« 三井物産株式会社の業務処理マニュアルPDF化 | メイン | XSL V1.1 仕様についての多言語組版研究会開催 »
2006年02月07日
PDFと文字 (41) – Unicode標準形式NFCの問題点(続き)
2006年02月03日にPDFと文字 (40) – Unicode標準形式NFCの問題点で、合成除外文字の中の1種類Singletonについて説明しました。
合成除外文字のリストには、Singletonの他に、次の種類があります。
(a) スクリプト依存
デバナガリ文字、ヘブライ文字の合成文字など67文字。
(b) Unicode3.0以降に追加された合成文字
数学記号1文字、音楽記号13文字
(c) 正規分解が結合文字から始まる合成文字
4文字
これらの文字は、標準形NFCにすると分解されたままになってしまい合成されません。
Singletonの問題を合わせて考えますと、組版ソフトのように文字の形が重要な意味をもつソフトでは、Unicode文字列を安易に標準形NFCにする処理を既定値にするのは危険なので避ける方が良い、という結論になりそうに思います。
次に、2006年02月03日に挙げた2つ目の
(2) Unicodeにコードポイントを持たない文字を指定したときの問題
について検討します。これは、UAX#15の表5にも載っていますが次の図のような例です。
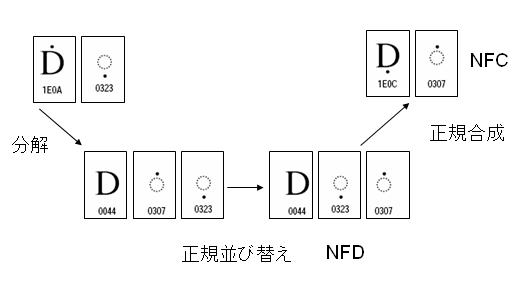
これは、Latin capital letter D with dot aboveとCombining letter dot belowという結合文字列を標準形NFCにすると、Latin capital letter D with dot belowとCombining letter dot aboveに化けてしまうという類の問題です。
NFCにする処理では、最初に、合成済の文字を分解し、そして正規並び替えを行います。(2006年01月30日PDFと文字 (37) – 結合文字列の正規合成を参照してください。)
並び替えで、Combining letter dot belowとCombining letter dot aboveの順序が入れ替わります。この結合文字列を正規合成すると基底文字DにCombining letter dot belowが先に結合してしまいます。上と下の両方にドットの付いたDはUnicodeにはありません。従って、Combining letter dot aboveが独立した文字として残ってしまいます。
正規並び替えでは結合クラスが小さい文字を、結合クラスが大きい文字より先になるよう並び替えるため、この例のような問題が起きるケースは、少なくないと考えられます。
元はといえば、Unicodeの正規分解や正規合成の概念は、分解可能な文字、合成済みの文字を想定して組み立てられています。従って、標準形NFCの適用範囲は、分解可能な文字、合成済みの文字、及びそれらを分解した文字だけからなる文字列に限定されるのではないかと思いますが、どうなのでしょうか?
実際のところ、上の例で、最初の結合文字列と最後の結合文字列が正規等価である、といわれても認めがたいように思います。少なくとも、結合文字列の表示が等価になるかどうかは、フォントとレンダリングするアプリケーション依存となってしまいます。
ちなみに、上の2つの結合文字列をWord2003で表示しますと次のようになります。

正規等価な結合文字列の表示が同じになっていないということがお分かり頂けると思います。
結合文字列をレンダリングするアプリケーションが、結合文字の位置を自在に制御して、基底文字に対して正しい位置に配置できるのであれば、標準形NFCなど考慮しなくても、結合文字列をダイナミックに合成できるわけです。この場合、標準形NFCは無用の概念となります。
このように、文字をレンダリングするという観点から考えますと、標準形NFCというのはやや中途半端な仕様ということになりそうです。
投稿者 koba : 2006年02月07日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/151