« 2006年01月04日 | メイン | 2006年01月06日 »
2006年01月05日
PDFと文字(16) –漢字統合の破綻
Unicodeの漢字統合は、中国、日本、韓国で同じ字形の漢字をひとつのコードポイントにまとめた、と言いました(1月3日)。しかし、UnicodeV3.1の統合漢字拡張Bを調べてみますと、UnicodeのCJK漢字統合は破綻してしまったのではないかという印象をもちます。
ここにいくつかその例を挙げます。
1.一般統合漢字と同じ漢字が定義されている例
○一般統合漢字

○統合漢字拡張B
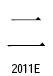
この2つの漢字は字形が完全に同じものではないでしょうか?なぜ、まったく同じ字形を別のコードポイントに追加したのでしょう?
2.一般統合漢字に統合されるはずの漢字が別に定義されている例
(1) ハネの有無
○一般統合漢字
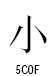
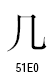
○統合漢字拡張B
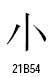
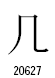
この2組の漢字は、ストローク終端のハネの違いです。ストローク終端のハネの違いは、書体の違いとして統合するという例がUnicodeの仕様書に出ています。しかし、統合漢字拡張Bで分離されて新しいコードポイントを与えてしまいました。
(2) 点の有無
○一般統合漢字


○統合漢字拡張B


この2組については、1月3日に日本語と中国語の字形の例で示しました。一般統合漢字では、点のある器と点のない器、点のある突と点のない突は、ひとつのコードポイントに統合されています。ところが、統合漢字拡張Bで、点のない器と点のない突が、新たに別のコードポイントを与えられてしまいました。
これは、統合漢字拡張Bのコードチャートを1,2時間ざっとみて見つけたものです。コードチャートを詳細にチェックすると他にもこのような例が一杯出てくるのではないかと思います。
Unicodeの仕様書では、一般統合漢字と統合漢字拡張の統合ルールは、原規格分離規則を除いて同一と説明されています。しかし、上の例で示しましたように、実際のコードチャートを見ると、それ以外にも統合ルールが違っていることになります。この統合ルールの変更は仕様書に書いてない、闇ルールということになります。
Unicode仕様書によれば、統合漢字拡張Bには、使用制限がなく、一般統合漢字と混在使用できます。従って、一つの漢字に複数のコードポイントを与えてしまった問題は、理論的に救済不可能と思います。
どうしたら良いんでしょうか?実装の段階で一方を使わないようにするんでしょうか?
それにしても困ったものです。実装者泣かせの仕様書ですね。
投票をお願いいたします