
« 『瞬簡PDF OCR』を使ってみましょう(その2) | メイン | Server Based ConverterのWindows Server 2012対応について »
2012年10月05日
『瞬簡PDF OCR』を使ってみましょう(その3)
本日は、日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』のご紹介の最終回です。
昨日は、『瞬簡PDF OCR』で領域の誤認識を直す方法について説明をしました。
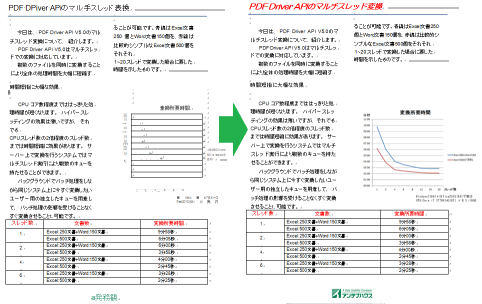
本日は、文字の誤変換を回避する方法として、画像データの「文字認識」について説明します。
これまでの変換例では、文書の先頭のタイトル部分が文字を誤認識しておかしな結果になっていました。
元の文字を見ると、丸文字系のフォントが使われていてデザインを優先した文字であることが分かります。
実は、こういった文字の認識はOCR処理の苦手とする部分です。人間の眼でみればなんということもないのですが、画像化された点の集まりから文字の形を拾い出して元の文字コードを推測するというOCR処理の論理からすると、文字の形状や方向が変化している画像は元の文字を特定しにくくて誤変換しやすいものとなるのです。
OCRソフトを使った変換では、こうした誤変換を変換前に修正する機能を用意しています。
再び『瞬簡PDF OCR』に戻って、ツールバーにある「文字認識」というボタンをクリックします。OCR処理で文字認識した結果が右のテキストビューに表示されますので、誤変換している文字を選択します。
すると、いくつか文字の一覧が傍らにポップアップで表示されるので、そこに正しい文字があれば選択して置き換えます。

同様に他の文字についても置き換えを行っていきます。
また、『瞬簡PDF OCR』では、テキストのフォント種類やサイズ、色、強調表示なども合わせて指定できます。
変換したいテキスト範囲を選択して、「文字のプロパティ」で文字属性を簡単に変更することが可能です。
<
(画像をクリックすると拡大します)
このように文字の認識結果について気になるところがあれば、変換前にある程度修正を行うことが可能です。
さて、以上の修正を行った上であらためてWordに変換した結果を示します。左側の既定値での変換結果と比較してみてください。
(画像をクリックすると拡大します)
一度紙に固定された文書からテキストや画像を取り出し再利用可能にするOCRソフトは、非常に有用なツールです。
オフィスや家庭には、これまであまり再利用されなかった紙の資産がたくさん眠っているのではないでしょうか?
『瞬簡PDF OCR』をご活用いただくことで、皆さまの資産の有効利用に多少なりともお役に立つことができれば、開発・販売を行っているものとして、たいへん嬉しく存じます。
今後とも弊社製品をご愛用いただけますよう、よろしくお願いいたします。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。
投稿者 AHEntry : 2012年10月05日 09:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/1978
コメント
コメントしてください
サイン・インを確認しました、 さん。コメントしてください。 ( サイン・アウト)
(いままで、ここでコメントしたとがないときは、コメントを表示する前にこのウェブログのオーナーの承認が必要になることがあります。承認されるまではコメントは表示されません。そのときはしばらく待ってください。)