
« 日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』のご案内 | メイン | 『瞬簡PDF OCR』を使ってみましょう(その1) »
2012年10月02日
『瞬簡PDF OCR』のマルチドキュメント・インタフェースとは?
昨日に続いて、日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』をご紹介します。
『瞬簡PDF OCR』は、マルチドキュメント・インタフェースというちょっと聞き慣れない用語でその操作性をアピールしております。
これは何かといいますと、平たく言えば、いくらでもデータを読み込んでお好きな変換先に変換できますよ、ということです。
もちろんパソコンの物理的な制限というのはありますから、「いくらでも」というのは言い過ぎですね。
しかし、スキャナからでも、PDFからでも、ビットマップやJPEGなどのイメージからでも、クリップボードからでも、画像データであればとりあえず『瞬簡PDF OCR』の画面上に放り込んでおいて、いつでもWordやExcelに変換できるような作りになっています。
以下では、そのあたりを説明してみたいと思います。
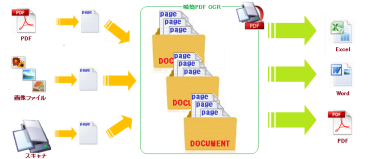
『瞬簡PDF OCR』では、原稿データの1枚を「ページ」と言っています。
スキャナで紙の原稿を読み込むときの原稿1枚、1枚がそれぞれ1ページになります。
画像ファイルを読み込んだ場合はひとつの画像ファイルが1ページとなり、 PDFを読み込んだ場合はPDFに含まれる各ページがそれぞれ1ページになります。
次に、ページをひとつにまとめたものを「ドキュメント」と言います。
『瞬簡PDF OCR』では、ひとつのドキュメントが『Word』や『Excel』の1文書に変換されます。 また、作業ファイルに保存する場合も「ドキュメント」毎に行います。
これを図に表すと以下のようになります。
(画像をクリックすると拡大します)
これをどんなふうに使うかというと、例えばスキャナで複数の原稿を取り込む場合を考えてみます。
紙の原稿にはいろいろな種類があると思いますが、報告書であるとか、申請書のような形式の文書はWordで編集した方が何かと便利です。
一方、表形式になった月次売上だとか名簿などは、Excelで編集するのが向いていると言えます。
これらを一度にスキャンして、別々のドキュメントにまとめて取り込んでおけば、片方はWordに、もう片方はExcelに分けて変換することができます。
また、Wordに変換する場合でも、報告書は報告書でまとめてひとつのWordファイルに変換し、申請書は申請書で種類毎に別のWordファイルにしたいと思いませんか?
そのような場合でも、『瞬簡PDF OCR』では、報告書のドキュメント、申請書Aのドキュメント、申請書Bのドキュメントというように、原稿を取り込んだ時点で分類しておけるので、後はそれぞれのドキュメント単位で変換できます。
これを整理しますと、以下のようになります。
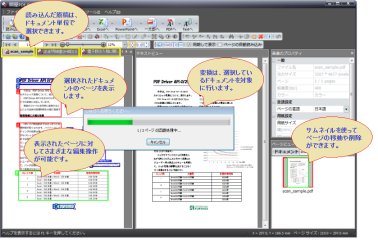
- スキャンした原稿や、PDFの内容などをひとつのドキュメントにしたり、それぞれを別のドキュメントに分けたりすることで、目的に応じた変換結果を簡単に得ることができます。
- ドキュメントに含まれるページは、サムネイルを使って順序を入れ替えたり、不要なら削除したりが簡単に操作できます。また、ドキュメント間でページに含まれる任意の範囲をコピーして貼り付けたり、移動することも可能です。
- ドキュメント毎にその状態を保存できますので、途中で作業を中断して『瞬簡PDF OCR』を終了しても、次回起動時に再び前回の中断時点から作業を再開することが容易です。
(画像をクリックすると拡大します)
以上、『瞬簡PDF OCR』の操作画面について、簡単に説明しました。
次回は実際に取り込んだ画像データから変換を行うまでの操作方法についてご紹介したいと思います。
是非明日もこちらのブログをご覧ください。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。
投稿者 AHEntry : 2012年10月02日 09:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/1975
コメント
コメントしてください
サイン・インを確認しました、 さん。コメントしてください。 ( サイン・アウト)
(いままで、ここでコメントしたとがないときは、コメントを表示する前にこのウェブログのオーナーの承認が必要になることがあります。承認されるまではコメントは表示されません。そのときはしばらく待ってください。)