
« PDFをWordやExcelで再編集!! 瞬簡/リッチテキストPDF6.1 | メイン | PDFをWordやExcelで再編集!! 画像PDFはここにご注意 »
2011年07月12日
PDFをWordやExcelで再編集!! テキストPDFなのに文字化け!?
今日は、PDFをWordやExcelに変換する場合に、複合型(内部解析変換+OCR変換)の変換方法がお役に立ちます、というお話をさせていただきます。
PDFをWordやExcelに変換して再編集可能にするツール、瞬簡/リッチテキストPDF6.1のお客様からお寄せいただくご質問の中で、画像データでないPDFを変換したのに文字化けしてしまった、というご報告がときどきあります。
例えば、以下のようにPDFではテキストがしっかり表示されているのに、Wordに変換したら見事に文字化けしてしまった!!というケースです。
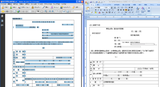
PDFに文字データが含まれるかどうかは、Adobe Reader などのPDF表示ソフトでPDFを開いて、編集メニューなどからすべてのテキストを選択(Adobe ReaderではCtrl+A のキー操作でも可)してみると手っ取り早く確認できます。
上記のサンプルでもテキスト部分がハイライトで表示されているのがお分かりになるかと思います。
さて、これはなぜでしょうか?
理由はPDFの作成方法にあります。
PDFを作成する場合、文字の情報をPDFに格納する方法として以下のふた通りがあります。
- 文字コードをPDFに直接格納する。
- 文字の形状(グリフ)をPDFに埋め込む。
前者は、文字を識別する固有のコード(シフトJISやUnicodeなど)をそのままPDFに格納するもので、PDFから文字を取り出すのも容易ですが、PDFを作成した環境とPDFを表示する環境で使用できるフォントファイルに違いがあると、PDFの見た目が違ってしまう場合があります。
後者は、文字を形づくる輪郭線をデータとして埋め込むもので、どの環境でPDFを開いても同じ見た目で表示されることを目的にしたものです。
一般にはフォント埋め込みされたPDFといいますが、文字の見た目が保証されるので表示する分にはまったく問題ありません。しかし、内部の文字を取り出す場合には文字の形の情報だけでは不十分で、文字の形から文字コードを引き出すための対照表データが必要となります。これがないと、WordやExcelなどのアプリケーションに文字データを正しく渡すことができないのです。
文字コード対照表をPDFに用意するのは、PDFを作成する側のソフトウェアの責任です。ただし、PDFの仕様上、この表を用意するのは必須とされていません。このためこれを省いてPDFを作成するケースが結構多いのです。
ここでようやく本題です。
文字コードを引き出すための対照表データがないPDFをWordやExcelに変換しても文字化けするばかりでは、PDFに文字は見えているのに再利用できないというジレンマに落とされてしまいます。
このとき、OCR機能が用意された複合型変換ソフトがお役に立ちます。
OCR機能は、PDFをいったん画像に変換してから文字の認識処理を行いますので、PDFに文字データがなくても文字を取り出すことができるわけです。
以下は、瞬簡/リッチテキストPDF6.1のOCR機能を使用して先ほどのPDFを変換し直した結果です。
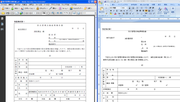
これなら、少しの手直しで再利用できそうですね。
PDF逆変換ソフトではOCR機能がお役に立ちますというところで、次回もう少しそのあたりの詳しいお話しをしてみたいと思います。
なおPDFのフォント埋め込みに関する詳細は、
コンピュータによるテキスト表記とPDFのフォント埋め込みについて
日本語の文字についての用語について(9) ? PDFへのフォント埋め込みとは
などの記事をご参照ください。
投稿者 taishii : 2011年07月12日 11:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/1670
コメント
コメントしてください
サイン・インを確認しました、 さん。コメントしてください。 ( サイン・アウト)
(いままで、ここでコメントしたとがないときは、コメントを表示する前にこのウェブログのオーナーの承認が必要になることがあります。承認されるまではコメントは表示されません。そのときはしばらく待ってください。)