
ツイート
2013年03月26日
PDF/UA(ISO 14289-1)について
みなさん、こんばんは。
前回に続けて、 ISO 14289-1 規格についてです。今回はこの規格の仕様書(2012年7月25日初版、2012年8月1日修正版)の内容を見てみます。
この規格に関連する仕様として、ベースとなる ISO 32000-1 のほかに、W3Cの Web Content Accessibility Guidelines(WCAG) 2.0が記載されています。
仕様書ではPDF/UAファイルのバージョンの識別方法、準拠レベル、ファイルフォーマットに関する要件が記載されます。(このあたりはPDF/A、PDF/X などのファイルと同様の構成です)。準拠レベルは PDF/A-1では Lebel A,Level Bの2種類が定義されていましたが、PDF/UAにはこのようなレベルはありません。
続けて、この規格に準拠するリーダ(Conforming Reader)に対する要件が記載されます。
ファイルフォーマットに関する要件は主にPDF/UAファイルの作成者(書き手)側に対する要件ですが、こちらは、PDF/UAファイルが持つアクセシビリティ機能を利用可能とするためにリーダ(読み手)に必要とされる要件が提示されます。
最後にATに対する要件が定義されます。ATとは、障害をもつ人によって使用され、代替えのコントロールや表示を提供したり、有効な機能の使用方法や情報を提供するソフトウェアあるいはハードウェアといった定義がされています。準拠リーダと統合可能と記載されています。
ファイルフォーマットの要件の主な規定は、ドキュメントをその構造に沿って解釈できるように、タグ付けされていることにあります。このタグの使用方法、論理構造の表現などについて、テキスト、画像、表、リストなどの各項目についての規定が説明されています(元のISO 32000-1に定義されているPDFのタグ付を理解していないとこのあたりは難しいかもしれません。稿を改めて説明してみたいと思います)。
フォントの埋め込みもPDF/A,PDF/Xと同様に必須とされています。一方、注釈やアクションについては、印刷時の再現性等を求めるための規格ではありませんので、用法に制限がありますが、完全に禁止とはなっていません。この部分はリーダ側の要件とも関係してきます。
リーダ側の要件については、後日、説明いたします。
■ご参考:アンテナハウスPDF資料室
投稿者 AHEntry : 20:41 | コメント (0) | トラックバック
2013年03月25日
PDF/UA(ISO 14289-1)について
今回、および次回は PDF/UAと呼称される ISO 14289-1 規格について記載してみます。
ISO 14289-1(以下、PDF/UA)は昨年、国際標準となった規格で、規格書初版は 2012年7月25日に初版が発行されています。
規格書のタイトルは、
Document management applications —
Electronic document file format enhancement for accessibility —
Part 1: Use of ISO 32000-1 (PDF/UA-1)
となっています。
PDF/UAも今まで説明してきた、PDF/X、PDF/Aの各規格同様に、PDFの仕様書をベースとして、それぞれの用途に沿った規則を設けたものになります。今回とりあげる ISO 14289-1という版は 、タイトルにもありますように、ISO 32000-1をベースとし、その機能のなかから、使用してはいけない機能、使用方法に制限のある機能などを定めた規格となります。
PDF/UAのタイトルに、アクセシビリティのエンハンスメントとあります。PDFにおけるアクセシビリティの向上とはどのようなものでしょうか。現在、PDFは最も広範に利用されている電子文書形式ですので、多くの人に使いやすいものであることが求められます。障害を持つ人、高齢者にも簡単に使える必要があります。
たとえば視覚に障害を持つ人が利用する場合、音声読み上げソフト等によって、確実にテキストが読み上げ可能である必要があります。
画面に文字が表示されているPDFでも、読み上げが確実に可能とは限りません。コピー&ペーストで他のアプリケーションに文字がコピーできないPDFがありますが、このようなPDFは文字コードがファイル内に格納されていないため、読み上げソフトでも文字が取得できません。また、同じ漢字でも日本語と中国語では読み方が異なりますので、そのテキストがどの言語のものなのか、といった情報も必要となります。
また、画像、図形等が使用されている場合、それがどのような意味を持つものなのか、テキストによる説明があると、利用しやすくなります。
このような点を考慮して、PDFの利用方法(作成側、読み込み側の双方)を定義したものがPDF/UAとなります。
次回、内容について説明します。
PDF/Xについて
PDF/Aについて
- Antenna House PDF Driver V5.0がサポートするPDF/A とは?
- PDF/A-2って、PDF/A-1と、どこがどう違うの?
- 続・PDF/Aとは― PDF/A-3について
- PDF/A-3 PDFの新しい目的
その他のPDF規格
投稿者 AHEntry : 10:44 | コメント (0) | トラックバック
2013年02月22日
PDFベースとしたワークフローシステム開発時に必要な基盤となるライブラリの紹介
本日は、PDFベースによるワークフローシステムを開発する際に、アンテナハウスのライブラリ製品(ソフトウェアコンポーネント)がどのような機能を提供できるものなのか、ちょっと考えてみました。
多くの企業では、まだ紙を中心とした業務管理が行われていると思います。
膨大な紙の書類が発生し、保管の場所も取りますし、管理も大変になってきます。
紙の代わりとしてのPDFは、OSやソフトと云った環境が違っても内容が確認可能な文書交換フォーマットとして、世界で広く利用されています。バージョンの互換性や運用リスクを心配する必要がありません。PDFはファイルサイズも小さく出来ますので、電子文書の配布、管理に適しています。
そこで、社内文書・資料、契約書、申請書や稟議/決裁書と云った様々な書類をPDFにして、一元管理することで、保管場所を節約、整合性(ミスの軽減)の確保、検索の容易性などの利便性と効率を上げることができます。
PDFをファイル管理システム(データベースシステム)で一元管理しますと、共有利用して、申請書の承認/決済や稟議書/決裁書、あるいは受発注処理のおける承認印、書き込みなどの定型化した業務をPDF上で行い保管するワークフローによる業務処理の自動化の要求も出てきます。 業種の違いによるそれぞれの業務に適した、人とコンピュータの連携を最適化した(適切なナビゲーションを含む)ワークフローシステムを構築する必要が有ります。
PDFによるワークフローシステムを実現するためには、基本として、
- 紙の書類、電子文書をセキュリティ付でPDF変換できること、②既存PDFに対しても、加工、編集、セキュリティ変更・追加ができること
- 既存PDFに対しても、加工、編集、セキュリティ変更・追加ができること
- 画面(GUI)作成ツールが有り、画面から、PDFを検索、表示し、コメント注釈、スタンプ付加および印刷ができること
などが考えられます。
ソフト開発会社様には、業種・業務に合ったワークフローシステムのソフトウェア製品を開発、販売を手掛けられているところがあります。
アンテナハウスは、ソフト開発会社様が、そのようなPDFワークフローシステムの開発に組み込んで頂く基盤となるライブラリ(ソフトウェアコンポーネント)製品を用意しております。
アンテナハウスのライブラリ製品を以下に簡単に紹介させて頂きます。
1.PDF変換ライブラリとして
まずは、業務上発生する電子文書、主に一太郎やMS Officeで作成した文書をPDFに変換し、ファイル管理システムあるいはデータベースに登録・保存するアプリケーションが必要となります。アンテナハウスは、目的とするワークフローに適したPDF変換アプリケーションを効率よく開発することが出来る以下のライブラリを用意しております。
■PDF Driver API(PDF Driverを含む) 元ファイルのアプリケーションの印刷機能を利用。
http://www.antenna.co.jp/ptl/function.html
- 本ライブラリの機能
-
- 一太郎、Office 文書のPDF変換
変換元ファイルの指定、PDF出力先(Path、PDFファイル名)を指定するだけで変換ができます。 - セキュリティの設定
プログラムからダイナミックに、閲覧パスワード、編集パスワード(印刷、コピー、ページの抽出etc.の禁止)の設定、および「Confidential」などの透かしをいれたPDFに変換にすることができます。 - PDF/A(長期保存)の指定もできます。
- PDF/X(印刷用)の指定もできます。
- 一太郎、Office 文書のPDF変換
サーバ上での一括PDF変換処理を行うような場合、開発者は、本ライブラリがマルチプロセス、マルチスレッドに対応していますが、それらを余り意識することなく、並行処理による処理速度の向上を図ったアプリケーションを開発することが出来ます。
他に元ファイルのアプリケーション不要で、ダイレクトにPDF変換する「サーバベースコンバータ」も提供しております。
2.PDFに対し、加工、編集を行うライブラリとして
システム管理責任者が、既存のPDFをワークフローシステムに適したもの(標準化)として取り込むためにPDFを加工、編集、セキュリティの変更・追加して、ファイル管理システムに保存・登録すると云ったツール、アプリケーションが必要性な場合があります。一括で処理する場合も有れば、表示して、インタラクティブ処理を行いたい場合もあるかと思います。アンテナハウスの以下のライブラリを用意しております。
■PDF Tool API
http://www.antenna.co.jp/ptl/function02.html本ライブラリの機能
- PDFの分割、結合、しおり作成や、透かし、画像、文字列、スタンプを任意の場所に挿入。
- セキュリティの変更と以下の追加が出来ます。
- 閲覧有効期間の設定。
- ファイルパス設定(PDFを持ち出しても、所定の場所以外は、閲覧不可)
フォーム入力を設定することが出来れば、ワークフロー処理の幅も広がります。本ライブラリでは、検討中というところです。
3.PDFを表示し、ワークフローを実行するためのライブラリとして
開発者は、ワークフロー合った操作し易い、メイン画面(メニュー)の作成、画面遷移など、ファイル管理システムを画面上で表示し、簡単に検索出来、指定のディレクトリから PDF ファイルを開き、担当者から別担当者、担当者から管理者へと注釈、コメント、スタンプ(捺印)などの処理を行い、指定のディレクトリに PDF ファイルを保存すると云ったプリケーションの開発が必要です。
アンテナハウスの以下のライブラリを用意しております。
■PDF Viewer SDK
http://www.antenna.co.jp/oem/ViewerSDK/※スタンプ付加は、PDF Tool APIと併せて開発することが出来ます。
他にも、PDFのセキュリティを高めるために電子署名、タイムスタンプが付与できる「PDF電子署名モジュール」製品も用意しております。
ここで、PDFを利用した様々なワークフローシステムが考えられますが、ワークフローシステムの例として、1部を以下に列挙してみました。
- 病院の医療業務における様々な書類に対するワークフローシステム
- 保険会社における様々な書類に対するワークフローシステム
- 一般企業内においては、社内申請の承認、稟議/決裁業務に対するワークフローシステム
- 学校・塾における問題集に対するワークフローシステム
- 製造業におけるCAD図面などのPDF化による一括管理と承認等に対するワークフローシステム
- 印刷業における原稿をPDFにして、インターネット経由で入稿するワークフローシステム
以上のライブラリ製品は、http://www.antenna.co.jp/oem/ に載せておりますので、ご一覧下さい。 お問合せ先は、OEM営業グループ E-mail: oem@antenna.co.jp へ宜しくお願い致します。
投稿者 AHEntry : 09:00 | コメント (0) | トラックバック
2012年12月17日
PDF 表示機能の比較
近年、OS、WWW ブラウザー等で PDF 表示機能を内蔵するものが増えています。
そのうち、PDF を見るためだけに何か別のソフトウェアをインストールしなければいけないということは、なくなってしまうのかも知れません。
現状のいくつかのソフトウェアでの表示画像を簡単に比較してみようと思います。
表示する PDF は、
http://ondoc.logand.com/d/223/pdf
を使います。
Adobe Reader XI (バージョン 11.0.0)
Windows では、事実上標準の閲覧ソフトです。
IE や Firefox でもプラグインが提供されています。
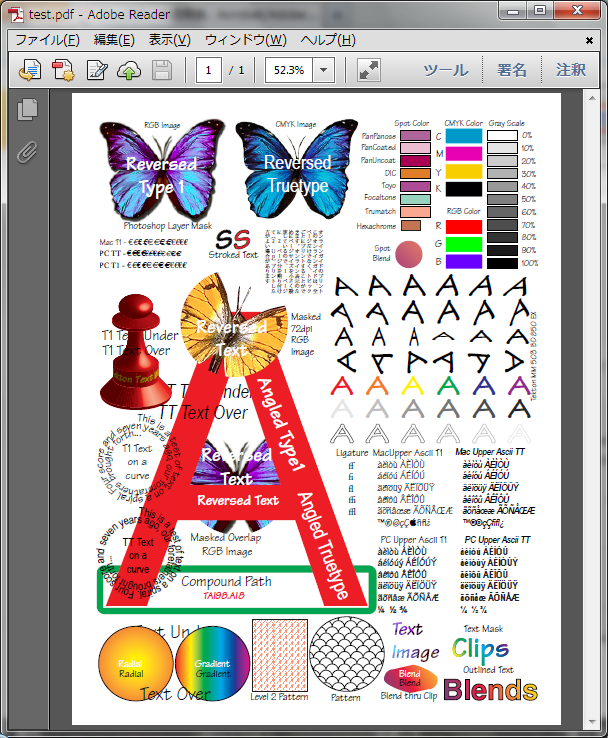
これを基準にします。
Google Chrome (バージョン 23.0.1271.97 m)
最近では WWW ブラウザーのシェアでも Firefox を追い抜いているという Chrome ですが、PDF の表示機能は内蔵されていて、既定で使われています。

特に問題無さそうです。
Firefox (PDF.js) (バージョン 17.0.1)
最近の Firefox には PDF の表示機能は内蔵されていますが、既定では無効化されています。
実体は PDF.js のようです。
アドレスバーに about:config と打ち込んで pdfjs.disabled を false に設定すると、PDF.js で表示できるようになります。
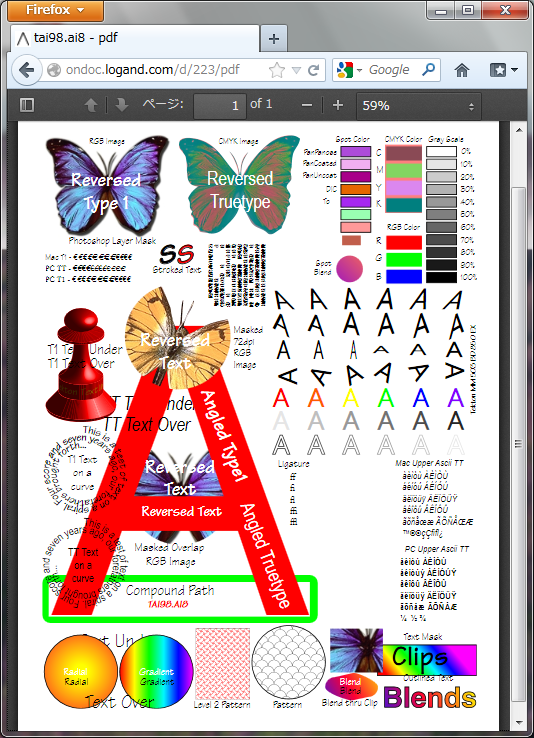
まだ色々問題がありますね。
ところどころ表示できていないところや色が違っているところがあります。
また、日本語が化けてしまうのが残念なところです。
Windows 8 (Windows Reader)
Windows 8 では Modern UI の PDF 閲覧ソフトがはじめから使えます。

右上のあたりで色が少し違うところがありますが、まずまずといったところでしょうか。
番外: Antenna House PDF Viewer SDK V3.3
アンテナハウスでは Windows 向けの PDF 表示ライブラリーを販売しています。
サンプル実行ファイルで表示してみます。

特に問題なし。(だと思います)
PDF Viewer SDK についてはこちらのページを御覧ください。
http://www.antenna.co.jp/oem/ViewerSDK/
投稿者 AHEntry : 15:46 | コメント (0) | トラックバック
2012年12月11日
PDF/E(ISO 24517)について
みなさま、おはようございます。
これまで、PDFをベースとした国際標準規格PDF/A(ISO 19005)、PDF/X(ISO 15930)ファミリついて紹介してきました。それぞれ、デジタルドキュメントの長期保存、印刷用データの交換を目的としたPDF関連規格でした。
今回はまた別の規格 PDF/E について記載してみます。
PDF/Eの仕様は、ISO 24517で規定されています。
ISO 24517も 19005,15930同様に複数のパートからなるマルチドキュメントですが、現時点でISOの仕様となっているものは PDF/E-1(ISO 24517-1)のみです。
まず、ISO 24571-1のタイトルからですが、
Document management ? Engineering document format using PDF ?
Part 1:Use of PDF 1.6 (PDF/E-1)
となっています。
エンジニアリングワークフローにPDFを適用するための仕様であり、PDF 1.6をベースとして、2008年に制定されています。
目的はエンジニアリングワークフローにおけるドキュメントの確実な作成、交換、レビューを可能とすること。具体的な例として、仕様書内のユースケースに上げられている項目の一つに、住宅設計図面のメーカによる作成、第三者機関による審査、監督官庁による承認があります。この中で、作成された図面を審査した第三者機関が差し戻しを行う場合に注釈等を用いて具体的な不具合箇所の指示を行い、審査に合格した場合は図面にデジタル署名を行って監督官庁に提出、監督官庁では図面の承認後、デジタル署名を行った承認図をメーカに戻す、というようなワークフローが説明されています。
この過程で、表示・印刷されるドキュメントが環境によって異なった表示とならないよう、PDF/EにおいてもPDF/A、PDF/Xなどと同様に、フォントの埋め込み、カラースペースの制限などが規定されます。また、上記ワークフローで登場しますように、注釈の使用が許可されています。ただし、PDFの注釈には、ディスプレイ上では非表示となる、あるいは印刷時には印刷対象外となる、といった機能が使用できますが、PDF/E-1ではこのような機能の使用は許可されていません。
また、組立手順書、保守マニュアルといったドキュメントで、使用されるパーツや組立て手順の説明などに有効な3D注釈なども使用可能となっています。承認図等でデジタル署名が使用されますので、デジタル署名機能についてもその使用方法が指定されています。
PDF/E-1はPDF 1.6をベースとした規格ですが、現在、ISO 32000-1をベースとしたPDF/E-2も検討が進められています。
PDF/A,PDF/X,そしてPDF/E について紹介してみました。このほかに、PDF/VT、PDF/UAなど、PDFに関係する規格が他にもあります。前回、審議中として紹介したPDF/A-3は,今年国際標準になっています。今年はこのほかにも PDF/UA-1(ISO 14289-1)も国際標準になりました。このあたりについても、また機会をみて取り上げてみたいと思います。
PDF、そのほか、各種ご相談はアンテナハウス システム製品技術相談会まで
投稿者 AHEntry : 09:00 | コメント (0) | トラックバック
2012年12月10日
PDF/X-5(ISO 15930-8)とは
おはようございます。
しばらく前に、PDF/Xファミリの紹介、およびPDF/X-4の概要を記載しました。今回は、PDF/X-5の概要を紹介したいと思います。
PDF/X-5はPDF/X-4同様に2008年に国際標準(ISO 15930-8)となっています。他のPDF/X同様、ベースとなるPDFの仕様に対して、その機能内で使用可能な項目を定義することで、印刷用データの交換形式を定めるものす。PDF/X-5は、PDF/X-4同様にベースとなるPDFの仕様はPDF 1.6です。また、2010年に改訂が加えられた Second Edition が発行され、現在はこちらに置き換えられています(このあたりもPDF/X-4と同じです)。では、PDF/X-4とは何が異なるのか、簡単に見ていきたいと思います。
PDF/X-5には準拠レベルが3種類定義されています。
- PDF/X-5g
- PDF/X-5n
- PDF/X-5gp
PDFにはOPI(Open Prepres Interface)といって、PDFの外部にあるグラフィックファイルを参照する機能があります。容量の大きなグラフィックを本文から切り離しておくことにより、高解像度のグラフィックが使用される印刷用のデータの校正時に、修正とは無関係な大きなデータのやりとりを行わなくてもすませることができます。
PDF/Xは印刷データの交換を単一のデータのやりとりですませることを目的としたものでありますが、上記のPDF/X-5gおよびPDF/X-5gpは、OPIとほぼ同様の手法を許可することで、印刷データ自体は複数となってしまいますが、複数回のデータ交換の総量を抑えたり、グラフィックデータは本文とは異なる部署から印刷業者へ渡す、といったことが可能となります。
PDF/X-5gとPDF/X-5gpの違いはPDF/X-4とPDF/X-4pの違いと同じです。PDF/X-5gpは、PDF外部にあるカラープロファイルの参照を許可したものとなります。
PDF/X-5nは若干、他と違ったものになっています。他のPDF/X仕様は、ベースとするPDF仕様に対して、使用可能な機能を制限するものでしたが、PDF/X-5nは、ベースとしるPDF仕様では禁止されている部分を許可しています。PDFでは1成分,3成分,4成分のカラースペースに対するカラープロファイルの仕様が定義されていますが、n成分のカラースペースのカラープロファイルについては定義されていません。PDF/X-5nはこれの仕様が認められています。このプロファイルの仕様は ISO 15076-1:2005で定められているものとなっています。これ以外の部分についてはPDF/X-4pと同様の制限となっています。
このように、PDF/X-5は、PDF/X-4で制限されている内容を、使用するワークフローに応じて、緩和したもと緩和したものと言えます。PDF/X-5の仕様内には、外部のグラフィックを使用する必要がないのであれば、PDF/X-5g、PDF/X-5gpではなくPDF/X-4、PDF/X-4p仕様とするべきである、との記述もあります。
以上、PDF/X-5についてまとめてみました。
PDF、そのほか、各種ご相談はアンテナハウス システム製品技術相談会まで
投稿者 AHEntry : 09:33 | コメント (0) | トラックバック
2012年10月04日
『瞬簡PDF OCR』を使ってみましょう(その2)
日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』を使った変換について、昨日の続きから説明します。
『瞬簡PDF OCR』は、以下の手順で画像からの変換処理を行います。
- 画像データの読み込み
- 領域解析
- 文字認識
- 変換先ファイル形式への保存
昨日は、OCRソフトでは誤変換が避けられないというお話をしました。
本日は、誤変換を回避する方法として、画像データの「領域解析」から説明していきます。
下記は、サンプルのPDFを既定値で変換した例です。
(画像をクリックすると拡大します)
自慢にならないですが、ひと目みて、おかしな変換や文字の誤変換があることがお分かりになるかと思います。
特に赤い丸をつけたグラフ部分がまったく再現されていません。これは、Word上では表に変換されているためです。
この原因は、OCR処理でこの部分の領域を間違えて認識しているためです。
『瞬簡PDF OCR』に戻って、ツールバーにある「領域解析」というボタンをクリックすると、OCR処理でどのような認識が行われたかが分かります。
以下は、問題部分の領域解析結果です。
図で、赤枠で囲まれた箇所は横書きテキスト、ピンク色の枠で囲まれた箇所は縦書きテキスト、緑色の枠で囲まれた箇所は表領域にそれぞれ認識されています。表と認識されたのは、グラフにある横の目盛りを表の罫線と認識したためです。
これでは、Word上で修正しようがないので、元の認識処理に遡ってやり直す必要があります。
誤認識した範囲を画像領域に変更する例を図で示します。
(1)誤認識している領域範囲をマウスでドラッグ→(2)選択された領域をすべて解除→(3)範囲を選択し直し、一括で画像領域に変更
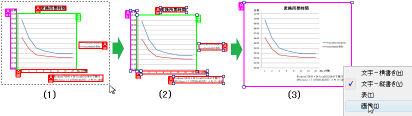
(画像をクリックすると拡大します)
領域を変更したところで、いったんWordに変換して結果を確認してみましょう。いったん「文字認識」を行い、「Wordへ変換」ボタンをクリックします。
以下は、Wordに変換しなおした結果です。先ほどのグラフ部分に注目してください。

(画像をクリックすると拡大します)
さて、変換結果をみると、まだ不具合があります。文書の先頭のタイトル部分が文字を誤認識しておかしなことになっています。
誤認識した文字の修正方法は、また明日の回で説明しましょう。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。
投稿者 AHEntry : 09:00 | コメント (0) | トラックバック
2012年09月20日
PDF/X-4とは
前回のPDF/Xファミリの紹介に続いて、PDF/X-4の概要を記載します。
PDF/X-4は 2008年に国際標準となっています。ベースとしてPDF 1.6を採用し、PDF 1.6の機能内で使用可能な項目を定義することで、印刷用データの交換形式を定めるものです。
PDF/X-4は 2008年に国際標準となっていますが、その後、2010年に改訂が加えられ、Second Edition が発行され、こちらに置き換えられています。
PDF/X-1aおよびPDF/X-3で利用可能な特徴をすべて組み込み、さらにベースがPDF 1.6となっていますので、PDF/X-1a、PDF/X-3のベースであるPDF 1.3やPDF 1.4以降に追加された機能が使用可能となっています。
PDF/X-4は、フォントを埋め込まなければならない等の制限は、PDF/X-3と同様ですが、ベースがPDF 1.6にあがることにより、以下の機能が使用できます。
JPXDecodeフィルタの許可(JPEG2000画像で使用される圧縮方法が使用可能となり、画質をさげずに圧縮率をあげることができます)。
Optional Content使用の許可(これはAcrobatではレイヤーと呼ばれている機能の実装にも使われています)
また、下記はいずれもPDF 1.4で追加された機能ですが、PDF 1.4をベースとするISO 15930-4(PDF/X-1a)、15930-5(PDF/X-2)、15930-6(PDF/X-3)では禁止とされていました。PDF/X-4では、これらの使用が認められています。
JBIG2Decodeフィルタの許可(モノクロ画像用の圧縮方法で、従来の圧縮方法より、圧縮率をあげることができます)
透明使用の許可
この規格内にはPDF/X-4のほかに、PDF/X-4pと呼ばれる準拠レベルが定義されています。こちらは、使用するカラーに関するICCプロファイルをPDFファイル外に置くことを許可したものです。このため、前回説明した Complete exchage ではなくなります。
これはICCプロファイルを埋め込むことによりサイズが増加することを回避する、という理由のほかに、ICCプロファイルの埋め込みが禁止されていて、PDF/X-4が採用できないケースへの対応のようです。
この規格内では、特別な理由がない限りPDF/X-4pではなく、PDF/X-4を優先せよと述べられています。
以上、簡単にPDF/X-4についてまとめてみました。
PDF、そのほか、各種ご相談はアンテナハウス システム製品技術相談会まで
投稿者 AHEntry : 09:00 | コメント (0) | トラックバック
2012年09月19日
PDF/Xファミリについて
しばらく前に、デジタルドキュメントの長期保存のための仕様 PDF/A(ISO 19005)のファミリについて記載しました。
今回は印刷用データの交換を目的としたPDF/Xのファミリについて書いてみたいと思います。
PDF/Xの仕様は、ISO 15930で規定されています。
ISO 15930は複数のパートからなるマルチドキュメントで、各パートがPDF/Xファミリのメンバを定義しています。
- ISO 15930-1:2001(PDF/X-1、PDF/X-1a)
- ISO 15930-3:2002(PDF/X-3)
- ISO 15930-4:2003(PDF/X-1a)
- ISO 15930-5:2003(PDF/X-2)
- ISO 15930-6:2003(PDF/X-3)
- ISO 15930-7:2008(PDF/X-4、PDF/X-4p)
- ISO 15930-8:2008(PDF/X-5g、PDF/X-5n、PDF/X-5pg)
※ IOS 15930-2はPDF/X-2ですが、公開されませんでした。また、上記の中には、改定版が発行されて、新版では年号部分が変わっているものもあります。
PDF/XはPDFの仕様に定められる機能のそれぞれについて、使用することを必須とする、使用することを禁止する、あるいは、なんらかの制限を加えて使用を許可する、ということを定め、印刷用のデータ交換が確実に行えるようにするものです。
わかりやすい例を挙げれば、上記のファミリ全体を通じて、フォントはかならずファイル内に埋め込み、受け取った側にそのフォントが存在しなくても、渡した側と同じ内容の印刷が行われることを保証できるようにしています。
各メンバの特徴を簡単に見てみます。
PDFには、各種バージョンが存在し、バージョンがあがるごとに機能が追加されています。PDF/Xの各メンバも、その規格のベースとなるPDFのバージョンを持っています。
- PDF 1.3をベースとする規格
- ISO 15930-1
- ISO 15930-3
- PDF 1.4をベースとする規格
- ISO 15930-4
- ISO 15930-5
- ISO 15930-6
- PDF 1.6をベースとする規格
- ISO 15930-7
- ISO 15930-8
PDF/Xの仕様内でComplete exchange(あるいは Blind exchange)と呼ばれるものがあります。これはデータ交換において、1回のファイル交換に、必要なすべての情報が含まれていることを意味しています。
たとえば、印刷データをPDFを渡し、その中のあるページの画像は別途送ります、というようなケースは Complete exchangeではありません。
PDF/Xは基本的には Complete exchage を要求しますが、以下のものは、一部のデータを外部におくことを認めた規格です。
- PDF/X-2
- PDF/X-4p
- PDF/X-5g
- PDF/X-5n
- PDF/X-5pg
以上、PDF/Xファミリについて紹介してみました。
PDF、そのほか、各種ご相談はアンテナハウス システム製品技術相談会まで
投稿者 AHEntry : 09:49 | コメント (0) | トラックバック
2012年09月03日
PDF Driver API V5.0利用のマルチプロセス対応アプリケーション開発について
昨日に続き、PDFDriver API V5のスレッドを利用したアプリケーションからOffice文書を一括して、PDFに変換する場合についてお伝えします。
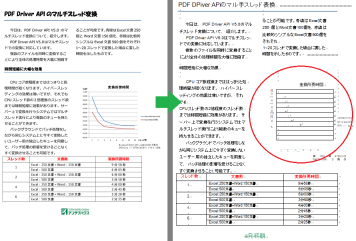
アプリケーション開発では、PDFDriver(仮想プリンタ)の選択・取得をスレッド単位に行い、最適なスレッド数を決めて、ユーザが変換したいOffice文書群を、それぞれのスレッド(PDFDriver)に振り分け、並行出力することにより、変換速度を上げることができます。プログラムから、それぞれのOffice文書に対して、それぞれの出力設定ファイル(プロパティ)を選択、あるいは変更して、PDF変換することが出来ます (図B参照)。
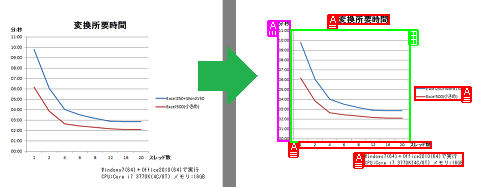
一括してPDF変換の例に、7月2日のブログで紹介しておりますように、スレッド数と変換速度の推移がプロットされております。
グラフを見て頂くと分かりますが、変換元のファイル数、ファイルサイズに関わらず、スレッド数と伴に、変換速度が減少して行く傾向(パターン)は、殆ど同じです。
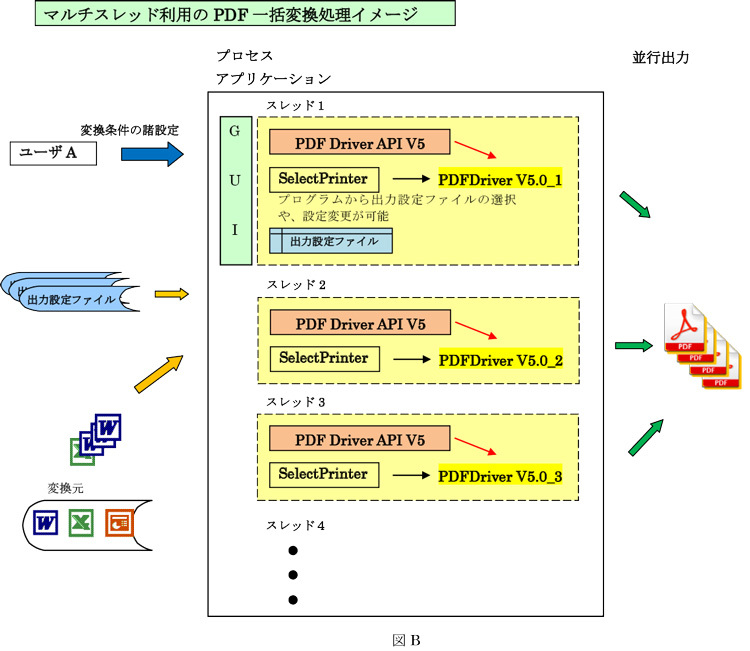
投稿者 AHEntry : 09:00 | コメント (0) | トラックバック
2012年08月31日
PDF Driver API V5.0利用のマルチプロセス対応アプリケーション開発について
PDFは、どんな環境でもレイアウトを崩さず表示できる電子文書として、世界で認められています。
そのような理由から、電子文書の管理は、専らPDF形式で行っています。
紙資料をスキャン(透明テキストを付加)してPDFに変換したものや、MSのOffice文書などを、アプリケーションから直接PDFに変換し、電子文書管理システムに登録して、調査や研究時に、必要な資料を検索、再利用すると云ったことが、多くなってきています。
そこで、PDF変換アプリケーションの開発が容易にできる、アンテナハウス製品を紹介いたします。
アンテナハウスは、仮想プリンタDriver経由でPDF変換を行うソフトウェアコンポーネント製品「PDF Driver API V5」を提供しております。
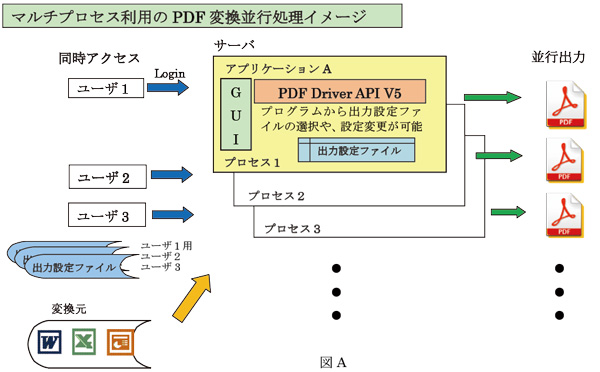
開発者は最低限、入力としてOffice文書(変換元)のパスとPDF(出力先パス)を指定するだけで、マルチプロセス対応の恩恵を受けたPDF変換プログラムの作成が出来ます。
この場合、パスワードを付与、文字の埋め込み等PDFをどのように作成するかを指定する出力設定ファイル(プロパティ設定)は、Default値が自動選択されます。
もちろん、プログラムからPDF変換時に出力設定ファイルの諸設定や変更を動的に行うことができます。
複数ユーザから、サーバ側のPDF Driver API V5を利用したアプリケーションに、同時アクセスが有っても、並行してPDF変換を行うことが出来ます(図A参照)。
マルチプロセス対応になったので、旧バージョンと比較すると、飛躍的に処理速度が上がったことが体験できます。
評価版URL:http://www.antenna.co.jp/ptl/trial.html
投稿者 AHEntry : 09:00 | コメント (0) | トラックバック
2012年07月12日
紙の情報をコンピューターに取り込む
本日は、紙の情報をコンピューターに取り込む手段としてのOCR技術について説明いたします。
OCRとは、Optical Character Recognition(あるいはReader)という英語の略で、日本語では光学的文字認識(あるいは光学的文字読み取り装置)と訳されます。 紙に印刷された文字をイメージスキャナやデジタルカメラなどで読み取り、画像化された情報から文字情報を識別し、コンピュータで処理可能な情報(文字コード)を抽出する技術またはその装置を指します。
こう書くとなんだかややこしいですが、要は人間が新聞や雑誌など紙に書かれた文字を読んで内容を理解するのと同じようなことをコンピュータにもやらせようとするための技術のひとつと言えます。
実はOCR技術は身近なところで使われています。割と古くからあってOCRの老舗といえるのは「郵便番号読み取り装置」でしょう。日本では1968年の郵便番号導入とともに使われたといいますから、既に40年以上の実績があるわけです。 また、試験の際にお目にかかるマークシート方式の回答用紙も採点のためにOCR技術が応用されている身近な例といえます。
これらは大量の情報を一括で高速に処理する必要があるのでOCR装置も専用の高精度、高価格なものが使用されますが、私たちがパソコンを使って汎用に使用する場合には、市販のスキャナとOCRソフトとの組み合わせで取り込むのが一般的です。
さて、実際に紙の原稿からパソコンにデータを取り込み、文字を認識する場合には、概略次のことが行われます。
- 画像で取り込み:スキャナでスキャンした紙の原稿は画像データとしてパソコンに取り込まれます。画像データの種類はお使いのスキャナの仕様によって異なりますが、最近はPDF形式が使用されることが多いようです。PDFであっても内部には画像データのみ格納されています。
- 領域の識別:取り込んだ画像には、当然のことながら紙の原稿のレイアウトが移されています。それは文字であったり、図形であったり、画像であったりします。人間が紙に書かれたこれらの範囲を区別するのと同じようにOCRも識別をします。これを領域(レイアウト)認識または領域解析と呼びます。
- 文字の認識:上記で文字領域と識別された部分について文字データの読み込み(抽出)を行います。
ただし、人間が文字を読み取るのと比較して、コンピュータが文字を読むことは簡単なことではありません。人間の脳は、乱暴に書かれた手書き文字やかすれた文字などを読む場合、曖昧な部分を的確に補って正しく認識する能力を備えていますが、コンピュータはこうした認識が大の苦手です。
例えば、以下は、元の文字画像が鮮明でないために、文字の誤認識が出てしまう例です。
このため、さまざまな方法が考案されて文字の認識率を高める努力がされていますが、文字の認識率が100%(つまり完全)ということにはなかなかなりません。文字のかすれやつぶれがないなどコンディションの良い活字を認識した場合、一般に98%くらいの認識率であれば正確といえるようです。
- 認識結果の保存:OCR処理された結果はそのままでは利用することができません。認識された文字や画像などの情報をパソコン・ユーザーが扱える形式、たとえばWordやExcelなどのOffice文書やテキストファイル、透明テキスト付きPDFなどに保存することで、文字の検索に利用したり、編集して別の文書に再生したりといったことが可能になります。
以上、簡単にアウトラインだけをご説明しました。実際にはOCR技術はもっと複雑で、具体的な文字識別の方法などは興味のつきないところですが、これ以上は専門的な話題となってしまいますのでここでは割愛させていただきます。
投稿者 AHEntry : 09:00 | コメント (0) | トラックバック
2012年07月11日
OCR技術の活用
前回はOCR技術が完璧なものでなく、文字の誤認識は避けられないということをお話しました。
現状では、原稿の文字の品質が十分によければ、市販されているOCR用のソフトウェアで活字を認識できる率は100%に近いところまでいけるようです。
しかし、文字のかすれやつぶれなどがあって品質が低かったり、文字と文字の間隔が狭い場合などは、どうしても認識率が低下してしまいます。
また、広告などで使われる装飾された文字や背景に模様がある文字、イタリックのように斜めに寝てデザインされた文字などはやはり苦手なものです。
では、OCRはまったく使えないかというと、決してそうではありません。
例えば、以下はA4サイズの原稿を弊社の「瞬簡PDF 変換7」のOCR機能を使用してWordに変換した例です。この原稿に含まれる文字数は約1600字あります。
これを、もしOCR技術を使わないで取り込むとしたら、他の手段としてはキーボードから直接文字を打ち込むことくらいかと思います。
原稿が1枚きりであればそれも選択肢と考えられます。しかし10枚、20枚とあったら...これはもう冷や汗ものですね。
また、パソコン上に原稿を移して後から文字で検索するといった用途を考えた場合、文字の誤認識が仮に100文字中10文字あったとしたらどうでしょう?
紙の状態のままでまったく検索できないことを考えると、検索できない文字があったとしても、十分実用の範囲ではないでしょうか?
OCRの文字認識レベルは、特定の産業分野では実績もあり十分実用に耐えるものとなっています。
しかし、不特定の紙の原稿を汎用的に扱うパソコン用のOCRソフトではまだその信頼性は十分でありません。
それでも、こうした技術は日進月歩で、文字の認識率を上げる研究も絶え間なく行われていますから、ハードウェアの進化とともに今後性能が向上することはあってもこのままで停滞することは考えられません。
これまで人の手で時間をかけて行っていたことも、コンピューターにまかせられるところは上手に利用して、人間でなければできない別のところに時間とエネルギーを使うのがOCR技術の賢い使用方法だと思います。
最近は、スマートフォンやタブレットと、クラウドと呼ぶサーバーでのサービスとが組み合わされて、携帯端末のカメラで撮影した画像をクラウド上でOCR処理して文字情報を取得し、送り返すといった仕組みが利用されるようになってきました。パソコンの枠を超えた、こうした利用方法は今後もどんどん増えていくことでしょう。
絶えず新しい技術革新がされて進化を続けるOCR技術と、それを応用したOCRソフトに今後とも注目していただければ幸いです。
投稿者 AHEntry : 09:00 | コメント (0) | トラックバック
2012年07月10日
OCRのよもやま話
先週はNHKテレビのニュースで電子出版EXPO(7/4~7/6)についての話題が何度も取り上げられていました。ニュースを見られた方も、また直接会場に足を運ばれた方もたくさんおられたことでしょう。
弊社でも電子書籍関連の製品とサービスを出展しておりましたが、ご覧になられたでしょうか?
7月の第16回国際電子出版EXPOに、電子書籍関連製品とサービスを出展します。
さて、近年はスマートフォン(スマホ)やタブレット端末が急速に普及し、電子書籍や関連する技術・サービスへの関心も再び高まっているようです。 デジタル化されたデータを扱うといったら、これまではパソコンが主な手段でしたが、大きさや起動に時間がかかるなどの制約があり、いつでもどこでも気軽に使えるというものではありませんでした。
これを劇的に解決したのが、スマホやタブレットなど携帯性に特化した、まさに手のひらの上にのる「コンピュータ」の登場でした。
ハードウェアの進化でパソコンに近い処理性能が与えられてサクサク動作するのもさりながら、何よりインターネットへの接続が簡単にできる(というか、接続を意識することもないほど当たり前につながっている)ことが普及の大きな推進力となっているように思います。
これにより、単に個人の趣味的な使用にとどまらず、ビジネスシーンにおいてもパソコンを駆逐する勢いでスマホやタブレットの活用範囲が広がり続けているのは、皆さんもご存じの通りかと思います。
デジタルなデータを気軽に持ち出し、閲覧できる環境が広く整ってきたことで、電子書籍と同じようにこれまでややもすれば滞りがちだった企業内におけるペーパーレス化(紙文書のデジタルデータ化とその活用)にも拍車がかかることが予想されます。
前振りが長くなってしまいましたが、今週は、やや強引ながら電子書籍など紙を代替するデジタル化技術に欠かせないOCR技術について、これまであまりパソコンに縁のなかった方や、OCRという言葉にあまり馴染みのない方を対象にお話してみたいと思います。
投稿者 AHEntry : 10:36 | コメント (0) | トラックバック
2012年05月14日
PDF/A-3 PDFの新しい目的
PDF/A-3(DIS、以下単にPDF/A-3とします)仕様のIntroductionに、PDFを他のファイルフォーマットのコンテナとして機能できるようにすることが新しい目的である、との記載があります。この部分について、今回は見ていきます。
PDFファイル内にPDFやその他のファイルを格納する埋め込みファイル(Embedded Fil)と呼ばれる機能があります。Acrobat 8で「PDFパッケージ」、Acrobat 9以降で「PDF ポートフォリオ」呼ばれるようになった機能なども、これを用いて実装されています。PDF/A-2の仕様では、埋め込み可能なファイルをPDF/A-1あるいはPDF/A-2形式のファイルに限定していました。
PDF/A-3では、この制限がなくなり、任意の形式のファイルを埋め込むことを認めるように変更されています。
ただし、いくつかの要件が追加されています。
まず、埋め込みファイルがどのようなものであるかを説明するテキストを記載する必要があります。次に埋め込みファイルを記述するデータ内にAFRelaitionshipという、新しいキーを追加しています(PDF/A-1,2 ではベースとなるPDFの仕様に対して使用可能なキーを制限するような形で仕様を定めていましたが、PDF/A-3では、ベースのPDFの仕様では定義されていないキーが使われるようになっています)。
このAFRelationshipは、埋め込みファイルとPDF本文(全体であったり、PDF内の一部であったりします)との関係を指定するもです。
PDF/A-3の仕様で、AFRelationshipに設定する値の例がいくつか記載されています。
・ワープロファイルからPDFを作成し、元のワープロファイルをPDF内に埋め込む場合は"Source"と記載し、PDFのオリジナルデータ(Source File)であることを示す。
・PDF内に数式部分があり、この数式を補足するためにMathMLのデータをPDFに埋め込む場合は"Supplement"と記載し、PDF内のデータの補足データであることを示します。
・PDF内のチャートが存在し、このチャートのデータをCSVで埋め込んでおく場合、"Data"と記載し、チャートの元データであることを示します。
("Source","Data","Supplement"の他に、代替え表現用の"Alternative",それら以外の場合の"Undefined"が定義されています)
また、このほかに、上記の説明で、埋め込みファイルがPDFファイル全体に対するものであったり(上記のワープロの例)、PDF内の一部に対するものであったり(上記の数式の例)することを示すために、PDF内の各種データに埋め込みデータと対応付けをするためのキー(AF)が追加されています。
PDF/A-3は、このような機能の追加により、PDF/A-2を各種ファイルのコンテナとして使用できるように拡張したものとなります。
投稿者 taishii : 09:49 | コメント (0) | トラックバック
2012年05月09日
続・PDF/Aとは― PDF/A-3について
以前、国際標準化機構(ISO)が制定している国際標準 ISO 19005 のパート1、パート2 である PDF/A-1、PDF/A-2についてその概要を記載しました。
今回(および次回)はその続編である PDF/A-3についてまとめてみたいと思います。
PDF/A-1 はISO 19005 パート1として2005年に、PDF/A-2は ISO 19005パート2として2011年に制定されています。これに対して、パート3は、現時点ではDIS(Draft International Standard/国際規格案)というステータスで、まだ審議中のものです。審議中ではありますが、ISO ストアで 仕様書が販売されていますので、このレベルで記載してみたいと思います。
まず、タイトルからですが、PDF/A-2は、「Use of ISO 32000-1(PDF/A-2)」 でしたが、PDF/A-3(DIS)では、「Use of ISO 32000-1 with support for embedded files(PDF/A-3)」となっています。
前回記載しましたように、PDF/Aは PDFの特定のバージョンをベースとして、その機能に対して、使用範囲を制限し、長期保存に適した形(視覚的な外観、およびドキュメントの論理構造、意味などを継続して維持すること)にするものでした。PDF/A-1、PDF/A-2がベースとするPDF仕様はそれぞれ、PDF 1.4、ISO 32000-1 となっていました。PDF/A-3はタイトルからもわかりますように、PDF/A-2同様にISO 32000-1をベースとしています。変更点は埋め込みファイル関連のようです。
PDF/A-2とPDF/A-3の仕様書をざっと比較してみますと、どちらにも、Embedded filesという項がありますが、この項の記載内容が変更され、PDF/A-3では補遺部分に PDF/A-2には無かったAnnex E(informative) Associate Filesという項目が追加されています。この部分を除くと、ISO 32000-1をベースとして、 a,b,およびuの3種類の準拠レベルを定めている点など、PDF/A-3はPDF/A-2とほぼ同様です。
次回は、この変更部分についてまとめてみます。