« 2006年01月09日 | メイン | 2006年01月11日 »
2006年01月10日
PDFと文字(19) – 漢字統合問題再検討
Unicode4.0では、既に漢字を7万字以上も規定しています。さらに統合漢字拡張Cとして新たな漢字の追加を計画しているようです。
しかし、1月5日、1月6日には、①Unicodeの漢字統合の基礎になるはずの3次元モデルが曖昧で間違った解釈がなされていること。②その結果、統合ルールも不整合になっていること。③新しく追加した漢字の中には同じ抽象的字形を別のコードポジションに重複して登録しているものがあるなど、既に大きな問題を抱えていて、Unicodeの漢字統合は破綻していると述べました。
このような状況で新しい漢字を追加することは、新たな混沌をもたらすだけではないでしょうか?
これに対して、どのように考えたら良いのでしょうか?
「日本の苗字七千傑」というWebページのQ&Aを見ますと、
Q4.日本の苗字は何種類の漢字が必要か?
という項があります。
これによりますと、住民基本台帳ネットワークでは、非公開の統一文字コード(約二万一千字)を外字として使用していて、JIS X0213でも漏れている文字があるとのこと。さらに、苗字拾遺を見ますと、Unicode外(とされている)漢字の例も見ることができます。
このようなことからだけでも、標準文字規格に新しい漢字を追加して欲しい、という強い要望があるだろうことは容易に予想されます。では、その要望通り追加したら良いのではないか、と思われますが、事はそう簡単ではありません。標準規格に文字を追加することは、後で検討しますように、社会全体では相当に大きな額のコストがかかるだろうと思います。
しかし、自分の苗字位は正しく書きたいのは人情です。これに応えられなければ、プロの名が泣くというものです。
大口たたいたな。じゃあ、お前、解決策を示してみろ?と問われれば:
私は、現段階では実際のところ直感的にですが、PDFを使うことによって標準規格の漢字字種不足および漢字統合に関する問題を、すべて、比較的簡単に解決できるのではないかと考えています。このことについては、このブログですこしづつ検討したり、説明していきたいと思っていますので、お楽しみに :-)
つまり、私たちの時代は、漢字の標準規格に新しい漢字をそれほど沢山追加しなくても、世の中に出現する漢字を自由自在に取り扱う技術を有していると思うのです。ですので、これから、何万種類もの漢字を標準に追加したり、管理する作業は行わなくても良いのではないか、いや、むしろ社会的コストを考えますと漢字を増やすのはできるだけ止めるほうが良いのではないかと考えています。
そういっても、実際のところどうなの?本当にPDFですべての問題を解決できるの?ということもあると思います。
それに万人を説得できる証拠を提示することも必要でしょうし。そうなりますと、もう少し漢字のことを調べてみなければなりませんね。そんなわけで、漢字から先へ進めなくなってしまいました。そんなつもりじゃなかったんですが :-)
※補足
なお、統合漢字拡張Bには次のような疑問を感じる漢字もありますが、次の漢字は正しいのでしょうか?
・天地が逆ではないでしょうか?それとも逆さまであることに意味があるのかな?
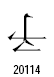
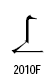
・白抜きの部分はどう解釈すべきでしょうか?


