

本日は、度々お問い合わせのある、Antenna House Formatterでの異体字の使用についてお話しします。
異体字とは
・同じ意味/発音を持っているが、異なる表記の字体の文字
・新字と旧字による違いや、手書きによる個人差から生じたものなどもある
・人名や屋号、地名に多く使われる
JISやUnicode仕様においては、基本的に異体字ごとに異なるコードを割り振るようなことは行っていません。(ただし例外もあります)
Unicodeでは異体字セレクタという名称でタグを付けることにより、先行する一文字と組み合わせて定義付けされた字体を選択する方法をとります。
2006年1月13日に漢字で異体字セレクタを使うための漢字字形データベース(Ideographic Variation Database)への登録手続きが定められ、2007年12月14日に最初の異体字コレクションとしてAdobe-Japan1が登録されました。
Antenna House Formatterはこの異体字に対応しています。
異体字選択機能を持っているCIDフォント(OpenTypeフォント)と組み合わせて使うことで、Antenna House Formatter から、PDFへの異体字出力が可能です。(PDF出力のみ、他の出力オプションは未対応)
Antenna House Formatter での使用方法
Antenna House Formatterで、これらを使うには次のようにします。
例えば、葛飾区と葛城市の「葛」には、二つの字形があります。
どちらの文字も、U+845Bという符号位置に統合されています。
異体字セレクタを使って、次のように区別することができます。
1. U+845B U+E0100
2. U+845B U+E0101
XSL-FOでは、次のように書きます。
<fo:block>葛󠄀</fo:block>
<fo:block>葛󠄁</fo:block>
これを小塚明朝 Pr6N フォントを使用した場合、出力は次のようになります。
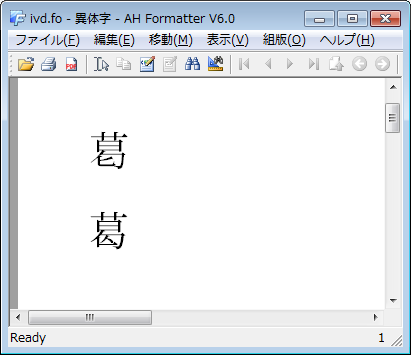
皆さんも試してみてください。
年別アーカイブ: 2011年

Antenna House Formatter V6 のルビ機能
Antenna House Formatter V6 ではルビ機能について拡張し、
使いやすく、正しい表現が可能になりました。
Antenna House Formatter V5 までは、ルビを直接表現できなかったため、fo:inline-container などを利用して模倣せざるを得ませんでした。そのためルビの配置や行分割に対して多くの制約がありました。
Antenna House Formatter V6 で実装されたルビ拡張では、このような制約を取り払い本来のルビを表現できるようになりました。
ルビ機能を使ったサンプルをご覧ください。

ぜひ、これらの機能をお試しください。
Antenna House Formatter V6 の評価版のダウンロードはこちらから。
明日もAntenna House Formatter V6 のお話が続きます。
Antenna House Formatter V6 を米国国税庁が採用!
本日も、9月30日にリリースとなった、世界標準の自動組版ソフト Antenna House Formatter V6 についてです。
以前にもお話しましたが、Antenna House Formatter V6 は、米国の国税庁の新しいPDF配布ページに採用されました。
プロジェクトでは、ページ組版の多くの要求仕様がリストアップされていました。
次のようなものです。
・Open Type Fonts に対応
・マルチバイト言語に対応
・TaggedPDF出力機能
・XSLT, XSL-FOに対応
・Logファイルを生成する
・4つのカラムをサポート
・ヘッダ、フッタ機能
・段組ページの上か下または隅に段を跨るフロート配置
・ページや段の任意の位置へのフロート配置
・フットノート機能
・改定バーの代わりに任意の文字を置く機能
・カラムのバランス機能
・ハイフネーション機能
・インデックス機能
・水平、垂直アライメント機能
・PDFを画像としてPDFに埋め込む
・行折り返し時のインデント位置指定機能を追加
・AcroForm による記入欄のあるPDFを埋め込み
:
などなど。
これらの多くは既に実装済みでしたが、不足している機能もありましたので、それらを実装することで採用となりました。Antenna House Formatter V6 では、これら多くの要求を満たす充実した機能をご利用いただけます。

ぜひ、Antenna House Formatter V6 の評価版をお試しください。ダウンロードはこちらから。
明日も Antenna House Formatter V6についての話です。
世界標準の自動組版ソフト Antenna House Formatter V6 新発売!
かねてよりブログなどで報告させていただいておりました、自動組版ソフトの新版 Antenna House Formatter V6 を 9月30日にリリースいたしました。
今回の新版では、float機能の強化によって、従来は難しかった図版の自由な配置を実現しました。
ページの指定位置に floatを配置したり、段組の中に float を配置したり、段組中を通しで float を配置したりすることができます。
色々な指定をしたfloat機能のサンプルをご覧ください。

・バージョンアップについて
現在 Antenna House Formatter V5 をお使いのユーザー様は、Antenna House Formatter V6 に無償バージョンアップしていただけます。
無償バージョンアップの条件などにつきましては、こちらをご参照ください。
バージョンアップをご希望されるユーザー様は、
弊社保守サービス:hosyu@antenna.co.jp宛に、ユーザIDとシリアル番号を記述し、V6へバージョンアップ希望と書いてメールにてご連絡ください。
なおバージョンアップの場合、ご依頼から発送まで一週間程度のお時間がかかりますので、よろしくお願いいたします。
明日も引き続き、Antenna House Formatter V6についてお話します。
DITA超入門 ― まとめ
こんにちは。DITAの話は今日でいったんおしまいにします。
昨日までの4日間で漏れてしまった話題について、軽く紹介しておきます。
■conref
昨日、条件処理を使ってコンテンツの一部を出したり出さなかったりをする方法を紹介しましたが、conrefは他のトピックの中のほんの一部を流用する機能です(フラグメント単位での再利用)。
製品名とかコピーライト表記をひとつのトピックファイルにまとめておいて、それを参照したりするような使い方をします。
■関連テーブル
どのトピックとどのトピックが関連し合っているのかを、それぞれのトピックの中ではなくマップの中に記述することができます。
トピックの中に関連情報を書くこともできますが、そうするとトピック間の関連関係が変更されたとき、トピックをこつこつと変更しなくてはなりません。それはそれで大変なので、マップに追いやってしまおうというわけですね。こうすることでマップだけを修正すればいいことになります。
■keyref
これは参照先をマップで解決しようという機能です。言葉で説明するのは難しいのですが、図式化すると次のようになります。
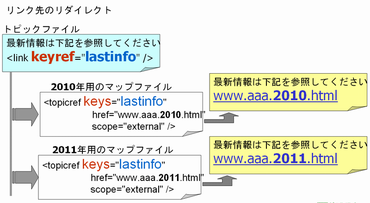
トピックの中には具体的な参照先は書かないで、マップに書いてしまおうということですね。
この機能は最新のDITA1.2仕様で追加された機能です。一度書いたトピックはできるだけ変更しなくてもいいようにしよう、可変データは可能な限りマップに追いやってしまおう、というDITAの設計思想が感じられます。
■DITA Open Tookit
せっかくマップやトピックが用意できたのに、これをどうやってHTMLやPDFにすればいいんだろう、という疑問がありますよね。大丈夫です。マップやトピックを処理して最終成果物を作ってくれる「DITA Open Tookit」という処理系がすでにあります。オープンソースで誰でも無償で使うことができます。入手先は下記です。
http://sourceforge.net/projects/dita-ot/
Open Toolkitは
* トピックファイルや画像などの素材を集める
* 条件処理を解決する
* conrefやkeyrefを解決する
* PDFやHTMLを作る
といったことを自動的にやってくれます。
■期待するレイアウトを実現するには
Open Toolkitを使えばPDFを作ることはできるのですが、あくまでもサンプル程度です。
これを期待したレイアウトにするにはそれなりのカスタマイズが必要になります。具体的にはPDF生成用のXSLTスタイルシートを作らないといけないのですが、弊社ではこのスタイルシート作成を請け負っていますので、ぜひご相談ください。
また、Open Toolkitには標準で自動組版エンジンが付いてくるのですが、正直な話、機能的にいまいちです。特にまじめに日本語組版をしたいということであれば、Antenna House Formatterが必須になります。
■お問い合わせ
DITA導入についてのお問い合わせをお待ちしております。
営業担当:小林(guten@antenna.co.jp)までよろしくお願いいたします。
では、5日間ありがとうございました。
最後に関連情報のリンクを少しだけ
OASIS DITA仕様(英語サイト)
DITA News(英語サイト)
DITAコンソーシアムジャパン(日本語サイト)
アンテナハウスDITAサービス(日本語サイト)
DITA超入門 ― 特殊化ってなに?
こんにちは。今週のDITA超入門も、残すところ、あと1回です。
今回は特殊化の話題です。
「DITA」の最初の「D」は(進化論の)ダーウィンの頭文字から来ていますが、ずばり、特殊化という機能があるがゆえにダーウィンの登場というわけです。
昨日までに紹介した機能は、名称や形こそ違え、似たようなことは昔から行われてきました。しかし特殊化という機能はおそらくDITAが最初ではないでしょうか。
■特殊化
特殊化とは既存の情報タイプ(トピックタイプ)を自分が好きなように拡張することです。たとえばdocbookでドキュメントを記述するとき、docbookの仕様の中で定義されている要素をそのまま使うしかありませんが、DITAの場合、都合のいいように要素を定義し直してもいいよ、と。もちろんある程度の制限というか作法のようなものは守らなければいけませんが。
生物は環境に適したものが生き延びる、というのが進化論の教えるところですが、情報タイプもあなたの環境に応じたものを用意していいですよ、というわけです。
次のような手順を出力したい、としましょう。
—
1. 電源スイッチを押す
2. [ラジオ]ボタンを押す
3. チューニングレバーを回す
—
もっとも初歩的な解決方法は次のようなトピックを用意することです。
<topic>
<title>ラジオの聴き方</title>
<body>
<ol>
<li>電源スイッチを押す</li>
<li>[ラジオ]ボタンを押す</li>
<li>チューニングレバーを回す</li>
</ol>
</body>
</topic>
もちろんこれでも期待する結果は得られますが、では次のような例はどうでしょうか。
<task>
<title>ラジオの聴き方</title>
<taskbody>
<steps>
<step><cmd>電源スイッチを押す</cmd></step>
<step><cmd>[ラジオ]ボタンを押す</cmd></step>
<step><cmd>チューニングレバーを回す</cmd></step>
</steps>
</taskbody>
</task>
前者は番号付き箇条書きであることは分かりますが、どういった意味の箇条書きであるのかまでは分かりません。それに対して後者の場合、単なる箇条書きではなく、何かの「手順」であるということがはっきりと分かります。どちらの方が情報の質が上かと言えばもちろん後者ですよね。
このように、それまでは<ol>を使うしかなかった状況から、(情報の質を高めるために)<steps>を使える状況に拡張することが特殊化です。
あ、これは<ol>に限ったことではなく、別の要素だって特殊化の対象になりえます。
■情報タイプ(トピックタイプ)
DITAにはすでに下記の情報タイプ(トピックタイプ)が用意されています。
【汎用topic情報タイプ】
DITAの出発点となる情報タイプで、HTMLライクな要素が定義されています。この情報タイプを使えばだいたいどのようなマニュアルも記述できますが、先ほど述べたように情報の質という点では劣ります。
昨日までにいくつかのトピックサンプルを例示しましたが、すべてこの情報タイプで記述したものです。
【task情報タイプ】
操作手順を記述するのに特化した情報タイプです。どのような順番でどういう操作をすればどのような結果が得られるか、というようなことを記述しやすいようになっています。
この情報タイプは上記の汎用topic情報タイプから派生させた(特殊化した)ものです。
【concept情報タイプ】
「それは何か」に対する答えを記述するのに便利な情報タイプです。たとえば「製品の特徴」であるとか「ご使用の前に」とか…etc。上記のtask情報タイプでは記述できないコンテンツは大抵この情報タイプを使うことになるでしょう。
この情報タイプは上記の汎用topic情報タイプから派生させた(特殊化した)ものです。
【reference情報タイプ】
リファレンスマニュアルを記述するのに特化した情報タイプです。
この情報タイプは上記の汎用topic情報タイプから派生させた(特殊化した)ものです。
【glossary情報タイプ】
用語集を記述するのに特化した情報タイプです。
この情報タイプは上記のconcept情報タイプから派生させた(特殊化した)ものです。
おおよそこれらのすでに用意された情報タイプで事足りると思いますが、中にはそれでも不十分だということもあるでしょう。そのときは(上記の情報タイプから派生させる形で)自分で特殊化することになります。
今日の話を図式化すると次のようになります。
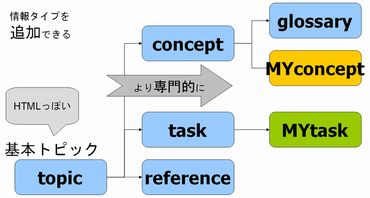
なんだか、いかにもダーウィンって感じですね。
特殊化については(それだけで数十ページ書けそうな話題なので)これ以上突っ込んだ話は他の参考書に任せますが、日本語の参考書としては
DITA 101
DITA概説書
があります。
では、また明日。
DITA超入門 ― フィルタリング トピックを効率的につくる!
こんにちは。昨日に引き続きDITAのお話です。
昨日は(複数の)トピックとマップを使ってマニュアルを作るという話でした。この仕組みによってトピック単位でのデータ再利用が実現されるわけです。
ここで、ある製品Aと別の製品Bとで充電の方法が「ほんの少しだけ」異なる場合を考えてみましょう。昨日の話の範疇で考えると「充電の方法-A用.dita」と「充電の方法-B用.dita」のふたつを用意して、マップの中から必要な方のトピックを参照すれば無事解決です。もちろんこの方法で間違っていません。
ただ、「ほんの少しだけ」違うだけなのにトピックを丸ごとふたつに分けるのもなんだかな~、と思いますよね。
そこで条件処理(コンディショナルプロセシング)の出番です。
■条件処理(コンディショナルプロセシング)
条件処理には、大きく2つの機能があります(フィルタリングとフラッギング)。今日は、そのうちのひとつ、「フィルタリング」を紹介します。
●フィルタリング
ひとつのトピックファイルの中に複数の製品の情報を混在して書いておいて、マニュアル生成時にその時の条件によって、特定の情報を出力したり、出力しなかったり、をコントロールすることをフィルタリングといいます。具体例をあげましょう。
<topic id=”HowToCharge”>
<title>充電の方法</title>
<body>
:
:
<p product=”上位モデル”>
充電が完了するのに「30分」程度かかります
</p>
<p product=”下位モデル”>
充電が完了するのに「60分」程度かかります
</p>
<p>
充電中は電源を入れないでください
</p>
:
<body>
</topic>
ここには上位モデル用の充電時間と下位モデル用の充電時間が混在して書かれています。このまま何も考えずに処理すると両方ともマニュアル内に出力されてしまいます。
そこで、もうひとつ、ditavalファイルというものを用意します。上位モデル用の出力を得たい場合は次のような内容にしておきます。
<val>
<prop att=”product” val=”上位モデル” action=”include” />
<prop att=”product” val=”下位モデル” action=”exclude” />
</val>
ここでは、
* product属性が「上位モデル」のコンテンツは出力してください
* product属性が「下位モデル」のコンテンツは出力しないでください
* その他は出力してください
ということを意味しています。
そしてマニュアルを作る時に、このditavalファイルを使ってくださいね、と宣言すると次のような出力が得られるわけです。
—
充電が完了するのに「30分」程度かかります
充電中は電源を入れないでください
—
見事に下位モデル用の記述が抜け落ちていますね。
こうすることで、「ほんの少しだけ」違うトピックを複数個作る必要がなくなるわけです。
この機能をうまく使えば、ひとつのトピックの中に「Windows向けとLinux向けの記述」であるとか「上級者向けと入門者向けの記述」であるとかを混在して書いてもいいことになりますね。
では、また明日。
DITA超入門 ― トピックとマップ 避けては通れないはじめの一歩
こんにちは。昨日に引き続きDITAのお話です。今日は、DITAの初めの一歩として避けては通れないトピックとマップについて触れてみます。
DITAではひとつのドキュメントを作るにあたり、(複数の)トピックと(ひとつの)マップを組み合わせて使います。
■トピック
トピックにはドキュメントのコンテンツを記述します。たとえば次のようになります。
<topic id=”GoalOfDITA>
<title>DITAのめざすもの</title>
<body>
<p>DITAの目的は次のとおりです</p>
<ul>
<li>データ再利用性の向上</li>
<li>ワンソースマルチユース</li>
<li>翻訳の効率化
</ul>
</body>
</topic>
なんだかどこかで見たことあるような..ないような…
そう、雰囲気的にはHTMLにそっくりです。とりあえずここまではあまりハードルは高くなさそうですね。
ひとつのトピックファイルにはひとつのトピック(話題)しか書かない、ということが推奨されています。ひとつのトピックファイルの中でだらだらといくつもの話題に触れるのはよしましょう、ということですね。そのため、ひとつのドキュメントを制作するにあたり必然的に複数のトピックファイルを用意することになります。
■マップ
上記の(複数の)トピックファイルをひとつにまとめることがマップの役割です。マップを使ってトピックの出力順やトピック間の階層構造を決めることになります。たとえば次のようになります。
<map title=”取扱説明書”>
<topicref href=”はじめに.dita” />
<topicref href=”電源の入れ方.dita” />
<topicref href=”ラジオの聴き方.dita” />
:
:
</map>
この例は超基本的な例です。この他にさまざまな機能が用意されています。個人的にはマップを制することがDITAを成功へ導く秘訣だと感じていますが、ま、最初の一歩としては上記で十分でしょう。
マップとトピックの関係を図式化すると次のようになります。
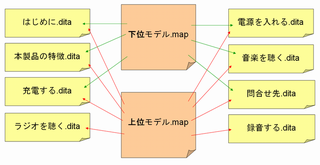
この図を見て分かるように、マニュアルの種類だけマップを作り、それぞれのマップから1セットのトピックファイル(群)を共有参照する、というのがDITAの基本的な考え方です。
■トピック指向の執筆
ワードやdocbookでマニュアルを書くときは、1つのファイルに1冊分のコンテンツを丸ごと記述することになりますが、DITAでは複数のトピックファイルに分割して記述することになります(モジュール化)。こうすることで各トピックの再利用性の向上を図るわけですが、このことにより、執筆の仕方を今までとは変えなくてはならないことがあります。
たとえば「ラジオの聴き方」を書いたトピックの中では「すでに述べた方法で電源を入れた後に・・・」という書き方は避けた方がいいでしょう。なぜならマップの書き方次第では「すでに述べた」とは言い切れないからです。後で述べるかもしれませんし、そもそもどこにも述べない可能性もあります。つまり文脈依存の書き方は避けた方がよい、ということになります。これをトピック指向と言います。
■ショートデスクリプションの奨め
トピック内にショートデスクリプション(要約)を書くことが推奨されています。たとえば次のようになります。
<topic id=”GoalOfDITA>
<title>DITAのめざすもの</title>
<shortdesc>DITAによってマニュアル制作の効率化を望めます</shortdesc>
<body>
<p>DITAの目的は次のとおりです</p>
<ul>
<li>データ再利用性の向上</li>
<li>ワンソースマルチユース</li>
<li>翻訳の効率化</li>
</ul>
</body>
</topic>
こうすることでHTMLにした場合など、アンカー文字列にマウスホバーしたときに要約をポップアップさせたり、検索結果として要約のみをリストアップすることができるようになります。
とても小さなトピックの場合、要約を書くことによって本文に書くことがなくなってしまう、という心配もあるかもしれませんが、そのときは本文の方を空にします。それほど要約が重要視されているということですね。
各トピックの要約を読んだだけで製品の全体像がそこそこ分かってしまう、という形が理想的なのかもしれません。ですので、
<shortdesc>ここではxxxについて述べます</shortdesc>
というような要約はご法度です。
では、また明日。
これ以上ないくらい分かりやすいDITA入門(当社比)
こんにちは。今日から5日間、XML関連営業担当からDITA関連のお話をさせていただきます。
これ以上分かりやすいDITA入門情報は他に無い、という文面を心がけますのでしばらくの間お付き合いください。
●DITAとは
ここ数年、日本でもDITAの話題が盛んになってきました。DITAはもともとIBMが策定したマニュアルを記述・管理するための仕様で、その後この仕様はOASISに寄贈され世界標準の仕様となり注目を集めています。
2008年に「DITAコンソーシアムジャパン(http://dita-jp.org/)」がアンテナハウス、ジャストシステム、日本アイ・ビー・エム、富士ゼロックスの4社が発起人として設立され、現在26の企業、団体が会員となっています。
年に2回のペースで「DITAコンソーシアムジャパン」主催のイベントが開催されていますが、毎回、参加者募集開始後ほんの数日で100名を超える方々からの応募をいただいていて、DITAへの関心度が非常に高いことをしのばせています。この状況は今後も続くものと思っています。
●DITAはどんなマニュアル、またはマニュアルのどの部分を作るのに効果的?
もともとマニュアルを記述・管理するための仕様ですので、各企業のマニュアル制作ご担当者はもちろんのこと、制作会社や翻訳会社も大きな関心を持たれているようですが、突然DITAと言われても、いったい何から手をつければいいのかとまどっていらっしゃる方も多いのではないでしょうか。
そのDITA仕様ですが、目的は次の3つです。
* データ再利用性の向上
* ワンソースマルチユース
* 翻訳の効率化
これらはどれも絡み合った話ですので、あえて3つに分けることもないかと思いますが、ともかくDITAはこれらを実現するために考えられた仕様です。つまり、次のような方々はDITA採用を検討する価値がおおいにあるということです。
* 似たような製品を複数製造しているけれど、それぞれの製品のマニュアルをすべて個別に作っている
–>大多数の共通箇所は1つにまとめたいよなぁ…
* 住所や電話番号・部署名が変わったとき、数多くのマニュアルを改修するのがめちゃくちゃ大変だった
–>ほんのちょっとした変更にはほんのちょっとしか汗を流したくないよなぁ…
* いままでは紙のマニュアルだけだったけれど、これからはHTMLでも作らないといけなくなった
–>紙マニュアルのデータをHTMLでも流用したいよね…
* 毎年マニュアル改訂があるけれど、翻訳にかける時間を短くしたいなぁ…
では、DITAという仕様を「採用しただけで」すべて一気に解決すのでしょうか。答はNo.です。ここを勘違いすると後で痛い目に遭います。
明日以降、これらのことにも触れながら、少し具体的にDITAの仕様を見ていくことにします。
欧米ではDITA採用がちゃくちゃくと進んでいます。DITAという黒船はすでにそこまで来ているんですね。
●参考URL
DITAとは (アンテナハウスDITAサービスより)
AH FormatterとFormatter Clubをよろしく
こんにちは。XML自動組版ソフト AH Formatter の開発担当です。いつもは「CSS組版ブログ」にいるのですが、今日はアンテナハウスのメインのこのブログに進出です。
このブログでも案内がありましたが、AH Formatter とその関連技術(XSL、CSS、XML 多言語組版など)に関心をもっていただいている皆様と開発者とをつなぐコミュニティとして“Formatter Club”を7月に発足し、先週9月16日に第2回定例会を開催しました。私からは、AH Formatter V6の紹介(この資料もXHTML+CSSでAH Formatterで組版)と、いくつかのサンプル文書をAH Formatterで組版して見せるデモを行いました。
お見せしたデモは次のものです:
-
 米国国税庁の案件のためのテストデータ
米国国税庁の案件のためのテストデータ段組のページに段をまたがる図表の配置が多用されています。たとえば3段組のページの右下に2段抜きで表があるなど。
-
これの第2版が公開準備中で、その書籍版の組版をAH Formatterで行います。データはXHTML+CSSですが、AH Formatter拡張を含むページ組版用のCSSスタイルシートを指定しています。V6でのfloat拡張を利用することにより、図版の配置が最適化され、従来のXML自動組版では図版が多いとページに余分なアキが生じやすかった問題が解消されています。
-
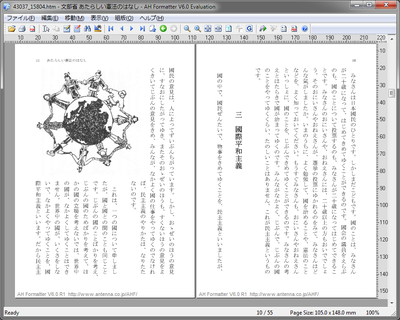
青空文庫のXHTMLを縦書きのCSS指定で縦書きで、文庫本のような体裁になるように柱やノンブルをつけています。図版はV6の拡張floatを利用して、天・小口寄りに自動的に配置しています。AH Formatterが、縦書き青空文庫ビューアーになるというデモです。
このようなデモをするとき、AH FormatterのWindows版GUIアプリケーションは便利です。AH Formatterはサーバー上のシステムに組み込まれて利用されることが多いのですが、このWindows版アプリケーションは、手軽にAH Formatterの組版を試すために使えます。
(AH Formatterはマルチプラットフォームであり、Windows以外に、Mac OS X、Linux、各種Unix系のOS用のものがあります。いまのところWindows版のみGUIアプリケーションを用意しています)
Windows版AH Formatterアプリの動作は、Webブラウザに似ています。HTMLやXMLのURLを指定すると組版がはじまりページが表示されます。ファイルをWindowsエクスプローラからドラッグ&ドロップでAH Formatterに与えることもできます。また、Webブラウザのアドレスバーのアイコンをドラッグ&ドロップしてブラウザで開いているURLをAH Formatterで開くこともできます。
AH Formatterの上級ユーザーにも意外に知られていないのは、文書ファイル(HTMLまたはXML)と、スタイルシート(CSSまたはXSL)を別々にAH Formatterにドラッグ&ドロップすることも出来るということです。文書とスタイルシートを同時にドラッグ&ドロップすると、両方組み合わせて組版されますが、はじめに文書をドラッグ&ドロップ、次にスタイルシートをドラッグ&ドロップ、あるいはその逆の順番で行うこともできます。
青空文庫のXHTMLファイルをAH Formatter V6拡張入りのCSSを指定して組版するデモでは、まず青空文庫のXHTMLだけをAH Formatterにドラッグ&ドロップしました。そうすると、Webブラウザで表示するのと同じように、青空文庫XHTMLにもともと指定されているCSSだけでまず組版された結果が表示されます。そこに、CSSファイル aozora-ah.css をドラッグ&ドロップすると、こんどはそのCSSを使っての組版に変わります。さらに別のスタイルシートをドラッグ&ドロップしてスタイルを切り替えるといったこともできます。
どうでしょう? まだAH Formatterを試していない方も、試してみようという気になりませんか?
AH Formatterは評価版をダウンロードして試してみることが可能です。おすすめなのは、Formatter Clubに入ることです。そうすると、開発中の最新版のAH Formatterをダウンロードしてお試しいただけます。Formatter Clubには、AH Formatterのベテランユーザーや組版のプロたちも集まっていて、MLや定例会でノウハウを交換して知識を広げることができます。
ということでAH Formatterと、Formatter Clubをどうぞよろしく。それから「CSS組版ブログ」のほうもよろしく。