« 2006年01月16日 | メイン | 2006年01月18日 »
2006年01月17日
PDFと文字 (25) – CMapで文字コードからCIDへ変換
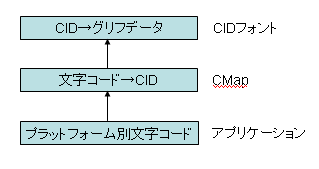
Adobe-Japan1、Adobe-GB1などのグリフセットでは、ひとつひとつのグリフにCIDという番号が付いていることは説明しました。CIDフォント・ファイルには、文字を画面表示したり印刷するためのグリフ・データを収容しています。フォント・ファイルに収容されているグリフ・データにアクセスするときはCID番号を使わなければなりません。
Windows、LinuxやマッキントッシュなどのOSや、OSの上で動くアプリケーションは、Unicode、または機種専用の文字コードを使ってテキストを処理します。一方、CIDフォントにあるグリフを使ってその文字を表示・印刷するには、文字コードからCIDに変換しなければなりません。
この文字コードからCIDへの変換を定義するのがCMapです。
図 CMapで文字コードからCIDへ変換
アドビシステムズはAdobe-Japan1、Adobe-GB1などのグリフセット毎に多数のCMapファイルを提供しています。古いCMapにはNECのPC、富士通のPC、Windows3.1、マッキントッシュなど機種依存文字コードからCIDへの変換用が沢山あります。しかし、最近のCMapはUnicodeからCIDへの変換用が中心になっています。
例えばAdobe-Japan1用の比較的新しいCMapには次のようなものがあります。
| CMap名称 | 内容 |
|---|---|
| UniJIS-UTF8-H | Unicode 3.2 (UTF-8) からCID |
| UniJIS-UTF8-V | UniJIS-UTF8-Hの縦書用 |
| UniJIS-UTF16-H | Unicode 3.2 (UTF-16) からCID |
| UniJIS-UTF16-V | UniJIS-UTF16-Hの縦書用 |
| UniJIS-UTF32-H | Unicode 3.2 (UTF-32) からCID |
| UniJIS-UTF32-V | UniJIS-UTF32-Hの縦書用 |
| UniJISX0213-UTF32-H | Unicode 3.2 (UTF-32) からCID Mac OS X Version 10.2互換 |
| UniJISX0213-UTF32-V | UniJISX0213-UTF32-Hの縦書用 |
各CMapファイルには、横書用(-H)と縦書用(-V)の2種類があることに注意してください。これは次のような仕組みです。
(1)文字によっては横書と縦書で表示・印刷用の字形が異なるものがあります。
(2)グリフセットには、これらの文字に相当するグリフには横書用と縦書用の2種類が用意されています。(次の例)
横書用グリフの例: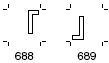
縦書用グリフの例: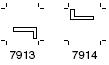
※Adobe-Japan1-6 Character Collection for CID-Keyed Fonts p. 12, p. 76
末尾に-Hの付くCMapを使うと、文字コードから横書用グリフのCID番号に変換することになり、同-Vの付くCMapを使うと、縦書用グリフのCID番号に変換することになります。
OSやアプリケーションの文字コードを内部コードと言うと、CID番号の付いたグリフは表示層と言えます。この内部コードと表示層を分離して、CMapで仲立ちをさせていることになります。この仕組みでフォントをプラットフォームの文字コードから独立にした、ということがCIDフォントの意義ということになります。
但し、CMap方式で入力値として指定できるのは単一コードになります。縦書と横書に対してCMapを切り替えることで、単一の入力コードからそれぞれ異なるグリフを得るCIDフォント方式は、漢字やかなのような単純な記法の文字を使う日本語や中国語などしか適用できないでしょう。例えばアラビア文字や南インド文字、あるいはラテン文字の結合やリガチャには対処し難いように思います。
投票をお願いいたします