« 2006年01月31日 | メイン | 2006年02月02日 »
2006年02月01日
PDFと文字 (38) – Unicode標準形NFCの実装
さて、先日までに、Unicode文字列をUnicode標準形NFCに変換する処理を実装することで、結合文字列を合成文字で表示できるようになるはず、ということを考えて、実際にXSL Formatterの次期バージョンV4.0のα版に試しに実装してもらいました。
そこで、まずその成果をざっと見てみましょう。Unicodeの標準形を決めているUAX#15には、Normalization Conformance Testというテストケースが付随しています。
これを、従来のバージョンと新機能を実装したバージョンで組版して比較してみました。そうしましたところ次のことに気がつきました。
(1) XSL FormatterV3.4のGUIでは、Unicodeの結合文字列をNFCを使わないで表示しているにも関わらず、結合文字列がかなりの割合で正しく表示できます。
次の図は、XSL FormatterV3.4のGUIに表示される組版結果中、ラテン拡張-Bブロックの後ろの方の画面のスクリーン・ショットです。
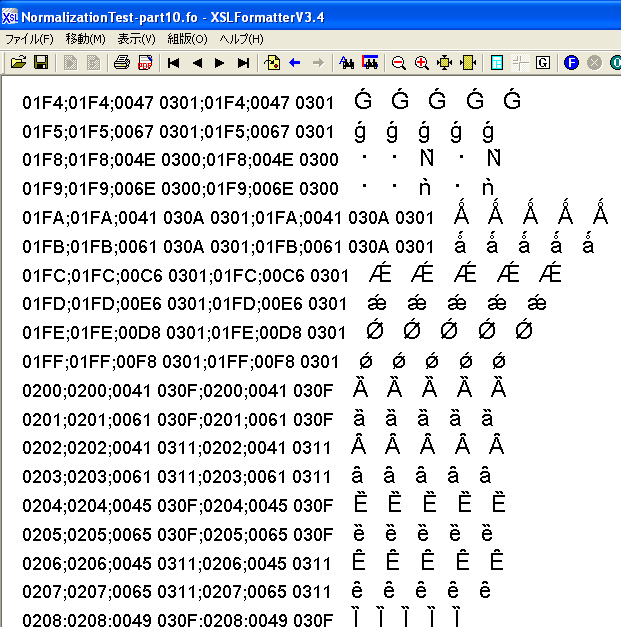
図の中で、左から3列目が左端の文字の正規分解(NFD)です。例えば、U+01FAは、<U+0041, U+030A, U+0301>と正規分解されます。WindowsのGUI経由では正規分解が正しく表示できています。
主なブロックの文字の正規分解が正しく表示できるかどうかを、表に整理しましたが、ラテン文字はほとんど正しく表示できていることが分かります。
| ブロック | コードポイント | Windows XP SP2の表示 | |
|---|---|---|---|
| ラテン文字 | Latin-1追補 | U+00C0~U+00FF | 結合文字列を正しく表示している |
| Latin Extended-A | U+0100~U+017F | 結合文字列を正しく表示している | |
| Latin Extended-B | U+0180~U+024F | U+0218以降の結合文字列が正しくない | |
| Latin Extended Additional | U+1E00~U+1EFF | 結合文字列を正しく表示している | |
| ギリシャ文字 | Greek | U+0370~U+03FF | U+0344, U+0374が不正。一部グリフがない。 |
| Greek Extended | U+1F00~U+1FFF | U+1FBE, U+1FC1, U+1FCD~U+1FCF, U+1FDD~U+1FDF, U+1FED~U+1FEF, U+1FFDが不正。 | |
| キリル文字 | Cyrillic | U+0400~U+4FF | U+0400, U+040D, U+04ECが不正。一部グリフがない。 |
Windows XPは、ラテン文字については結合文字列を画面に表示する際に、結合文字列の中の結合文字の位置を正しく調整していると思われます。あるいは、結合文字列を、それと正規等価な合成済み文字に置き換えているのかもしれません。但し、この処理は、スクリプト依存になっているようです。すなわち、ラテン系はほぼOKですが、キリル文字、ギリシャ文字はNGが幾つかある、というように。
先日(2006年01月29日PDFと文字 (36) – 文字の合成方法(続き))、「Wordは、tildeの高さの制御を行っています。」と書きましたが、これはWordではなく、実際はWindowsが行っているんですね。
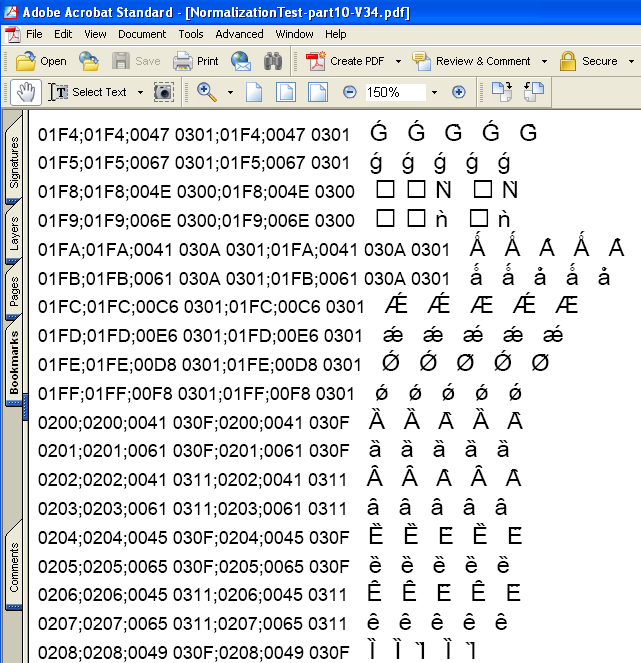
(2) 次に、この文書をFormatterV3.4でPDFにして見ました。上の図と同じ場所のPDFの画面が次の画像です。XSL Formatter V3.4のPDFは、結合文字の位置が正しくないものがあります。これは、バグではなく仕様です。
このように、Windowsの画面表示では正しく見えてしまうのに、PDFにすると結合文字の位置が正しくないことがあるというのは注意が必要です。
(3) さらに、XSL Formatter V4.0 (Alpha)で標準形NFC化の機能をONにして、同じ文書を組版し、PDFを作成してみました。そうしますと、こんどは、正規分解で表した結合文字列も正しく表示できています。次の図を参照してください。
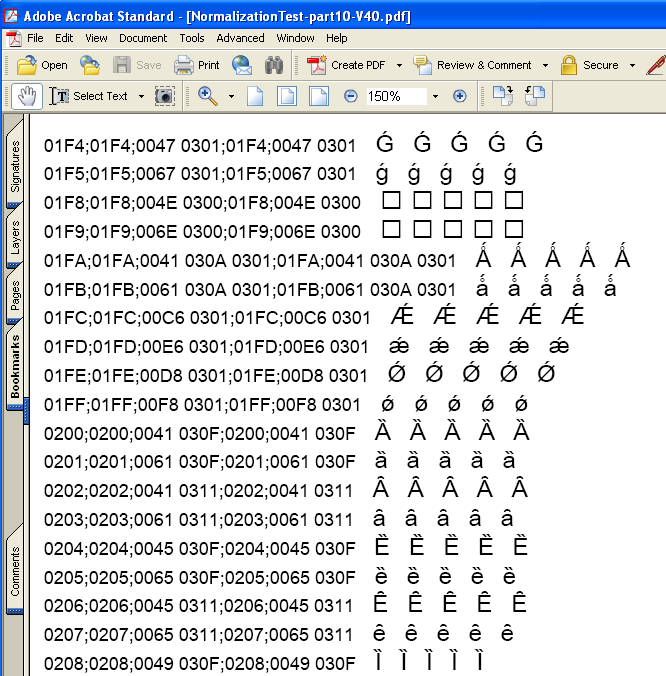
これを見ますと、標準形NFCのサポートにより、正規分解を合成文字として正しくPDFにできるようになっていることが分かります。
なお、この画面でもうひとつ気が付くことがあります。それは、U+01F8、U+01F9がグリフがないとされていることです。この試験では、Unicodeのグリフをもっとも沢山もっているとされるArial Unicode MS フォントを指定しています。しかし、Arial Unicode MS フォントにもU+01F8、U+01F9のグリフはないんですね。
また、最初の画面で分かりますが、WindowsのGUIはU+01F8、U+01F9についてはArial Unicode MS フォントにグリフがないので合成文字は表示できませんが、結合文字列はそれぞれを基底文字と結合文字で表示しています。これを見ますと、Windowsでは結合文字列を画面に表示するとき、フォントに合成済みグリフがあるかどうかをチェックして、グリフがあるときは基底文字と結合文字に正規等価な合成文字に置換しているのかもしれません。いづれにせよWindowsのやっていることは不透明です。
※テスト環境OS:Windows XP SP2(英語版)。地域と言語の設定は、地域のオプション:日本語、Location:日本、非Unicodeアプリケーションの言語:日本語としています。
投票をお願いいたします