
« 『瞬簡PDF OCR』のマルチドキュメント・インタフェースとは? | メイン | 『瞬簡PDF OCR』を使ってみましょう(その2) »
2012年10月03日
『瞬簡PDF OCR』を使ってみましょう(その1)
日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』を使って変換するまでの概略を何回かに分けてご紹介します。
『瞬簡PDF OCR』は、以下の手順で画像からの変換処理を行います。
- 画像データの読み込み
- 領域解析
- 文字認識
- 変換先ファイル形式への保存
これまでOCRソフト製品を使用してこられた方であれば、お馴染みの手順かと思います。
それでは、まず画像データの読み込みから始めましょう。
- イメージスキャナ:イメージスキャナは一般的にTWAINと呼ばれる標準規格を採用しています。『瞬簡PDF OCR』もこの規格を採用したスキャナであれば基本的に扱うことができます。
また、TWAIN規格ではないですが、「ScanSnap」というドキュメントスキャナの機種で読み込んだデータも受け取ることができます。 - PDF:PDFには、スキャナで作成される画像だけのPDFもありますし、一般的にPDFドライバと呼ばれる仮想プリンタ形式のソフトを使って、Wordなどのアプリケーションから作成されるテキストが含まれたPDFもあります。
『瞬簡PDF OCR』はいずれのPDFであっても読み込みできます。ただし、後者のテキストが含まれたPDFはいったん画像にした上でOCR処理しますので、元あったテキストデータは消えてしまいます。この点はご注意ください。 - 画像ファイル:イメージファイルとして一般的なビットマップ形式や写真でよく使われるJPEG形式など、広く使用されている画像形式をサポートしています。また、クリップボードにコピーした画像データも対象にできます。
ここでは、手近にあるPDFを読み込む手順を説明しましょう。ファイルの読み込みは、単にWindowsのエクスプローラなどから任意のPDFをつかんで、『瞬簡PDF OCR』の上にドラッグ&ドロップするだけです。
この際に、既に何か読み込みされたデータがあると、以下のような確認画面が表示されるのが他のOCRソフトと違ったところです。
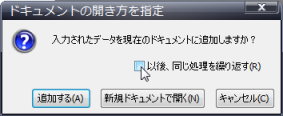
これが昨日説明した、『瞬簡PDF OCR』独特のドキュメントの扱い方に関連するものです。既にあるドキュメントに同じ仲間としてページを追加するか、あるいは別物として新規にドキュメントを作成し、そちらに格納するかを問い合わせているわけです。
ここでもし「追加する」を選択し、画面中にある「以後、同じ処理を繰り返す」にチェックをいれると、次に新しいデータを取り込んでも問い合わせをしないで、ひとつのドキュメントに「追加」し続けます。この指定は、1枚づつしか取り込みできないスキャナから連続して原稿を取り込みたいときなどに便利です。
画像の読み込みが終わると、内容が画面に表示されます。
下記は、PDFを読み込んだ直後の状態です。
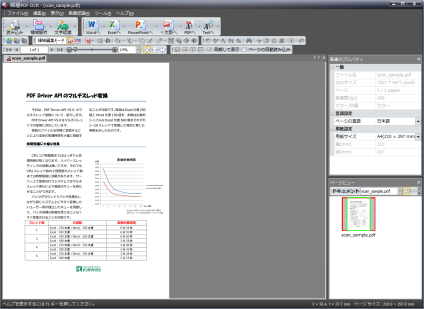
(画像をクリックすると拡大します)
結果を急ぐ人は、ここでいきなり変換してしまうこともできます。
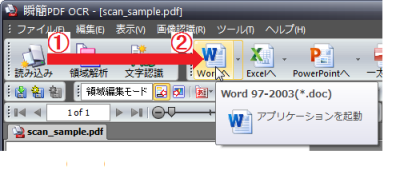
元の画像の条件がよい場合は、いきなり変換してそのまま再利用ができるほどの変換結果が得られるかも知れません。
OCR処理で「条件がよい」というのは、元の画像の解像度が高くて、画像の傾き、ゴミなどのノイズがなく、文字は活字で余分な飾りもなく、レイアウト自体も単純、といったような場合をさします。しかし、そういった原稿など現実にはあまりなさそうですね。
通常、OCR処理で変換したい画像は、たいてい文字が化けたり元と違う文字に置き換わったりするなど、誤変換が避けて通れないものです。
元と違う文字が変換される程度であれば、変換後にワープロソフトを使って修正可能ですが、画像で変換したい箇所を文字と誤認識してひどい文字化けになるなど、変換後では修正しきれない場合もあります。
このような事情から、OCRソフトには誤変換を回避するための処理が備わっています。
その詳細は、明日の回で説明することにしましょう。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。
投稿者 AHEntry : 2012年10月03日 09:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/1976
コメント
コメントしてください
サイン・インを確認しました、 さん。コメントしてください。 ( サイン・アウト)
(いままで、ここでコメントしたとがないときは、コメントを表示する前にこのウェブログのオーナーの承認が必要になることがあります。承認されるまではコメントは表示されません。そのときはしばらく待ってください。)