« 2006年01月27日 | メイン | 2006年01月29日 »
2006年01月28日
PDFと文字 (35) – 文字の合成方法
Unicodeでは基底文字と結合文字があり、基底文字と結合文字を合成することができることを説明しました。次に合成の実際について少し検討してみたいと思います。
まず、基底文字になることができるのはどんな文字で、結合文字になることができるのはどんな文字かを調べてみます。
Unicodeでは各コードポイントの文字に対応する属性のデータベースとしてUnicode Character Databaseを提供しています。
このデータベースではUnicodeでコードポイントが与えられる全ての文字を、アルファベットや漢字など通常の文字(L)、マーク(M)、数字(N)、句読点(P)、数学・通貨記号(S)、空白・改行などの分離子(Z)、その他(C)の7つの大きなカテゴリーに分けています。
結合文字はカテゴリーMに分類されます。カテゴリーMは、さらに、字幅のない記号(Mn)、字幅のある記号(Mc)、囲み記号(Me)に分類されています。囲み記号は今まで出てきませんでしたが、丸付き数字などを合成して作りだすための○記号などになるのでしょう。
さらに各コードポイントには結合クラスという数字が定義されています。基底文字は結合クラスがゼロ(0)の文字とされています。これに対してカテゴリーMの記号には、1から240の数値が与えられます。
数値の意味は次の通りとなっています。
1:上書きまたは文字の内部
2:ヌクタ(Nukta:デバナガリ文字の結合記号)
3:ひらがな・カタカナの濁音・半濁音
4:ヴィラマ(Virama:デバナガリ文字の結合記号)
10から199:固定の位置
200~240:基底文字の上下左右の位置(図)
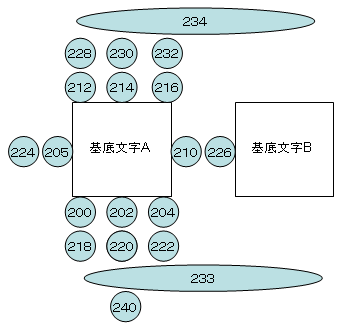
実際に、これまでに出てきました結合文字の結合クラスを調べてみましょう。
| 文字名 | コードポイント | カテゴリ | 結合クラス |
|---|---|---|---|
| Hamza Below | U+0655 | Mn | 220 |
| Kasra | U+0650 | Mn | 32 |
| Shadda | U+0651 | Mn | 33 |
| Fatha | U+064E | Mn | 30 |
| Combining circumflex accent | U+0302 | Mn | 230 |
| Combining macron below | U+0331 | Mn | 220 |
| Combining macron low line | U+0332 | Mn | 220 |
| Combining grave accent | U+0300 | Mn | 230 |
| Combining tilde | U+0303 | Mn | 230 |
| Combining diaeresis | U+0308 | Mn | 230 |
| Combining macron | U+0304 | Mn | 230 |
| Combining macron over line | U+0305 | Mn | 230 |
| Combining accute accent | U+0301 | Mn | 230 |
| Combining cedilla | U+0327 | Mn | 202 |
| Combining ring above | U+030A | Mn | 230 |
| Devenagari vowel sign aa | U+093E | Mc | 0 |
| Devenagari vowel sign i | U+093F | Mc | 0 |
| Thai char. sara i | U+0E34 | Mn | 0 |
| Thai char. mai tho | U+0E49 | Mn | 107 |
実際のデータではデバナガリ文字や、タイ文字では結合文字の属性をもちながら、結合クラスがゼロになっている文字があります。
基底文字に続く結合文字の並びは、その結合クラスの値を参照して基底文字の上下左右に配置するのだな、ということが想像できますね。そうして、Unicodeの合成規則は、ラテンアルファベットとダイアクリティカルマークを対象に考案されていて、アラビア文字、タイ文字、デバナガリ文字には適用できそうもないこともなんとなく想像されます。
投票をお願いいたします