« 2006年02月08日 | メイン | 2006年02月10日 »
2006年02月09日
PDFと文字 (42) – ハングル音節文字の合成
次に、2006年02月03日PDFと文字 (40) – Unicode標準形式NFCの問題点で挙げましたが、ハングルの字母(Jamo)で表されたテキストをNFCにすることでハングル合成文字(Johab)にすることが可能、という点について調べてみます。
以前に、2006年01月18日PDFと文字(26) – ハングルの扱いで、ハングル音節文字(Johab)は字母からプログラムで合成できると書きましたが、これは具体的には、字母で表された文字列をNFCにするということを指します。
こんどは、実際に試して見ましょう。
(1) まず、ハングルの「こんにちは」は、「アンニョンハセヨ」と言うらしいですが、このハングル表記を調べます。そして、各音節文字を初声、中声、終声に分解します。
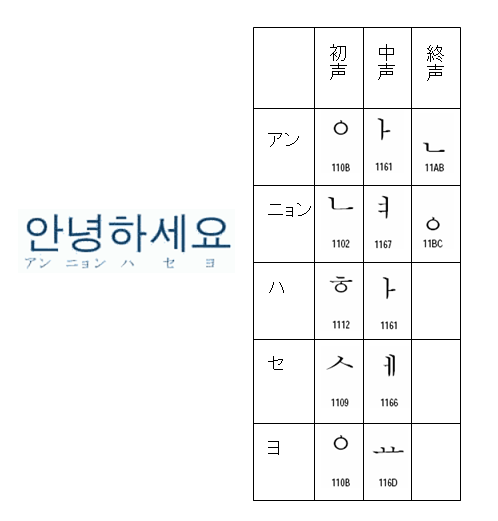
(2) これをUnicodeのJamoの文字列として表します。次のようになります。

(3) この文字列をXSL FormatterV4.0(Alpha)で標準形NFCにして表示します。
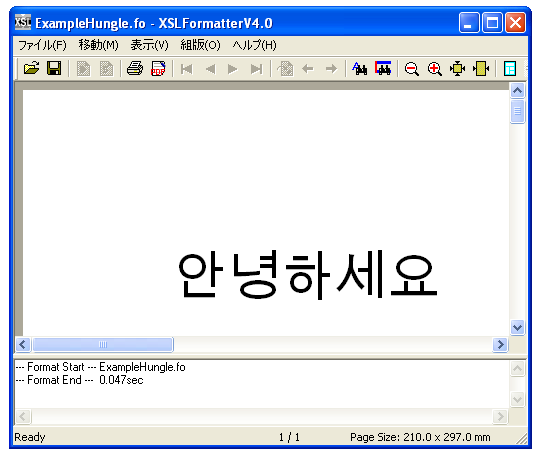
このように、ハングルの字母で表した文字列をNFCにすることで、合成文字Johabにして表示することができることを確かめることができます。
試しに、同じ文字列をMicrosoft Word2003で表示しますと次のようになってしまいます。
![]()
どうやらMicrosoft Word2003は、まだ、ハングルの字母を合成することはできないようですね。
投票をお願いいたします