文字 | Cyrillic | U+0400~U+4FF | U+0400, U+040D, U+04ECが不正。一部グリフがない。 |
Windows XPは、ラテン文字については結合文字列を画面に表示する際に、結合文字列の中の結合文字の位置を正しく調整していると思われます。あるいは、結合文字列を、それと正規等価な合成済み文字に置き換えているのかもしれません。但し、この処理は、スクリプト依存になっているようです。すなわち、ラテン系はほぼOKですが、キリル文字、ギリシャ文字はNGが幾つかある、というように。
先日(2006年01月29日PDFと文字 (36) – 文字の合成方法(続き))、「Wordは、tildeの高さの制御を行っています。」と書きましたが、これはWordではなく、実際はWindowsが行っているんですね。
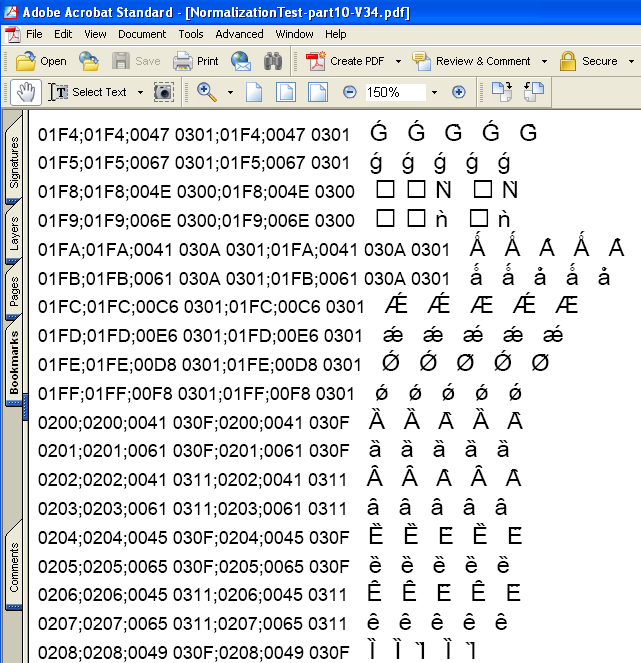
(2) 次に、この文書をFormatterV3.4でPDFにして見ました。上の図と同じ場所のPDFの画面が次の画像です。XSL Formatter V3.4のPDFは、結合文字の位置が正しくないものがあります。これは、バグではなく仕様です。
このように、Windowsの画面表示では正しく見えてしまうのに、PDFにすると結合文字の位置が正しくないことがあるというのは注意が必要です。
(3) さらに、XSL Formatter V4.0 (Alpha)で標準形NFC化の機能をONにして、同じ文書を組版し、PDFを作成してみました。そうしますと、こんどは、正規分解で表した結合文字列も正しく表示できています。次の図を参照してください。
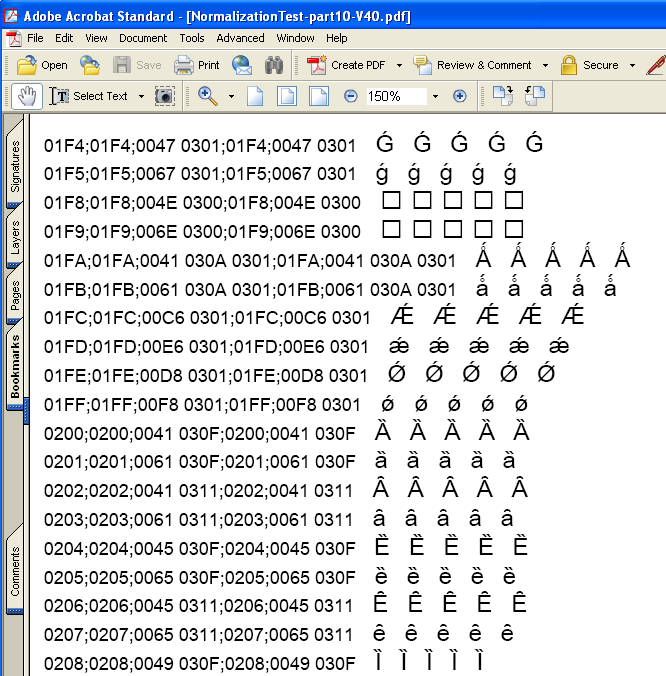
これを見ますと、標準形NFCのサポートにより、正規分解を合成文字として正しくPDFにできるようになっていることが分かります。
なお、この画面でもうひとつ気が付くことがあります。それは、U+01F8、U+01F9がグリフがないとされていることです。この試験では、Unicodeのグリフをもっとも沢山もっているとされるArial Unicode MS フォントを指定しています。しかし、Arial Unicode MS フォントにもU+01F8、U+01F9のグリフはないんですね。
また、最初の画面で分かりますが、WindowsのGUIはU+01F8、U+01F9についてはArial Unicode MS フォントにグリフがないので合成文字は表示できませんが、結合文字列はそれぞれを基底文字と結合文字で表示しています。これを見ますと、Windowsでは結合文字列を画面に表示するとき、フォントに合成済みグリフがあるかどうかをチェックして、グリフがあるときは基底文字と結合文字に正規等価な合成文字に置換しているのかもしれません。いづれにせよWindowsのやっていることは不透明です。
※テスト環境OS:Windows XP SP2(英語版)。地域と言語の設定は、地域のオプション:日本語、Location:日本、非Unicodeアプリケーションの言語:日本語としています。
投票をお願いいたします