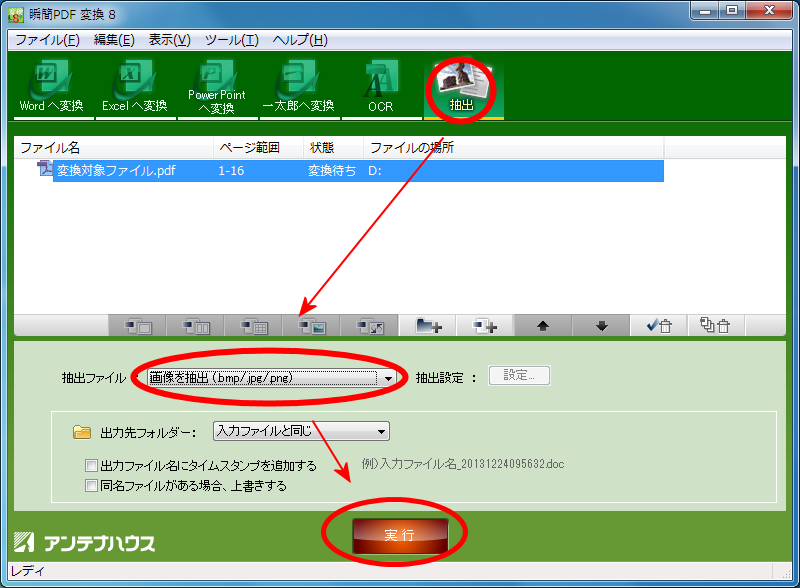
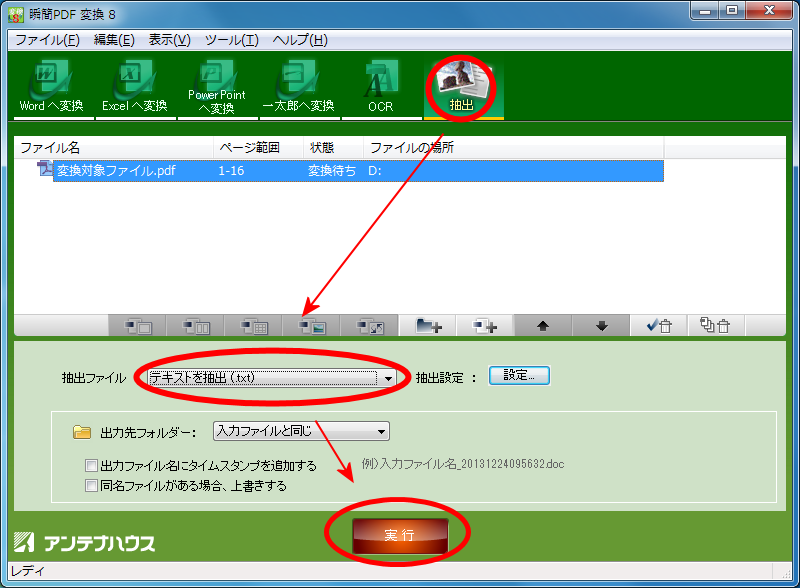
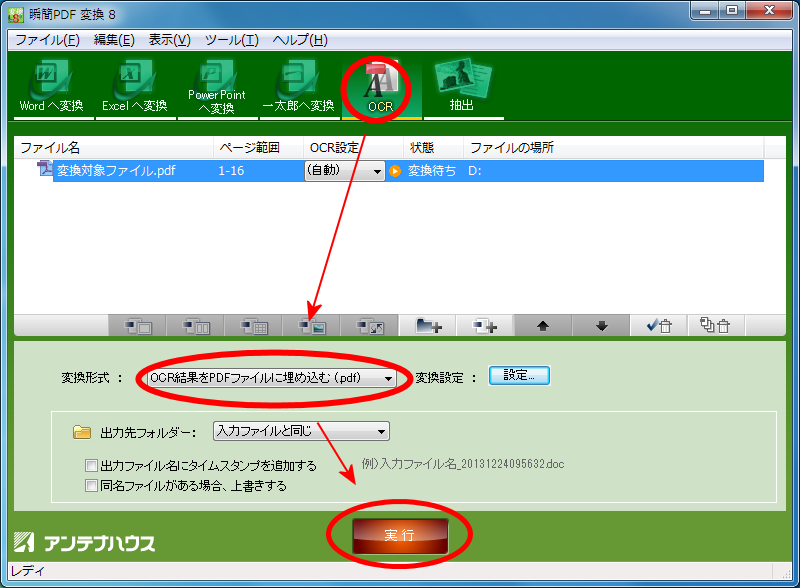
さて、3月に入り来月には新年度が始まります。新社会人になる方、新学期を迎える方など、新しい環境で始動する機会も多いことでしょう。
仕事や勉強のために、はじめてパソコンを買ったり、触れたりする方も多いのではないかと思いますが、インターネットのやり方や電子メールのやり方、電子文書の作成の仕方など、パソコンを使った作業で覚えることも沢山!
その中で、いずれは「PDF」(ピーディーエフ)というものに出くわすことになると思います。はじめのうちはWebサイトでダウンロードしたり、電子メールで送信されてきたものを見ることが多いと思いますが、パソコンを使いこなして文章や資料などを作成していくと、PDFを作成することが必要になってくることもあります。
PDFとはパソコンなどで見ることができる電子ファイルの形式のひとつで、「○○○.pdf」とファイル名の最後に「.pdf」が付いたファイルです。(※Windows の初期の状態ではこの「.pdf」(PDFの拡張子)などは表示されない設定になっています。)
PDFファイルイメージ
閲覧ソフトがあればパソコンでも、スマホでもタブレットPCでも、環境を問わず同じ状態で見たり印刷したりできる利点があります。
無料のPDF閲覧ソフトが普及していて、誰でも簡単に見ることができるため、電子文書を見たり、電子メールで送ったり、インターネットで配布したり、保管、共有するのに適しており、多くの場面で使われています。
PDFについて詳しくは、弊社のWebサイトでも解説していますので、参考にしていただければと思います。
PDFとはなんですか? PDFにするとどんなメリットがありますか?
PDFってどうやって作るの?
PDFを見ることは簡単ですが、PDFを作るのってどうやるのでしょうか。
実はPDFを作成するソフトがあれば、簡単に作れるのです。
電子文書の作成ソフトに標準でPDFに出力できるものもありますが、これはその電子文書作成ソフトからしか利用できません。
PDFにはいろいろなソフトで作ったファイルをすべてPDFにすることで、ひとつのPDFの文書としてまとめることができるという利点もあります。Office文書以外にもテキストや画像、一太郎、Webページ、メール、図面などすべてPDFにしてまとめてることができれば、提出資料の作成や配布文書などの作成にすごく便利ですね。
そこで、いろいろな電子ファイルからPDFを作成できるように、PDFの作成ソフトというものがあります。
現在ではいくつものPDFの作成ソフトがありますが、多くのソフトはプリンターで印刷する方法とほぼ同じ手順で作成することができます。
電子文書を印刷するとき、その電子文書を開いているソフトの「印刷」メニューから、プリンター(プリンタードライバー)を選んで印刷をすると思いますが、まさにこのプリンター(プリンタードライバー)を選ぶ代わりにPDF作成ソフト(PDF作成仮想プリンタードライバー)を選んで印刷することでPDFを作成することができます。
アンテナハウスのPDFを作成するソフトの代表は『瞬簡PDF 作成 7』というソフトです。

このソフトをパソコンにインストールすると、他のプリンターと同様にプリンターの一覧に『Antenna House PDF Driver 6.0』が入ります。
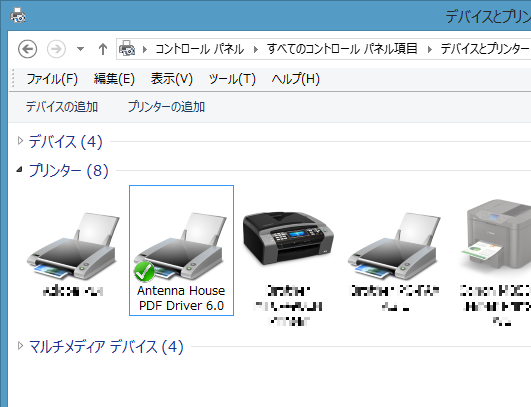
プリンターの一覧
印刷時にプリンターの代わりにこの『Antenna House PDF Driver 6.0』を選んで印刷を実行するだけで、いろんな印刷機能を持つソフトからPDFを作成することができます。
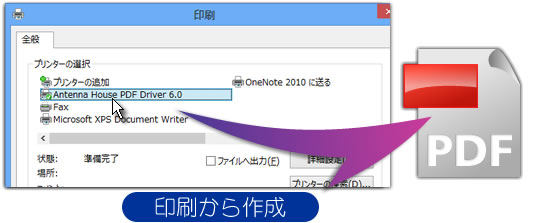
アプリケーションの印刷からPDF作成