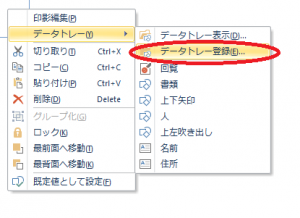
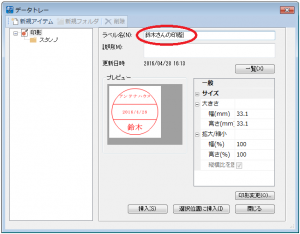
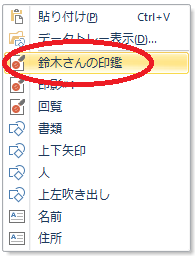
Webマニュアルの公開
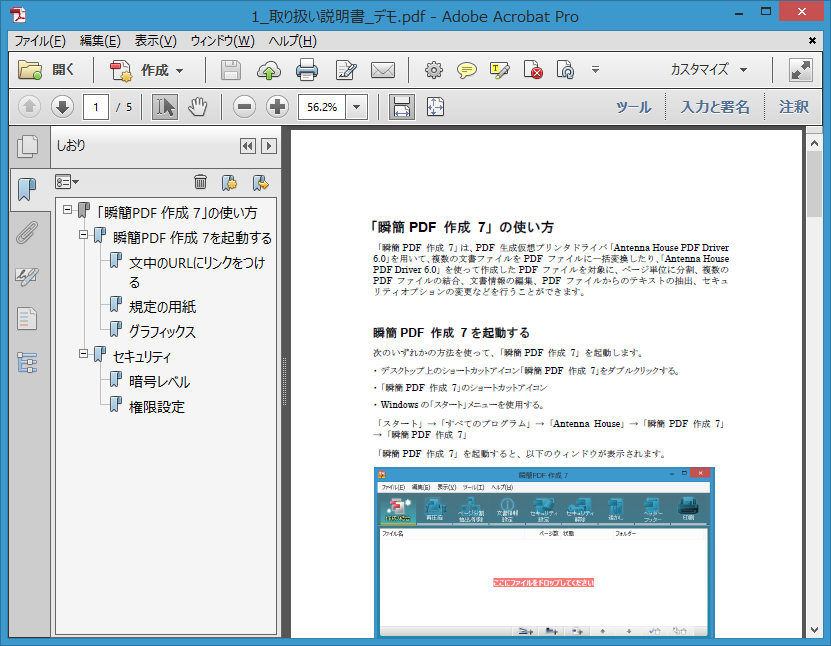
瞬簡PDFシリーズ製品では、ユーザーズマニュアルやヘルプを、PDF形式やWindowsヘルプ形式でご利用いただけますが、いずれも製品をインストールした後に表示できるようになっています。
ご購入前や製品をインストールしていないパソコン、スマホなどから、簡単にマニュアルを確認する方法がこれまでありませんでした。
そこで、Webから手軽にマニュアル(ユーザーズマニュアル)をご覧いただけるよう準備を進めており、現在、下記の3製品を公開しております。
瞬簡PDF 書けまっせ 6 ユーザーズマニュアル
https://www.antenna.co.jp/kpd/pdfwritemanual_web/index.html
瞬簡PDF 作成 7 ユーザーズマニュアル
https://www.antenna.co.jp/SPD/skpdf7_webpage/index.html
瞬簡PDF 編集 6 ユーザーズマニュアル
https://www.antenna.co.jp/pdfedit/manual/index.html
Webマニュアルは、すでに『AH Formatter』や『AH PDF Tools API』などシステム製品などでも公開しており、こちらも順次拡大予定です。
紙のマニュアルも販売中

紙のマニュアルを読みたいというご希望も多くいただいております。
そこで、『瞬簡PDF 作成 7』のユーザーズマニュアルを冊子(紙の本)でお求めいただけるようになりました。
AmazonのPOD(プリントオンデマンド)サービス
『瞬簡PDF 作成 7 ユーザーズマニュアル オンデマンド(ペーパーバック)』
https://www.amazon.co.jp/dp/4900552240/
製品インストール後に利用できるPDFマニュアルはA4の用紙にプリンターで印刷することを想定しています。
POD版のマニュアルは、冊子用に最適化した版面、誌面レイアウトになっています。
現在は『瞬簡PDF 作成 7』だけですが、ご要望に応じてこちらも順次拡大予定です。
なお、この『瞬簡PDF 作成 7 ユーザーズマニュアル オンデマンド(ペーパーバック)』は、弊社の書籍編集・制作Webサービス『CAS-UB』で執筆し、AmazonのPOD用に出力したものです。PDFマニュアル版、POD版をひとつの原稿から生成できます。
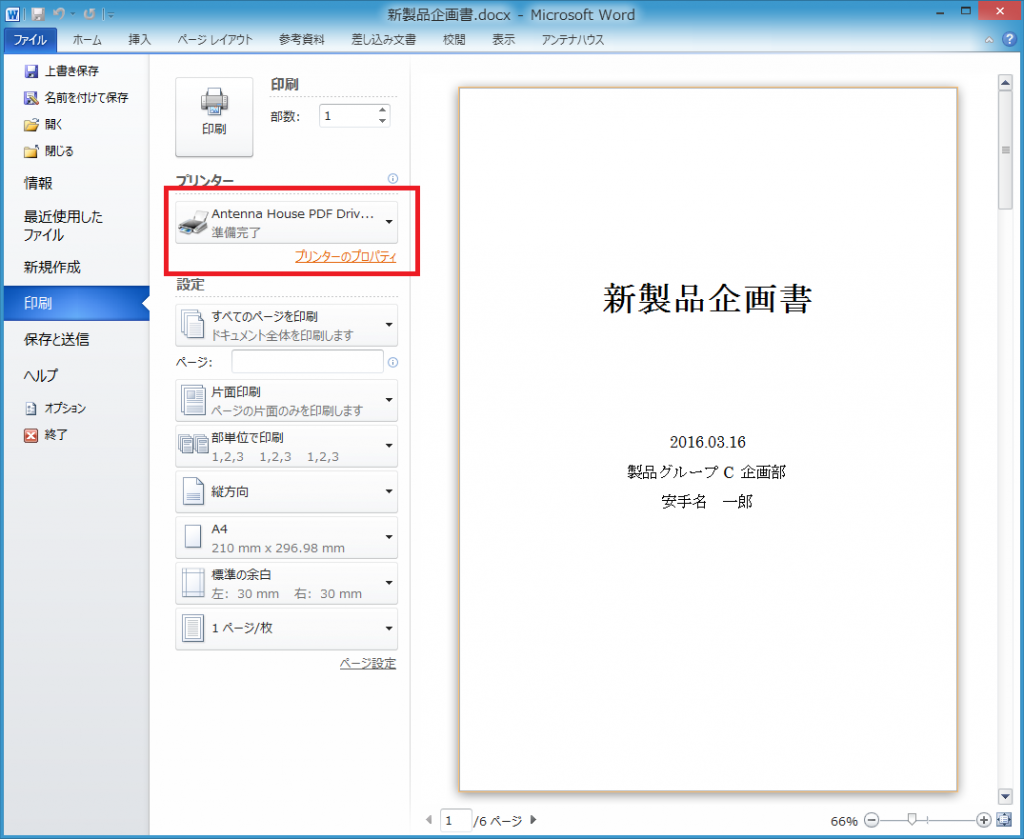
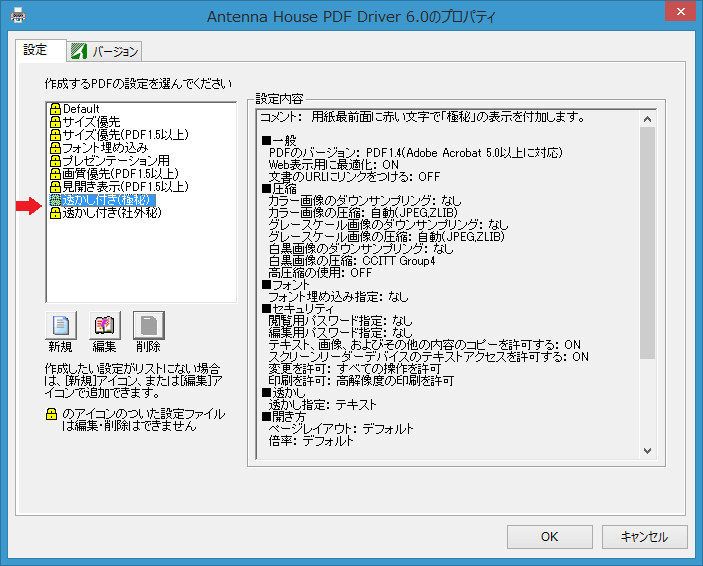
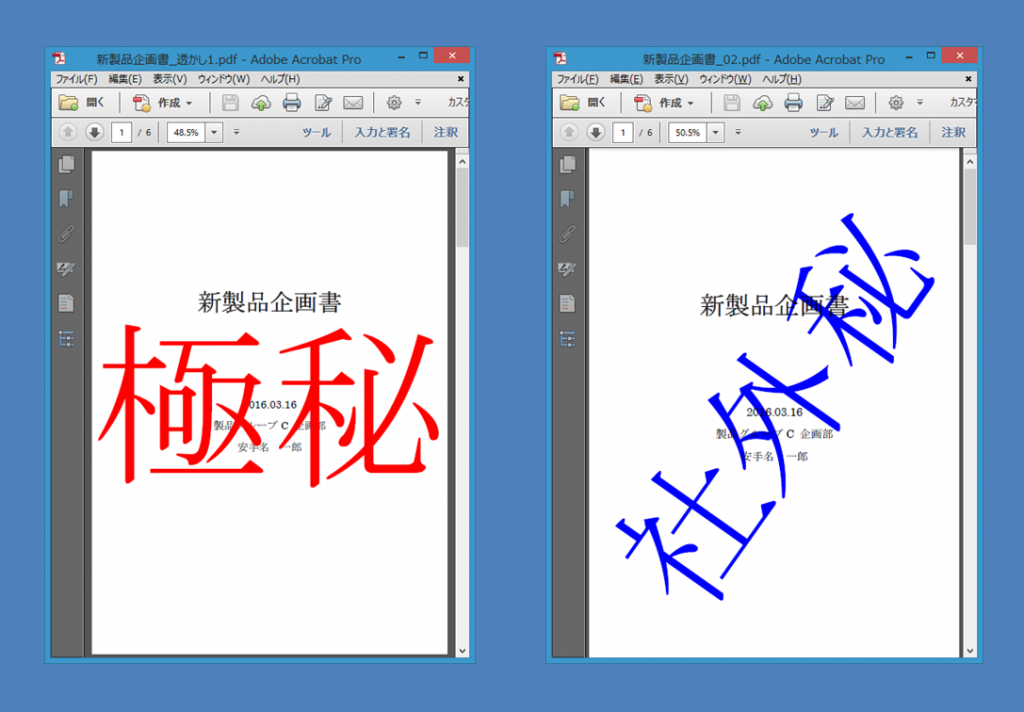
※【ご注意】『瞬簡PDF 作成 7 ユーザーズマニュアル オンデマンド(ペーパーバック)』には、PDF変換ドライバ『Antenna House PDF Driver』の操作方法や設定方法についての記載はございませんので、ご注意ください。Webマニュアルはこちら(PDF Driver 利用ガイド)をご覧ください。