oXygen XML Editor 20.0 の販売を2018年03月16日から開始いたしました。
oXygen XML Editor は先進のXMLオーサリング・開発機能とグラフィカルな編集プラットホームを提供し、世界各国で愛用されています。
Windows、Mac OS X、Linuxに対応し、ユーザーインタフェースには日本語版も用意されています。
oXygen XML Editor にはDITAで書かれた文章を、HTMLで構成された WebHelp(Webページ)に変換する機能を備えています。
例えば以下のように書かれたDITA文書を WebHelpに変換すると・・
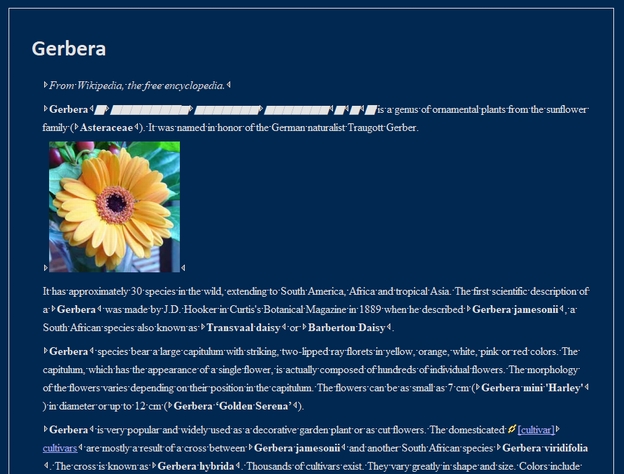
ボタンひとつで、このようなWebページを作成することができます。
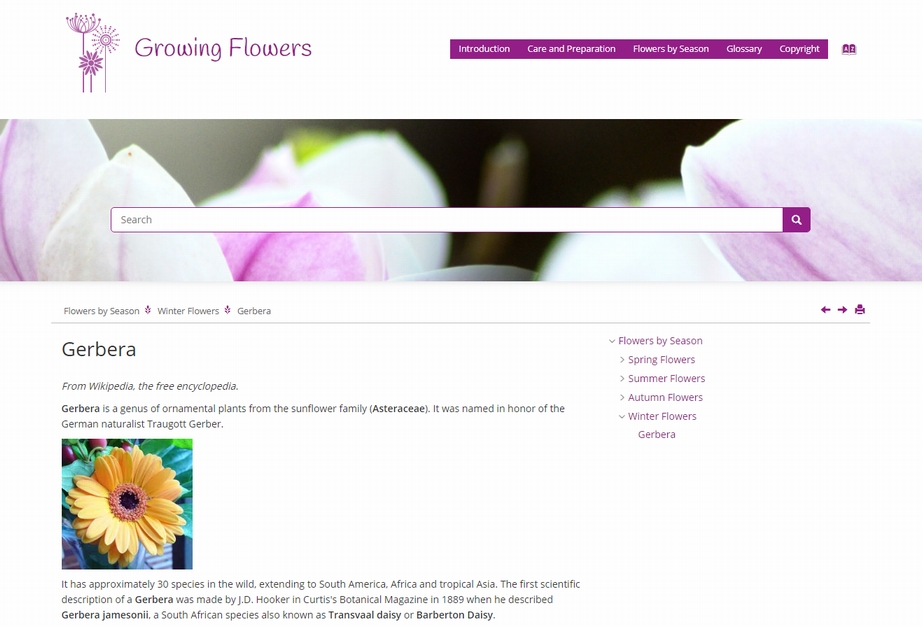
先ほどのDITA文書をPDFに変換することもできますよ。
こちらレイアウトにはアンテナハウスで開発した pdf5.mlを使用しています。

ひとつの文章から、Webページを作成したり、PDFを作成したり、色々なことができます。
oXygen XML Editor の WebHelpは最初からレイアウトのテンプレートが用意されているので、簡単にレイアウトを変更することができます。
例えば、空と雲をモチーフとしたレイアウト。
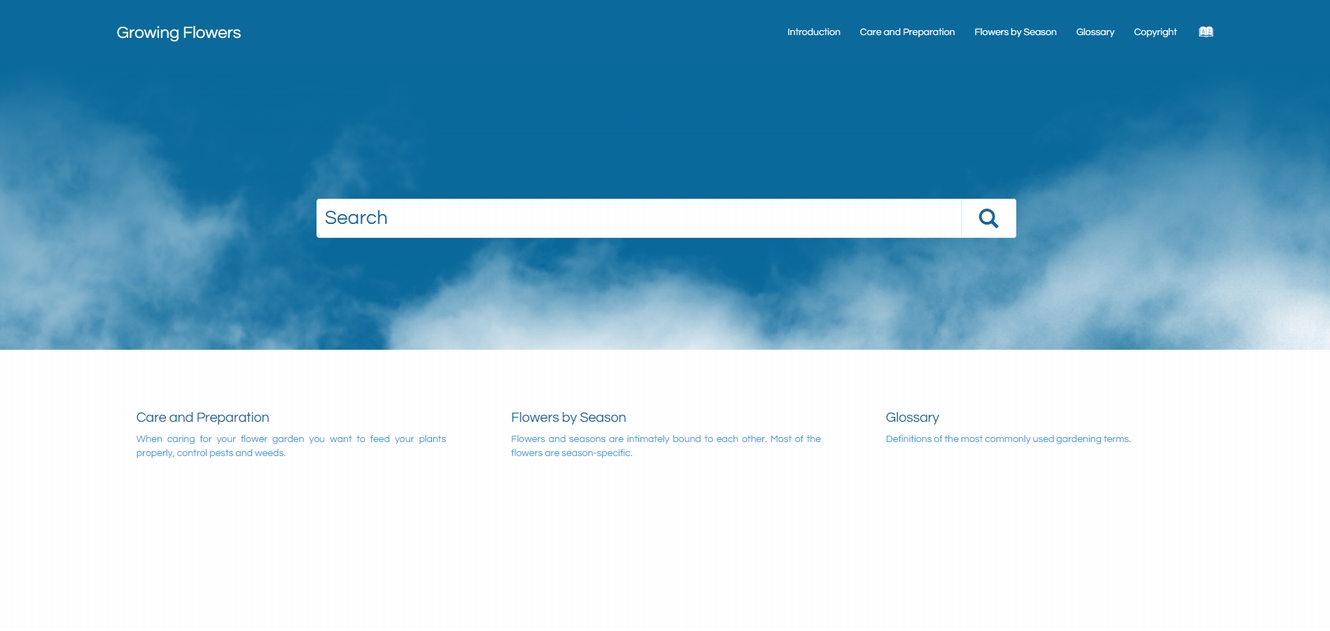
テクノロジーをモチーフとしたレイアウト。
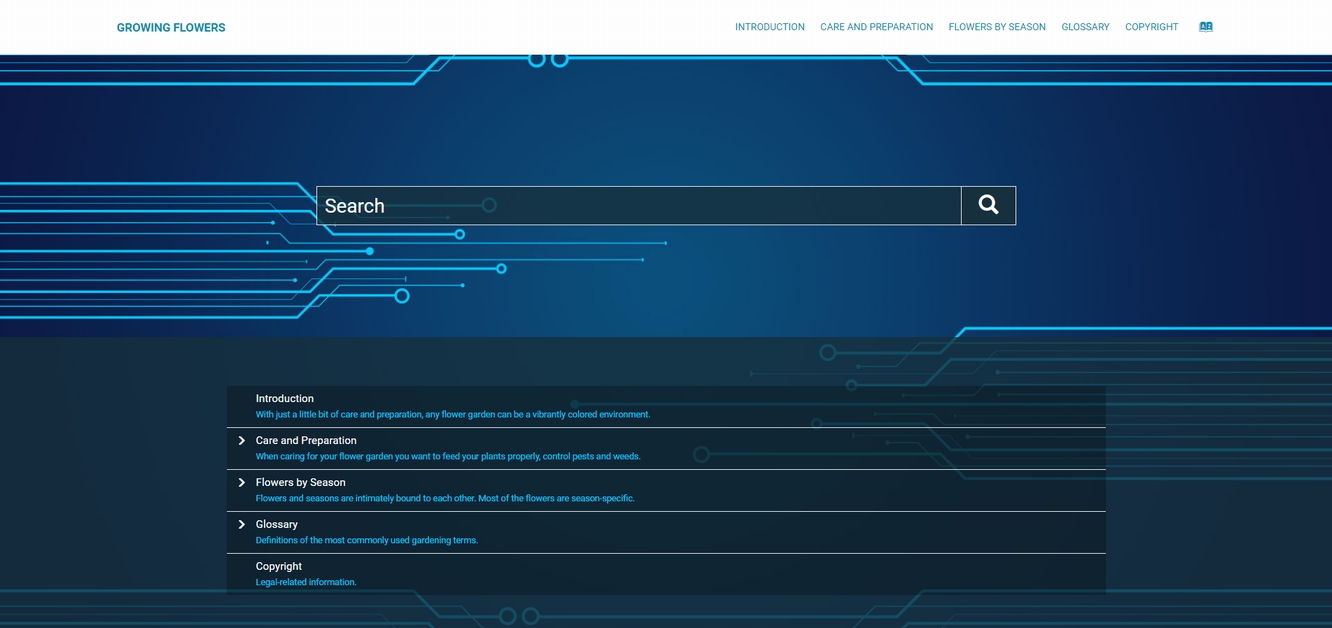
もちろんスタンダードでシンプルな青色をモチーフとしたレイアウトもあります。
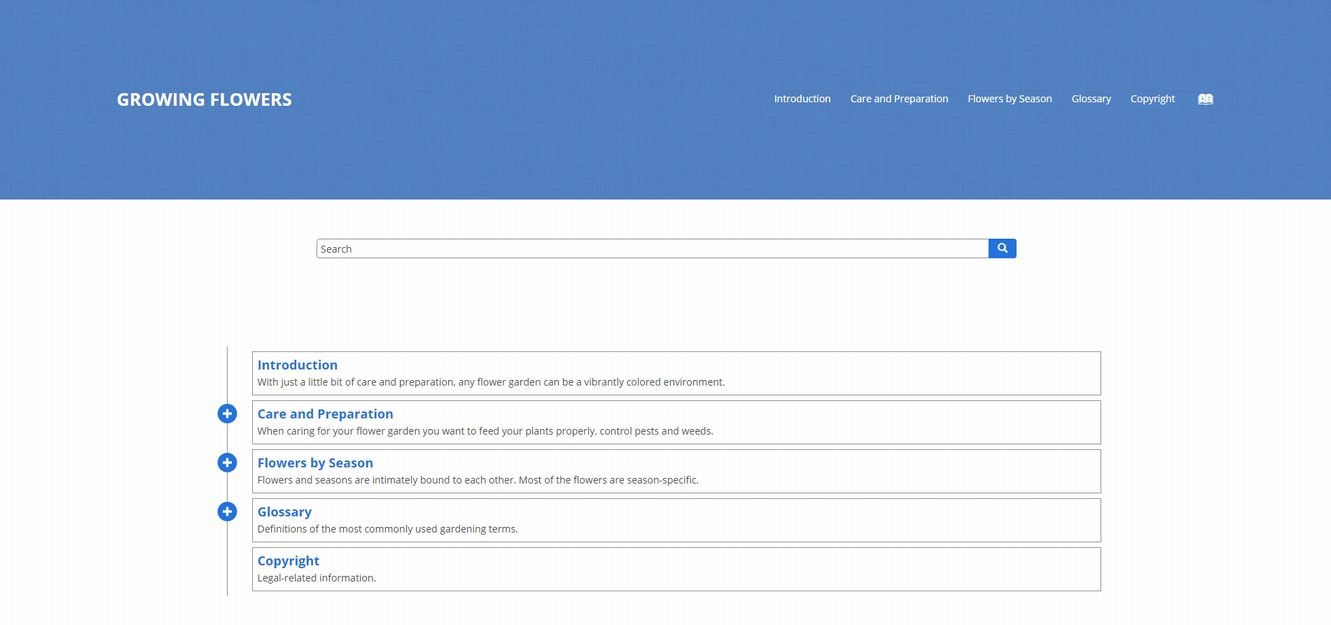
他にも色々なテンプレートが用意されています。
テクニカルな要素は増えますが、自分でテンプレートを作成することもできます。
テンプレートの作成方法(英語)
https://www.oxygenxml.com/doc/versions/20.0/ug-editor/topics/whr_publishing_template_contents.html
WebHelpはレスポンシブデザインで設計されているので、モバイル機器の表示にも対応しています。すごい!
ここまでくると、もはやエディタという感覚ではなく、システムという感覚に近いですね。
oXygen XML Editor 20.0 で追加された主な機能は以下です。
・ DITA
- 未参照のキー定義をレポートする
[DITA マップ 完全度の確認]ダイアログボックスに新しく[参照されていないキー定義を報告する]が追加され、 参照されていないキー定義をレポートすることができます。 - 未参照の再利用可能な要素をレポートする
[DITA マップ 完全度の確認]ダイアログボックスに新しく[参照されていない再利用可能な要素をレポートする]が追加され、 どこにも参照されない潜在的な再利用可能な要素をレポートすることができます。
これらは、ID属性を持ち、リソースのみとしてマークされたトピック、または他の要素が再利用されるトピックで定義される要素です。
・ WebHelp
- 公開テンプレート
WebHelpレスポンシブ出力のルックアンドフィール(レイアウトとスタイル)を定義します。 これらのテンプレートは、チームと簡単に共有できるカスタマイズパッケージを表します。 - ビルトイン公開テンプレートギャラリー
oXygenには組み込みの公開テンプレートが付属しています。 これは、WebHelp変換シナリオの[ テンプレート ]タブで利用できます。 フィルタリングオプションとテンプレートプレビュー画像を使用して、 必要なテンプレートを簡単に見つけることができます。
・・・などなど、これらが追加された機能の一部となります。(追加機能が多すぎて書ききれません!)
詳細はアンテナハウスのホームページをご覧ください。
https://www.antenna.co.jp/oxygen/#v20.0
oXygen XML Editor はバージョンアップの度に、沢山の機能が追加されます。
こちらのページでは oXygen XML Editor 19.0 19.1 20.0 に追加された機能を紹介しています。
https://www.antenna.co.jp/oxygen/new-feature190-200.html
- マスターファイルサポート
- DITA再利用コンポーネントビュー
- PDFとXHTML出力のフロート画像
- DITAトピックタイプの変換
- oXygen WebHelp テンプレート
DITAやWebHelpに関する機能がとても充実していますね!
oXygen XML Editor に関してはアンテナハウスまで お問い合わせ ください!(oxygen@antenna.co.jp)



![[AH Formatter] インデントの継承のお話](https://www.antenna.co.jp/AHF/blog/201803/cap1.png)
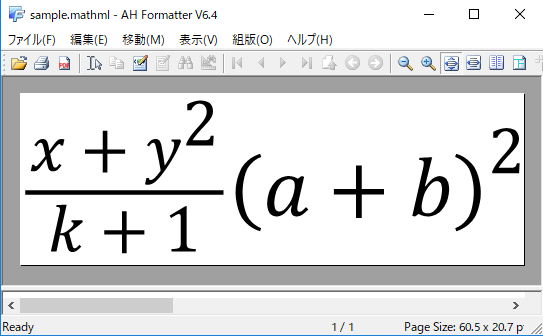
![[CSS組版例] MathML 3.0 2nd Edition](https://www.antenna.co.jp/AHF/blog/201803/MathML3.0-2ndEdition.png)